
Slf4j를 이용해서 log를 남기고 있는 부분이 있긴 한데, 사실 log를 저장해서 이것을 가지고 분석하거나 활용하는 부분은 전무하다. 로그에 대한 중요성은 듣기만 해서 와닿지 못 했는데, 최근에 기능 구현 업데이트 이후 버그 발생이 있음에도 눈치 채지 못하고 다른 분의 피드백에 의해서 겨우 발견하는 아찔한 상황이 있었다.
그래서 마음 먹고 로그 시스템을 구축 해야겠다는 생각이 들었다.
그렇다면 어떤 로그를 활용하고 싶은가? 목적이 뭔가?
- 사용자가 검색하는 도서명에 대해서 통계를 내고 싶다.
- 사용자의 검색이 실패하여 빈 결과를 반환하는 경우를 찾고, 최신화가 급하게 필요한 도서 데이터를 찾고 싶다.
- 지도 기반 서비스에 대한 성능 이슈가 있는지 계속적으로 관찰하고 싶다.
- 또한 추가로 APM을 도입해서 정식 서비스 런칭 후 Application을 체계적으로 관리 하고 싶다.
로그 시스템 구축 일단은 완료!
처음 로그 시스템을 구축하려고 했을 때, 시중 기술을 선택하려고 했다. 프로젝트가 너무 가내 수공업으로 만든 느낌이 강해서 더욱더... 그래서 키바나를 알아봤지만 ElasticSearch에 묶여 있어 실패. 그 다음은 프로메테우스 - 그라파나 조합이었다. 관련 내용을 찾아보고 EC2에 설치까지 하면서 고민을 했지만, 지금 서비스에선 오버 스택이라는 생각이 들어 서비스가 커지면 적용하기로 했다. 물론 그럼에도 필요성을 느끼는게 자연어 분석기가 메모리 500MB를 잡아 먹고 있기 때문에 어떻게 흘러갈지 모른다는 점이 마음에 걸리긴 한다. 근데 이건 Jmeter를 통해서 다시 부하 테스트를 해보면 그래도 답이 나올 것 같다.
서두가 너무 길어졌다. 그래서 구축 했다는 로그 시스템이 뭔가?
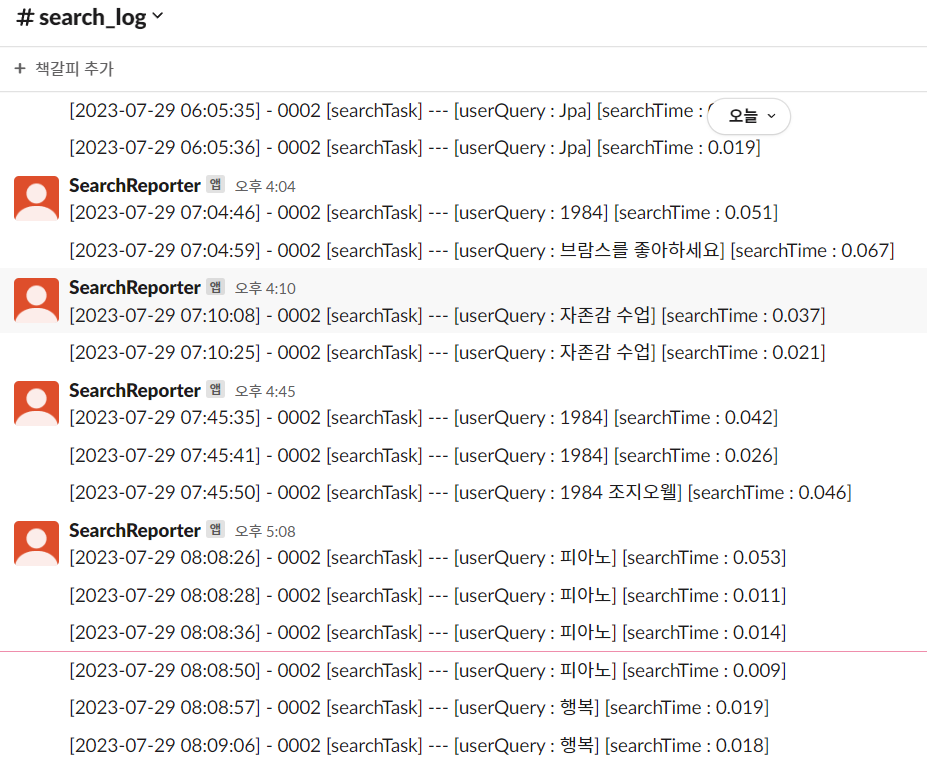
Slack Bot을 통한 로그 시스템이다. 이 시스템을 선택한 이유는 아래와 같다.
- 기존에 slow 검색 작업에 대한 SlackReporter라는 클래스가 있었기 때문에 빠르게 적용할 수 있다.
- 빠르게 적용함으로써 로그 시스템이 없는 공백의 기간 중 놓치는 로그 데이터를 최소화 하고 싶었다.
- 팀원들도 쉽게 확인할 수 있다.
그럼에도 차후엔 바꿔야 하는 이유가 있다
- 비용을 지불하고 slack을 업그레이드 하지 않는 이상 데이터가 90일 뒤엔 소실 된다. 주기적으로 옮겨서 저장하면 되지만, 이 수작업은 언젠가 문제가 될 것이다.
- 로그를 쉽게 보기 위해서 나름 구조화 한 메시지를 보내고 있지만, 저 상태라면 다시 파싱하는 작업을 거치고 통계를 내기 위해 다른 부가 작업이 필요하다. (이 작업은 그래도 해볼 것이다)
그래, 그럼 어떻게 만들었는가?
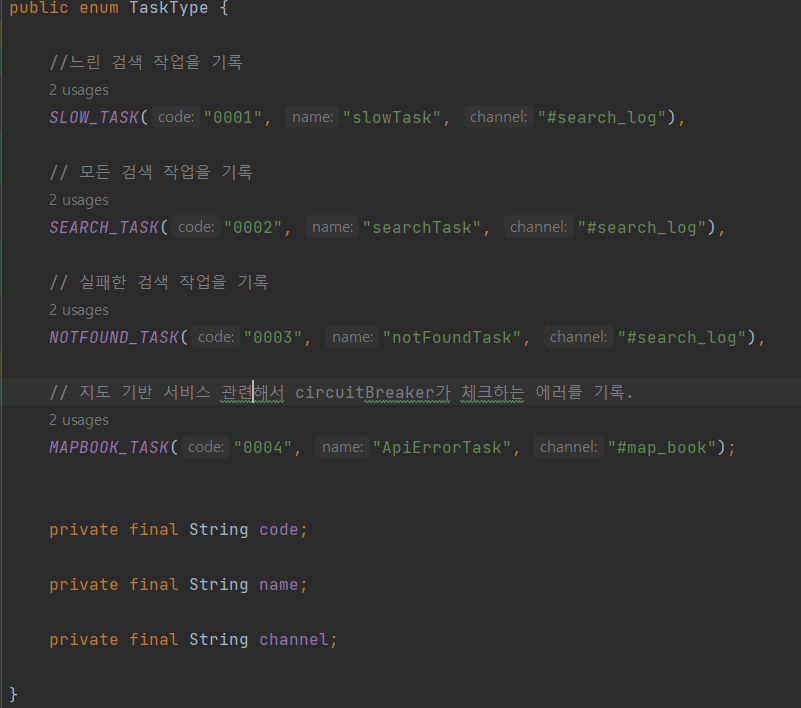
일단 구조화 하기 위해서 기록하는 작업을 분류를 했다. 총 크게 2가지로 분류하고 search_log 채널로 가게 되는 로그는 총 3가지로 검색과 관련한 로그 데이터, 나머지는 API 연결과 관련한 로그로 나눴다.
구조화는 대략적으로 이렇다.
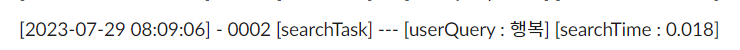
1) [2023-07-29 08:09:06] : 이벤트 발생한 로그 시간
2) 0002 : 로그가 어떤 작업인지에 대한 코드 번호 (0002는 검색)
3) [searchTask] : 코드 번호를 설명하기 위한 작업 이름
4) [userQuery] : 사용자의 검색어
5) [searchTime] : 검색에 걸린 시간
MapBook_Task는 apiUrl과 circuitBreaker가 장애 상황을 판단해 연결을 차단한 시간이 기록 된다.
패키지 구조는 어떠한가?
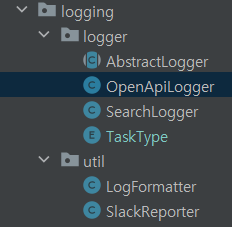
logger 패키지에 logger가 해당 task에 맞게 SlackReporter를 의존해 SlackBot을 통해 메시지를 보내는 구조이다. LogFormatter는 중복되는 로그 구조를 한번에 관리하고, 필요한 로그 메시지의 구조를 만드는 역할을 한다.
LogFormatter부터 보자
//로그 메시지를 구조화 하기 위한 클래스
public class LogFormatter {
// Logger 클래스가 최종적으로 사용하는 메소드. TaskType은 해당 로그가 어떤 작업인지를 나타낸다
// logMessageMap엔 logger가 저장하는 [userQuery (key) : 정석(value)] 식의 로그 메시지이다.
public static String formatting(TaskType taskType, Map<String,String> logMessageMap){
return createLogTemplate(taskType)
.append(formatLogMessages(logMessageMap)).toString();
}
// 공통적인 로그 구조를 StringBuilder에 넣어서 반환 한다.
private static StringBuilder createLogTemplate(TaskType taskType) {
return new StringBuilder(formatBasicLog(taskType));
}
// 공통적인 로그 구조를 나타 낸다.
private static String formatBasicLog(TaskType taskType) {
return String.format(
"[%s] - %s [%s] --- ",
formatDateTime(LocalDateTime.now()),
taskType.getCode(),
taskType.getName());
}
// 공통적으로 로그 발생 날짜 시간을 위한 구조
public static String formatDateTime(LocalDateTime dateTime) {
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
return dateTime.format(formatter);
}
// 상세 로그 메시지에 대한 구조를 처리 한다.
private static String formatLogMessages(Map<String, String> logMessages) {
return logMessages.entrySet().stream()
.map(entry -> String.format("[%s : %s]", entry.getKey(), entry.getValue()))
.collect(Collectors.joining(" "));
}
}Logger에 Slack을 통해 메시지를 보내는 로직의 반복이 생겨 추상 클래스를 사용
public abstract class AbstractLogger<V> {
private final SlackReporter slackReporter;
// logger 구현체가 공통으로 사용하는 메소드. slackReporter를 통해 실제로 메시지 전송
public void sendLogToSlack(V value) {
Map<String, String> logMessages = collectLogInMap(value);
TaskType taskType = determineTaskType(value);
slackReporter.report(
LogFormatter.formatting(taskType, logMessages), taskType.getChannel());
}
//구현체마다 원하는 TaskType을 결정 해야한다.
abstract TaskType determineTaskType(V value);
// 로그 상세 메시지를 map에 구조화 한다. 구현체마다 구현 해야한다.
abstract Map<String, String> collectLogInMap(V value);
}다음은 search Log을 맡는 SearchLogger
public class SearchLogger extends AbstractLogger<RespBooksDto> {
private final static double LIMIT_TIME = 1.0;
public SearchLogger(SlackReporter slackReporter) {
super(slackReporter);
}
@Override
TaskType determineTaskType(RespBooksDto respBooksDto) {
return respBooksDto.isEmptyResult() ? NOTFOUND_TASK
: (parseDoubleSearchTime(respBooksDto) > LIMIT_TIME ? SLOW_TASK : SEARCH_TASK);
}
@Override
Map<String, String> collectLogInMap(RespBooksDto respBooksDto) {
Map<String, String> logMessageMap = new LinkedHashMap<>();
logMessageMap.put("userQuery", respBooksDto.getMeta().getUserQuery());
logMessageMap.put("searchTime", respBooksDto.getMeta().getSearchTime());
return logMessageMap;
}
private double parseDoubleSearchTime(RespBooksDto respBooksDto) {
return Double.parseDouble(respBooksDto.getMeta().getSearchTime());
}
}나머지는 logger 구현체도 비슷하다.
그래서 결과는?
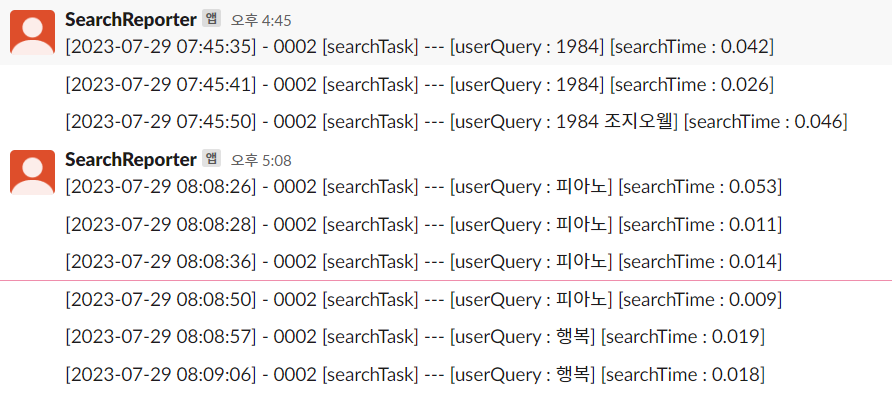
슬랙으로 메시지가 잘 전송 된다. 하지만 몇가지 개선 해야할 사항이 있다.
- [내 도서관 찾기] 버튼을 클릭하는 이벤트가 추적이 안되고 있다. (main 기능 중 하나인데 필수로 필요하다)
- 사용자가 검색하고 버튼까지 클랙하는 일련의 과정을 하나로 기록하고 싶다. 그래야 해당 도서가 더욱 더 사용자에게 가치 있는 검색이였을 것이다.
- 검색 이후 무한 스크롤을 통해 다른 페이지를 받아오는 검색 과정도 기록이 된다. -> 이건 바로 고쳐야겠다.
이후에 나아갈 방향
- 로그를 파싱하고 통계를 내고 시각화 할 수 있는 프로세스를 구축 해야한다.
