1. 어떤 상황인가?
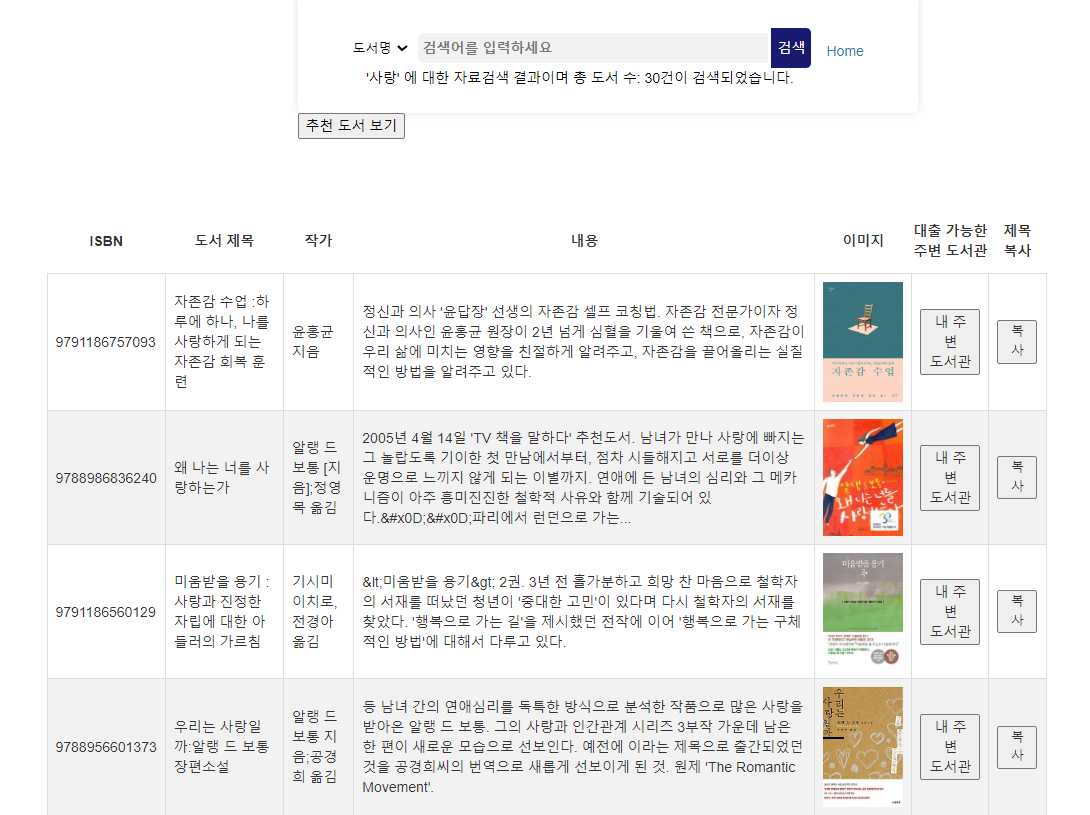
우리 도서 검색 서비스는 검색 품질을 위해 서울 전국 도서관의 대출 횟수를 합산하여 각각의 책마다 대출 횟수 데이터를 가지고 있다. 이를 통해 사용자가 검색 시 대출 횟수를 기준으로 내림 차순으로 검색 결과를 보여 준다.
2. 그래서 뭐가 문제인가?
select *
from book_final
where match(title_token) against('사랑' in boolean MODE)
order by loan_cnt desc ;따라서 대출 횟수(loan_cnt)를 order by를 통해서 검색 쿼리를 날리게 되는데, 검색 결과가 많지 않은 경우에는 크게 성능 문제가 없지만 위의 사진과 같이 '사랑'과 같이 포괄적인 키워드를 검색하게 되면 2만 7천이 검색되고 그결과 10초를 초과하는 성능 저하 이슈를 보였다.
더욱 더 문제는 order by에 인덱스를 설정해도 full text index를 검색하게 되면 다시 정렬 작업을 수행 해야하기 때문에 걸어놓은 order by 인덱스를 전혀 작동하지 않았다.
3. 그래서 어떻게 해결 했는가?
- DB에 csv file을 import하는 순간부터 대출 횟수 기준으로 내림차순으로 정렬된 데이터를 넣으면 되지 않을까?
-> 실험을 해본 결과 가능성이 보였다.
그래서 먼저 DB에서 Java단으로 데이터를 읽어 올 때, order by를 적용해서 가져 왔다.
// csv file로 변환 할 때 사용하기 위한 메소드.
public Page<Book> findAllAndSort(Pageable pageable){
JPAQuery<Book> books = factory
.selectFrom(book)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(book.loanCnt.desc());
return PageableExecutionUtils.getPage(
books.fetch(),
pageable, () -> countQueryAll().fetchOne());
}그리고 out of memory를 피하기 위해 50만개씩 페이징으로 끊어서 읽어 온 뒤 명사 키워드 별로 추출 한 데이터를 기존의 book 데이터에 넣고 다시 Csv file로 export 했다.
public abstract class ExporterService<V,T> {
private final CsvWriter<V> csvWriter;
public void exportToCsv(int pageNumber,int pageSize,String outputName){
Pageable pageable = PageRequest.of(pageNumber, pageSize);
Page<T> page = Page.empty();
do {
List<V> voList = analyzeAndExportVo(pageable,outputName);
csvWriter.writeToCsv(voList, outputName);
page = renewPage();
pageable = pageable.next();
} while (page.hasNext()); // 다음 페이지가 존재하는지 확인
}
abstract List<V> analyzeAndExportVo(Pageable pageable,String outputName);
abstract Page<T> renewPage();
}
public class BookExporter extends ExporterService<BookVo, Book> {
private final TitleAnalyzer titleAnalyzer;
private final BookRepoQueryDsl bookRepository;
private Page<Book> page;
public BookExporter(CsvWriter<BookVo> csvWriter,
TitleAnalyzer titleAnalyzer, BookRepoQueryDsl bookRepository) {
super(csvWriter);
this.titleAnalyzer = titleAnalyzer;
this.bookRepository = bookRepository;
this.page = Page.empty();
}
@Override
List<BookVo> analyzeAndExportVo(Pageable pageable, String outputName) {
// 대출 횟수(loan_cnt) 기준으로 내림 차순으로 데이터를 입력하고,
// 실제 작업을 수행하기 위해 DB에서 Java단으로 데이터를 가져온다
this.page = bookRepository.findAllAndSort(pageable);
List<BookVo> books = new ArrayList<>();
page.stream().forEach(book -> {
TitleQuery query = titleAnalyzer.analyze(book.getTitle(), false);
books.add(new BookVo(book, String.join(" ", query.getNnToken())));
});
pageable.next(); // 다음 페이지를 가져오기 위한 설정
return books;
}
public Page<Book> renewPage() {
return page;
}
}4. 그래서 성과가 있었나?
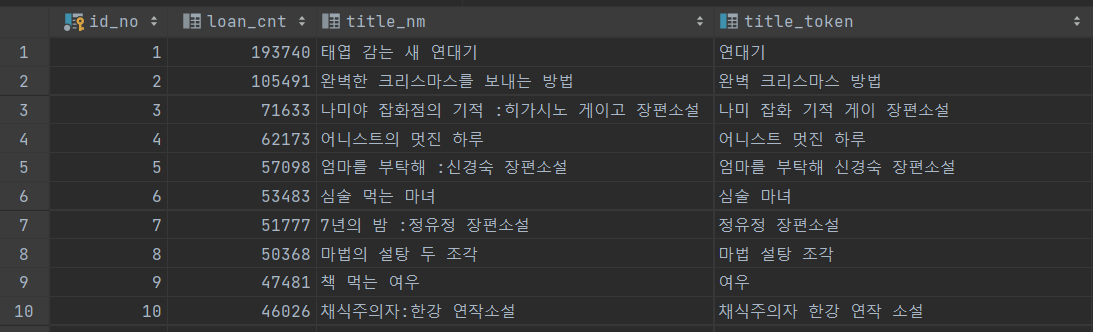
- loan_cnt 순으로 데이터가 입력 돼 있다.
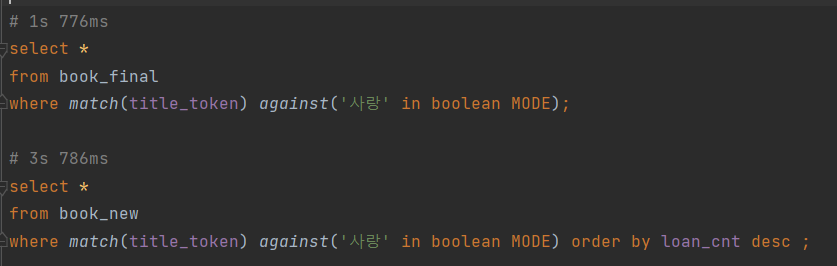

- 이제는 order by를 하지 않아도 full text search의 결과 값이 loan_cnt에 의해 내림 차순 정렬 돼 있다.

좋은 영향력과 교류를 위하여
소중한 정보 감사드립니다!