
최근에 구축한 로그 시스템을 통해 새벽에 notFoundTask의 로그를 발견 했다.

실제로 맵북에 들어가서 검색 해봤는데, 자동 완성에는 나오지만, 실제로는 검색이 안되고 있었다. 이 말은 내부 DB에 데이터는 있는데 검색을 못하는 상황이기에 시급하게 개선 해야하는 사항이라 자다 말고 개선에 나선다.
뭐가 문제인가?
일단 문제를 확인하기 위해 DB에 해당 제목이 title_token이 어떻게 구성 되어 있는지 확인부터 했다.

사용자가 검색어로 'kotlin in action'을 입력하면 이 경우 쿼리는 아래와 같이 날라간다.
select *
from book_final
where match(title_token) against('+kotlin +in +action' in boolean MODE);여기서 문제는 InnoDB에서 in은 불용어(stopWord)로 처리되기 때문에 있어도 없는 존재이다. 다시 말해 +in 도 boolean mode에 포함 했기 때문에 반드시 in을 포함 해야하지만 inno_db의 처리 때문에 없는 것으로 처리 되는 것이다.
어떻게 해결 할 것인가?
사실 제목을 형태소로 분석해서 title_token에 담을 단계에서부터 불용어는 제거하고 넣었어야 했는데, 그것을 놓쳤다.
지금 당장은 DB의 데이터는 그대로 냅두고, 자바단에서 filter를 하나 추가해서 불용어를 제거해주고 검색하는 방식으로 간다.
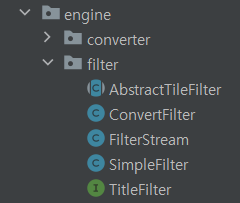
기존의 filter는 위와 같다. AbstractTileFilter를 추상 클래스로 아래의 코드와 같이 filter 구현체들은 filtering 메소드를 오버라이딩 하면 된다. 그리고 사용은 FilterStream에 사용할 filter들을 등록해서 FilterStream을 의존해서 TitleAnalyzer가 사용한다.
1. 불용어 데이터부터 확보 하자.

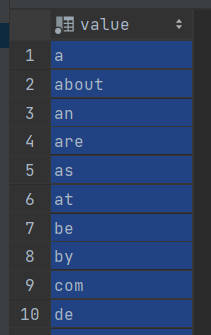
InnoDB가 취급하는 불용어 36개를 확보 한다.
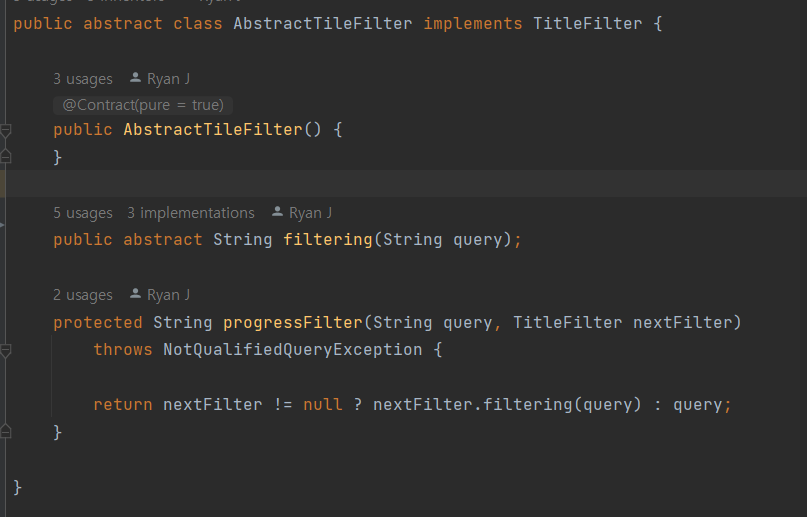
public class StopWordFilter extends AbstractTileFilter {
private final TitleFilter nextFilter;
private final HashSet<String> STOP_WORDS = new HashSet<>(
List.of("a", "about", "an", "are", "as", "at", "be",
"by", "com", "de", "en", "for", "from", "how",
"i", "in", "is", "it", "la", "of", "on", "or", "that", "the", "this", "to", "was",
"what", "when", "where", "who", "will", "with", "und", "the", "www"));
public StopWordFilter(TitleFilter nextFilter) {
this.nextFilter = nextFilter;
}
@Override
public String filtering(String query) {
String removedQuery = Arrays.stream(query.split("\\s+"))
.filter(word -> !STOP_WORDS.contains(word)).collect(Collectors.joining(" "));
return progressFilter(removedQuery, this.nextFilter);
}
}Stopword를 걸러낼 filter를 하나 정의해서 구현 한다. StopWord 데이터는 검색시 상수 시간이 걸리도록 HashSet에 담는다.
STOP_WORDS에 저렇게 초기화를 할 것인가, 아니면 저것도 DB에 넣어두고, where in절로 해결 할 것인가. 라는 고민이 됐다. 일단 테스트 코드를 작성하고 생각 해보기로 한다.
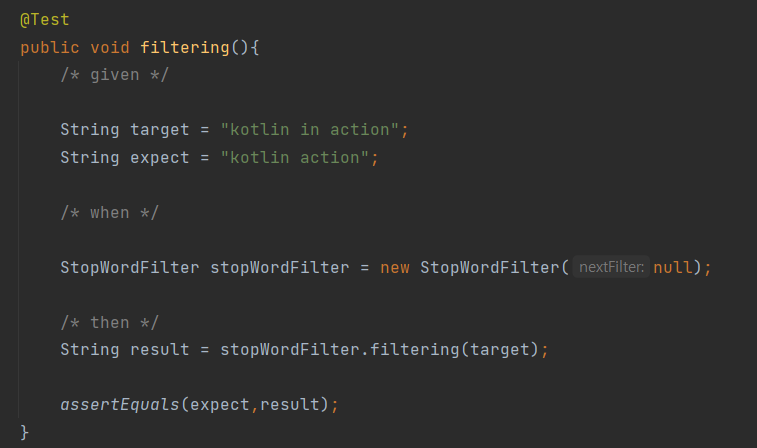
메모리에 올려서 사용하기로 결정.
-
InnoDB 스펙에 결정되어 있는 불용어이고, 불용어라는게 쉽게 바뀌지 않기 때문에 저 초기화한 데이터가 변동 될 가능성은 거의 없을 것이라 판단.
-
36개의 데이터를 저장하고, 불러와서 where in 절로 매칭 해보는건 너무 과한 행동이라고 판단. 엔티티도 정의 해야하고, repository 등 다른 클래스들이 과하게 생겨 날 것이다.
결론 - 해결 완료

(로그 시스템은 이래서 중요하다고 하는구나)
