
프로젝트 개요
서울시 CCTV 분석(왕초보용..ㅎ)
프로젝트 목표
서울 인구수와 CCTV 개수로 구별 그래프를 그리고 경향선을 기준으로 데이터를 강조하자
데이터는 공공데이터 사이트, 통계청 등등 다양한 곳에서 찾을 수 있다.
프로젝트 시작!
pandas를 이용하여 파일을 읽고 다룰 예정
데이터 읽기
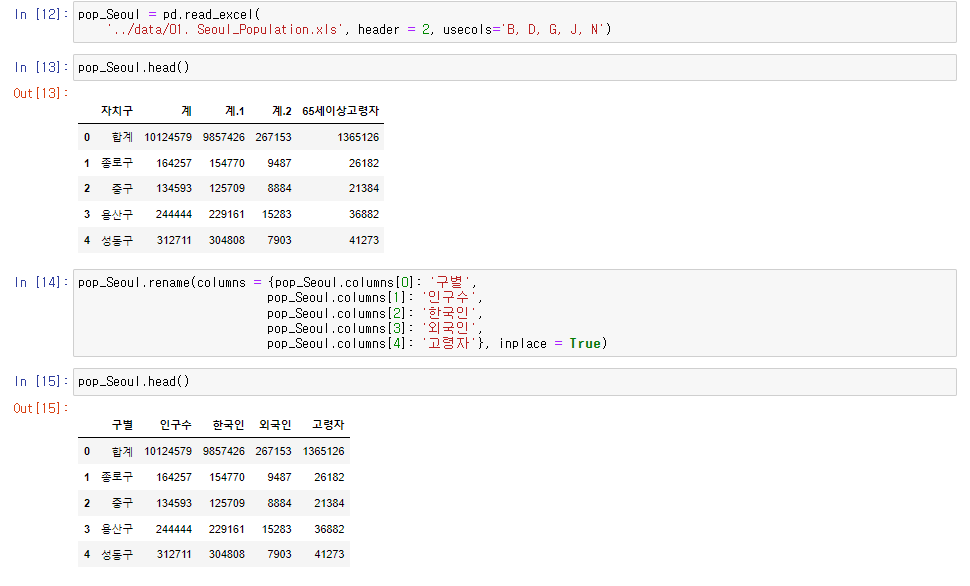
서울CCTV현황과 서울 인구수를 pd.read로 읽어와
head() #파일 보기, rename() #이름 재설정, drop() # 행or열 삭제 등을 사용하여 자료를 사용하기 편하게 정리한다.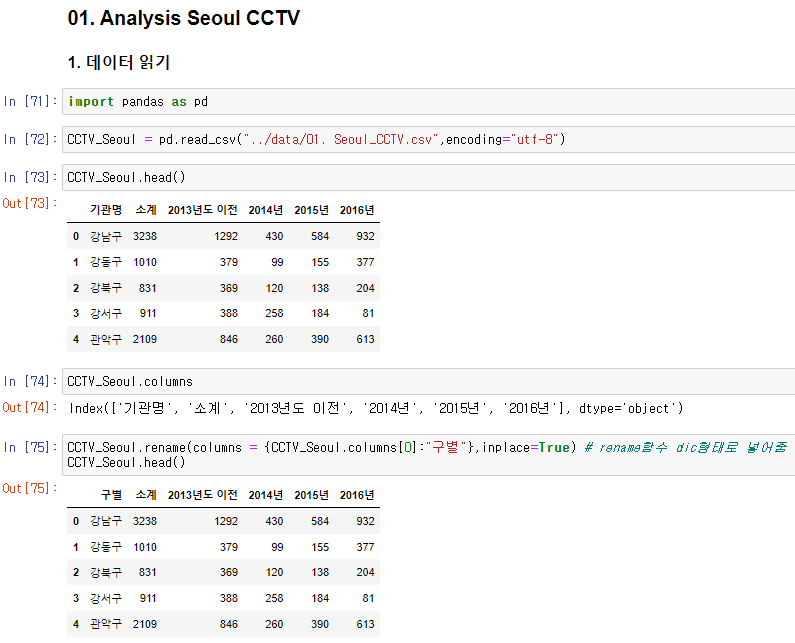
# 1. 데이터 읽기
import pandas as pd
import numpy as np
CCTV_Seoul = pd.read_csv("../data/01. Seoul_CCTV.csv",encoding="utf-8")
CCTV_Seoul.rename(columns = {CCTV_Seoul.columns[0]:"구별"},inplace=True) # rename함수 dic형태로 넣어줌
pop_Seoul = pd.read_excel('../data/01. Seoul_Population.xls', header=2, usecols="B,D,G,J,N") # 칼럼 한번에
pop_Seoul.rename(columns={pop_Seoul.columns[0]:"구별",
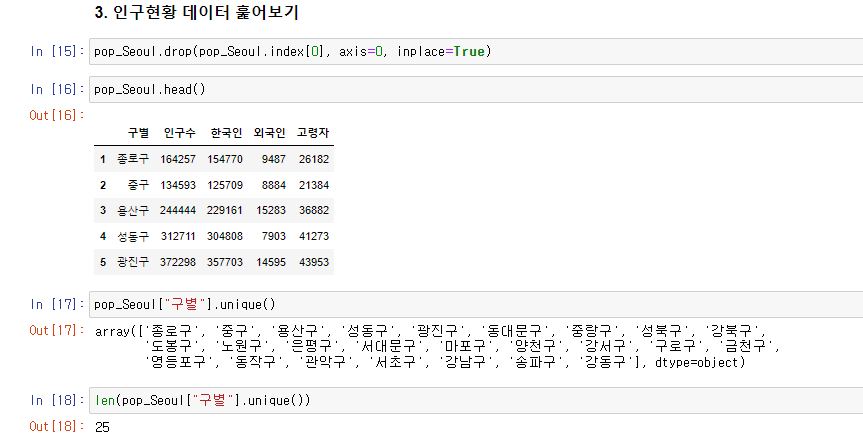
pop_Seoul.columns[1]:"인구수",
pop_Seoul.columns[2]:"한국인",
pop_Seoul.columns[3]:"외국인",
pop_Seoul.columns[4]:"고령자"}, inplace=True)- pnndas 데이터 프레임의 구조
데이터 훑어보기
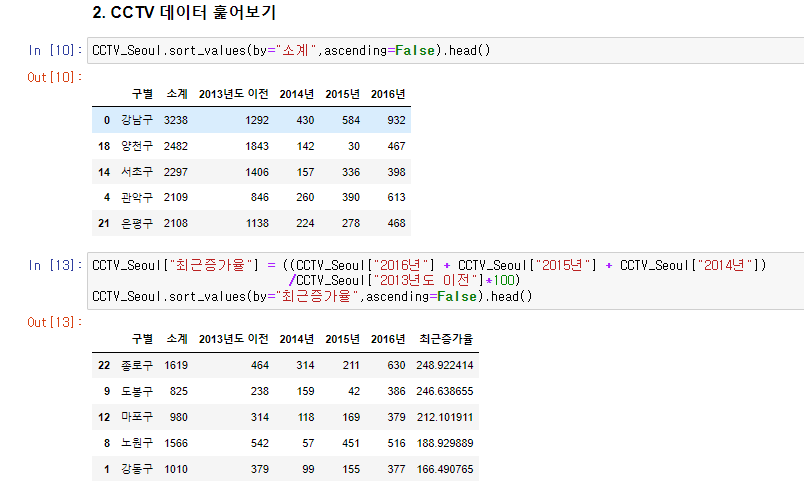
sort함수를 이용하여 데이터를 정렬,
unique함수를 이용하여 중복없은 값을 볼 수 있다.
필요한 컬럼도 추가 가능
# 2. CCTV 데이터 훑어보기
CCTV_Seoul.sort_values(by="소계",ascending=False).head()
CCTV_Seoul["최근증가율"] = ((CCTV_Seoul["2016년"] + CCTV_Seoul["2015년"] + CCTV_Seoul["2014년"])
/CCTV_Seoul["2013년도 이전"]*100)
CCTV_Seoul.sort_values(by="최근증가율",ascending=False).head()
# 3. 인구현황 데이터 훑어보기
pop_Seoul.drop(pop_Seoul.index[0], axis=0, inplace=True)
## 외국인 비율, 고령자비율
pop_Seoul["외국인비율"] = pop_Seoul["외국인"]/pop_Seoul["인구수"] * 100
pop_Seoul["고령자비율"] = pop_Seoul["고령자"]/pop_Seoul["인구수"] * 100두데이터 합치기
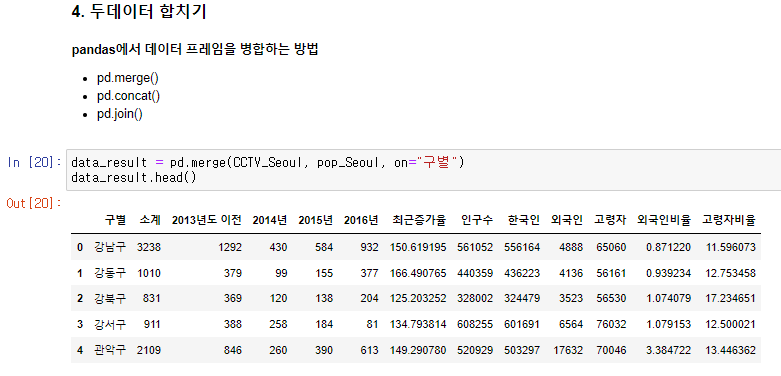
pandas의 merge함수를 이용하여 "구별"을 기준으로 데이터를 합친다.
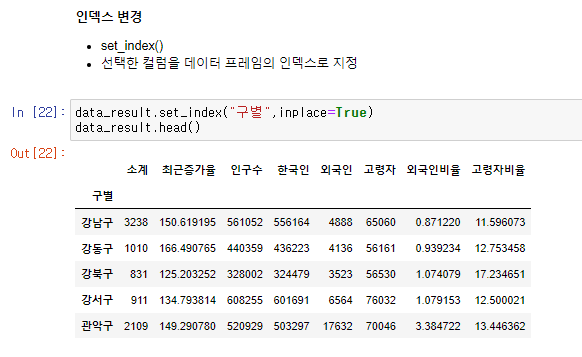
set_index() 함수를 이용하여 선택한 컬럼을 데이터 프레임의 인덱스로 지정, 필요없는 컬럼 삭제
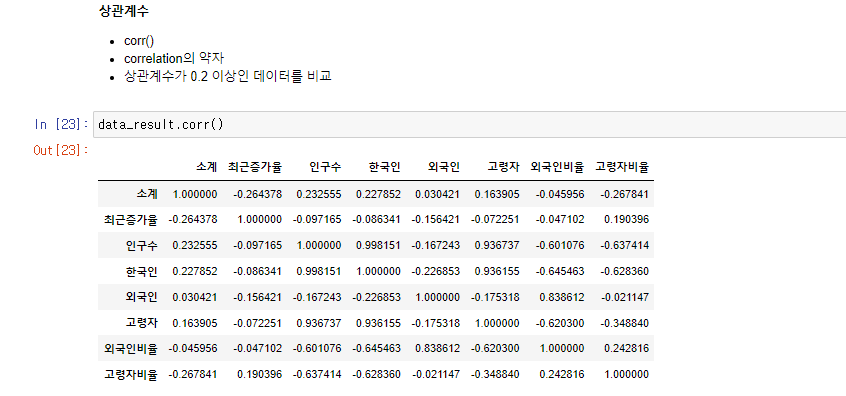
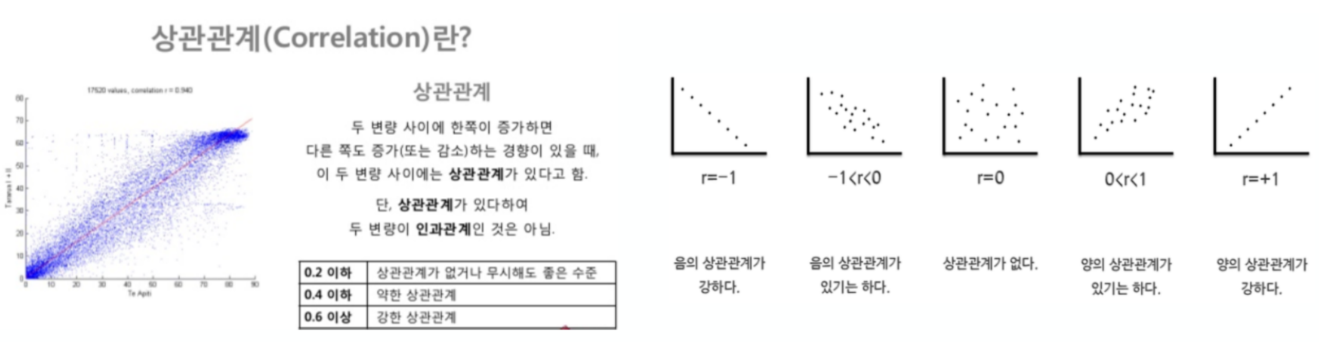
corr()함수로 데이터의 상관계수를 볼 수 있다.
상관계수가 0.2 이상인 데이터를 비교하는 것이 유의미
# 4. 두데이터 합치기
data_result = pd.merge(CCTV_Seoul, pop_Seoul, on="구별")
data_result.drop(["2013년도 이전","2014년","2015년","2016년"], axis=1, inplace=True)
data_result.set_index("구별",inplace=True)
data_result["CCTV비율"] = data_result["소계"]/data_result["인구수"]*100
data_result.sort_values(by="CCTV비율",ascending=False).head()데이터 시각화
데이터 시각화를 위해 matplotlib을 import하고
차트에 한글을 적어주기위해 해당 코드를 적어준다.
# 5. 데이터 시각화
## 한글 사용을 위한 작업
import matplotlib.pyplot as plt
from matplotlib import rc
plt.rcParams["axes.unicode_minus"] = False
rc("font",family = "Malgun Gothic")
# % matplotlib inline
get_ipython().run_line_magic("matplotlib","inline")
## 다양한 차트그리기
data_result["인구수"].plot(kind="bar",figsize=(10,10));
data_result["소계"].plot(kind="barh",figsize=(10,10));
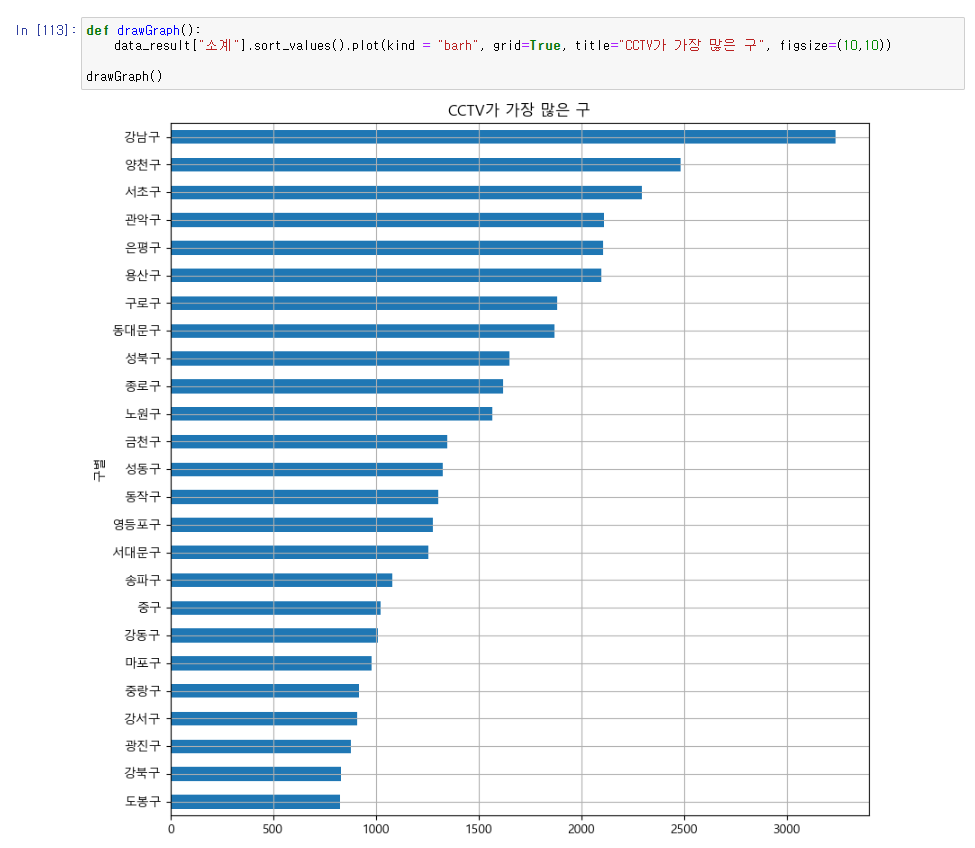
data_result["소계"].sort_values().plot(kind = "barh", grid=True, title="CCTV가 가장 많은 구", figsize=(10,10))
data_result["CCTV비율"].sort_values().plot(kind = "barh", grid=True, title="CCTV비율이 가장 높은 구", figsize=(10,10))데이터 경향 표시
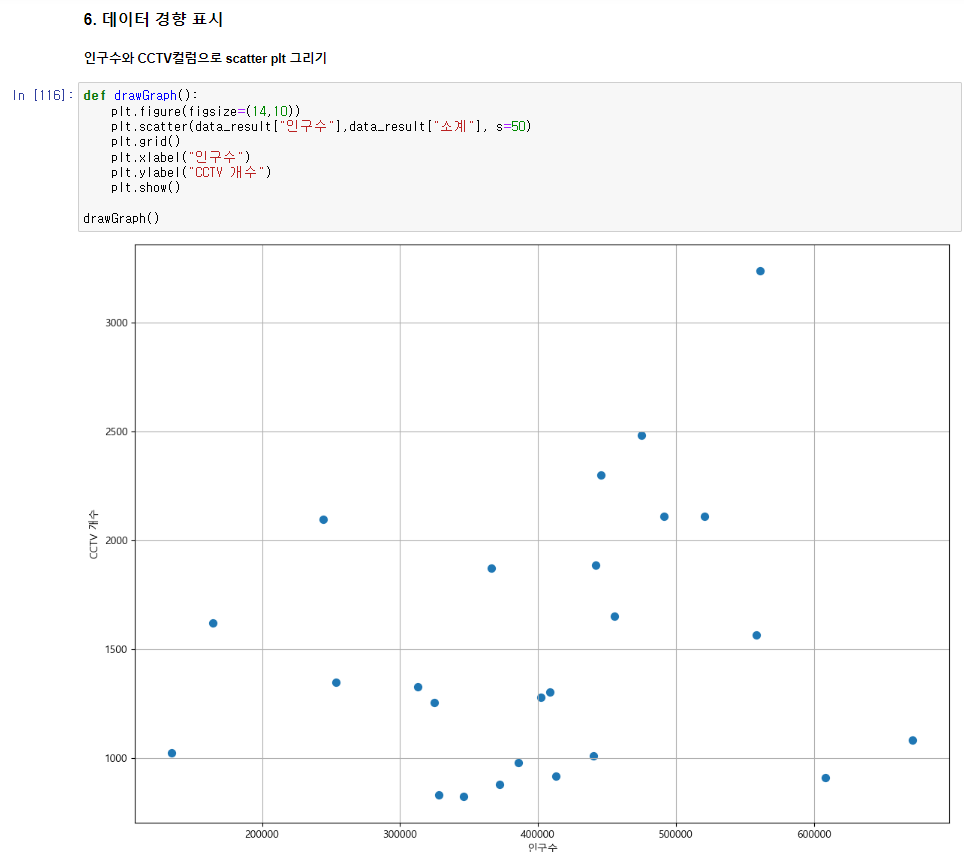
scatter함수를 이용하여 데이터의 분포를 점으로 표시하였다.
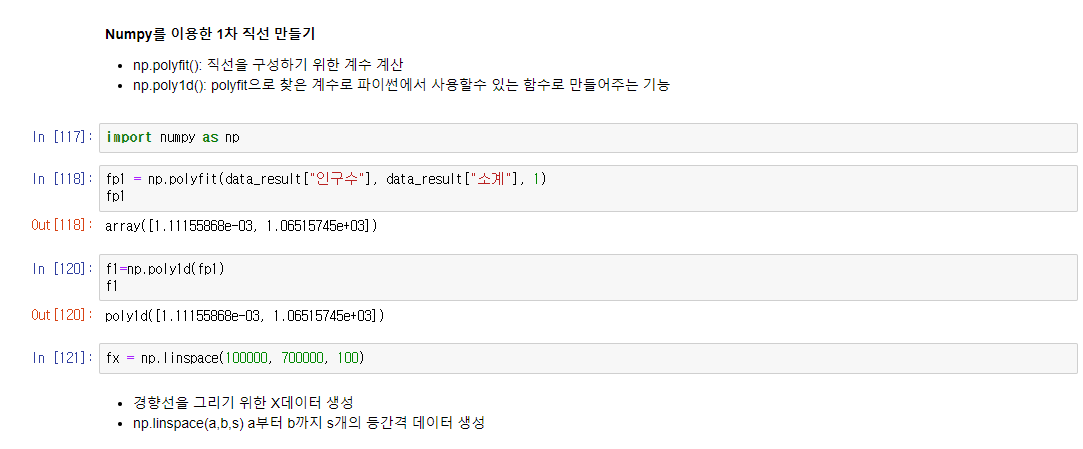
Numpy를 이용한 1차 직선(경향) 만들기
np.polyfit(): 직선을 구성하기 위한 계수 계산
np.poly1d(): polyfit으로 찾은 계수로 파이썬에서 사용할수 있는 함수로 만들어주는 기능
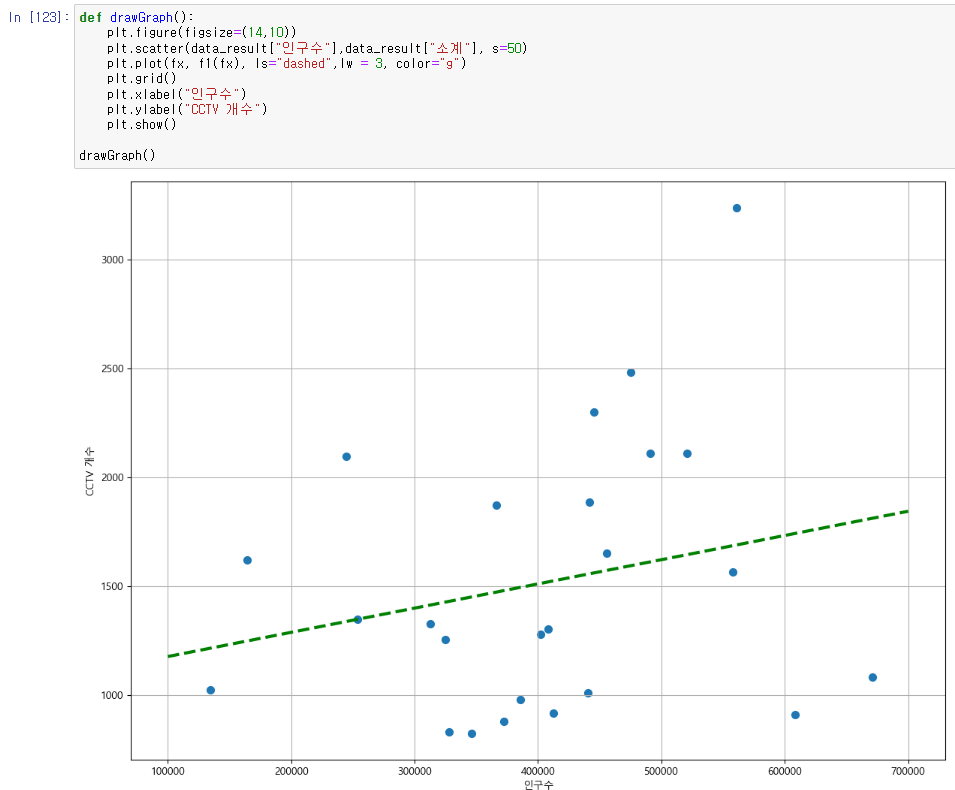
# 6. 데이터 경향 표시
## 인구수와 CCTV컬럼으로 scatter plt 그리기
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"], s=50)
plt.grid()
plt.xlabel("인구수")
plt.ylabel("CCTV 개수")
plt.show()
drawGraph()
## Numpy를 이용한 1차 직선 만들기
fp1 = np.polyfit(data_result["인구수"], data_result["소계"], 1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000, 700000, 100)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"], s=50)
plt.plot(fx, f1(fx), ls="dashed",lw = 3, color="g")
plt.grid()
plt.xlabel("인구수")
plt.ylabel("CCTV 개수")
plt.show()
drawGraph()강조하고싶은 데이터 시각화
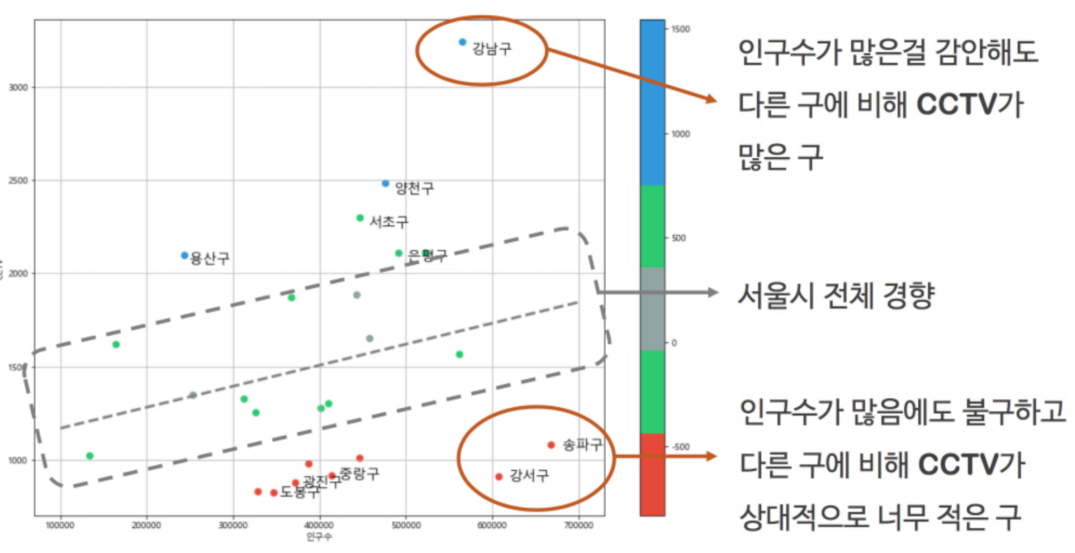
"오차"라는 컬럼을 추가해 인구대비 CCTV가 많은 구, 적은 구를 찾는다.
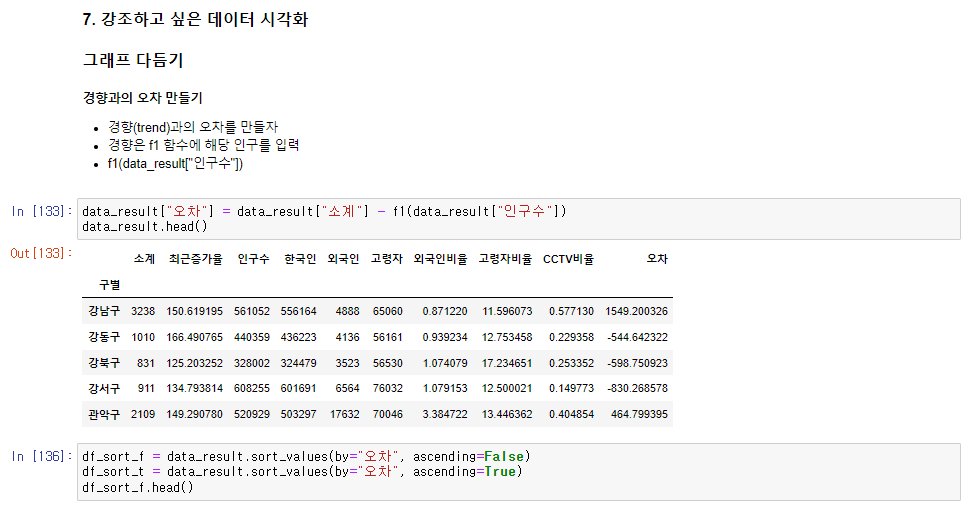
# 7. 강조하고 싶은 데이터 시각화
data_result["오차"] = data_result["소계"] - f1(data_result["인구수"])
df_sort_f = data_result.sort_values(by="오차", ascending=False)
df_sort_t = data_result.sort_values(by="오차", ascending=True)
from matplotlib.colors import ListedColormap
# colormap을 사용자 정의(user define)로 세팅
color_step = ["#e74c3c", "#2ecc71","#95a9a6","#2ecc71","#3498db","#3498db"]
my_cmap = ListedColormap(color_step)
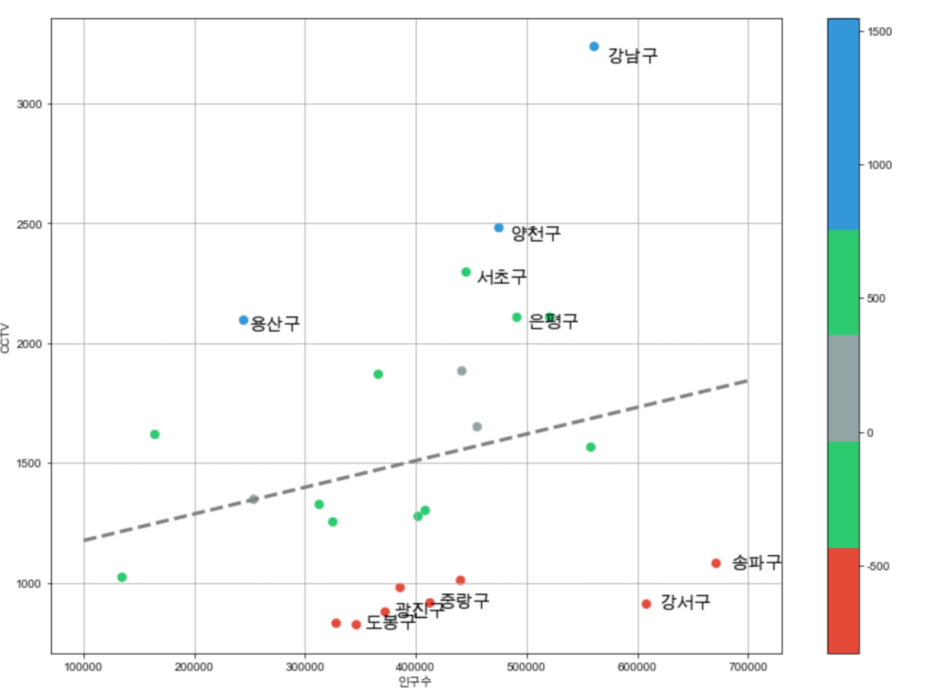
프로젝트 완성
인구대비 CCTV가 많은 구, 적은 구의 구이름과 색으로 구별하여 시각화
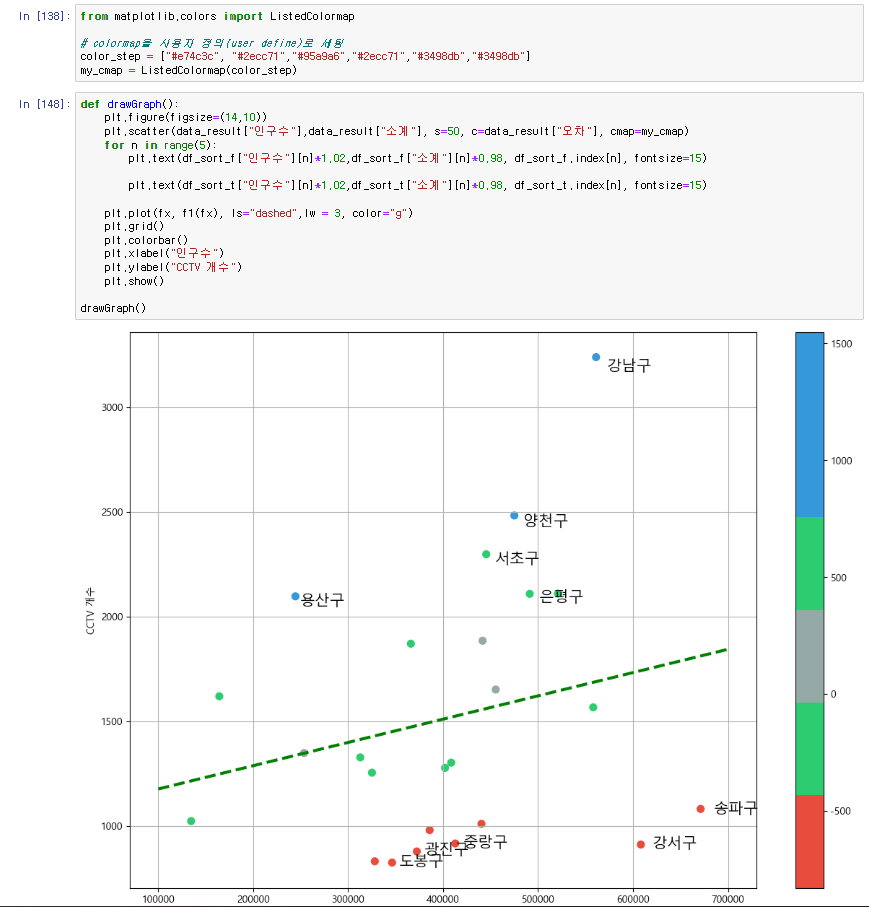
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result["인구수"],data_result["소계"], s=50, c=data_result["오차"], cmap = my_cmap)
plt.plot(fx,f1(fx), ls="dashed", lw=3, color="g")
for n in range(5):
# 상위 5개
plt.text(df_sort_f["인구수"][n]* # x좌표
1.02,df_sort_f["소계"][n]* # y좌표
0.98,df_sort_f.index[n],fontsize=15) # title
#하위 5개
plt.text(df_sort_t["인구수"][n]* # x좌표
1.02,df_sort_t["소계"][n]* # y좌표
0.98,df_sort_t.index[n],fontsize=15) # title
plt.grid()
plt.colorbar()
plt.xlabel("인구수")
plt.ylabel("CCTV 개수")
plt.show()
drawGraph()- 프로젝트 결론
강남구, 양천구, 용산구가 인구대비 CCTV대수가 많고,
송파구, 강서구는 인구대비 CCTV대수가 적다.
후기
첫 EDA 프로젝트라서 할 수 있을까 걱정이 많았는데 단계단계 자세한 설명과 실습으로 문제 없이 왕초보 프로젝트를 완성할 수 있었다.
차트를 그려가며 시각적으로 산출물이 나오니 신기하고 재미있었다. 오류가 나면 당황하지만 차근차근 해결해나가면서 열심히 해야겠다는 동기부여가 되는것 같다.
이글은 제로베이스 데이터 취업스쿨의 강의자료 일부를 발췌하여 작성되었습니다.
