https://arxiv.org/pdf/2106.09685 - 논문링크
논문리뷰
Abstract
- 최근 자연어처리에서는 pre-trained된 language model을 가지고 downstream-application에 적용
- 다양한 application에 알맞게 적용을 할려면 fine-tuning 작업을 해야한다.
- 하지만, fine-tuning을 할 때 가장 큰 단점은 모든 파라미터를 업데이트 해야한다는 것이다.
- 기존 GPT-2나 RoBERTa large에서는 단순 불편한 문제였지만, language model이 발전함에 있어 GPT-3와 같은 1750억개의 학습 파라미터가 있는 language model에서는 중요한 문제이다.
- 따라서 이 논문에서는 Low-Rank Adaptation, 또는 LoRA라는 방법론을 제시하였다
- LoRA는 pre-trained된 모델의 weight들을 고정시킨 뒤, 학습 가능한 rank decomposition matrices를 transformer의 각 레이어에 붙여 fine-tuning할 때 이들만 업데이트 하는 방식이다.
- 이로인해, 더 적은 수의 파라미터를 업데이트 함에도 많은 language model에서 더 높은 성능을 보여주었다.
rank decomposition matrices란?
행렬을 더 작은 랭크의 행렬로 분해햐는 기법. 주로 행렬의 차원을 축소하여 계산 효율성을 높이기 위해 사용
이 예시를 통해 큰 행렬을 두 개의 작은 행렬로 분해하는 것을 확인할 수 있음. LoRA는 이 아이디어를 통해 pre-trained model의 일부 작은 행렬만 업데이트함으로 효율적인 fine-tuning을 가능하게 함.
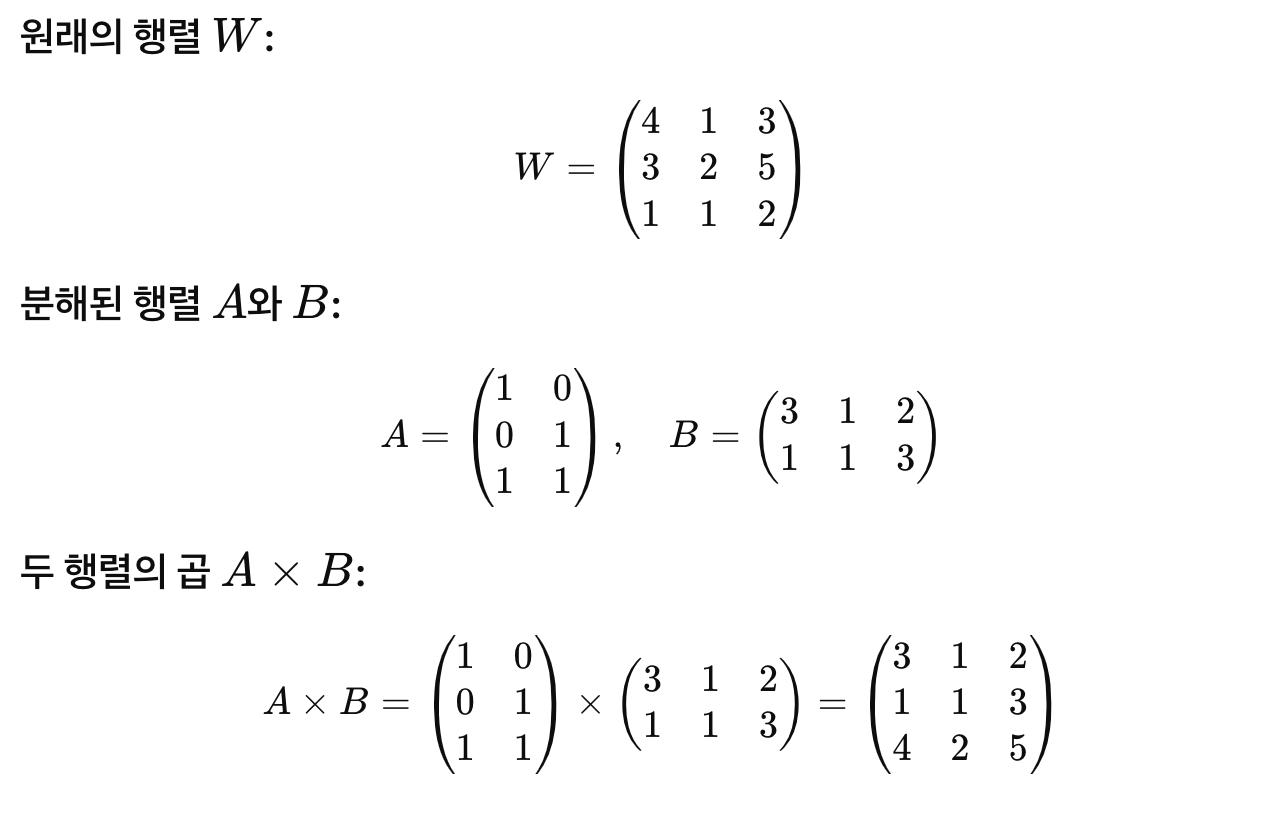
1. Introduction
- 모델이 클수록 pre-trained된 fine-tuning을 할 때 더 많은 파라미터를 학습시켜야 해서 시간도 오래 걸릴 뿐더러 비효율적이다.
- 따라서 모든 파라미터를 업데이트 하는 것이 아닌, 일부 파라미터만 업데이트 하는 방식들이 제시되었다.
- 하지만, 이러한 방식은 모델 깊이를 확장하거나 모델의 사용 가능한 시퀀스 길이를 줄임으로 inference latency와 fine-tuning baseline(기준선)과 일치하지 않는 경우가 많아 효율성과 모델 품질 사이에 trade-off가 발생
Inference latency : 모델이 답을 내기까지 걸리는 시간
Trade-off : 두 가지를 동시에 최대로 얻을 수 었어, 한쪽을 높이면 한쪽이 낮아지는 상황 (즉, 한쪽은 포기해야 한다는 것) - 따라서 논문 저자들은 이전의 연구에서 영감을 받아, over-parametrized model이 실제로 low instrinsic dimension에 놓을 수 있다 주장하였다.
Over-parametrized model : 모델이 매우 복잡해, 많은 파라미터를 가지고 있는 상황
Low instrinsic dimension : 모델이 겉보이게 매우 복잡해 보이는 데이터나 모델도 실제로는 몇 가지 주요 변수로 설명할 수 있는 것 - 즉, low dimension의 intrinsic rank를 이용해 fine-tuning하는 방식은 Low-Rank Adaptation(LoRA)를 제시하였다.
Intrinsic Rank : 데이터나 모델에서 실제로 중요한 차원의 수를 나타내는 개념
- 이를 통해 pre-trained model의 wieght들은 업데이트 하지 않고, LoRA의 rank decomposition matrices의 weight들만 업데이트 하는 것이다. (레이어의 변화에 대한 rank decomposition matrix들을 최적화하여 신경망의 일부 레이어를 간접적으로 학습)
직접적인 학습 : 모든 파라미터를 직접 업데이트 하는 방식
간접적인 학습 : 기존의 큰 가중치 행렬을 고정하고, 작은 행렬들을 업데이트하여 간접적으로 가중치를 조정하는 방식
LoRA의 작동 방식 : 가중치 행렬 𝑊는 고정된 상태로 두고, 작은 행렬 𝐴와 𝐵만 업데이트하여 𝑊를 간접적으로 조정. 이로 인해 모델의 일부 레이어는 간접적으로 학습되며, 이는 메모리와 계산 비용을 절감하면서도 높은 성능을 유지할 수 있음.
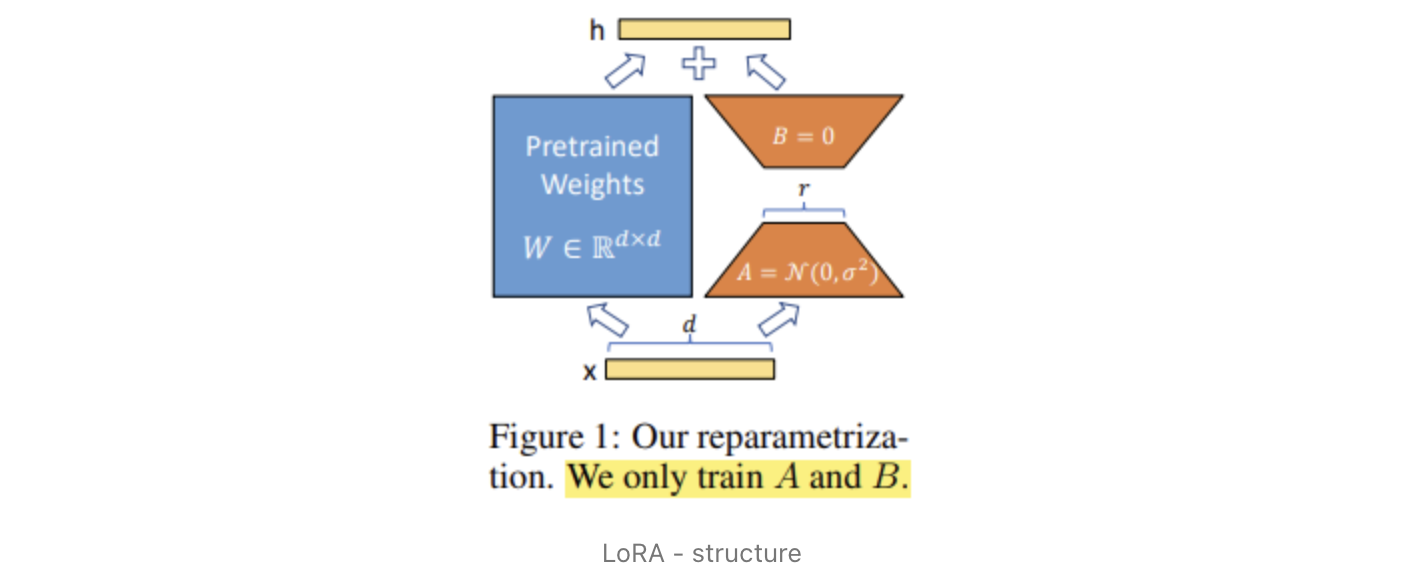 - 사전 학습된 가중치 𝑊를 고정하고, 작은 행렬 𝐴와 𝐵를 추가하여 fine-tuning을 수행하는 LoRA 방법을 설명하는 사진
- 사전 학습된 가중치 𝑊를 고정하고, 작은 행렬 𝐴와 𝐵를 추가하여 fine-tuning을 수행하는 LoRA 방법을 설명하는 사진
- 예를 들어 GPT-3 175B의 경우 rank-1, rank-2 (위 그림에서 r=1, r=2인 경우)와 같은 low rank로도 full rank (rank-d, d는 model의 hidden dimension)를 대체할 수 있음을 증명했다고 밝히고 있다. (즉, GPT-3와 같은 대형 모델에서 LoRA 방법을 적용했을 때, 매우 작은 rank(예: 1 또는 2)로도 충분히 원래의 전체 rank를 대체할 수 있다는 것을 증명)
Rank: 행렬에서 독립적인 정보의 차원의 수
LoRA에서의 Rank: 큰 가중치 행렬을 작은 행렬로 분해할 때 사용되는 차원의 수로, 매우 작은 값으로 설정(예: 1 또는 2)
Terminologies
- 본 논문은 Transformer의 아키텍처의 기존 용어 사용

2. Problem Statement
-
다음은 기존의 fine-tuning 방식인 모델의 모든 파라미터를 업데이트 하는 "최대우도 추정(Maximum Likelihood Estimation, MLE)" 목적식이다.
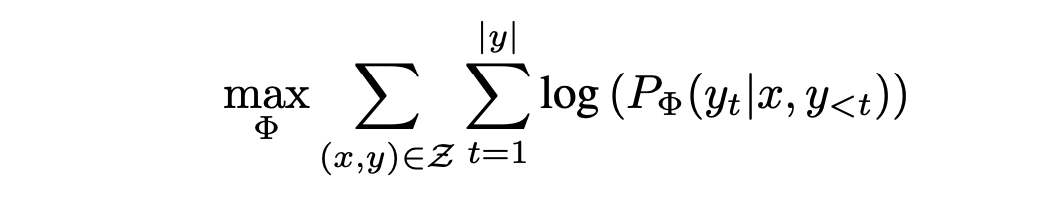
Φ: 모델의 파라미터
maxΦ: 매개변수 Φ를 최적화
(x,y)∈Z: 데이터 샘플
t: 타임 스텝
PΦ(yt|x, y<t): 주어진 입력 x와 이전 출력 y<t에서 현재 출력 yt의 확률 -
즉, MLE를 이용해 모델의 전체 파라미터 Φ를 업데이트 하는 것이다.
-
하지만, 앞서 언급했다 시피 이 방식은 pre-trained과 fine-tuning할 때 전체 파라미터 Φ를 업데이트 한다는 문제가 있다. (계산 비용과 메모리 사용량이 큼)
-
따라서 본 논문에서는 각 downstream task마다 다른 LoRA layer를 사용해 효율적으로 파라미터를 업데이트 하도록 제시하였다.
LoRA Layer: 사전 학습된 모델의 가중치 행렬에 두 개의 작은 행렬을 추가하여 효율적으로 파라미터를 업데이트하는 구성 요소.
-
기존의 model 파라미터인 Φ를 이용해 forward를 진행한 뒤 얻어지는 ΔΦ(Φ의 gradient)를 이용해 backpropagation을 진행할 대 LoRA의 파라미터 Θ를 이용하는 것이다.
-
다음은 LoRA를 이용해 일부분의 파라미터만 업데이트하는 목적식이다.
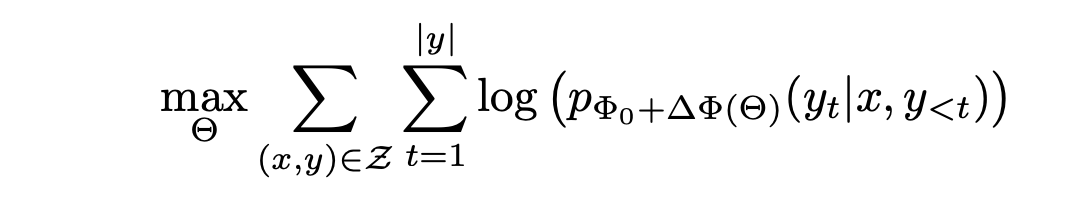
Θ: LoRA의 파라미터
Φ0: 사전 학습된 모델의 고정된 파라미터
ΔΦ(Θ): LoRA 파라미터 Θ를 이용해 계산된 파라미터 업데이트
- 이 식은 모델의 일부 파라미터만 업데이트하여 효율적으로 파라미터를 학습하는 방법이다.
- 논문에서는 LoRA로 업데이트하는 파라미터 Θ의 크기인 |Θ|가 기존의 fine-tuning으로 업데이트 하는 파라미터 Φ의 크기인 |Φ|의 0.01%라고 한다. (훨씬 효율적이고, task-specific하다)
3. Aren't Existing Solutions Good Enough?
- 본 논문에서 해결하고자 하는 fine-tuning의 문제는 본 논문외에도 다양한 시도들이 있었다.
- 이러한 방법을 Parameter-Efficient Fine-Tuning (PEFT)라 부른다.
- 다양한 시도들은 크게 두 가지 흐름으로 나눌 수 있다
- Adding adapter layers : adapter라는 layer를 transformer block에 추가해주어 이 부분만 학습하는 것으로 기존 fine-tuning을 대체하는 것
Adapter Layers: 대규모 pre-trained model의 각 transformer 블록 사이에 추가되는 작은 네트워크 모듈.
- Optimizing some forms of the input layer activations : language model의 입력으로 들어갈 input vocab embedding에 prompt embedding을 추가하고, prompt embedding을 다양한 학습 방법으로 학습시키는 것으로 기존 fine-tuning을 대체하는 것
prompt embedding: 모델의 입력으로 추가되는 특화된 임베딩 벡터로, 특정 작업을 수행하기 위한 힌트나 지시를 포함
- 그러나 위 두 가지 방법은 문제가 있다.
- Adapter Layers Introduce Inference Latency (adding adapter layers)
- transformer를 이용한 기존 대규모 신경망은 하드웨어의 병렬 처리가 가능하다는 것이 장점이었는데, adapter를 적용하면 추가적인 컴퓨팅 작업이 들어가기 때문에 작업 시간이 눈에 띄게 증가하는 것을 볼 수 있다.
- 파라미터를 높일수록, 즉 연산량이 많아질수록 확연하게 시간이 증가했다.
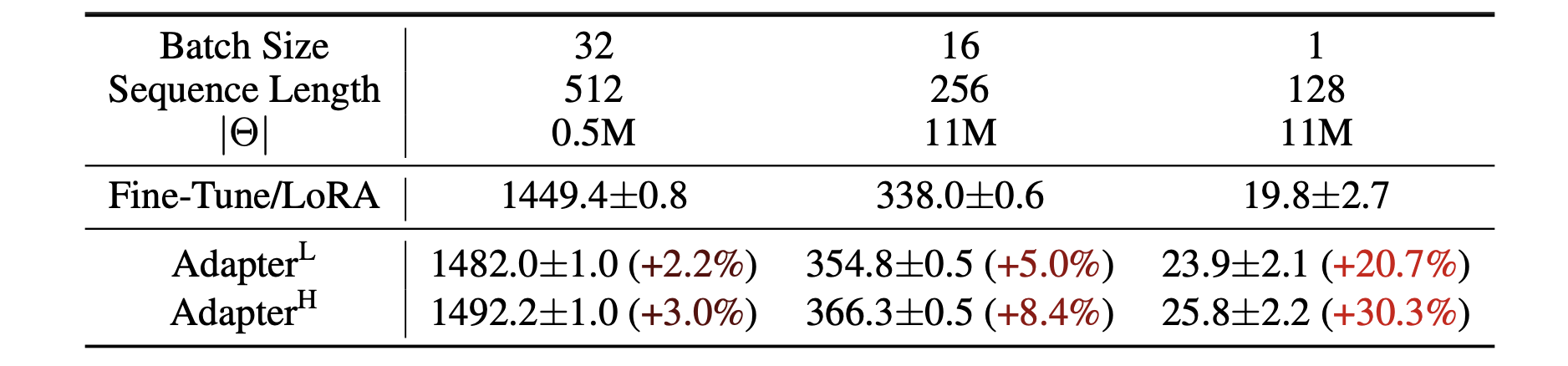
추론 지연(inference latency): Adapter를 사용하면 기존의 Fine-Tune/LoRA 방식에 비해 추론 시간이 증가함.
Batch Size와 Sequence Length의 영향: 배치 크기와 시퀀스 길이가 작을수록 Adapter의 영향이 더 크게 나타남.
Adapter의 종류:
Adapter𝐿: 낮은 메모리와 계산 요구량으로, 상대적으로 적은 지연 발생.
Adapter𝐻: 높은 메모리와 계산 요구량으로, 상대적으로 큰 지연 발생.
- Directly Optimizing the Prompt is Hard (optimizing some forms of the input layer activations)
- 이 방법에 해당하는 대표적인 예시로는 prefix tuning이 있는데, 최적화하는 것 자체가 어렵고, 그 성능이 단조적으로 증가하지 않고 진동하는 경우도 있다고 논문에서 밝히고 있다. (its performance changes non-monotonically in trainable parameters)
- 더하여 이 방법을 사용하게 되면, sequence input을 넣을 때 prompt 자리를 미리 만들어놓아야 하기 때문에 downstream task를 처리하는데 사용할 수 있는 sequence length의 길이가 줄어드는 것도 한계라 밝히고 있다.
Prefix Tuning: 입력 시퀀스 앞에 학습 가능한 프롬프트 임베딩을 추가하여 모델의 출력을 조정하는 방법
prompt 자리 미리 만들기: 입력 시퀀스 앞에 prompt 임베딩을 추가하는 과정
4. Our Method
- 앞으로 소개할 LoRA 방법론은 본 논문에서는 transformer에만 적용했지만, 다른 Deep-Learning 구조에서도 적용할 수 있다.
4-1. Low-Rank Parametrized Update Matrices
- 신경망의 많은 레이어들은 행렬곱으로 이루어져 있는데, 대부분의 weight layer들은 full-rank이다.
- 기존의 연구에서 모든 pre-trained model은 "low instricsic rank"를 가질 수 있다고 밝혔다.
- 예를 들어 기존 모델의 가중치가 메트릭스가 dk 크기는 가질 때, 이를 dr 매트릭스 B와 r*k매트릭스 A로 나타낼 수 있다.(여기서 r 차원은 d, k보다 작은 차원) 기존의 파라미터 업데이트 과정과, A&B 매트릭스를 이용한 forward pass 과정을 수식으로 나타내면 다음과 같다.
Low Intrinsic Rank: 큰 행렬에서 중요한 정보가 몇 개의 작은 부분에 집중되어 있어서, 이 큰 행렬을 더 작은 행렬로 나눠도 거의 같은 정보를 유지할 수 있다는 개념
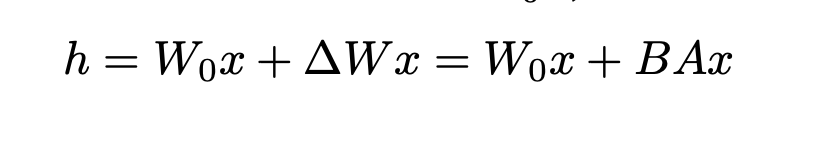
5. 가중치 초기화 시 A 매트릭스는 가우시안 분포를 따르는 랜덤 변수로 초기화하고, B 매트릭스는 0으로 초기화한다.
6. A Generalization of Full Fine-tuning
- LoRA 방법론을 통하면 차원 수는 감소하지만 (full-rank -> r-rank), 원래 모델과 관련된 weight만 효율적으로 학습가능하다.
- 반면 두 가지 기존의 방법론의 경우 한계점이 존재하는데 다음과 같다.
- adapter-based 방법론의 경우엔 추가적으로 Multilayer Perceptron(MLP) 레이어를 학습해야 한다.MLP Layer (다층 퍼셉트론 레이어): 여러 개의 완전 연결 층으로 구성된 신경망 모델.
완전 연결 층: 각 뉴런이 이전 층의 모든 뉴런과 연결. 이로 인해
모든 입력 뉴런의 정보를 조합하여 출력 뉴런으로 전달할 수 있음.
차원 수 감소: 모델의 가중치 행렬을 작은 행렬로 분해하여, 학습해야 하는 파라미터의 수를 줄이는 것을 의미. 이를 통해 계산 비용과 메모리 사용량을 줄이고, 효율적으로 모델을 학습할 수 있음 - prefix-based 방법론의 경우 input에 prompt embedding을 추가해야하기 때문에 long input sequences 추가하는데 한계가 있다고 언급한다.
- No Additional Inference Latency(추론 지연)
- 특정 task를 위해 LoRA 방법론으로 BA 가중치 매트릭스를 이용해 fine-tuning을 한 뒤 downstream task에 적용하고 싶은 경우, 단순히 BA 매트릭스를 B'A'매트릭스로 바꾸는 식으로 효율적인 학습이 가능하다.
4-2. Applying LoRA to Transformer
- Transformer 한 블럭에는 여러 개의 가중치 매트릭스가 있는데, self-attention module 4개의 가중치 매트릭스가 있고(Wq, Qk, Wv, Wo) encoder, decoder 각각에 MLP modlue이 있다.
- 이 중에서 본 논문이 LoRA를 적용하는 가중치 매트릭스는 attention 가중치 매트릭스로만 제한한다.
(MLP module의 가중치 매트릭스는 적용하지 않는다 - 'freeze the MLP modules both for simplicity and parameter-efficiency 때문') - Practical Benefits and Limitations
- LoRA의 가장 큰 이점은 메모리와 저장 공간을 효율적으로 사용할 수 있다는 것이다.
- 특히 GPT-3 1750억의 경우 VRAM의 사용량의 1.2TB에서 350GB로 줄일 수 있다.
- 또한 rank=4로 W_q, W_v 매트릭스만 adapt할 경우 35MB까지 줄일 수 있다.
- 이를 통해 25%의 속도 향상을 관찰할 수 있었다.
- 반면 LoRA의 한계로 다른 downstream task를 진행할 때마다 다른 AB 매트릭스들을 사용해야 한다.
5. Empirical Experiments
- 본 논문에서는 LoRA를 RoBERTa, De-BERTa 그리고 GPT-2에 적용시켜보고 크기를 키워 GPT-3 175B에도 적용시켜 보았다고 말한다.
- Natural Language Understanding(NLU), Natural Language Generation(NLG), GLUE bencgmark NL to SQL queries, SAMSum 등 다양한 downstream task에서 성능을 평가하였다.
- 모든 실험은 NVIDIA Tesla V100을 이용해 진행되었다.
5-1. Baselines
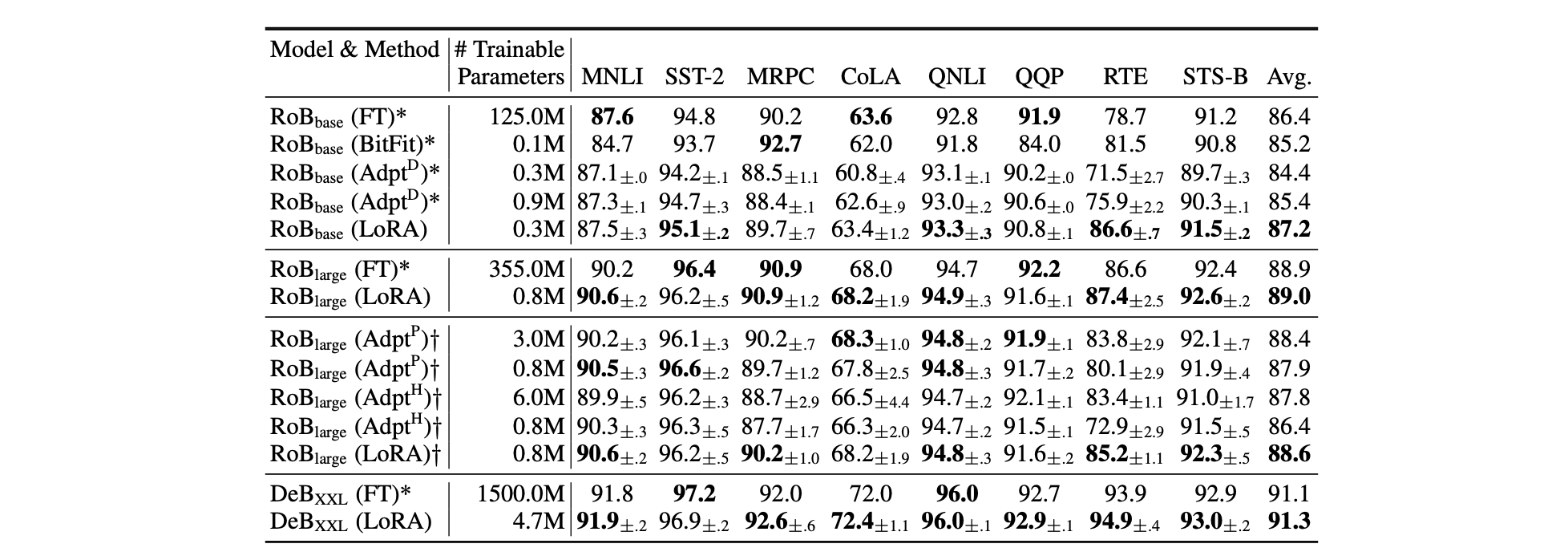
3. * 표시는 이전 연구의 방법론을 의미 && † 표시는 공정한 비교를 위해 Parameter-Efficient Transfer Learning for NLP, Houlsby etal., (2019). 의 설정을 따라 실험한 결과를 나타낸다.
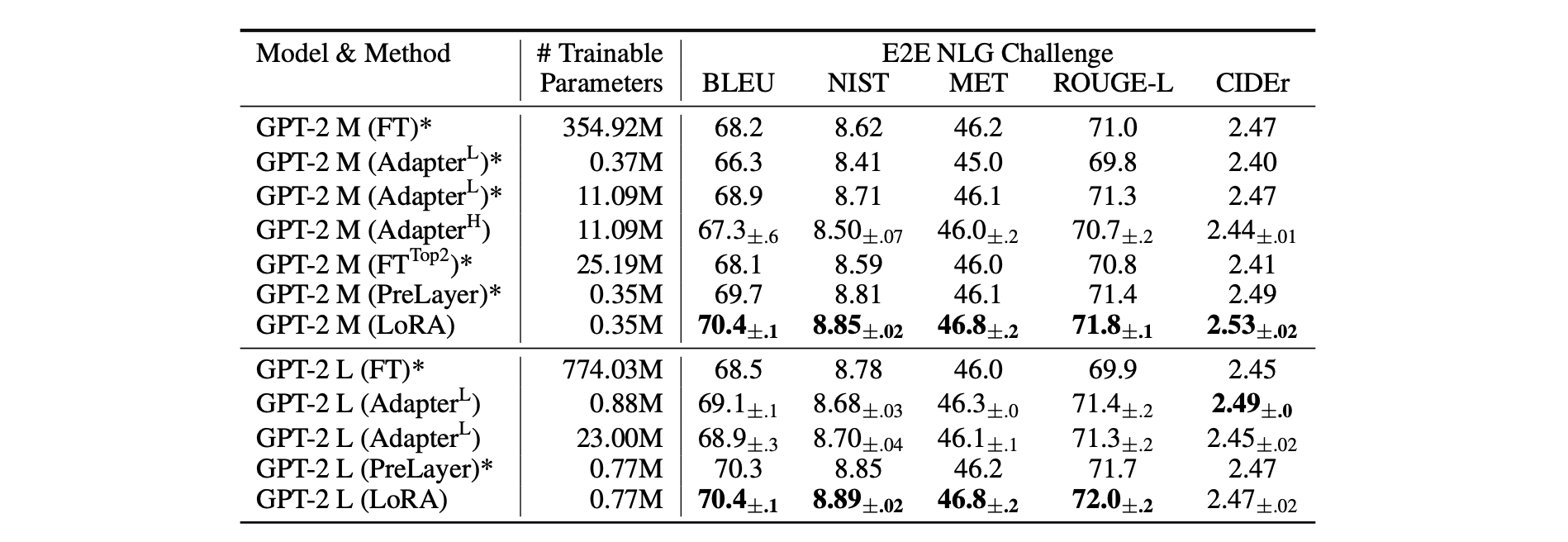
4. RoBERTa, De-BERTa, GPT-2를 이용한 대부분의 task에서 LoRA를 적용한 방법론이 가장 좋은 성능을 낸다는 것을 알 수 있다.
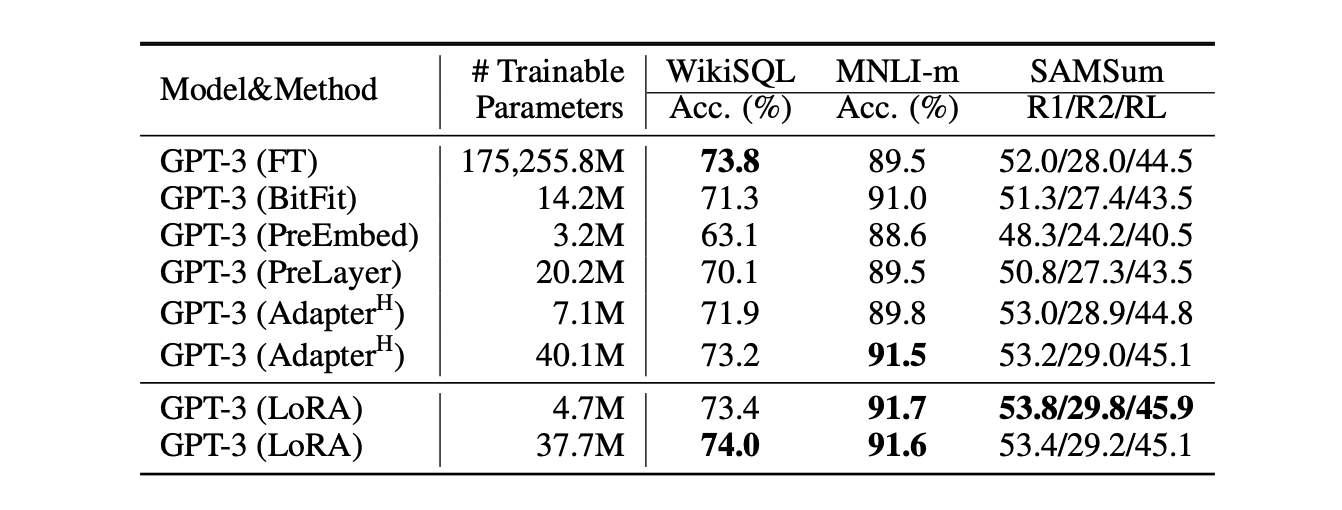
5. GPT-3를 이용한 task에서도 LoRA를 적용한 방법론이 가장 좋은 성능을 낸다는 것을 알 수 있다.
6. Understanding the Low-Rank Updates
- 본 연구에서 진행한 실험들을 바탕으로, 세 가지 토픽에 관해 연구진들이 조사한 내용을 밝히고자 한다.
- 어떠한 가중치 매트릭스에서 LoRA를 이용해야 가장 높은 성능 향상을 기대할 수 있을까?
- LoRA의 최적의 rank는 무엇일까?
- Adaptation matrix ΔW와 W의 사이에는 어떤 관계가 있을까?
6-1. Which Weight Matrices in Transformer Should We Apply LoRA to?
- 앞서 언급한 것처럼, self-attention module에 있는 가중치 매트릭스들(Wq, Qk, Wv, Wo)만 고려했으며, 전체 파라미터 수가 18MB(FP16인 경우 35MB)을 넘지 않도록 설정했다.
- 업데이트하는 파라미터의 용량을 제한하기 위해 예를 들어 한 가지 종류의 가중치 매트릭스를 사용한다면 rank=8이며, 두 가지 종류의 가중치 매트릭스를 사용한다면 rank=4로 하는 것이다.

- 결과를 살펴보면 W_q, W_q 두 가중치 파라미터에 LoRA를 적용하는 것이 업데이트하는 가중치의 종류를 최대한 적게 가지면서 좋은 성능을 냈다. 이를 통해 알 수 있는 것은 rank를 4로 해도 충분히 ΔW의 정보를 담을 수 있다는 것이다.
6-2.What is the Optimal Rank r for LoRA?
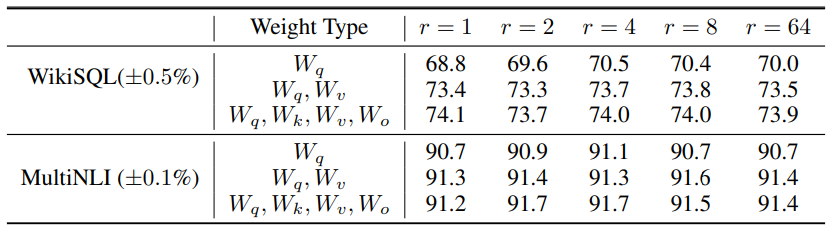
4. 놀랍게도, 매우 작은 rank로도 준수한 성능을 내는 것을 확인할 수 있다. (ΔW 업데이트 시, 매우 작은 'intrinsic rank'를 이용할 수 있다.)
5. Subspace similarity between different r.
- 똑같은 사전 학습 모델에서 rank 크기가 각각 8, 64인 LoRA를 적용해 학습한 뒤 만들어진 각각의 LoRA.매트릭스를 Ar=8, Ar=64라 할 때, 이들의 singular value decomposition(SVD)를 구한 뒤, U 값과 Grassmann distance를 이용해 두 매트릭스의 유사도를 계산한다.
- 그 결과 Ar=8, Ar=64의 1차원에서 유사도가 제일 높게 나왔으며 차원이 커질수록 유사도가 감소하였다.
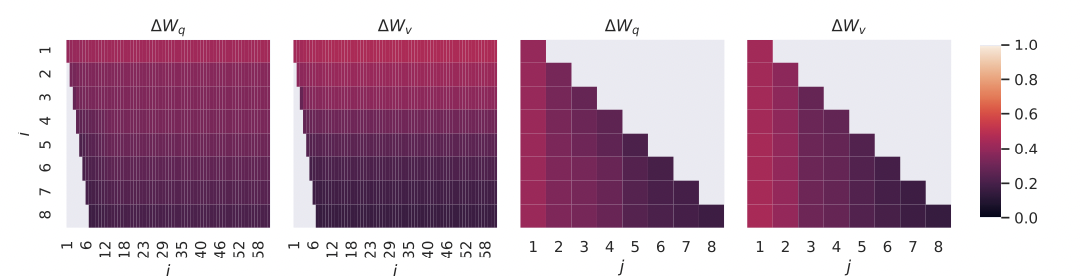
- 즉, 이것은 LoRA의 rank를 매우 저차원으로 했을 때도 (심지어 rank가 1일 때도) LoRA를 적용한 GPT-3가 downstream task에서 좋은 성능을 낼 수 있는 이유를 보여준다.
7. Conclusion and Future Work
- LLM을 fine-tuning하는 것은 많은 비용과 시간이 드는 작업이다.
- 본 논문에서 제시한 LoRA 방법론을 통해 얻을 수 있는 장점은 inference latency 줄일 뿐만아니라 input sequence 길이를 줄이지 않고도 fine-tuning이 가능하다는 것이 있다.
- 또한 다양한 downstream task에서 단순히 적은 수의 LoRA 파라미터만 바꾸면 되기에 효율적이다고 할 수 있다.
- Future works에는 다음과 같은 것이 있다.
- LoRA와 다른 adaptation 방법론과 결합할 수 있지 않을까
- LoRA의 원리가 명확하게 밝혀지지는 않았음
- LoRA의 weight matrices를 고를 때 휴리스틱한 방법에 의존
- ΔW의 rank 축소가 가능하다면 W도 rank를 축소해도 되지 않을까 하는 의문
