https://okky.kr/articles/1460429
오키에 서비스에 대한 피드백 요청을 올렸습니다.
친절하게도 오키 사용자 분들이
서비스에 대한 피드백을 주셔서, 그 개선기를 정리해서 올리고자 합니다.
1.ConvertFilter 와 관련하여 KeywordService DB 모아서 찌르기.
이 내용은 검색 엔진 기능 중 [한글을 영어로 잘못 입력 했을 때, 교정 해주는 기능]과 관련 된 내용이다.
어떤 상황인가?
public String filtering(String query) {
StringJoiner joiner = new StringJoiner(" ");
Arrays.stream(query.split(" "))
.forEach(word -> {
if (isEnglishWord(word) && !keywordService.isExistKeyword(word)) {
convertAndAddKoreanWord(word, joiner);
} else {
joiner.add(word);
}
});
return progressFilter(joiner.toString(), this.nextFilter);
}관련 코드는 입력 받는 사용자 검색어를 공백으로 쪼개서 영어 단어이고 keyword_dic table에 존재하는 단어인지를 확인하여 존재하지 않으면 변환 한 뒤 그 변환 된 단어가 다시 존재 하는지를 찾음으로써 입력 된 검색어가 잘못 됐는지를 찾는다.
keyword_dic table은 대략 이렇다.
어떤 문제가 있나?
검색 창에 'wkqk tmvmfld wkqk' (자바 스프링 자바)를 치게 되면
Hibernate:
select
keyword0_.id_no as col_0_0_
from
keyword_dic keyword0_
where
keyword0_.keyword=? limit ?
Hibernate:
select
keyword0_.id_no as col_0_0_
from
keyword_dic keyword0_
where
keyword0_.keyword=? limit ?자동 완성과 검색 결과를 포함해서 keywordService가 DB에 쿼리를 무려 13번을 찌른다...(와우...;; 고마 해라~ 마이 묵었다 아이가)
어떻게 해결 했는가?
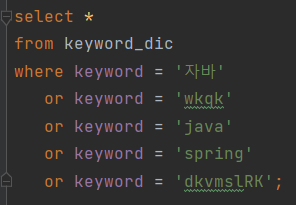
쿼리를 한번에 모아서 보내고, 그 결과값을 가지고 서버에서 판단하자!
public class KeywordQueryDsl {
private final JPAQueryFactory factory;
public List<Keyword> getKeywords(String... words) {
if(words.length == 0){
return Collections.emptyList();
}
BooleanBuilder builder = new BooleanBuilder();
Arrays.stream(words).forEach(
word -> builder.or(keyword1.keyword.eq(word)));
return factory
.selectFrom(keyword1)
.where(builder).fetch();
}
}Data JPA를 이용하던 repository 대신 queryDsl을 이용해서 BooleanBuilder를 통해서 매개 변수로 들어오는 words에 의해서
where or 절을 동적으로 만든다.
public String filtering(String query) {
StringJoiner joiner = new StringJoiner(" ");
List<String> requiredCheckList = new LinkedList<>();
Arrays.stream(query.split(" "))
.forEach(word -> {
if (isEnglishWord(word)) {
convertAndAddCheckList(word, requiredCheckList);
} else {
joiner.add(word);
}
});
joiner.add(String.join(" ", keywordService.getExistKeywords(requiredCheckList)));
return progressFilter(joiner.toString(), this.nextFilter);
}
private void convertAndAddCheckList(String originalWord, List<String> requiredCheckList) {
String convertedWord = EngToKorConverter.convert(originalWord);
requiredCheckList.add(originalWord);
requiredCheckList.addAll(EunjeonTokenizer.getQualifiedNnTokens(convertedWord));
}convertFilter는 영어 단어인 것을 위주로 원본 단어와 변환 한 단어를 List에 넣고,
keywordService한테 보낸다.
그걸 받은 keywordService는 queryDsl로 부터 DB에 존재하는 유효한 keyword들로 바꿔서 반환 해준다.
그래서 결과는??
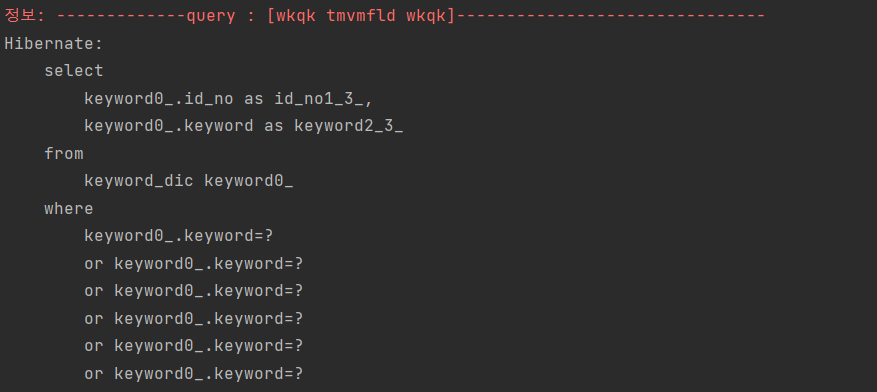
13번 쿼리를 보내던 것이 1번으로 바뀌었다..!
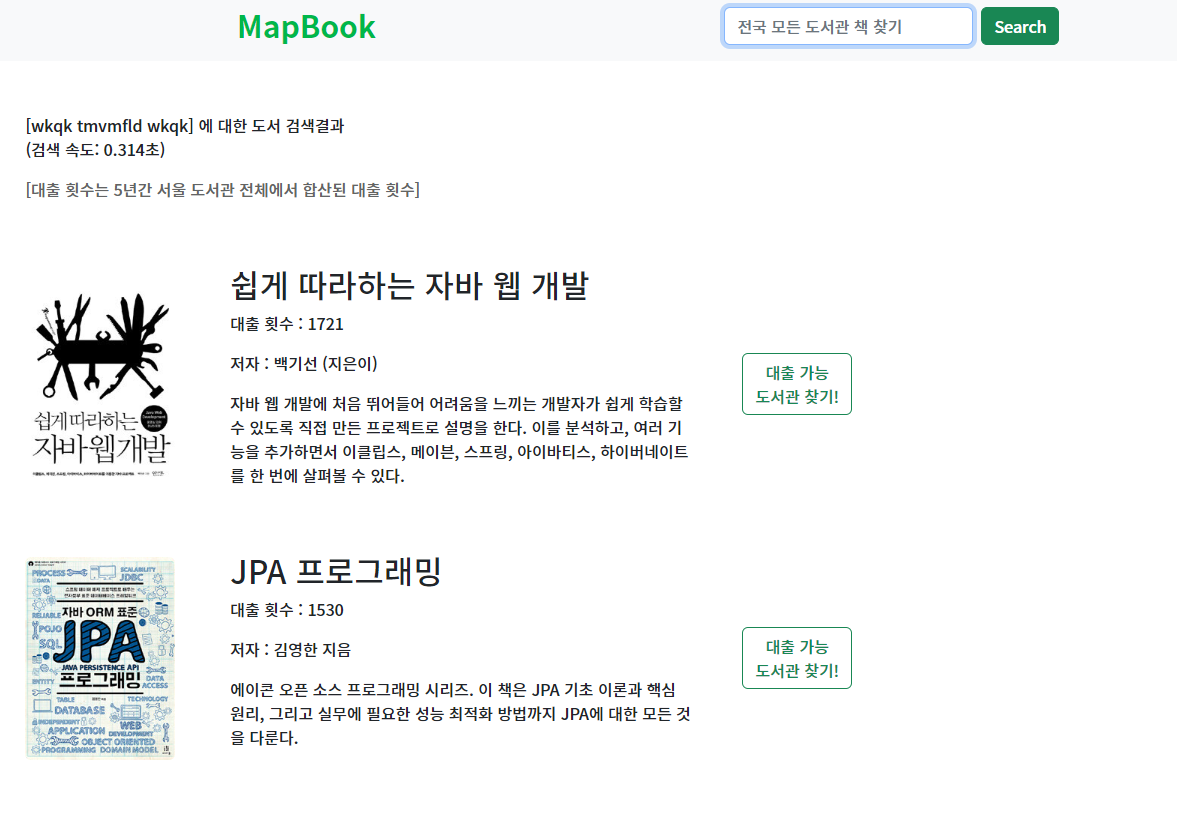
결과도 동일!
추가된 피드백
위에서 or절을 써서 문제를 해결 했는데, 우리 친절하신 선배 개발자 분께서 in절을 활용하는 쪽이 성능이나 코드 간결성에 있어서 더 좋을 것이라고 조언 하셨다.
내가 아는 지식에선 or절도 옵티마이저가 in 절로 바꿔서 쿼리를 날린다고 알고 있었는데, 내가 잘못 알고 있었나 보다. 그렇다면 실험 해보자..!
일단 기존에 booleanBuilder로 or절을 날리던 getKeywordsOr를 냅두고, 실험을 위해 데이터를 가져올 getKeywords 메소드와 In절을 날릴 getKeywordIn 메소드를 준비 한다.
public class KeywordQueryDsl {
private final JPAQueryFactory factory;
public List<Keyword> getKeywords(long limit){
return factory.selectFrom(keyword1).limit(limit).fetch();
}
public List<Keyword> getKeywordsOr(String... words) {
if(words.length == 0){
return Collections.emptyList();
}
BooleanBuilder builder = new BooleanBuilder();
Arrays.stream(words).forEach(
word -> builder.or(keyword1.keyword.eq(word)));
return factory
.selectFrom(keyword1)
.where(builder).fetch();
}
public List<Keyword> getKeywordsIn(String... words) {
if(words.length == 0){
return Collections.emptyList();
}
return factory
.selectFrom(keyword1)
.where(keyword1.keyword.in(words)).fetch();
}
}자 이제 테스트 코드를 준비 하자. setUp으로 데이터 세팅하고, 스프링 유틸의 stopWatch를 각각 준비해서 시작 해보자! (참고로 limit 값이 1300 이상되면 stack over flow가 뜬다...)
@SpringBootTest
class KeywordQueryDslTest {
@Autowired
KeywordQueryDsl keywordQueryDsl;
List<String> testSource;
@BeforeEach
void setUp() {
this.testSource = keywordQueryDsl.getKeywords(1000).stream()
.map(Keyword::getKeyword).toList();
}
@Test
public void inAndorPerformanceTest() {
StopWatch stopWatch2 = new StopWatch();
stopWatch2.start();
keywordQueryDsl.getKeywordsIn(testSource.toArray(String[]::new));
stopWatch2.stop();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
keywordQueryDsl.getKeywordsOr(testSource.toArray(String[]::new));
stopWatch.stop();
System.out.println("or 절 걸린 시간 : "+stopWatch.getTotalTimeMillis()+"ms");
System.out.println("in 절 걸린 시간 : "+stopWatch2.getTotalTimeMillis()+"ms");
}일단 1개의 키워드를 대상으로 했을 때, 신기하게도 or절이 10배 빨랐다.





오차 범위일까??? 어쩔 땐 in절이 빠르고 어쩔 떈 or절이 빠르다. 그래프로 나타내고 보자...!
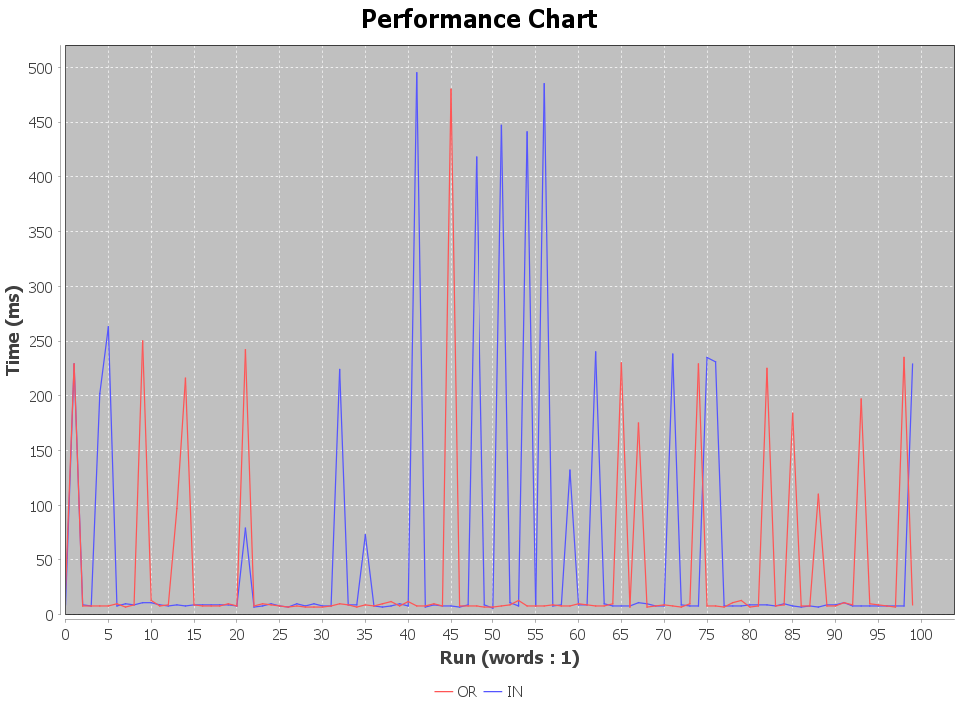
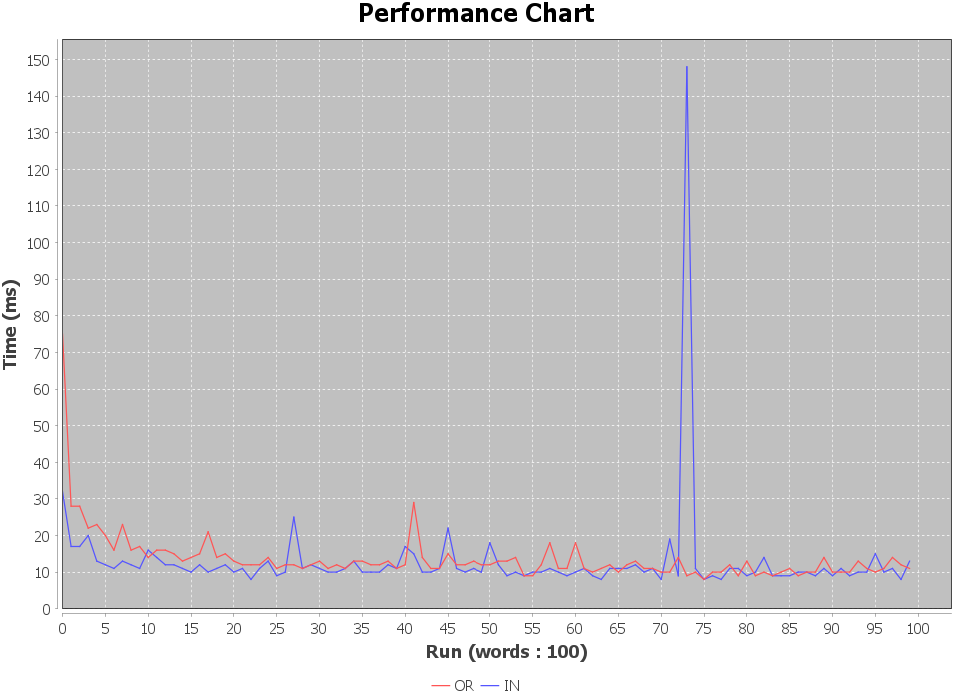
별로 의미 없는 것 같아. 평균 값으로 전환/ 그 중에서 가장 빈번한 케이스인 word 갯수가 3개 일때를 여러번 봤다.

in 절 WIN!!
public class KeywordQueryDsl {
private final JPAQueryFactory factory;
public List<Keyword> getKeywords(String... words) {
return words.length == 0 ? Collections.emptyList() :
factory.
selectFrom(keyword1)
.where(
keyword1.keyword.in(words))
.fetch();
}
}