https://velog.io/@alpahexia/로그-시스템을-구축하자
https://velog.io/@alpahexia/로그로-검색-엔진-개선하기(1)-stopWord-filter
최근에 로그 데이터를 구조화해서 Slack을 통해 전송하는 로그 시스템을 구축 했다. 로그 분석을 2주일 뒤에나 할 계획이었지만, 홍보 글을 올린 목적으로 가입한 독서 커뮤니티에서 댓글로 불만 사항을 접수 했다.

확인 결과, 일정 패턴에서 검색이 안되고 있있다. 그래서 3일정도 쌓인 로그 데이터를 분석하기로 마음 먹었다.
로그 데이터 파싱
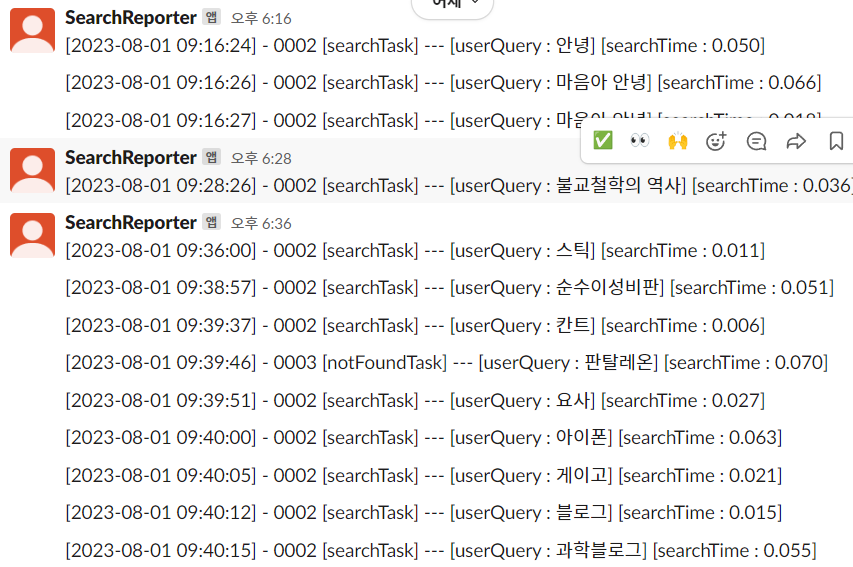
로그 데이터는 위와 같이 Task의 종류와 사용자가 입력한 검색어 그리고 검색 시간을 표시 한다. 가장 중요한 Task는 아무래도 notFoundTask와 SlowTask이다. 이번에는 검색이 되지 않는 경우이기 때문에 notFoundTask를 살펴보기로 했다.
아래는 Slack에서 제공하는 메시지 파일 export를 통해 다운로드 받은 json 파일을 Gson을 사용해서 parsing하는 클래스이다.
public class SlackLogParser {
private static final String USER_QUERY_REGEX = "\\[userQuery :(.*?)\\]";
private static final String MAP_BOOK_TITLE = "\\[title :(.*?)\\]";
private static final String DEFAULT_FILE_EXTENSION = ".json";
// 예시 [2023-08-01 11:48:38] - 0002 [searchTask] --- [userQuery : 아메리칸 프로메테우스] [searchTime : 0.008]
// 로그 파싱 실행 메소드
public static List<String> parsingLogData(String inputFolder,
TaskType taskType, String messageRegex) {
File[] files = filterFilesByExtension(inputFolder);
return Arrays.stream(files)
.flatMap(file -> {
List<SlackLogVo> logData = readLogDataFromFile(file);
return filterLogsByTaskType(taskType.getName(), logData, messageRegex).stream();
})
.collect(Collectors.toList());
}
// 로그 메시지를 쉽게 찾기 위한 helper
public static String getUserQueryRegex() {
return USER_QUERY_REGEX;
}
// 로그 메시지를 쉽게 찾기 위한 helper
public static String getMapBookTitle() {
return MAP_BOOK_TITLE;
}
// log 파일에서 객체로 변환 된 log 데이터에서 원하는 Task을 찾는다 ex) slowTask - 3초 이상의 느린 검색
private static List<String> filterLogsByTaskType(String targetTask, List<SlackLogVo> logList,
String messageRegex) {
return logList.stream()
.filter(slackLogVo -> slackLogVo.getText().contains(targetTask))
.map(slackLogVo -> extractMessageFromLog(slackLogVo, messageRegex))
.flatMap(Optional::stream)
.distinct()
.collect(Collectors.toList());
}
// 정규 표현식을 이용해서 원하는 상세 메시지를 추출
private static Optional<String> extractMessageFromLog(SlackLogVo slackLogVo,
String messageRegex) {
String text = slackLogVo.getText();
Pattern pattern = Pattern.compile(messageRegex);
Matcher matcher = pattern.matcher(text);
return matcher.find() ?
Optional.of(matcher.group(1).trim())
: Optional.empty();
}
// 파일의 로그 데이터를 객체로 변환 한다.
private static List<SlackLogVo> readLogDataFromFile(File file) {
try (BufferedReader reader = new BufferedReader(new FileReader(file))) {
Type logTypeListType = new TypeToken<List<SlackLogVo>>() {
}.getType();
return new Gson().fromJson(reader, logTypeListType);
} catch (IOException e) {
throw new UncheckedIOException(e);
}
}
private static File[] filterFilesByExtension(String inputFolder) {
return new File(inputFolder)
.listFiles((dir, name) -> name.endsWith(DEFAULT_FILE_EXTENSION));
}
}
아래는 결과 데이터를 종합하고, 원인들을 적어 놓은 부분이다.
-
오타 검색 (5개)
- 보도 썌퍼 보도 섀퍼
- 손자병볍 손자병법
- 자바스큽립트 자바스크립트
- 소년이 간다 소년이 온다
- 올재 카리마 올제 카라마조프
-
제목+저자 (2개)
- 안개 미겔 안개
- 이방인 민음사
-
알고리즘 (token_complex) (11개)
- 비평 이론의 모든 것 비평이론의 모든것 :신비평부터 퀴어비평까지
- 처음부터 진실되거나 처음부터 진실되거나, 아예 진실되지 않거나 :데이비드 포스터 월리스와의 일주일
- 국가를 계약하라
- 죽음의 수용소에서
- 왜 칸트인가
- 인간적인
- 마하바라따
- 아주작은 습관의힘 → 보완 X
- 포스트모더니즘까지
- 세이노의 가르침
- 소크라테스에서 포스트 → 보완 X
-
알고리즘 (한글자) (2개)
- 총 균 쇠 총, 균, 쇠:무기·병균·금속은 인류의 운명을 어떻게 바꿨는가
- 총균쇠
-
알고리즘 (token_ two) (1개)
- spring 자바
-
저자 검색 (11개)
- 세르주 다네 영화가 보낸 그림엽서 :어느 시네필의 초상
- 태요 “”
- 감스트 2019 K리그 스카우팅리포트 =2019 K league scouting report
- 이화식
- 움베르트 에코 디 에센셜: 장미의 이름(완전판)
- 리처드 도킨
- 신곡 최민순
- 세르쥬 다네
- 움베르토 에코 중세
- 모노노아와레
- 배세진
분석 결과, 검색 알고리즘 중 token_complex 부분에서 모든 문제를 가지고 있었다.
-
검색 알고리즘?
검색의 성능을 높이기 위해 사용자의 검색어를 명사와 그 외의 어절로 분석하고, 그 둘 단위의 갯수 비율에 따라서 검색 방식을 달리하는 검색 알고리즘. 알고리즘엔 4가지 큰 케이스로 나뉘게 된다.1) Token_complex
- 명사와 다른 어절이 모두 포함된 케이스를 의미 한다. 검색어에 명사가 오직 하나면 token_one이다.
예를 들면,
'왜 칸트인가' -> '칸트'와 '인가'로 분석해서

이런식의 쿼리를 날린다. 명사 토큰 1개 이상, 그 외의 토큰 1개 이상이기 때문에 Token_Complex라고 정의한 타입으로 저렇게 검색한다.
문제가 무엇인가?
만약 책 제목이 '왜 칸트 인가' 였으면 검색이 가능 했겠지만, '칸트인가'로 하나의 단어가 되기 때문에 '인가'를 natural mode로 검색 할 수 없다. 그렇다고 해서 ngram을 도입하기에는 이건 성능이 너무 떨어지기 때문에 안된다.
어떻게 해결 했나?

아래는 EunjeonTokenizer 클래스, 은전한닢이라는 자연어 분석 라이브러리를 활용하여 검색어를 일정 규칙에 맞게 쪼개는 클래스의 메소드 중 하나이다. 이 부분의 특정 로직을 변경 했다. 명사가 포함된 어절을 완전히 제거 하는 것이다. 다시 말해 '칸트인가'에서 '칸트'가 명사로 판단되니깐 '칸트'는 따로 담고, 나머지 '인가'는 없앤다.
String getEtcTokens(List<String> nnWords, String target) {
Set<String> uniqueWords = new LinkedHashSet<>(Arrays.asList(target.split(" ")));
nnWords.forEach(nnWord ->
uniqueWords.removeIf(splitWord -> splitWord.contains(nnWord))
);
return String.join(" ", uniqueWords).trim();
}하지만 또 너무 날리기만 하면 검색이 잘 안되는 경우가 생긴다.
가령 '왜 칸트인가'는 결국 '왜'는 token 최소 단위 2가 안되기 때문에 무시되고, 인가도 없어지기 때문에 '칸트'라는 단어만 가지고 검색하는 상황이 발생한다.
그러면 결과값은 사용자를 실망시키게 된다. '왜 칸트인가'를 검색 했더니 내가 찾고 싶은 책은 15번째 줄에 가 있고, 이상한 칸트 아저씨가 뜨는 광경을 보게 된다.

그래서 결론적으로 SQL은 어떻게 날라가냐?

물론 항상 Token_Complex 타입이라고 해서 저렇게 날라가진 않는다. 그것도 여러가지를 고려해서 변동해서 날리게 된다.
그래서 해결 됐나?
-
알고리즘 (token_complex) (11개)
1 비평 이론의 모든 것 (해결)
2 처음부터 진실되거나 (해결)
3 국가를 계약하라 (해결)
4 죽음의 수용소에서 (해결)
5 왜 칸트인가 (해결)
6 인간적인 (해결)
7 마하바라따 (해결)
8 아주작은 습관의힘 → 해결 X (아주 작은 습관의 힘)
9 포스트모더니즘까지 (해결)
10 세이노의 가르침 (해결)
11 소크라테스에서 포스트 → 해결 X (소크라테스에서 포스트모더니즘까지)
11개 중 9개 경우가 개선이 됐다. 나머지 두개가 개선이 되지 않은 이유는

'아주 작은'으로 입력이 되면 '아주 작은'으로 natural 모드로 검색이 되는데, '아주작은' 덩어리는 안된다. 이건 ngram을 도입 해야할지도 모른다는 생각이 들긴 한다. 하지만 맨 처음 검색 엔진 버전이 ngram을 주로 사용 했었는데, 굉장히 검색 성능이 느려 지금의 방식으로 온 것이기 때문에 이 부분은 더 고민 해봐야겠다.그리고 루씬을 학습하며 느낀게 루씬도 ngram을 자동 완성과 같은 기능에나 활용하지 검색에서 main으로 사용하진 않는다고 한다.
소크라테스에서 포스트의 경우에는 '포스트'라는 단어는 '포스트모더니즘'까지 검색어가 들어와야 검색이 가능한 상황이다. 왜냐? 원 제목이 '소크라테스에서 포스트모더니즘까지'이고, title_token이라는 명사 칼럼에 이미 '소크라테스', '포스트모더니즘'으로 들어가 있기 때문에 불가능 하다. -> 이 문제는 형태소 분석기를 다른 것을 더 써보고 더 명사로 잘 쪼개는 것을 고려 해볼만 하다.

ElasticSearch의 공식 한글 형태소 분석기 Nori가 내가 사용 중인 은전한닢의 데이터를 사용하고 있다는 글을 보니, 다른 라이브러리로 해결할 가능성은 적어 보인다. 다만 형태소 분석전에 형태소 분석을 도울 수 있는 filter를 좀 더 세밀하게 구현해서 추가 해보는 것이 제일 가능성이 높다.
저자+ 제목 검색 모드 추가
-
저자 검색 (11개)
- 세르주 다네 영화가 보낸 그림엽서 :어느 시네필의 초상
- 태요 “”
- 감스트 2019 K리그 스카우팅리포트 =2019 K league scouting report
- 이화식
- 움베르트 에코 디 에센셜: 장미의 이름(완전판)
- 리처드 도킨
- 신곡 최민순
- 세르쥬 다네
- 움베르토 에코 중세
- 모노노아와레
- 배세진
-
제목+저자 (2개)
- 안개 미겔 안개
- 이방인 민음사
다음으로 많았던 NotFoundTask는 저자를 통해 검색하고자 하는 사용자 검색어이다. 조사 해본 결과 독서 커뮤니티 유저들은 같은 제목의 책이여도 옮긴이에 따라 취향이 확고하다. 따라서 저자를 통해 검색하는 경우도 지원을 해야 사용자의 만족을 높일 수 있다고 판단해서 추가 했다.
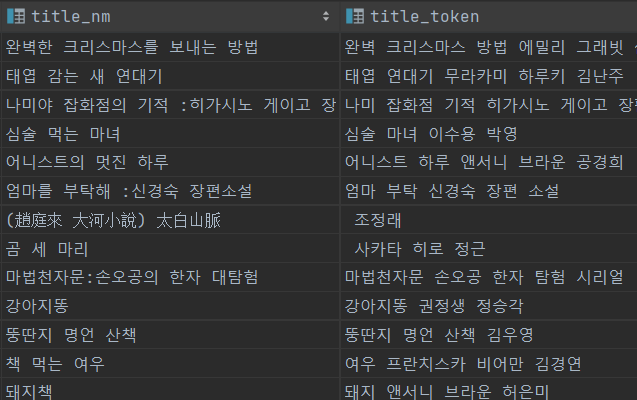
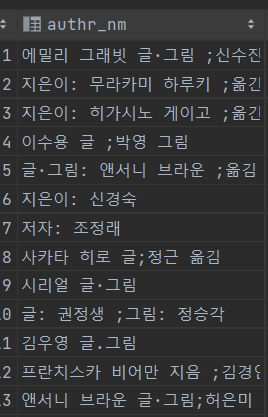
방법은 간단 했다. 기존의 authr_nm 칼럼의 데이터를 가공해서 검색용 칼럼인 title_token에 추가하면 된다.
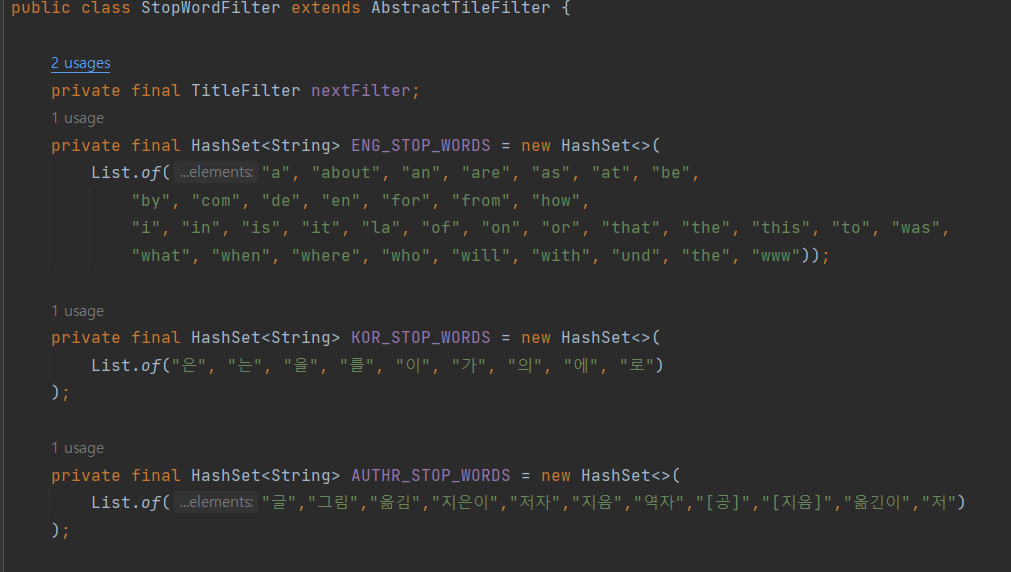
하지만 authr_nm 칼럼에 제외 되야 하는 단어(지은이,옮김 등)이나 특수문자가 있기 때문에 넣는 작업 이전에 전처리 하는 과정을 거치고 넣었다. 전처리 하는 과정은
기존에 사용 중인 StopWordFilter(불필요한 단어 삭제)를 활용 했다. 삭제할 불용어 모음 AUTHR_STORP_WORDS를 추가하고, 나머지 필요한 메소드를 구현해서 사용했다. 간단하기에 긴 설명은 생략하자.
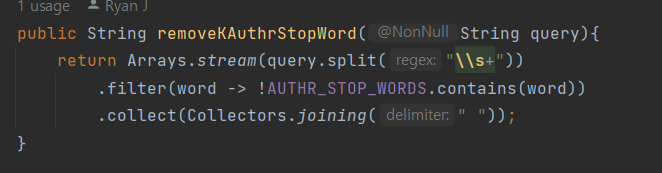
결과는??

성공이다~ title_token에 데이터가 늘어나서, 검색 엔진 성능이 저하 될 것이라고 판단 했지만, 지금으로썬 그렇진 않다. 2주 후에 로그 데이터를 분석해서 searchTime을 한번 비교 분석 해야겠다.
남은 과제
-
오타 검색 (5개)
- 보도 썌퍼 -> 보도 섀퍼
- 손자병볍 -> 손자병법
- 자바스큽립트 -> 자바스크립트
- 소년이 간다 -> 소년이 온다
- 올재 카리마 -> 올제 카라마조프
