
서론
지난 여름학기 때 수강한 데이터 분석 과목 첫 수업 때, 교수님께서 과정을 설명하시던 중 과제 중 하나로 Term Project가 있다는 것을 들었다. 주제를 하나 선정해서 관련한 데이터를 분석하고 그 결과를 발표하는 것이 프로젝트 내용이었다. 이후 구글링하면서 주제를 생각해보다가 며칠 전에 알고리즘으로 뜬 유튜브 영상이 떠올랐다.
 "이 영상에 좋아요를 눌러주세요" ('스토리' 제작)
"이 영상에 좋아요를 눌러주세요" ('스토리' 제작)
해당 영상은 좋아요를 누르는 것을 통해 한층 더 깨끗한 유튜브를 만들어 우리나라 유튜브의 수준을 조금이라도 더 향상시키고자 만들어졌다고 한다. 다만 영상에서는 단순히 우리나라와 해외 영상의 조회수 대비 좋아요 비율을 각각 몇 개만 비교한 것으로 끝났는데, 과연 국가별로 각각 몇 천, 몇 만 개의 영상을 비교했을 때 조회수 대비 좋아요 비율의 차원에서 유의미한 차이가 있을까 생각하였고 이를 주제로 데이터를 분석하기로 했다.
본론
1. 데이터 선정
유튜브 영상 정보와 관련한 데이터는 kaggle의 YouTube Trending Video Dataset 페이지에서 내려받아 사용했다. YouTube Trending(국내명 '인기 급상승 동영상')은 매 15분마다 신규 동영상 중 조회수, '온도'(조회수 상승 속도) 등을 반영했을 때 높은 점수를 얻은 영상을 모아놓은 사이트이다 (YouTube 고객센터 참조.)
Trending에서는 보통 조회수가 높은 영상이 개제되는 경향이 있으며, 고객센터의 내용에 따르면 개제된 영상은 모든 사람에게 노출된다고 하므로 많은 사람들이 해당 영상들을 시청했을 것이다. 또한 Trending에 개제된 영상은 국가마다 다르다고 하므로 각 국가별 Trending에 개제된 영상의 평균 조회수 대비 좋아요 비율은 서로 다를 수 있다고 생각했다. 따라서 데이터 분석용으로 해당 데이터베이스를 선택했다.
2. 데이터 분석 - 이론
2-1. Research Question
α=0.05에서(95% 이상의 확률로) 우리나라의 평균 조회수 대비 좋아요 비율이 미국보다 더 작다고 할 수 있는가?
우리나라와 비교할 대조군으로 미국을 골랐는데, 유튜브에서도 영어 영상을 비교 대상으로 한 것도 있고 당시 미국 대학에서 단기유학으로 수강했기 때문이다 (한국에서 온라인으로 들었지만...)
2-2. 유효성 검증 5단계
2-2-1. 가설 설정
한국과 미국의 평균 조회수 대비 좋아요 비율을 각각 라 했을 때, 질문에 대해서 다음 가설을 제시했다.
- (null hypothesis, 귀무가설) : (각 국가 간 평균 조회수 대비 좋아요 비율이 같다.)
- (alternative hypothesis, 대립가설) : (한국의 평균 조회수 대비 좋아요 비율이 미국보다 작다.)
여기서 α값은 귀무가설(H0)을 기각할 수 있는지, 아니면 할 수 없는지(대립가설을 기각하는 것이 아니다. 대립가설을 기각하려면 몇 가지 과정이 더 필요하다.)를 판별하는 값이다. 만약 p값(두 국가의 좋아요 비율이 서로 일치할 확률)이 α=0.05보다 작으면 귀무가설을 기각할 수 있고, 반대로 α보다 크면 기각할 수 없다.
2-2-2. 적절한 test statistic 선택하기
같은 주제(조회수 대비 좋아요 비율)에 대해 두 가지 샘플(한국, 미국)을 비교할 것이므로 Two samples test로 진행하였다. 두 국가의 좋아요 비율 샘플 평균, 샘플 표준편차, 샘플 개수를 각각 이라 한다면 다음과 같이 t값과 자유도(df, degrees of freedom)를 설정할 수 있다.
- (w는 임의의 문자)
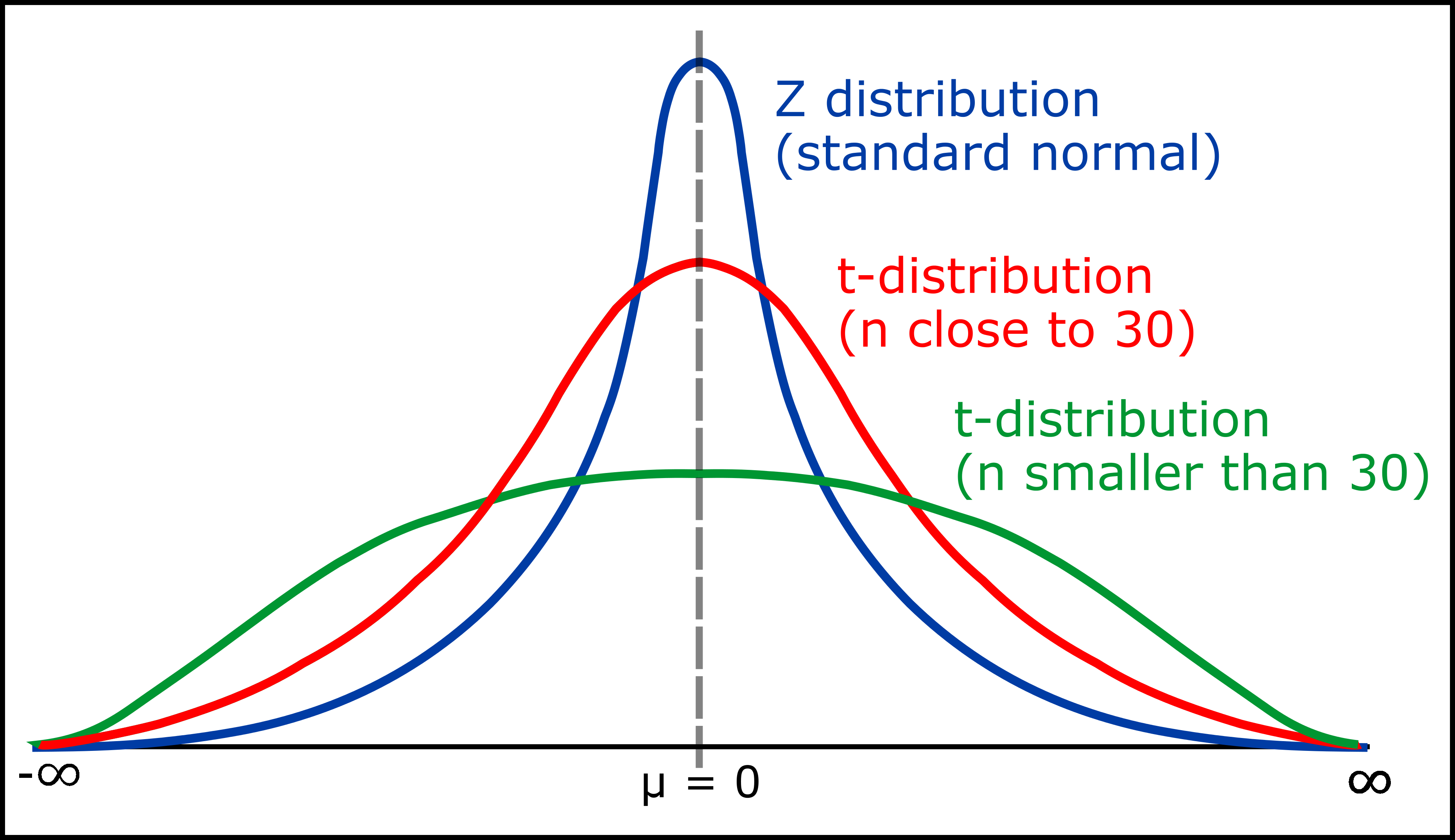 Z 분포와 t 분포 (n값이 높을수록 t분포가 Z 분포에 가까워진다)
Z 분포와 t 분포 (n값이 높을수록 t분포가 Z 분포에 가까워진다)
여기서 t값과 자유도는 t 검정(t-statistics)을 하기 위해 사용되는 값이다. 샘플 수가 무한한 경우 Z 검정을 사용할 수 있지만 해당 샘플(영상 정보)은 아무리 많아도 개수가 정해져 있으므로 t 검정을 사용하는 것이 더 적절하다. t값과 자유도는 R에서 알아서 계산되므로 식을 외우지 않아도 된다.
2-2-3. Decision rule 정하기
α값과 자유도(df)를 이용하여 구한 임계값(critical value)을 정하는 단계이다. 여기서는 에서 , 즉 left one-sided하므로 left hand tail probability는 그대로 α=0.05이다 (만약 , 즉 two-sided하다면 left hand tail probability는 2로 나눠 α/2=0.025로 계산해야 한다.) 그렇게 하여 구한 임계값을 c라고 할 때 t가 c 이하라면() 을 기각할 수 있다. 그 반대라면 을 기각할 수 없다.
2-2-4. t값 구하기
해당 단계에서는 계산을 통해 t값을 구한다. 이때 R 또는 Python 등을 이용하여 t값을 구하고 2-2-3 항목에서 구한 임계값(c)과 비교한다.
2-2-5. 결론
2-2-3 항목에서 구한 임계값(c)과 2-2-4 항목에서 구한 t값을 비교하여 을 기각할 수 있는지 결정하는 단계이다. 여기서 이 기각되면 우리나라의 조회수 대비 좋아요 비율이 미국보다 작다는 것으로 해석될 수 있다.
3. 데이터 분석 - 실전
3-1. 데이터 다운로드
kaggle에서 데이터베이스를 내려받을 때 직접 다운로드해도 좋고 api를 이용해도 괜찮다. 나는 RStudio를 이용하기 때문에 데이터베이스를 직접 내려받았다. API와 Colab을 이용한다면 다음 블로그들을 참고하면 좋겠다. 참고로 나는 2021년 11월 9일 오후 9-10시 기준 데이터베이스를 사용했다.
- API를 이용한 데이터베이스 다운로드 방법: https://jaaamj.tistory.com/141
- Colab 내 Python 모델에서 R 실행하기(rpy2 패키지): https://lunch-box.tistory.com/130 (블로그 내용의 2번째 방법 사용)
데이터베이스 다운로드 이후 곧바로 3-2의 코드를 실행하면
Error in read.table(file = file, header = header, sep = sep, quote = quote, : more columns than column names위와 같은 에러가 발생할 수 있다. 이때는 각 csv 파일을 utf-8 형식에서 ANSI 형식으로 일일이 바꿔야 한다 (다음 링크 참조.)
3-2. 데이터 추출
# 패키지 임포트
#install.packages("dplyr")
#install.packages("ggplot2")
library(dplyr)
library(ggplot2)
# 변수 설정(조회수 분석 및 two samples test용)
csvKR <- read.csv("KR_youtube_trending_data.csv",encoding='utf-8')
csvUS <- read.csv("US_youtube_trending_data.csv",encoding='utf-8')
# 영상별 최신 정보(조회수가 가장 많은 정보)만으로 추출
csvKR <- csvKR %>% arrange(trending_date) %>% group_by(video_id)%>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvUS <- csvUS %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()여기서 두 국가의 데이터베이스를 trending_date(YouTube Trending에 기록된 날짜)값 순서대로 정렬한 후, video_id(영상 ID)에 따라 마지막으로 YouTube Trending에 기록된 영상의 trending_date, title, view_count, likes 값을 추출한다.
# 조회수가 없는 데이터 삭제 및 조회수 대비 좋아요 비율 컬럼 추가
csvKR <- csvKR %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvUS <- csvUS %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)이후 view_count값이 0인 정보를 삭제하고 조회수 대비 좋아요 비율(likes.per.views, 단위: %) 값을 추가했다.
3-3. 데이터 시각화 및 분석
# 그래프에서의 색상별 분류를 위해 국가별 데이터베이스를 하나로 합치기
## 각 국가별 데이터베이스에 국가 분류 추가
csvKR <- csvKR %>% mutate(trended_nation = "KR")
csvUS <- csvUS %>% mutate(trended_nation = "US")
## 하나로 합치기
infoKRUS <- rbind(csvKR, csvUS)그래프를 국가별로 나타내기 위해 국가 컬럼(trended_nation)을 추가했고 하나의 데이터베이스로 합쳤다.
# 이상값 제거 전 한미 간 조회수 대비 좋아요 비율 비교
## 그래프 프레임 제작
gg_krus_bo <- ggplot() +
labs(title="\"Likes/Views\" Comparison in YouTube Trending Videos\nbetween South Korea and the United States (Before Removing Outliers)",
x="Likes/Views (%)",y="The Number of Videos", fill="Country", color="Country") +
scale_x_continuous(breaks=seq(-0.25,35.25,1), labels = 0:35) +
theme_bw()
## 데이터 추가
gg_krus_bo <- gg_krus_bo +
geom_histogram(data=subset(infoKRUS, trended_nation == "KR"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2) +
geom_histogram(data=subset(infoKRUS, trended_nation == "US"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2)
## 그래프 출력
gg_krus_bo
이후 위 코드를 실행하면 위와 같은 그래프가 만들어진다. 오른쪽이 완만한(right-skewed) 형태를 유지했어도 전체적으로 2개 이상의 종 모양이 만들어지지 않았으므로 이상값(Outliers)을 제거해도 무방하다고 판단했다. 따라서 이상값 제거 후 그래프를 제작하면 아래와 같은 그래프가 형성된다.
# 국가별 데이터의 이상값 제거 후 하나로 합치기
## 이상값 제거
csvKR2 <- csvKR %>% subset(likes.per.views<boxplot(csvKR$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvKR$likes.per.views)$stats[1,1]) %>% arrange(desc(likes.per.views))
csvUS2 <- csvUS %>% subset(likes.per.views<boxplot(csvUS$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvUS$likes.per.views)$stats[1,1]) %>% arrange(desc(likes.per.views))
## 하나로 합치기
infoKRUS2 <- rbind(csvKR2, csvUS2)
# 이상값 제거 후 한미 간 조회수 대비 좋아요 비율 비교
## 그래프 프레임 제작
gg_krus_ao <- ggplot() +
labs(title="\"Likes/Views\" Comparison in YouTube Trending Videos\nbetween South Korea and the United States (After Removing Outliers)",
x="Likes/Views (%)",y="The Number of Videos", fill="Country", color="Country") +
scale_x_continuous(breaks=seq(-0.25,35.25,1), labels = 0:35) +
theme_bw()
## 데이터 추가
gg_krus_ao <- gg_krus_ao +
geom_histogram(data=subset(infoKRUS2, trended_nation == "KR"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2) +
geom_histogram(data=subset(infoKRUS2, trended_nation == "US"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2)
## 그래프 출력
gg_krus_ao
다음으로 국가 간 좋아요 비율의 차이를 분석하자. 다음 코드로 test statistic을 진행할 수 있다.
# Test Statistic 실행
test <- t.test(csvKR2$likes.per.views, csvUS2$likes.per.views, alternative="less",conf.level = 0.95)
test
# critical value값 출력
qt(0.05,df=test$parameter)> # Test Statistic 실행
> test <- t.test(csvKR2$likes.per.views, csvUS2$likes.per.views, alternative="less",conf.level = 0.95)
> testWelch Two Sample t-test data: csvKR2$likes.per.views and csvUS2$likes.per.views t = -112.06, df = 21759, p-value < 2.2e-16 alternative hypothesis: true difference in means is less than 0 95 percent confidence interval: -Inf -2.869595 sample estimates: mean of x mean of y 1.846142 4.758487> # critical value값 출력
> qt(0.05,df=test$parameter)[1] -1.644924
위 결과에서 t값은 -112.06으로, 자유도는 21759으로 나타났다. 이때의 임계값(c, α=0.05 기준)은 -1.644924로 나타났다. 즉 를 만족하므로 을 기각할 수 있다. 이는 Research Question에 대해 95% 이상의 확률(정확히는 이상의 확률)로 우리나라의 조회수 대비 좋아요 비율이 미국보다 작다는 것으로 해석할 수 있다.
추가적으로 한국과 미국의 조회수 대비 좋아요 비율의 평균은 각각 1.846142%, 4.758487%이다.
결론
1. 정리
- 한국과 미국 YouTube Trending에 개제된 영상의 조회수 대비 좋아요 비율의 평균은 각각 1.846142%, 4.758487%이다.
- 이상(거의 100%)의 확률로 우리나라의 조회수 대비 좋아요 비율이 미국보다 작다.
- 이때의 t값은 -112.06이며, α=0.05, df=21759일 때의 임계값(c)은 -1.644924이다.
결론적으로 맨 위의 영상에서 제시한 것처럼 우리나라의 조회수 대비 좋아요 비율이 미국보다 작다는 것이 확인되었다. 다만 다음과 같은 한계점이 존재한다.
2. 한계 및 추후 과제
2-1. 조회수 대비 좋아요 비율과 좋아요를 누르는 빈도 사이의 연관성
두 국가 간에 조회수 대비 좋아요 비율이 차이가 난다는 것은 확인했지만, 이것이 반드시 한국인이 좋아요를 잘 누르지 않는다는 것으로 이어지는 것은 아니다. 좋아요는 한 사람당 한 번 밖에 누를 수 없지만, 영상은 여러 번 시청할 수 있다는 점 때문이다. 이러한 문제를 해결하기 위해서는 조회수를 중복 시청을 제외한 값으로 수정한 다음 비율을 다시 계산해서 비교해야 한다.
2-2. 영상 조회수가 갖는 허점
 "치즈분수 치킨과 함께 먹방...!!" ('Tasty Hoon 테이스티훈' 제작)
"치즈분수 치킨과 함께 먹방...!!" ('Tasty Hoon 테이스티훈' 제작)
다른 한계점은 한 국가의 시청자를 대상으로 영상을 만들었을지라도 그 영상이 100% 그 국가에서만 시청된다는 것은 아니라는 점이다. 위의 치즈분수 영상에서도 외국 유저가 적은 영어 댓글을 간간히 볼 수 있다는 것이 그 예이다. 그렇다고 정확한 비율이 위에서 계산한 좋아요 비율과는 크게 차이가 나지 않을 것이다. 다만 국가별 조회수 대비 좋아요 비율을 정확히 계산하기 위해서는 영상별로 조회수 비중이 어느 국가에서 시청됐는지 나타내는 정보를 찾아야 할 것이다.
3. 마지막으로
위 두 가지 한계점 이외에도 계산하는 과정에서 다른 문제점이 있을 수 있다. 만약 다른 문제점을 찾았다면 아래 댓글로 적어주길 바라겠다. 적어놓은 코드 전체와 다른 국가의 좋아요 비율 관련 그래프로 마무리하며 마치고자 한다.
별첨
그래프
 이상값 제거 전 국가 간 조회수 대비 좋아요 비율 분포 비교
이상값 제거 전 국가 간 조회수 대비 좋아요 비율 분포 비교
 이상값 제거 후 국가 간 조회수 대비 좋아요 비율 분포 비교
이상값 제거 후 국가 간 조회수 대비 좋아요 비율 분포 비교
여기서 kaggle의 데이터베이스에 나온 국가는 브라질(BR), 캐나다(CA), 독일(DE), 프랑스(FR), 영국(GB), 인도(IN), 일본(JP), 한국(KR), 멕시코(MX), 러시아(RU), 미국(US)이다.
전체 코드
install.packages("dplyr")
install.packages("ggplot2")
library(dplyr)
library(ggplot2)
# 변수 설정(조회수 분석 및 two samples test용)
csvKR <- read.csv("KR_youtube_trending_data.csv",encoding='utf-8')
csvUS <- read.csv("US_youtube_trending_data.csv",encoding='utf-8')
# 변수 설정(이외 조회수 분석용)
csvBR <- read.csv("BR_youtube_trending_data.csv",encoding='utf-8')
csvCA <- read.csv("CA_youtube_trending_data.csv",encoding='utf-8')
csvDE <- read.csv("DE_youtube_trending_data.csv",encoding='utf-8')
csvFR <- read.csv("FR_youtube_trending_data.csv",encoding='utf-8')
csvGB <- read.csv("GB_youtube_trending_data.csv",encoding='utf-8')
csvIN <- read.csv("IN_youtube_trending_data.csv",encoding='utf-8')
csvJP <- read.csv("JP_youtube_trending_data.csv",encoding='utf-8')
csvMX <- read.csv("MX_youtube_trending_data.csv",encoding='utf-8')
csvRU <- read.csv("RU_youtube_trending_data.csv",encoding='utf-8')
csvUS <- read.csv("US_youtube_trending_data.csv",encoding='utf-8')
# 영상별 최신 정보(조회수가 가장 많은 정보)만으로 추출
csvKR <- csvKR %>% arrange(trending_date) %>% group_by(video_id)%>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvUS <- csvUS %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvBR <- csvBR %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvCA <- csvCA %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvDE <- csvDE %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvFR <- csvFR %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvGB <- csvGB %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvIN <- csvIN %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvJP <- csvJP %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvMX <- csvMX %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
csvRU <- csvRU %>% arrange(trending_date) %>% group_by(video_id) %>%
summarise(trending_date=last(trending_date), title=last(title),
view_count=last(view_count), likes=last(likes)) %>% distinct()
# 조회수가 없는 데이터 삭제 및 조회수 대비 좋아요 비율 컬럼 추가
csvKR <- csvKR %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvUS <- csvUS %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvBR <- csvBR %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvCA <- csvCA %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvDE <- csvDE %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvFR <- csvFR %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvGB <- csvGB %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvIN <- csvIN %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvJP <- csvJP %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvMX <- csvMX %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
csvRU <- csvRU %>% filter(view_count>0) %>% mutate(likes.per.views = likes/view_count*100)
# 그래프에서의 색상별 분류를 위해 국가별 데이터베이스를 하나로 합치기
## 각 국가별 데이터베이스에 국가 분류 추가
csvKR <- csvKR %>% mutate(trended_nation = "KR")
csvUS <- csvUS %>% mutate(trended_nation = "US")
csvBR <- csvBR %>% mutate(trended_nation = "BR")
csvCA <- csvCA %>% mutate(trended_nation = "CA")
csvDE <- csvDE %>% mutate(trended_nation = "DE")
csvFR <- csvFR %>% mutate(trended_nation = "FR")
csvGB <- csvGB %>% mutate(trended_nation = "GB")
csvIN <- csvIN %>% mutate(trended_nation = "IN")
csvJP <- csvJP %>% mutate(trended_nation = "JP")
csvMX <- csvMX %>% mutate(trended_nation = "MX")
csvRU <- csvRU %>% mutate(trended_nation = "RU")
## 하나로 합치기
infoKRUS <- rbind(csvKR, csvUS)
info <- rbind(csvKR, csvUS)
info <- rbind(info, csvBR)
info <- rbind(info, csvCA)
info <- rbind(info, csvDE)
info <- rbind(info, csvFR)
info <- rbind(info, csvGB)
info <- rbind(info, csvIN)
info <- rbind(info, csvJP)
info <- rbind(info, csvMX)
info <- rbind(info, csvRU)
# 이상값 제거 전 한미 간 조회수 대비 좋아요 비율 비교
## 그래프 프레임 제작
gg_krus_bo <- ggplot() +
labs(title="\"Likes/Views\" Comparison in YouTube Trending Videos\nbetween South Korea and the United States (Before Removing Outliers)",
x="Likes/Views (%)",y="The Number of Videos", fill="Country", color="Country") +
scale_x_continuous(breaks=seq(-0.25,35.25,1), labels = 0:35) +
theme_bw()
## 데이터 추가
gg_krus_bo <- gg_krus_bo +
geom_histogram(data=subset(infoKRUS, trended_nation == "KR"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2) +
geom_histogram(data=subset(infoKRUS, trended_nation == "US"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2)
## 그래프 출력
gg_krus_bo
# 국가별 데이터의 이상값 제거 후 하나로 합치기
## 이상값 제거
csvKR2 <- csvKR %>% subset(likes.per.views<boxplot(csvKR$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvKR$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvUS2 <- csvUS %>% subset(likes.per.views<boxplot(csvUS$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvUS$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvBR2 <- csvBR %>% subset(likes.per.views<boxplot(csvBR$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvBR$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvCA2 <- csvCA %>% subset(likes.per.views<boxplot(csvCA$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvCA$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvDE2 <- csvDE %>% subset(likes.per.views<boxplot(csvDE$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvDE$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvFR2 <- csvFR %>% subset(likes.per.views<boxplot(csvFR$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvFR$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvGB2 <- csvGB %>% subset(likes.per.views<boxplot(csvGB$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvGB$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvIN2 <- csvIN %>% subset(likes.per.views<boxplot(csvIN$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvIN$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvJP2 <- csvJP %>% subset(likes.per.views<boxplot(csvJP$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvJP$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvMX2 <- csvMX %>% subset(likes.per.views<boxplot(csvMX$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvMX$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
csvRU2 <- csvRU %>% subset(likes.per.views<boxplot(csvRU$likes.per.views)$stats[5,1] & likes.per.views>boxplot(csvRU$likes.per.views)$stats[1,1]) %>%
arrange(desc(likes.per.views))
## 하나로 합치기
infoKRUS2 <- rbind(csvKR2, csvUS2)
info2 <- rbind(csvKR2, csvUS2)
info2 <- rbind(info2, csvBR2)
info2 <- rbind(info2, csvCA2)
info2 <- rbind(info2, csvDE2)
info2 <- rbind(info2, csvFR2)
info2 <- rbind(info2, csvGB2)
info2 <- rbind(info2, csvIN2)
info2 <- rbind(info2, csvJP2)
info2 <- rbind(info2, csvMX2)
info2 <- rbind(info2, csvRU2)
# 이상값 제거 후 한미 간 조회수 대비 좋아요 비율 비교
## 그래프 프레임 제작
gg_krus_ao <- ggplot() +
labs(title="\"Likes/Views\" Comparison in YouTube Trending Videos\nbetween South Korea and the United States (After Removing Outliers)",
x="Likes/Views (%)",y="The Number of Videos", fill="Country", color="Country") +
scale_x_continuous(breaks=seq(-0.25,35.25,1), labels = 0:35) +
theme_bw()
## 데이터 추가
gg_krus_ao <- gg_krus_ao +
geom_histogram(data=subset(infoKRUS2, trended_nation == "KR"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2) +
geom_histogram(data=subset(infoKRUS2, trended_nation == "US"),binwidth = 0.5,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0.2)
## 그래프 출력
gg_krus_ao
# Test Statistics 실행
test <- t.test(csvKR2$likes.per.views, csvUS2$likes.per.views, alternative="less",conf.level = 0.95)
test
# critical value값 출력
qt(0.05,df=test$parameter)
# YouTube Trending 운영 국가
country_list = c("BR", "CA", "DE", "FR", "GB", "IN", "JP", "KR", "MX", "RU", "US")
# 이상값 제거 전 국가 간 조회수 대비 좋아요 비율 비교
## 그래프 프레임 제작
gg_global_bo <- ggplot() +
labs(title="\"Likes/Views\" Comparison in YouTube Trending Videos\nbetween 11 countries (Before Removing Outliers)",
x="Likes/Views (%)",y="The Number of Videos", fill="Country", color="Country") +
scale_x_continuous(breaks=seq(0,90,10), labels = (0:9)*10) +
theme_bw() +
scale_fill_brewer(palette="Set3") +
scale_color_brewer(palette="Set3")
## 국가별 데이터 추가
for (i in 1:length(country_list)){
gg_global_bo <- gg_global_bo +
geom_density(data=subset(info, trended_nation == country_list[i]), size=1,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0)}
## 그래프 출력
gg_global_bo
# 이상값 제거 후 국가 간 조회수 대비 좋아요 비율 비교
## 그래프 프레임 제작
gg_global_ao <- ggplot() +
labs(title="\"Likes/Views\" Comparison in YouTube Trending Videos\nbetween 11 countries (After Removing Outliers)",
x="Likes/Views (%)",y="The Number of Videos", fill="Country", color="Country") +
scale_x_continuous(breaks=seq(0,27,1), labels = 0:27) +
theme_bw() +
scale_fill_brewer(palette="Set3") +
scale_color_brewer(palette="Set3") +
geom_line(size=1)
## 국가별 데이터 추가
for (i in 1:length(country_list)){
gg_global_ao <- gg_global_ao +
geom_density(data=subset(info2, trended_nation == country_list[i]), size=1,
aes(x=likes.per.views, fill=trended_nation, color=trended_nation),
alpha=0)}
## 그래프 출력
gg_global_ao
멋있어요