1. 원래 어떤 라이브러리를 사용하고 있었나?
Komoran이라는 자연어 분석 라이브러리를 사용하고 있었고, MapBook의 한글 단어에 대한 명사 추출 용도로 사용하고 있었다.
2. 어떤 문제가 있나?
Komoran을 통한 자연어 분석이 정확하지 못하다. 그렇기 때문에 사용자의 검색 쿼리를 명사 단위로 추출 한 뒤, 명사 단위로 토큰화 되서 저장돼 있는 Title_token 칼럼을 통한 검색에서 찾지 못하는 검색이 계속해서 발생 했다.
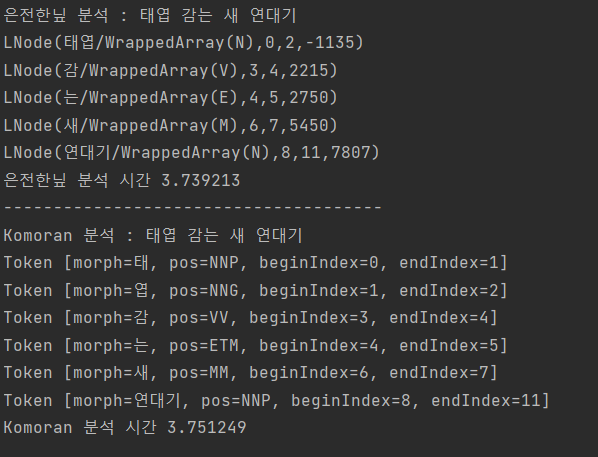
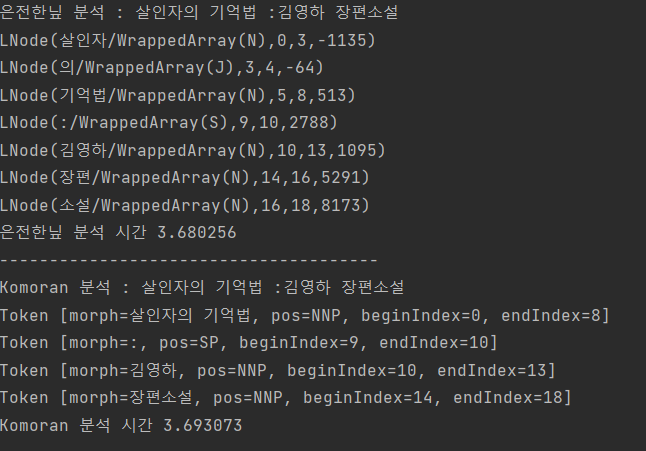
예를 들면 현재 [살인자의 기억법]이라는 도서를 찾기 위해서 사용자가 살인자 김영하라고 검색하면 두 키워들을 +을 붙여 boolean mode를 통해 반드시 포함된 결과를 찾기 때문에 검색에 실패 한다.
그래서 결론은 Komoran 대신 은전한닢으로 변경한다.
하지만 은전한닢도 고려 할 사항이 하나 있다.
초기화 되면 dictionary 데이터를 메모리에 모두 로드 해오기 때문에 500Mib를 바로 차지 한다. 그래서 gradle test에서 겪었던 트러블 슈팅은 아래 링크에 가면 자세히 볼 수 있다.
https://velog.io/@alpahexia/Gradle-Test%EC%8B%9C-Out-of-memory-%EC%9D%B4%EC%8A%88

좋은 영향력과 교류를 위하여
아주 유익한 내용이네요!