The total number of locks exceeds the lock table size 이슈 해결

https://velog.io/@alpahexia/MapBook-파일-다운로드-자동화
전국 도서관의 각 도서별 대출 횟수를 구하기 위해 도서관 별 장서 목록 데이터를 수집하고, 그 데이터에서 각각의 대출 횟수를 합산 해야 한다. 수집은 위에 링크에서 파일 다운로더를 통해서 14GB의 데이터를 수집 했다.
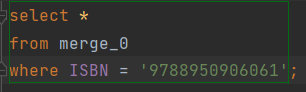
그 전에 서울과 경기 도서관을 한정해서 대출 횟수를 합산 했을 때부터
create table temp_loanCnt
select ISBN, sum(LOAN_CNT)
from loancnt
group by ISBN;GroupBy를 통해 ISBN 별로 대출 횟수(loan_cnt)를 sum 연산을 해서 임시 테이블로 만든 뒤, 그 임시 테이블로 만들어진 데이터를 기존의 Books 테이블에 추가 된 loan_cnt에 업데이트 하는 방식으로 다뤘었다.
하지만 이번엔 1억 2천 만건. 정규화를 거치고 14GB -> 7GB로 변환 된 데이터를 가지고 작업을 하다가 문제가 발생 했다!
어떤 문제인가?

- 3시간 30분을 기다리며 위의 쿼리를 날려 임시 테이블을 만들던 중 아래와 같은 Mysql 에러가 발생 했다
[The total number of locks exceeds the lock table size]
( Mysql 선생님.... 3시간 반을 기다렸어요....)

https://dev.mysql.com/doc/mysql-errors/8.0/en/server-error-reference.html
Mysql 공식 문서에선 innodb buffer pool size를 늘리던지, 더 작은 단위로 쪼개서 작업하라고 얘기 한다.
그리고 구글링 해봐도 오로지 답은 이거다 'my.ini 파일 가서 Buffer Pool size 늘리세요 ^^'
난 그런 대답은 원하는게 아니다...
-
왜 Buffer Pool is full 과 같은 에러가 아니라 전체 lock의 갯수가 lock 테이블 사이즈를 넘겼다는 걸까? lock table size가 뭐지??
-
locks table은 대체 어디에 존재하는 것일까? locks table가 buffer pool size에 있다면, buffer pool size를 높이면 locks table의 사이즈도 증가 될테니 합당해 보이긴 하다. (근데 알아본 봐론 아니다)
-
해당 쿼리가 과연 어떤 단계에서 뻗어서 에러가 난걸까?? Group by로 select해서 buffer pool에 적재 할 때?? 적재는 다 했는데, 이제 새로운 임시 테이블에 insert 하려고 시작 할 때??? 아니면 insert를 쭉 하다가 중간에??
일단 조사해서 내 나름대로 결론을 내린 것은 이러하다.
해당 작업에서 buffer Pool size를 아무리 7GB로 늘렸어(local)도 결국엔 Locks table size 에러가 나왔을 것이라고 예상 된다. (7GB로 늘려서 다시 테스트 해봤지만... 그 시간을 기다리지 못하겠어서 10분만에 포기)
그렇다면 group by로 select 해서 buffer pool엔 담기까지는 성공 했을 것이다. ( 다만 이때 128MB였기 때문에 스왑인/ 스왑 아웃이 빈번하게 일어나서 속도는 계속 저하 됐었을 것이다)
그리고 이제 임시 테이블을 만들고, 각 행마다 lock을 얻으면서 데이터를 넣다가 행마다 얻었던 lock이 한계치 locks table size를 넘어가면서 Mysql이 에러를 뱉어냈다고 판단이 된다. lock을 어떤 트랜잭션이 모두 점유한 상황이 발생 한 것이고 locks table size를 넘긴다는 것은 이 외의 트랜잭션을 지원하지 못하는 상황. DB에게 치명적인 상황이라고 생각된다. 그래서 DB 전체를 위해 에러를 뱉고 lock을 다 점유하던 트랜잭션을 rollback 처리 한 것으로 생각 된다.
그래서 어떻게 해결 했나??
해결은 Java 단에서 해결 했으며, 분할 정복의 느낌으로 해결 했다.
1) LibraryCatalogDivider
7GB로 다 merge된 csv 파일을 다시 1000만 raw 씩 짤라서 파일 12개로 쪼갰다.
public class LibraryCatalogDivider {
private static final int ISBN_IDX = 0;
private static final int LOAN_CNT_IDX = 1;
private static final String DEFAULT_OUTPUT_FORMAT = "%s_%d.csv";
// 큰 용량의 CSV 파일을 분할 작업하기 위한 나누기 메소드
@BatchLogging
public static Path divide(String path, String outPutNm, long maxRecordsPerFile) {
long recordCount = 0; //몇개의 raws를 기록 했는지 저장.
int fileCount = 0; // 나뉘어지는 file 이름에 해당 count를 붙여 file_3의 형식의 file 이름을 만듦
try (Reader reader = Files.newBufferedReader(new File(path).toPath())) {
CSVParser csvParser = CSVFormat.DEFAULT
.withFirstRecordAsHeader()
.parse(reader);
while (csvParser.iterator().hasNext()) {
try (BufferedWriter writer = constructBufferedWriter(outPutNm, fileCount)) {
while (csvParser.iterator().hasNext() && !isEndLine(++recordCount, maxRecordsPerFile)) {
CSVRecord record = csvParser.iterator().next();
writer.write(buildCsvLine(record.get(ISBN_IDX), record.get(LOAN_CNT_IDX)));
writer.newLine();
}
}
fileCount++;
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
return Path.of(outPutNm);
}
// 만약 maxRecord 만큼씩 나눠 파일에 담기 위해
private static boolean isEndLine(long recordCount, long maxRecordsPerFile) {
return recordCount % maxRecordsPerFile == 0;
}
private static LoanCntVo constructLoanCntVo(CSVRecord record) {
return new LoanCntVo(
record.get(ISBN_IDX),
record.get(LOAN_CNT_IDX)
);
}
private static BufferedWriter constructBufferedWriter(String outPutNm, int fileCount)
throws IOException {
String formattingFileNm = String.format(DEFAULT_OUTPUT_FORMAT, outPutNm, fileCount);
return Files.newBufferedWriter(
Paths.get(formattingFileNm),
StandardCharsets.UTF_8
);
}
// csv 파일로 다시 만들기 위해 "," 구분자를 넣어 준다.
private static String buildCsvLine(String... args) {
return String.join(",", args);
}
}
결과적으로 1억 2천 raws의 데이터가 1000만 raws씩 12개 파일로 나뉘었다.
2) LibraryCatalogAggregator
그 이후 1개의 파일 씩 Java 코드를 이용해 객체로 변환해 ISBN을 Key로 Loan_cnt를 value로 삼는 HashMap을 통해 ISBN 별로 loan_cnt를 합산 한다.
// 1억 2천만 대출 횟수 관련 데이터를 분할/합산/병합 프로세스에서 합산을 위한 클래스
@Slf4j
public class LibraryCatalogAggregator {
private static final String HEADER_NAME = "ISBN,LOAN_CNT";
private static final int ISBN_IDX = 0;
private static final int LOAN_CNT_IDX = 1;
private static final String DEFAULT_OUTPUT_FORMAT = "%s_%d.csv";
// 주어진 folder에서 file 마다 작업을 수행.
@BatchLogging
public static Path aggregateLoanCnt(String inPutFolder, String outPutNm, String format) {
AtomicInteger fileCount = new AtomicInteger();
// file마다 ISBN 별로 loan_cnt를 sum 하는 작업을 수행 합니다.
Arrays.stream(getCsvFiles(inPutFolder))
.forEach(file ->
mergeCnt(file, String.format(format, outPutNm, fileCount.getAndIncrement()))
);
return Path.of(outPutNm);
}
private static void mergeCnt(File file, String outPutNm) {
Map<String, Integer> isbnLoanCntMap = new HashMap<>();
try (
Reader reader = Files.newBufferedReader(file.toPath());
BufferedWriter writer = Files.newBufferedWriter(
Paths.get(outPutNm),
StandardCharsets.UTF_8)
) {
// csv file에서 데이터를 읽어 온다.
CSVParser csvParser = CSVFormat.DEFAULT
.withFirstRecordAsHeader()
.parse(reader);
// 읽어온 csv 데이터를 isbn별로 loanCnt를 합산하여 map에 넣는다
csvParser.forEach(record -> sumLoanCntPutMap(record, isbnLoanCntMap));
// 다시 map에 담겨진 데이터를 Csv file로 write하여 outPut 한다.
for (Map.Entry<String, Integer> isbnLoanCntEntry : isbnLoanCntMap.entrySet()) {
writeToCsv(writer, isbnLoanCntEntry);
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
private static void writeToCsv(BufferedWriter writer,
Map.Entry<String, Integer> entry) throws IOException {
String dataLine = buildCsvLine(entry.getKey(), String.valueOf(entry.getValue()));
writer.write(dataLine);
writer.newLine();
}
private static void sumLoanCntPutMap(CSVRecord csvRecord, Map<String, Integer> map) {
String newIsbn = csvRecord.get(ISBN_IDX);
String newLoanCnt = csvRecord.get(LOAN_CNT_IDX);
map.compute(newIsbn, (oldIsbn, oldLoanCnt) ->
(oldLoanCnt == null ? 0 : oldLoanCnt) + Integer.parseInt(newLoanCnt)
);
}
private static String buildCsvLine(String... args) {
return String.join(",", args);
}
private static File[] getCsvFiles(String folder) {
return new File(folder).listFiles();
}
public static String getDefaultOutputFormat(){
return DEFAULT_OUTPUT_FORMAT;
}
}
3) CsvFileMerger
마지막으로 쪼개져 각기 합산 작업인 완료된 파일을 하나로 합친다.
public class CsvFileMerger {
private static final String HEADER_NAME = "ISBN,LOAN_CNT";
private static final String DEFAULT_INPUT_FOLDER = "download\\";
private static final String DEFAULT_OUTPUT_NAME = "input\\step1.csv";
public static void main(String[] args) {
try {
mergeCsvFile("loanSumFile\\", "mergeFile\\result2.csv",0,1);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
// 분할 된 CSV 파일을 다시 병합
public static void mergeCsvFile(String inputFolder, String outPutNm,int... recordIdx)
throws IOException {
log.info("[CsvFileMerger] is start");
File[] files = fileLoad(inputFolder);
AtomicBoolean headerSaved = new AtomicBoolean(false);
try (BufferedWriter writer = Files.newBufferedWriter(
Paths.get(outPutNm+".csv"), StandardCharsets.UTF_8)) {
Arrays.stream(files).forEach(file -> {
List<String> lines = CsvFileReader.readDataLines(file,recordIdx);
writeToCsv(writer, file, headerSaved.get(),lines);
headerSaved.set(true);
});
}
log.info("[CsvFileMerger] is completed");
}
private static void writeToCsv(BufferedWriter writer, File file, boolean headerSaved,List<String> lines) {
try {
if (!headerSaved) {
writer.write(HEADER_NAME);
writer.newLine();
}
for(String line : lines){
writer.write(line);
writer.newLine();
}
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
public static String getDefaultInputFolder(){
return DEFAULT_INPUT_FOLDER;
}
public static String getDefaultOutputName(){
return DEFAULT_OUTPUT_NAME;
}
private static String buildCsvLine(String... args) {
return String.join(",", args);
}
private static File[] fileLoad(String inputFolder) {
return new File(inputFolder).listFiles();
}
private static CSVParser getCsvParser(BufferedReader reader) throws IOException {
return new CSVParser(reader, CSVFormat.DEFAULT);
}
}통합 테스트로 검증
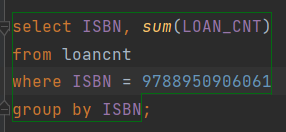
- 분할 작업으로 만들어진 결과를 DB에 import 후 ISBN에 맞게 제대로 합산 됐는지 누락된 데이터는 없는지 확인.

- 아래는 7GB를 그대로 import해서 SQL문으로 합산 했을 때의 ISBN별 Loan_cnt 합산 데이터.

그 이후 과제 - Spring Batch 서버 구축
이 글에서 기술한 작업 내용은 한달에 한번 씩 주기적으로 업데이트 해줘야 하는 작업이다. 그리고 이 데이터를 바탕으로 기존에 있는 도서 테이블에도 새롭게 대출 횟수를 업데이트 해줘야 한다. 더 나아가 새로 도서관에 소장 도서로 등록 되는 도서에 대해서 기존에 구현한 Kakao API를 활용한 도서 업데이터를 통해서도 최신화가 필요하다.
즉, 이런 작업의 자동화가 필요하다. 자동화를 위해서 필요한 컴포넌트는 어느 정도 미리 만들어 놓고, 진행 했기 때문에 Spring Batch를 학습 한 뒤 Batch 서버를 따로 구축해서 이 작업을 자동화 하자.
아래는 로컬에서 위의 프로세스를 한번에 실행하기 위한 Manager 클래스. 이 클래스와 속한 패키지의 패키지들이 아마도 Batch 서버로 옮겨질 것이다.
public class LibraryCatalogManager {
private static final int ISBN_IDX = 0;
private static final int LOAN_CNT_IDX = 1;
private final LibraryCatalogNormalizer normalizer;
private final LibraryCatalogDownloader libraryCatalogDownloader;
private final static String ROOT = "pipe";
private final static String BRANCH = "step";
// targetDate "(2023년 06월)"
@BatchLogging
public void executeProcess(String targetDate) throws IOException {
Path downLoadFolder = executeFilDownload(targetDate);
Path normalizePath = executeNormalizeStep(downLoadFolder);
Path divideStep = executeDivideStep(normalizePath);
Path aggregateStep = executeAggregateStep(divideStep);
executeMergeStep(aggregateStep);
}
private Path executeNormalizeStep(Path downLoadFolder) {
return normalizer.normalize(
downLoadFolder.toString(),
configOutPut(1, "normalFile.csv")
);
}
private Path executeFilDownload(String targetDate) {
return libraryCatalogDownloader.downLoad(ROOT + "/download/", targetDate);
}
private Path executeDivideStep(Path normalizePath) {
return LibraryCatalogDivider.divide(
normalizePath.toString(),
configOutPut(2, "divide"),
10000000
);
}
private Path executeAggregateStep(Path divideStep) {
return LibraryCatalogAggregator.aggregateLoanCnt(
divideStep.subpath(0,2).toString(),
configOutPut(3, "aggregatedFile"),
"%s_%d.csv"
);
}
private void executeMergeStep(Path aggregateStep) throws IOException {
CsvFileMerger.mergeCsvFile(
aggregateStep.subpath(0,2).toString(),
configOutPut(4, "result"),
ISBN_IDX, LOAN_CNT_IDX
);
}
private String configOutPut(int number, String leafNm) {
return String.format("%s/%s%d/%s",ROOT,BRANCH,number,leafNm);
}
}
좋은 글 감사합니다. 자주 방문할게요 :)