1. CacheManager 관련

MapBook 서비스에서 캐싱 기능을 사용 하는데, Redis를 도입하지 않고 CaffeingCache로 캐싱 데이터의 생명 주기를 관리하며 자체 캐시 시스템이 존재 한다.
@Service
@RequiredArgsConstructor
@Slf4j
public class CachedMapBookManager {
private Cache<ReqMapBookDto, List<RespMapBookDto>> mapBookCache;
private final LibraryFindService libraryFindService;
private final ApiQuerySender apiQuerySender;
private final ApiQueryBinder apiQueryBinder;
private final MapBookMatcher mapBookMatcher;
@PostConstruct
public void init() {
this.mapBookCache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.HOURS)
.maximumSize(1000)
.build();
}
@Timer
public List<RespMapBookDto> getMapBooks(ReqMapBookDto mapBookDto) {
List<RespMapBookDto> value = mapBookCache.getIfPresent(mapBookDto);
if (value != null) {
log.info(mapBookDto.getIsbn() + " cache hit !!!!!!!!!!!!!!!!");
} else {
log.info(mapBookDto.getIsbn() + " cache miss...............");
List<LibraryDto> nearByLibraries = libraryFindService.getNearByLibraries(mapBookDto);
if(!nearByLibraries.isEmpty()){
Map<Integer, ApiBookExistDto> bookExistMap = apiQueryBinder.bindBookExistMap(
apiQuerySender.multiQuery(
nearByLibraries,
mapBookDto.getIsbn(),
nearByLibraries.size()));
value = mapBookMatcher.matchMapBooks(nearByLibraries, bookExistMap);
}else{
value = new ArrayList<>();
}
mapBookCache.put(mapBookDto, value);
}
return value;
}
}무엇이 문제였나?
- 기존에는 캐싱이 필요한 서비스마다 그 서비스에 딸리는 캐싱 클래스를 구현하는 방식을 사용 했었다. 그러다 보니 캐싱이 필요한 서비스가 추가 될 때마다 캐싱 클래스를 구현 하는 문제가 있었다.
- 또한 각 캐싱 클래스는 중복된 코드를 포함하고 있었다.
어떻게 해결 했나?
1) 관심사 분리를 통해서 캐싱을 한곳에서만 관리하는 CacheManager 클래스를 구현 했다.
2) 또한 캐싱을 등록하고 캐싱된 데이터를 사용하는 메소드 호출 등의 중복을 막기 위해 Annotation 기반으로 AOP를 활용 했다.
/**
* {@link CustomCacheManager}는 여러 개의 캐시 인스턴스를 관리하고 캐시의 라이프사이클을 조절합니다. 이 클래스는 캐시 객체를 저장하고, 캐시에 데이터를
* 추가하거나 가져오는 기능을 제공합니다.
*
* @param <K> 캐시에서 저장할 데이터 유형
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class CustomCacheManager<K, I> {
private final Map<Class<?>, Cache<CacheKey<K,I>, I>> commonsCache = new ConcurrentHashMap<>();
/**
* 캐시를 등록하여 캐시 관리 시스템에 추가합니다.
*
* @param cache 등록할 캐시 인스턴스
* @param customer 캐시를 사용하는 클래스 정보
*/
public void registerCaching(Cache<CacheKey<K,I>, I> cache, Class<?> customer) {
log.info("[{}] is registered in caching System", customer);
commonsCache.put(customer, cache);
}
/**
* 주어진 클래스와 개인 키에 해당하는 아이템을 캐시에 추가합니다.
*
* @param customer 아이템을 추가할 클래스 정보
* @param personalKey 아이템에 대한 개인 키
* @param item 캐시에 추가할 아이템
*/
public void put(Class<?> customer, CacheKey<K,I> personalKey, I item) {
if (commonsCache.containsKey(customer)) {
log.info("CacheManger put item for [{}]", customer);
commonsCache.get(customer).put(personalKey, (I) item);
}
}
/**
* 주어진 클래스와 개인 키에 해당하는 아이템을 캐시에서 가져옵니다.
*
* @param customer 아이템을 가져올 클래스 정보
* @param personalKey 아이템에 대한 개인 키
* @return 캐시에서 가져온 아이템
*/
@Timer
public I get(Class<?> customer, CacheKey<K,I> personalKey) {
log.info("CacheManger find item for [{}]", customer);
return commonsCache.get(customer).getIfPresent(personalKey);
}
/**
* 주어진 클래스의 캐시를 제거합니다.
*
* @param customer 제거할 캐시의 클래스 정보
*/
public void removeCaching(Class<?> customer) {
if (commonsCache.containsKey(customer)) {
commonsCache.remove(customer);
} else {
log.error("해지 하고자 하는 캐싱 정보가 없습니다. [{}]", customer);
throw new IllegalArgumentException();
}
}
/**
* 주어진 클래스가 캐시를 사용 중인지 확인합니다.
*
* @param customer 확인할 클래스 정보
* @return 캐시를 사용 중이면 true, 그렇지 않으면 false
*/
public boolean isUsingCaching(Class<?> customer) {
return commonsCache.containsKey(customer);
}
/**
* 주어진 클래스와 개인 키에 해당하는 아이템이 캐시에 포함되어 있는지 확인합니다.
*
* @param customer 확인할 클래스 정보
* @param personalKey 아이템에 대한 개인 키
* @return 아이템이 캐시에 포함되어 있으면 true, 그렇지 않으면 false
*/
public boolean isContainItem(Class<?> customer, CacheKey<K,I> personalKey) {
if (isUsingCaching(customer)) {
return commonsCache.get(customer).getIfPresent(personalKey) != null;
} else {
throw new IllegalArgumentException(customer + "is not registered for caching");
}
}
/**
* 주어진 클래스와 인수를 사용하여 CacheKey 객체를 생성합니다. 적절한 CacheKey 구현을 찾지 못하면 UnsupportedOperationException을
* 발생시킵니다.
*
* @param arguments 캐시 키를 생성하는 데 필요한 인수
* @return 생성된 CacheKey 객체
* @throws UnsupportedOperationException 적절한 CacheKey 구현을 찾지 못한 경우 던져 진다.
*/
CacheKey<K,I> generateCacheKey(@NonNull Object[] arguments) throws UnsupportedOperationException {
for(Object obj : arguments){
if(obj instanceof CacheKey<?,?>){
return (CacheKey<K,I>) obj;
}
}
throw new UnsupportedOperationException(
"No suitable CacheKey implementation found for class: ");
}
}
/**
* 사용자 정의 캐싱 어스펙트로, CustomCacheable 어노테이션이 적용된 메서드의 결과를 캐싱합니다. 캐싱된 데이터는 CustomCacheManager를 통해
* 관리됩니다.
*
* @param <K> 캐시 키의 타입
* @param <I> 캐시 항목의 타입
*/
@Aspect
@Component
@Slf4j
@RequiredArgsConstructor
public class CustomCacheAspect<K, I> {
private final CustomCacheManager<K, I> cacheManager;
@Pointcut("@annotation(com.scaling.libraryservice.commons.caching.CustomCacheable)")
private void customCacheablePointcut() {
}
/**
* "CustomCacheable" 어노테이션을 사용하는 메서드를 위한 어드바이스입니다. 캐시에 해당 데이터가 존재하면 캐시로부터 그 값을 반환하고, 그렇지 않은 경우
* 메서드를 실행하고 그 결과를 캐시에 저장합니다.
*
* @param joinPoint 프록시된 메서드에 대한 정보를 제공하는 객체
* @return 캐시로부터 가져온 결과 또는 실제 메서드 실행의 결과
* @throws Throwable 메서드 실행 도중 예외가 발생할 경우
*/
@Around("customCacheablePointcut()")
@SuppressWarnings("unchecked")
public I cacheAround(@NonNull ProceedingJoinPoint joinPoint) throws Throwable {
// 해당 클래스로 등록된 caffeineCache 인스턴스가 있는지 찾기 위해
Class<?> customer = joinPoint.getTarget().getClass();
// 타겟 메소드의 매개 변수에서 해당하는 캐쉬 키를 찾는다.
CacheKey<K, I> cacheKey = cacheManager.generateCacheKey(joinPoint.getArgs());
// caching을 사용하고 있지 않다면, 먼저 등록을 한다. 그리고 마지막에 등록된 캐싱 객체에 캐시 데이터를 넣음
if (!cacheManager.isUsingCaching(customer)) {
cacheManager.registerCaching((Cache<CacheKey<K, I>, I>) cacheKey.configureCache(),
customer);
} else {
if (cacheManager.isContainItem(customer, cacheKey)) {
log.info("Cache Manager find this item ");
return cacheManager.get(customer, cacheKey);
}
}
return patchCacheManager(joinPoint,customer,cacheKey);
}
/**
* 이 메서드는 캐시 관리자(CacheManager)를 수정하여 메서드의 실행 결과를 캐시에 저장합니다.
* 실행 시간이 2초를 초과하거나 ApiRelatedService에 관련된 경우에만 결과를 캐시에 저장합니다.
*
* @param joinPoint 프록시된 메서드에 대한 정보를 제공하는 객체
* @param customer 캐싱 대상 객체의 클래스 정보
* @param cacheKey 캐시에 저장될 값의 키
* @return 메서드 실행 결과
* @throws Throwable 메서드 실행 도중 예외가 발생할 경우
*/
public I patchCacheManager(ProceedingJoinPoint joinPoint, Class<?> customer, CacheKey<K, I> cacheKey)
throws Throwable {
StopWatch stopWatch = new StopWatch();
// 캐싱이 필요한지를 판별하기 위해 해당 메소드의 시작과 끝나는 시간을 측정
stopWatch.start();
I result = (I)joinPoint.proceed();
stopWatch.stop();
// 메소드가 2초를 초과하거나 api 관련한 클래스면 caching 처리 한다.
if (stopWatch.getTotalTimeSeconds() > 2.0 | ApiRelatedService.class.isAssignableFrom(customer)) {
log.info(
"This task is related ApiRelatedService then CacheManger put this item");
cacheManager.put(customer, cacheKey, result);
}
return result;
}
}결론


캐싱 관련한 로직은 해당 서비스에 캐싱 관련 메소드 호출 없이 @CustomCacheable만 붙이면 등록부터 캐싱된 데이터 사용까지 바로 가능하다.
2. BookRepository 관련
무슨 상황인가?
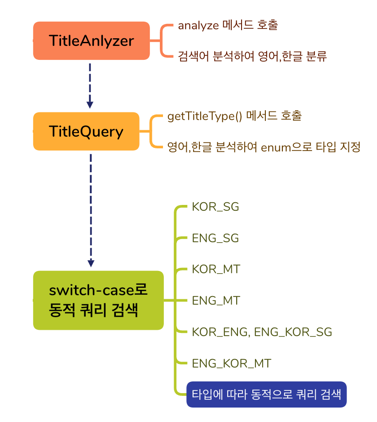
도서를 검색하기 위해서 사용자의 검색어를 분석한 결과를 토대로 DB에 연결하여 데이터를 가져오기 위한 단계에서의 문제이다.
문제는 아래와 같이 Data JPA에 정의된 각각의 메소드를 선택하는데 있어 7가지의 케이스별로 Switch문을 통해서 선택하고 있다.
@RequiredArgsConstructor
@Component @Slf4j
public class EnumBookFinder implements BookFinder<Page<BookDto>,Pageable> {
private final BookRepository bookRepository;
@Override
public Page<BookDto> findBooks(TitleQuery titleQuery, Pageable pageable){
return selectBooksEntity(titleQuery,pageable).map(BookDto::new);
}
/**
* 검색 대상(target)에 따라 적절한 검색 쿼리를 선택하여 도서를 검색하고, 결과를 반환하는 메서드입니다.
*
* @param titleQuery 검색 쿼리를 분석한 결과를 담고 있는 TitleQuery 객체
* @param pageable 페이지 관련 설정을 담은 Pageable 객체
* @return 검색 결과를 담은 Page<Book> 객체
*/
private Page<Book> selectBooksEntity(@NonNull TitleQuery titleQuery, Pageable pageable) {
TitleType type = titleQuery.getTitleType();
switch (type) {
case KOR_SG, KOR_MT_OVER_TWO -> {
return bookRepository.findBooksByKorNatural(titleQuery.getKorToken(), pageable);
}
case KOR_MT_TWO -> {
return bookRepository.findBooksByKorMtFlexible(titleQuery.getKorToken(), pageable);
}
case ENG_SG -> {
return bookRepository.findBooksByEngBool(titleQuery.getEngToken(), pageable);
}
case ENG_MT -> {
return bookRepository.findBooksByEngMtFlexible(titleQuery.getEngToken(), pageable);
}
case ENG_KOR_SG -> {
return bookRepository.findBooksByEngKorBool(titleQuery.getEngToken(),
titleQuery.getKorToken(), pageable);
}
case ENG_KOR_MT -> {
return bookRepository.findBooksByEngKorNatural(
titleQuery.getEngToken(),
titleQuery.getKorToken(),
pageable);
}
default -> throw new IllegalArgumentException("Invalid title type: " + type);
}
}
}왜 문제가 되는가?
- Switch문으로 작성되어 있어 유지 보수에 있어 크나큰 문제를 갖는다. 새로운 케이스가 추가되면 해당 로직은 변경 되야 하며, 케이스가 삭제되면 또한 로직도 변경 되어야 한다. 관심사 분리에 어긋나게 됨으로 리팩토링의 필요성을 느꼈다.
어떻게 해결 했는가?
- 이 문제는 두번의 단계를 거쳤다.
1) 제일 먼저 전략 패턴을 사용해 switch문에 해당되는 로직을 전략 클래스 구현체 별로 하나씩 분리 했다.
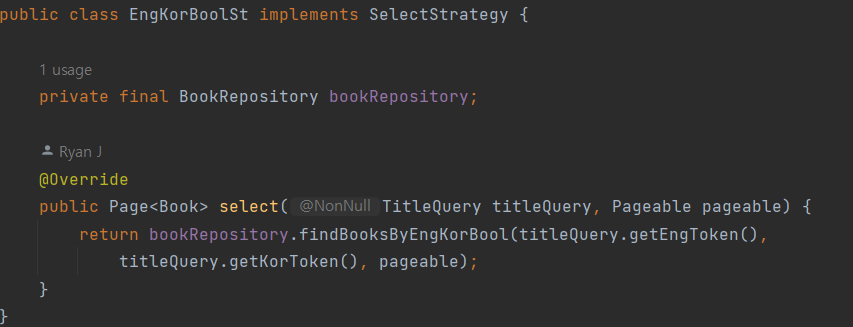
2) 그리고 아래 코드와 같이 생성자에서 관련 전략 구현체를 map에 등록하고 SQL 관련 메소드를 선택 해야 할 때는 findBooks 메소드를 통해 map에서 해당 전략에 맞는 메소드를 선택함으로써 변경 했다.
@Component
public class BookFinderImpl implements BookFinder<Page<BookDto>, Pageable>{
private final Map<TitleType,SelectStrategy> strategyMap;
public BookFinderImpl(BookRepository bookRepository) {
this.strategyMap = new EnumMap<>(TitleType.class);
strategyMap.put(KOR_SG, new KorNaturalSt(bookRepository));
strategyMap.put(KOR_MT_OVER_TWO, new KorNaturalSt(bookRepository));
strategyMap.put(KOR_MT_TWO, new KorBoolSt(bookRepository));
strategyMap.put(ENG_SG,new EngBoolSt(bookRepository));
strategyMap.put(ENG_MT,new EngBoolSt(bookRepository));
strategyMap.put(ENG_KOR_SG, new EngKorBoolSt(bookRepository));
strategyMap.put(ENG_KOR_MT, new EngKorNaturalSt(bookRepository));
}
/**
* 검색 대상(target)에 따라 적절한 검색 쿼리를 선택하여 도서를 검색하고, 결과를 반환하는 메서드입니다.
*
* @param titleQuery 검색 쿼리를 분석한 결과를 담고 있는 TitleQuery 객체
* @param pageable 페이지 관련 설정을 담은 Pageable 객체
* @return 검색 결과를 담은 Page<Book> 객체
*/
@Override
public Page<BookDto> findBooks(TitleQuery titleQuery, Pageable pageable) {
TitleType type = titleQuery.getTitleType();
SelectStrategy strategy = strategyMap.get(type);
if(strategy == null){
throw new IllegalArgumentException("Invalid title type: " + type);
}
return strategy.select(titleQuery,pageable).map(BookDto::new);
}
}잘 해결 됐는가?
- 그렇지는 않다. 가장 큰 문제가 각각의 전략을 계속해서 만드는 것의 불편함이였고, 전략이 증가하면 할 수록 생성자에서 map에 등록하는 과정 또한 계속해서 증가 될 것이라고 판단하여, 다른 방식의 해결 방법이 필요하다고 느꼈다.
그래서 어떻게 했는가?
- Repository의 코드가 먼저 리팩토링 되야 한다고 판단되어, Data JPA을 사용하고 JPQL을 활용해서 DB에 연결하는 코드들은 관련 검색 엔진 알고리즘의 문제와 결부되어 서브 쿼리, 서브 쿼리로 인한 countQuery 명시, 중복 코드 발생, 재사용성 저하 등의 이유가 있었다. 그래서 Repository의 JPQL문을 queryDsl을 활용하여 쿼리를 선택하는 복잡도를 줄여 해결 했다.
@RequiredArgsConstructor
@Repository
public class BookRepoQueryDsl implements BookRepository {
private final JPAQueryFactory factory;
private final static int LIMIT_CNT = 30;
private final static double SCORE_OF_MATCH = 0.0;
@Override
public Page<BookDto> findBooks(TitleQuery titleQuery, Pageable pageable) {
// match..against 문을 활용하여 Full text search를 수행
JPAQuery<Book> books = factory
.selectFrom(book)
.where(
getTemplate(
titleQuery.getTitleType(), titleQuery.getEngKorTokens()).gt(SCORE_OF_MATCH))
.offset(pageable.getOffset())
.limit(pageable.getPageSize());
long totalSize = getTotalSizeForPaging(titleQuery);
// 최종적으로 페이징 처리된 도서 검색 결과를 반환.
return PageableExecutionUtils.getPage(
books.fetch().stream().map(BookDto::new).toList(),
pageable, () -> totalSize);
}
private long getTotalSizeForPaging(TitleQuery titleQuery){
// 1.키워드가 하나인 포괄적 키워드는 count query 성능을 위해 size를 제한 한다.
// 2.그럼에도 결과값은 전체 대출 횟수를 기준으로 내림 차순으로 보여주기 때문에 검색 품질은 보장한다.
if (titleQuery.getTitleType() == TitleType.TOKEN_ONE) {
return LIMIT_CNT;
}else{
//키워드가 2개 이상일 땐, countQuery 메소드를 호출한다.
return countQuery(titleQuery).fetchOne();
}
}
private JPAQuery<Long> countQuery(TitleQuery titleQuery) {
return factory
.select(book.count())
.from(book)
.where(
getTemplate(
titleQuery.getTitleType()
, titleQuery.getEngKorTokens()).gt(SCORE_OF_MATCH));
}
// 사용자가 입력한 제목 쿼리를 분석한 결과를 바탕으로 boolean or natural 모드를 동적으로 선택
NumberTemplate<Double> getTemplate(TitleType type, String name) {
String function;
if (type.getMode() == BooleanMode) {
function = "function('BooleanMatch',{0},{1})";
// boolean 모드에서 모두 반드시 포함된 결과를 위해 '+'를 붙여주는 정적 메소드 호출.
name = TitleTrimmer.splitAddPlus(name);
} else {
function = "function('NaturalMatch',{0},{1})";
}
return Expressions.numberTemplate(Double.class,
function, book.titleToken, name);
}
private JPAQuery<Long> countQueryAll() {
return factory
.select(book.count())
.from(book);
}
// csv file로 변환 할 때 사용하기 위한 메소드.
public Page<Book> findAllAndSort(Pageable pageable){
JPAQuery<Book> books = factory
.selectFrom(book)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(book.loanCnt.desc());
return PageableExecutionUtils.getPage(
books.fetch(),
pageable, () -> countQueryAll().fetchOne());
}
}아래 링크는 JPQL을 queryDsl을 활용하여 변경하는 과정을 담은 글이다.
https://velog.io/@alpahexia/JPQL%EC%9D%84-QueryDSL%EB%A1%9C-%EB%B3%80%ED%99%98

정말 좋은 글 감사합니다!