
프로젝트 개요
강남 3구의 범죄 안전률 구하기
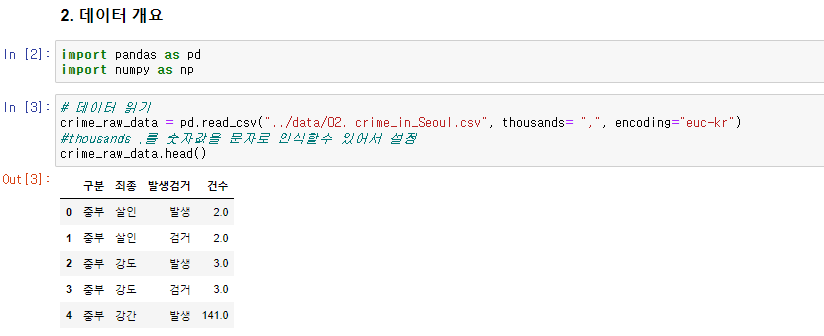
데이터 개요
- csv로 저장되어 있는 서울시 범죄 현황 데이터 파일을 pandas로 읽어온다.
# 데이터 개요
import pandas as pd
import numpy as np
crime_raw_data = pd.read_csv("../data/02. crime_in_Seoul.csv", thousands= ",", encoding="euc-kr") #thousands ,를 숫자값을 문자로 인식할수 있어서 설정
crime_raw_data = crime_raw_data[crime_raw_data["죄종"].notnull()]
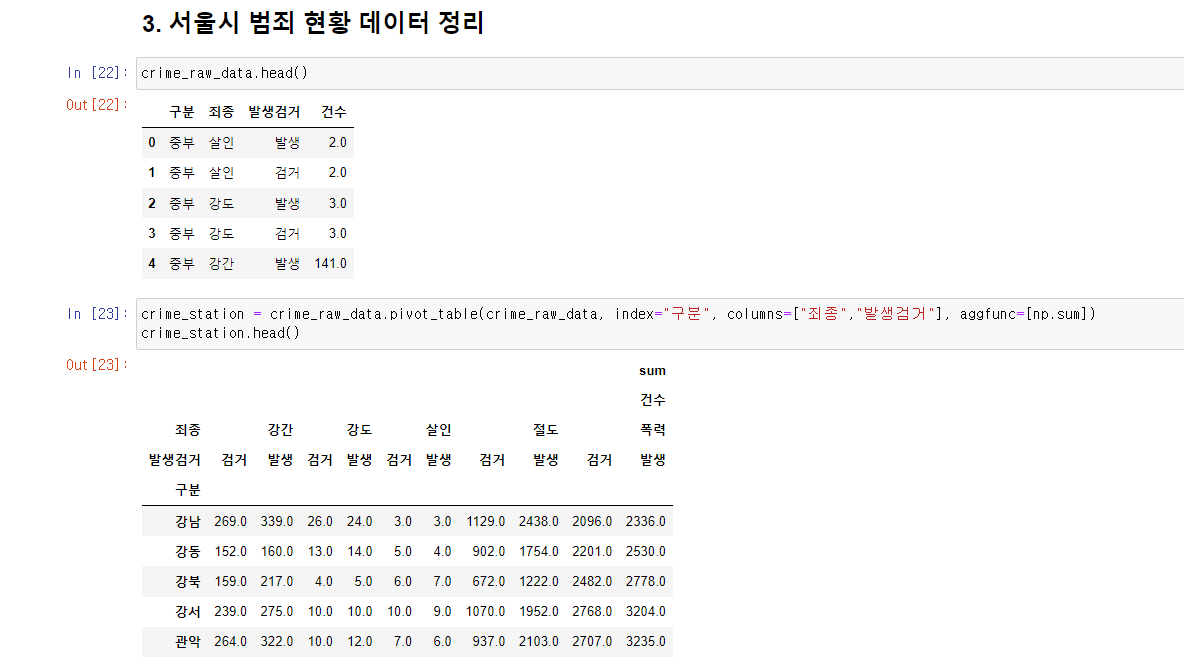
서울시 범죄 현황 데이터 정리
- 서울시 범죄 현황 데이터를 pivot으로 정리하고 컬럼을 정리
- columns.droplevel()을 이용해서 다중 컬럼에서 특정 컬럼 제거

# 데이터 정리
crime_station = crime_raw_data.pivot_table(crime_raw_data, index="구분", columns=["죄종","발생검거"], aggfunc=[np.sum])
crime_station.columns # 다중 컬럼
crime_station.columns = crime_station.columns.droplevel([0,1]) # 다중 컬럼에서 특정 컬럼 제거
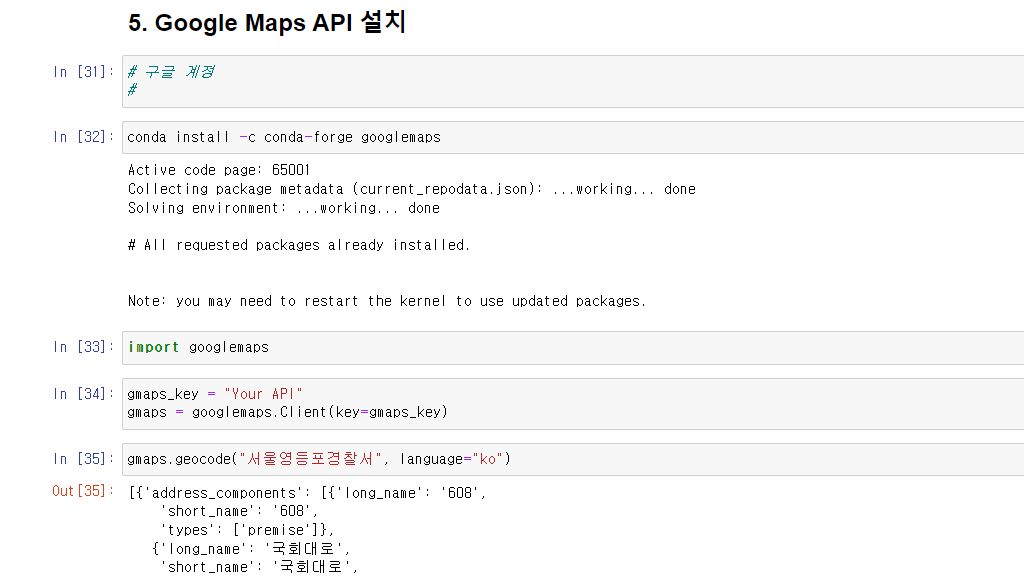
Google maps를 이용한 데이터 정리
- Google maps을 통해 특정 장소의 위도, 경도, 주소를 찾을 수 있다.
# googlemaps 실습
import googlemaps
gmaps_key = "Your API"
gmaps = googlemaps.Client(key=gmaps_key)
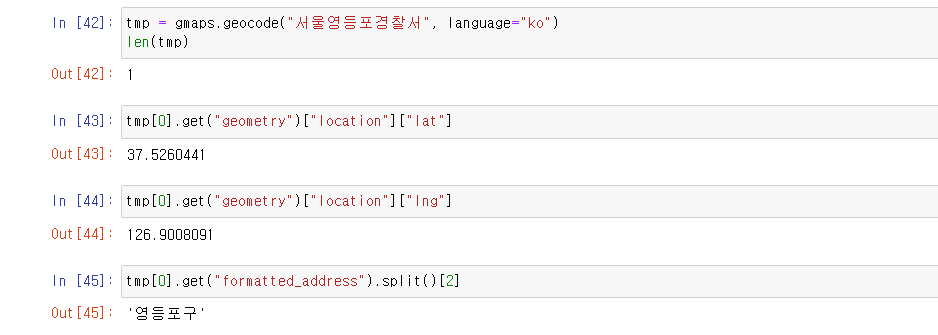
gmaps.geocode("서울영등포경찰서", language="ko")
tmp[0].get("geometry")["location"]["lat"]
tmp[0].get("geometry")["location"]["lng"]
tmp[0].get("formatted_address").split()[2]
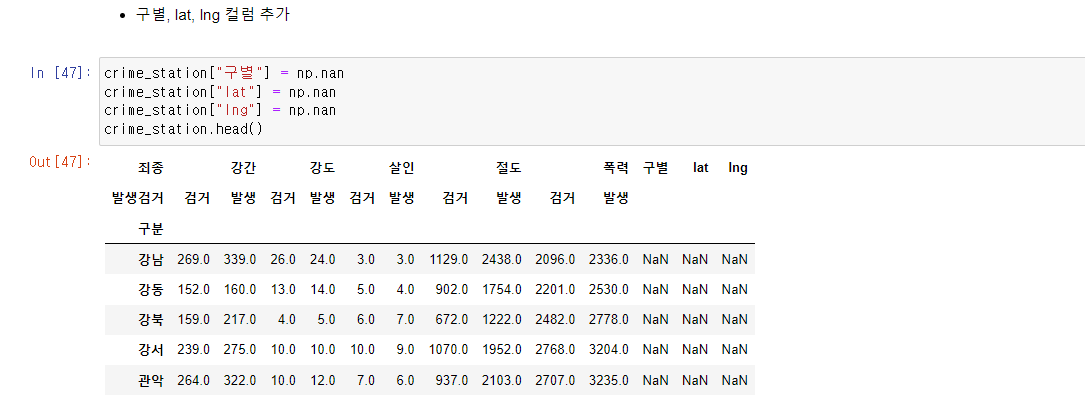
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
crime_station.head()
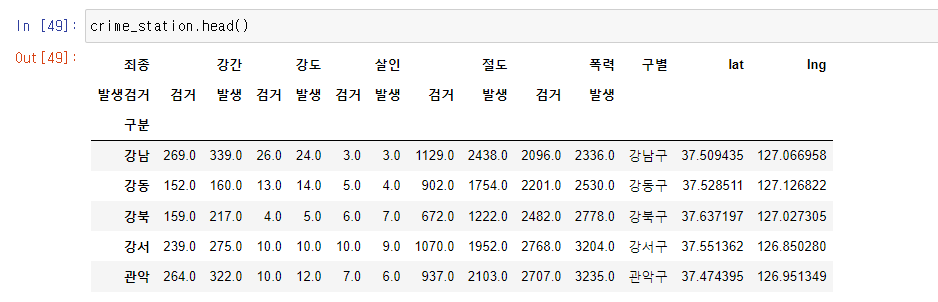
# googlemaps을 이용한 데이터 정리
crime_station["구별"] = np.nan
crime_station["lat"] = np.nan
crime_station["lng"] = np.nan
crime_station.head()
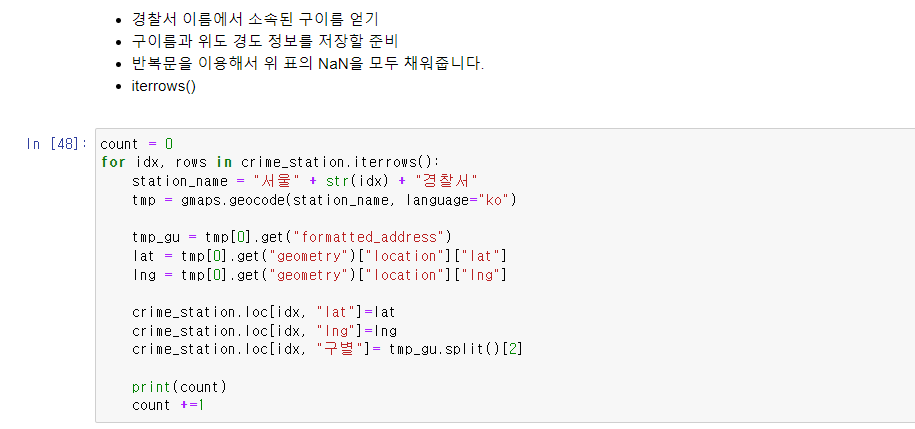
count = 0
for idx, rows in crime_station.iterrows():
station_name = "서울" + str(idx) + "경찰서"
tmp = gmaps.geocode(station_name, language="ko")
tmp_gu = tmp[0].get("formatted_address")
lat = tmp[0].get("geometry")["location"]["lat"]
lng = tmp[0].get("geometry")["location"]["lng"]
crime_station.loc[idx, "lat"]=lat
crime_station.loc[idx, "lng"]=lng
crime_station.loc[idx, "구별"]= tmp_gu.split()[2]
print(count)
count +=1
tmp = [crime_station.columns.get_level_values(0)[n] + crime_station.columns.get_level_values(1)[n]
for n in range(len(crime_station.columns.get_level_values(0)))]
crime_station.columns = tmp구별 데이터로 정리
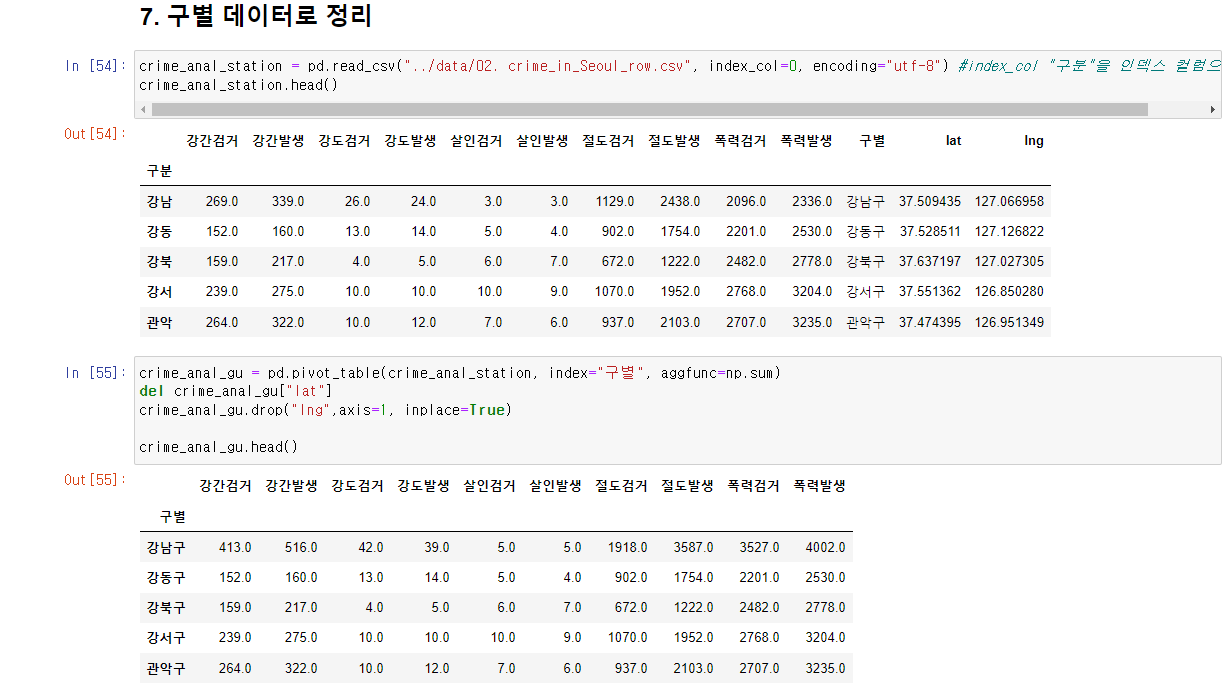
- 구별을 인덱스로 피봇테이블 생성
- 필요한 컬럼 생성, 필요없는 컬럼 제거한다.
# 데이터 정리
# 위도, 경도 삭제
crime_anal_gu = pd.pivot_table(crime_anal_station, index="구별", aggfunc=np.sum)
del crime_anal_gu["lat"]
crime_anal_gu.drop("lng",axis=1, inplace=True)
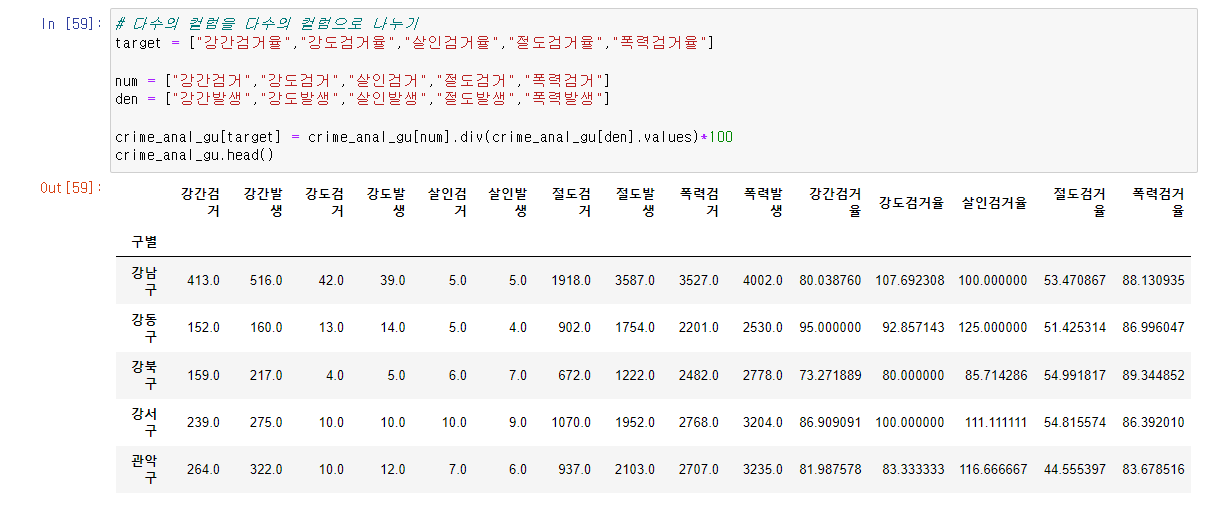
# 다수의 컬럼을 다수의 컬럼으로 나누기
target = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
num = ["강간검거","강도검거","살인검거","절도검거","폭력검거"]
den = ["강간발생","강도발생","살인발생","절도발생","폭력발생"]
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values)*100
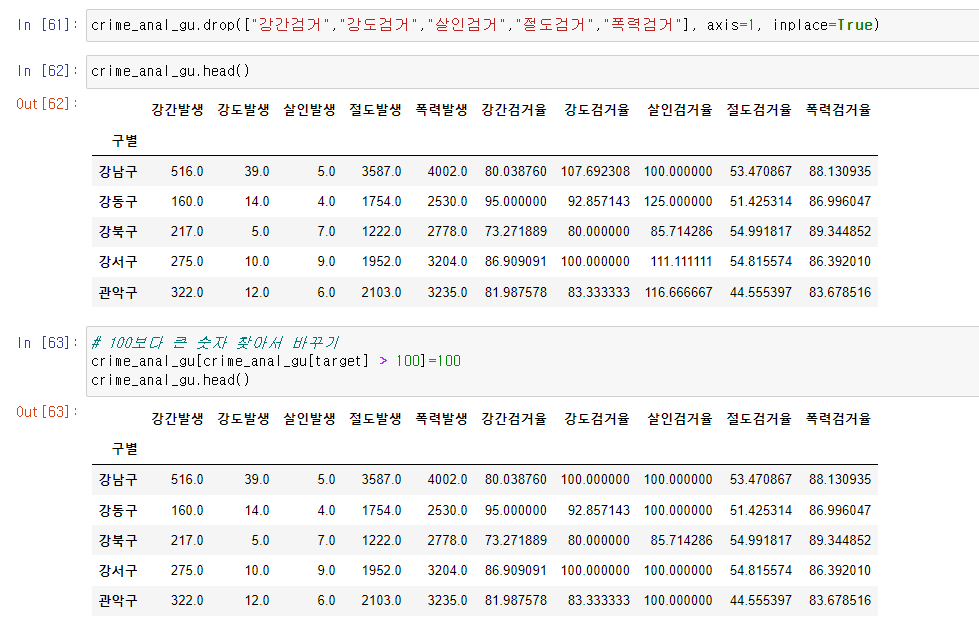
# 필요없는 컬럼 제거
crime_anal_gu.drop(["강간검거","강도검거","살인검거","절도검거","폭력검거"], axis=1, inplace=True)
# 100보다 큰 숫자 찾아서 바꾸기
crime_anal_gu[crime_anal_gu[target] > 100]=100
crime_anal_gu.head()
# 컬럼이름 변경
crime_anal_gu.rename(columns={"강간발생":"강간","강도발생":"강도","살인발생":"살인","절도발생":"절도","폭력발생":"폭력"},
inplace=True)
crime_anal_gu.head()범죄데이터 정렬을 위한 데이터 정렬
- 새로운 데이터 프레임을 만들어 범죄 수를 정교화
- 검거율 추가
- 구별 CCTV 자료에서 인구수와 CCTV수 추가
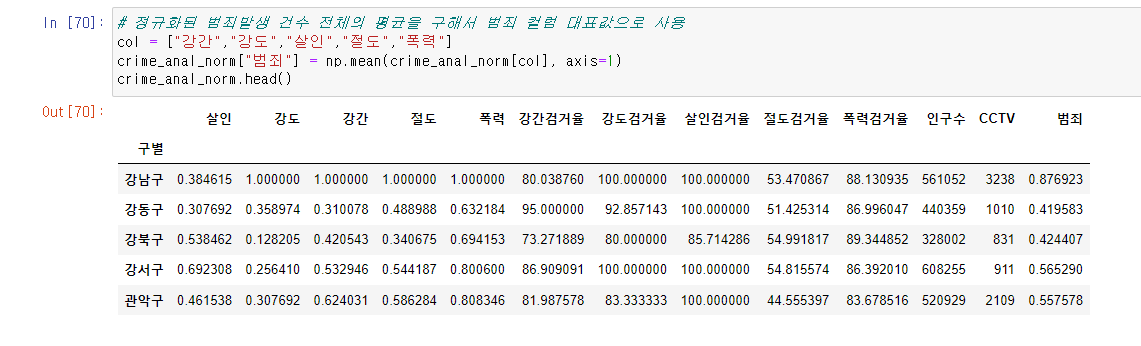
- np.mean() 사용하여 평균 구하기

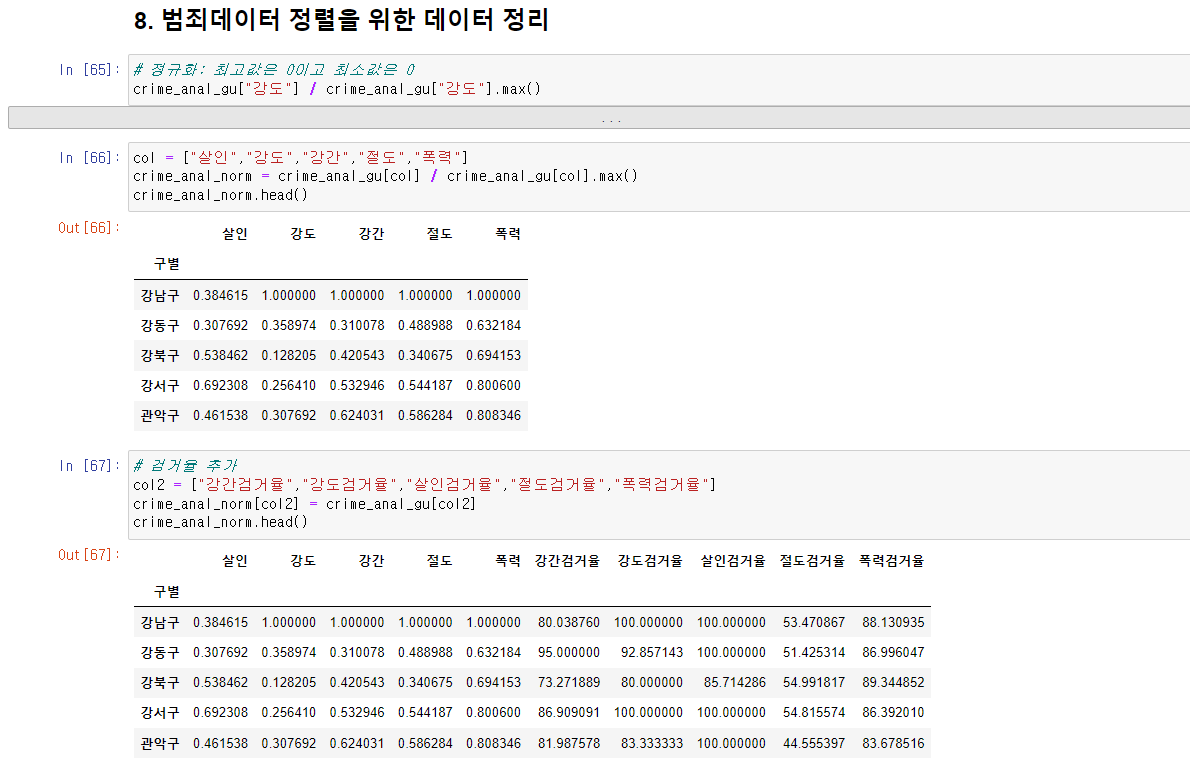
# 데이터 정렬
# 정규화: 최고값은 0이고 최소값은 0
col = ["살인","강도","강간","절도","폭력"]
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
# 검거율 추가
col2 = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_norm[col2] = crime_anal_gu[col2]
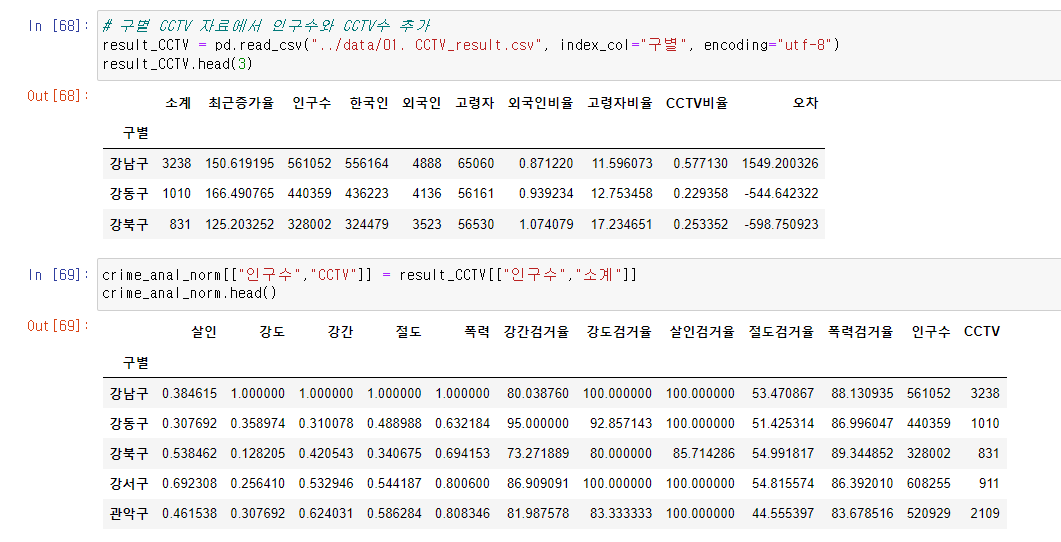
# 구별 CCTV 자료에서 인구수와 CCTV수 추가
result_CCTV = pd.read_csv("../data/01. CCTV_result.csv", index_col="구별", encoding="utf-8")
crime_anal_norm[["인구수","CCTV"]] = result_CCTV[["인구수","소계"]]
# 정규화된 범죄발생 건수 전체의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ["강간","강도","살인","절도","폭력"]
crime_anal_norm["범죄"] = np.mean(crime_anal_norm[col], axis=1)서울시 범죄 현황 데이터 시각화
- 데이터 사이의 관계를 한눈에 보기 쉽도록 pairplot, heatmap으로 데이터를 시각화한다.


# 서울시 범죄 현황 데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams["axes.unicode_minus"] = False
rc("font", family="Malgun gothic")
%matplotlib inline
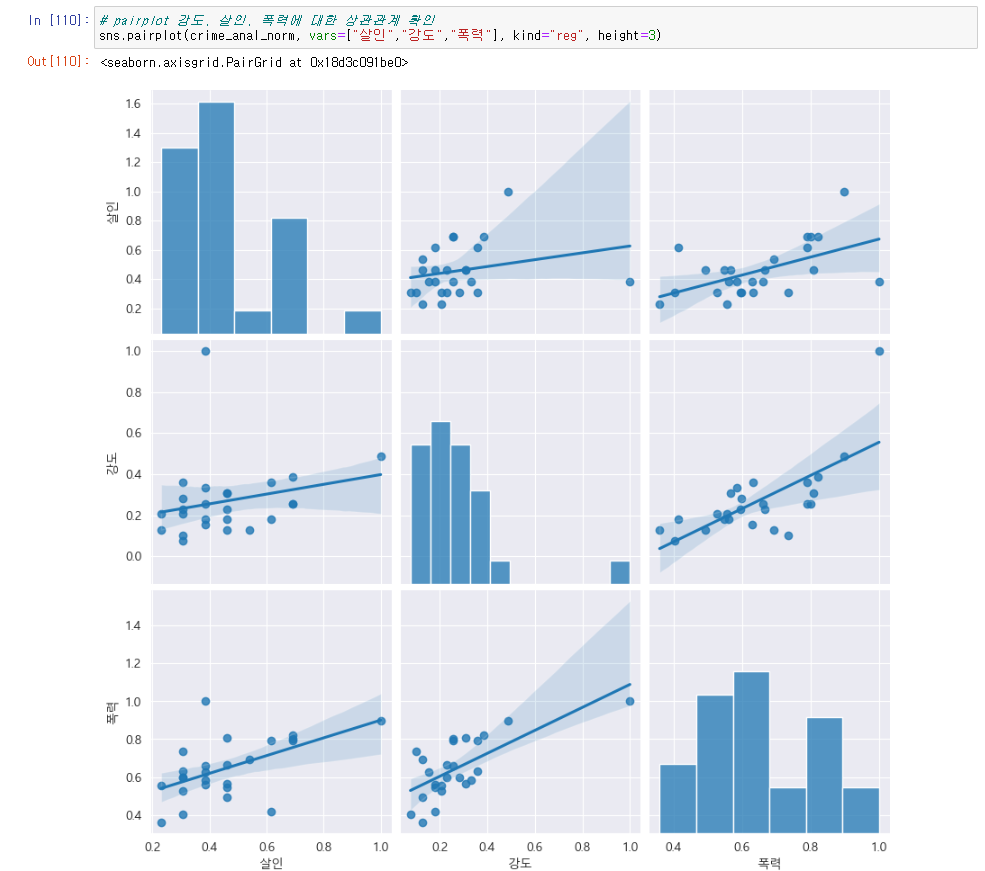
# pairplot 강도, 살인, 폭력에 대한 상관관계 확인
sns.pairplot(crime_anal_norm, vars=["살인","강도","폭력"], kind="reg", height=3)
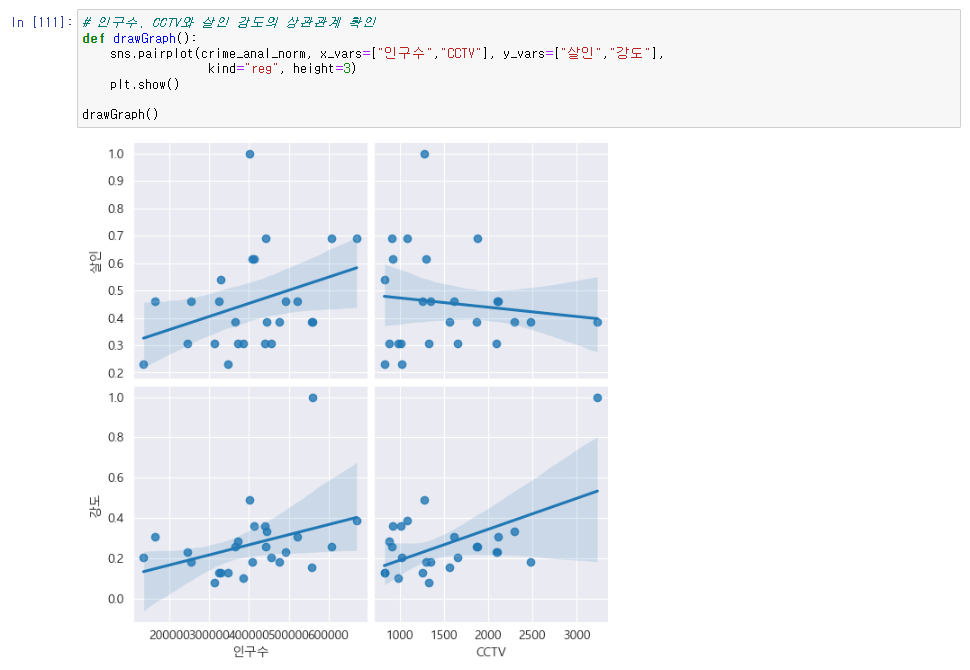
# 인구수, CCTV와 살인 강도의 상관관계 확인
def drawGraph():
sns.pairplot(crime_anal_norm, x_vars=["인구수","CCTV"], y_vars=["살인","강도"],
kind="reg", height=3)
plt.show()
drawGraph()
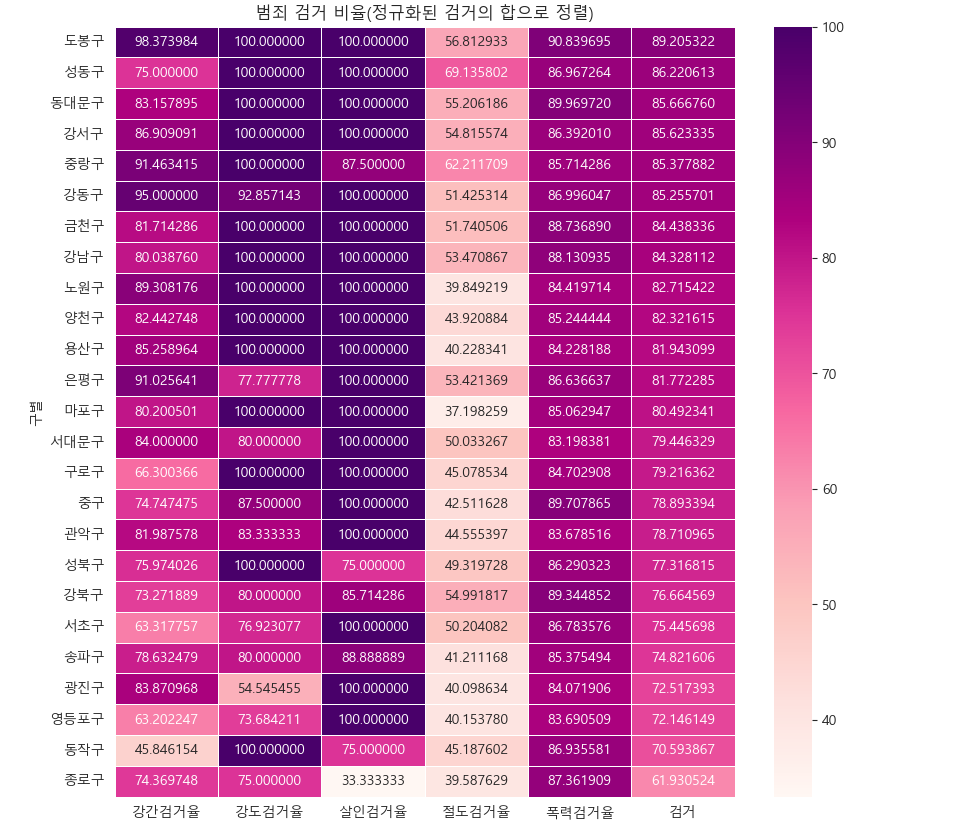
# 검거율 heatmap
# 검거 컬럼을 기준으로
def drawGraph():
# 데이터 프레임 설정
target_col = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율","검거"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="검거", ascending=False)
# 그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(crime_anal_norm_sort[target_col], annot=True, fmt="f", linewidths=0.5, cmap="RdPu")
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬)")
plt.show()
drawGraph()
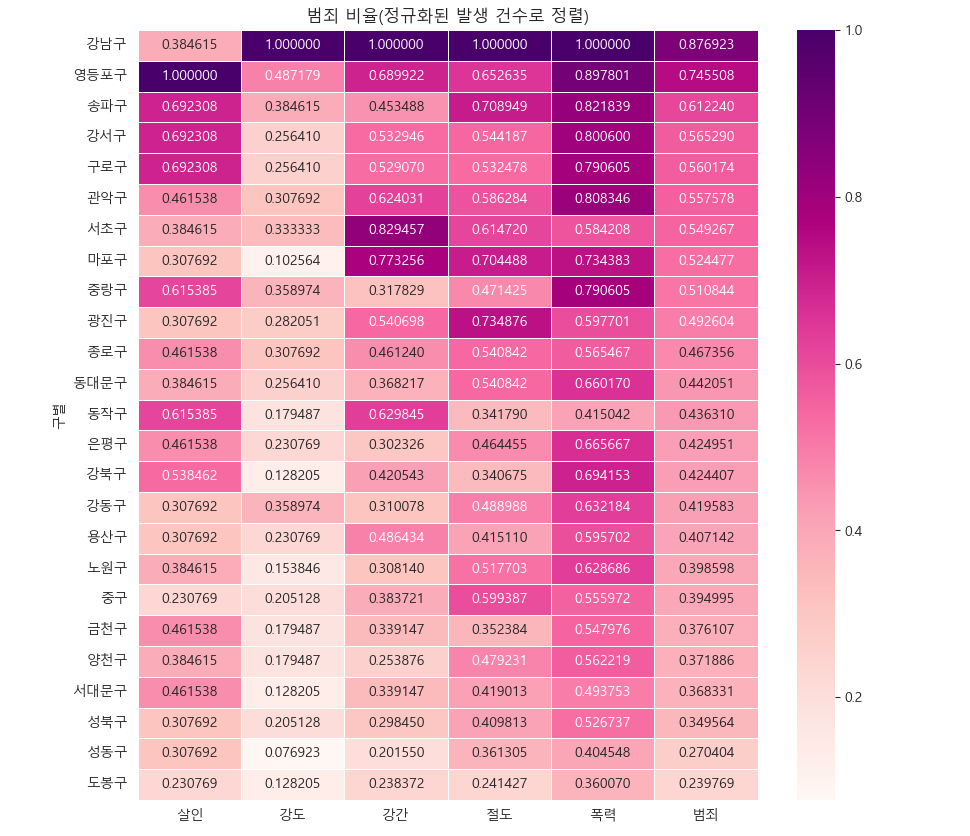
# 범죄발생 건수 heatmap
# 범죄 컬럼을 기준으로
def drawGraph():
# 데이터 프레임 설정
target_col = ["살인","강도","강간","절도","폭력","범죄"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="범죄", ascending=False)
# 그래프 설정
plt.figure(figsize=(10,10))
sns.heatmap(crime_anal_norm_sort[target_col], annot=True, fmt="f", linewidths=0.5, cmap="RdPu")
plt.title("범죄 비율(정규화된 발생 건수로 정렬)")
plt.show()
drawGraph()서울시 범죄 현황에 대한 지도 시각화
- 서울시 구별 경계선 파일은 json으로 읽어와 지도에 범죄 현황에 맞게 시각화, 경찰서 위치와 검거 수치로 지도 시각화

geo_path = "../data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding="utf-8"))
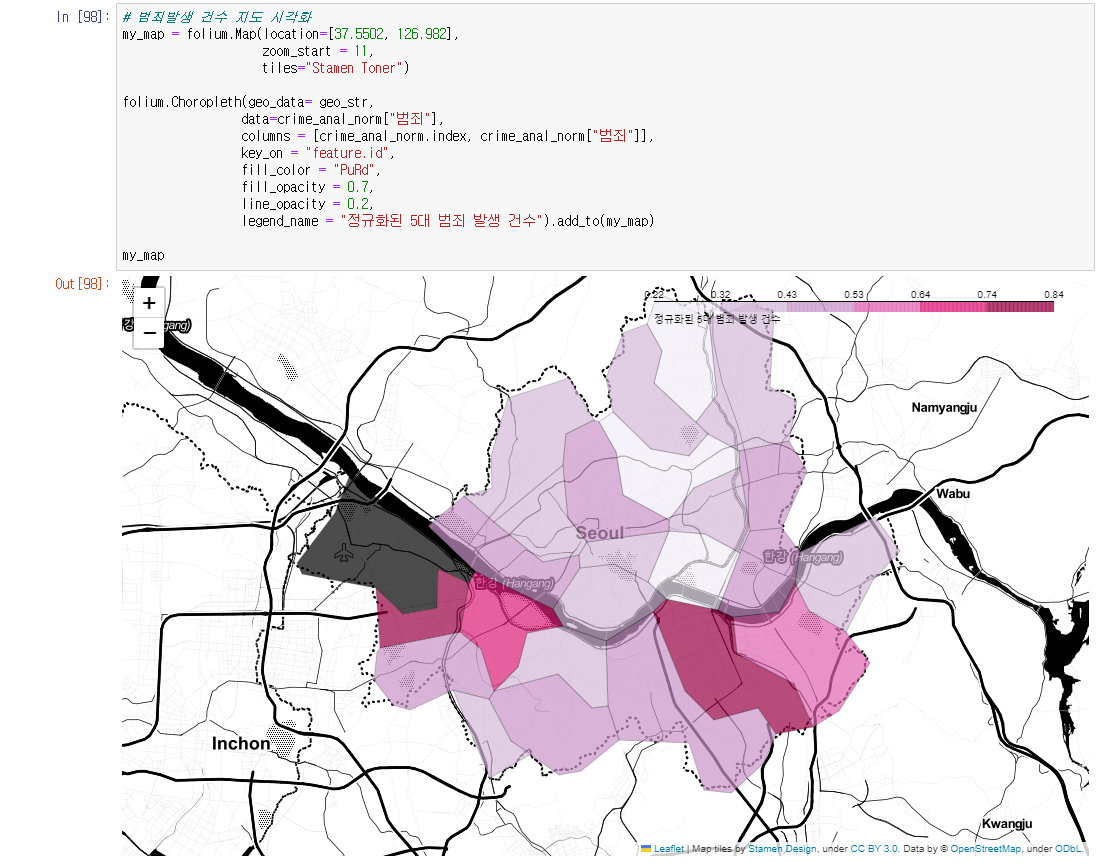
# 범죄발생 건수 지도 시각화
my_map = folium.Map(location=[37.5502, 126.982],
zoom_start = 11,
tiles="Stamen Toner")
folium.Choropleth(geo_data= geo_str,
data=crime_anal_norm["범죄"],
columns = [crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on = "feature.id",
fill_color = "PuRd",
fill_opacity = 0.7,
line_opacity = 0.2,
legend_name = "정규화된 5대 범죄 발생 건수").add_to(my_map)
my_map
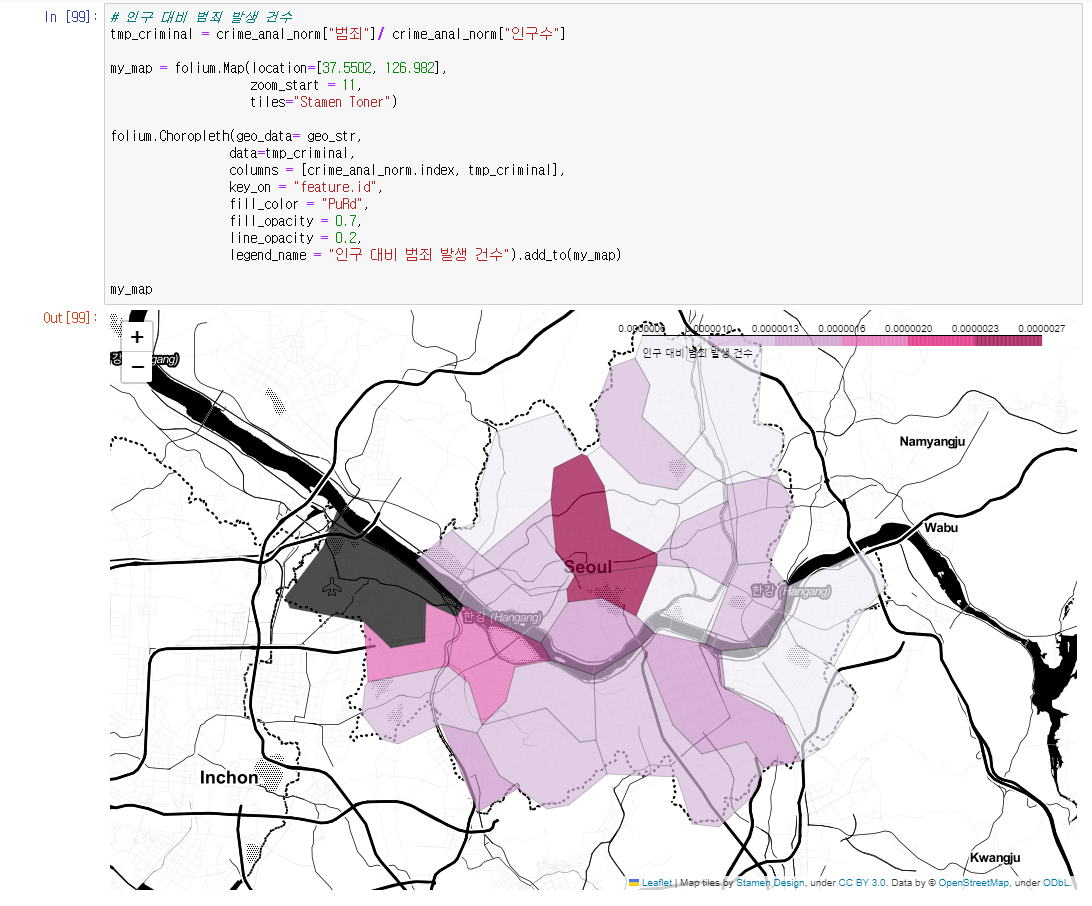
# 인구 대비 범죄 발생 건수
tmp_criminal = crime_anal_norm["범죄"]/ crime_anal_norm["인구수"]
my_map = folium.Map(location=[37.5502, 126.982],
zoom_start = 11,
tiles="Stamen Toner")
folium.Choropleth(geo_data= geo_str,
data=tmp_criminal,
columns = [crime_anal_norm.index, tmp_criminal],
key_on = "feature.id",
fill_color = "PuRd",
fill_opacity = 0.7,
line_opacity = 0.2,
legend_name = "인구 대비 범죄 발생 건수").add_to(my_map)
my_map
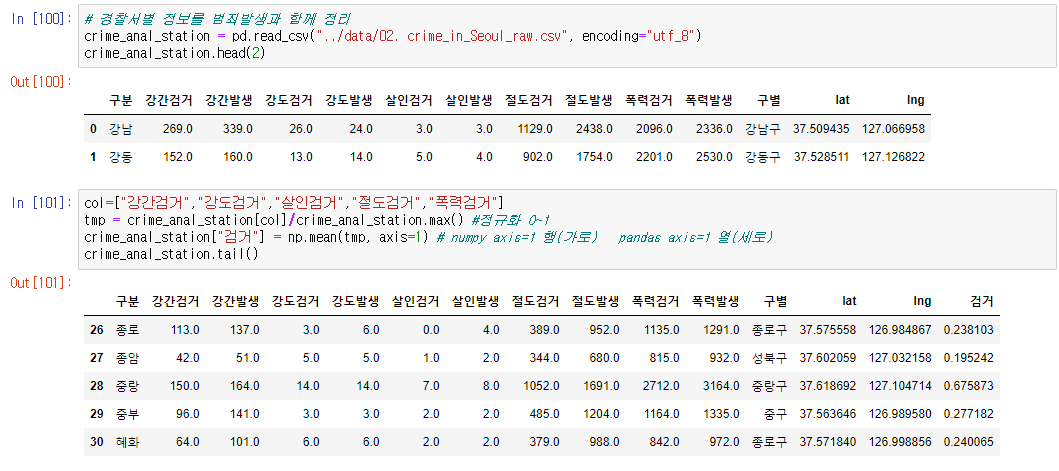
# 경찰서별 정보를 범죄발생과 함께 정리
crime_anal_station = pd.read_csv("../data/02. crime_in_Seoul_raw.csv", encoding="utf_8")
crime_anal_station.head(2)
col=["강간검거","강도검거","살인검거","절도검거","폭력검거"]
tmp = crime_anal_station[col]/crime_anal_station.max() #정규화 0~1
crime_anal_station["검거"] = np.mean(tmp, axis=1) # numpy axis=1 행(가로) pandas axis=1 열(세로)
crime_anal_station.tail()
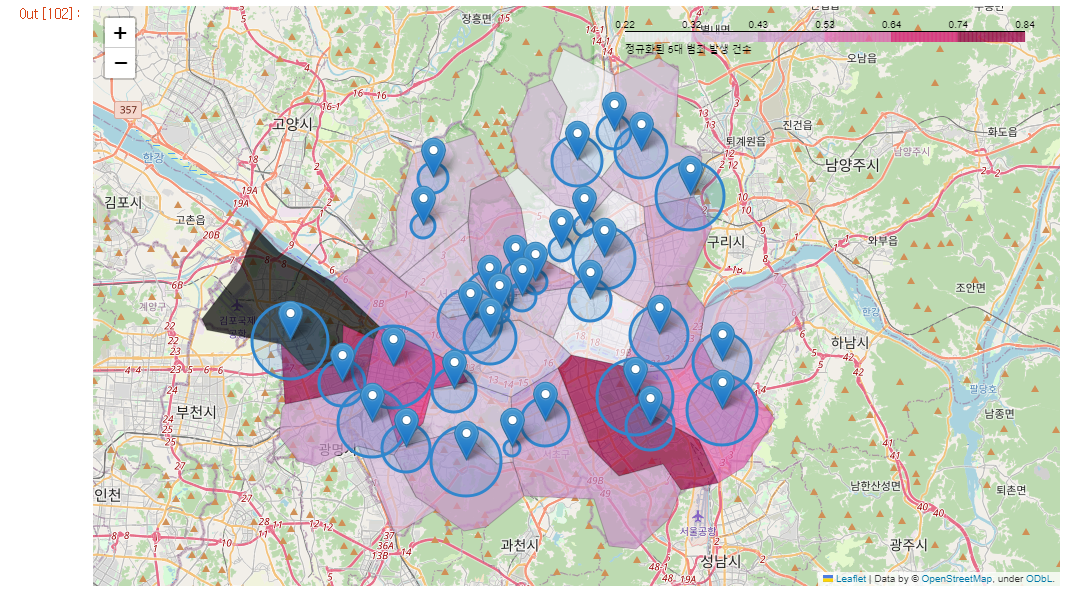
# 경찰서 위치 마커, 원 표시
my_map = folium.Map(location=[37.5502, 126.982],
zoom_start = 11)
folium.Choropleth(geo_data= geo_str,
data=crime_anal_norm["범죄"],
columns = [crime_anal_norm.index, crime_anal_norm["범죄"]],
key_on = "feature.id",
fill_color = "PuRd",
fill_opacity = 0.7,
line_opacity = 0.2,
legend_name = "정규화된 5대 범죄 발생 건수").add_to(my_map)
for idx, rows in crime_anal_station.iterrows():
folium.Marker(location = [rows["lat"], rows["lng"]],
popup= "서울"+ str(rows["구분"]) +"경찰서").add_to(my_map)
folium.CircleMarker(location = [rows["lat"], rows["lng"]],
radius= rows["검거"]*50,
fill = True,
color = "#3186cc",
tooltip = rows["구분"] + ":" + "%.2f" % rows["검거"],
fill_color = "#3186cc").add_to(my_map)
my_map서울시 범죄 현황 발생 장소 분석
- 추가검증
범죄가 일어나는 장소와 범죄의 관계를 확인해보자.
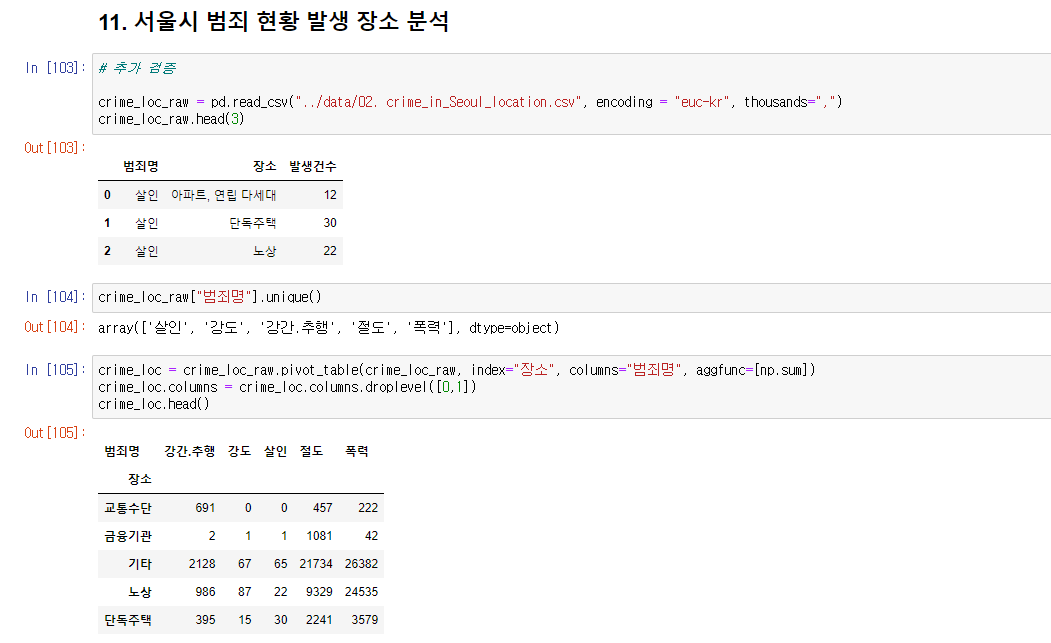
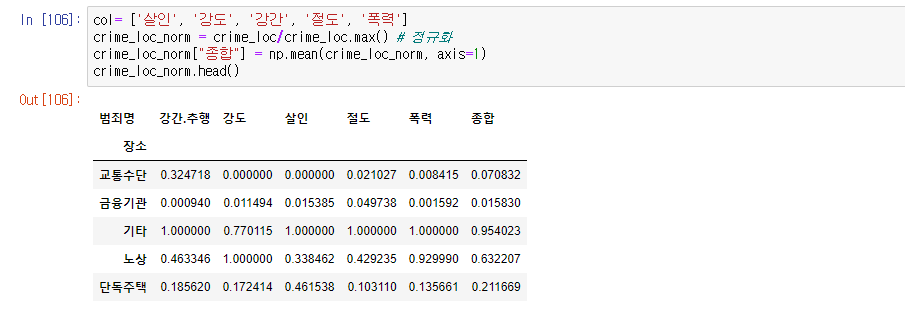
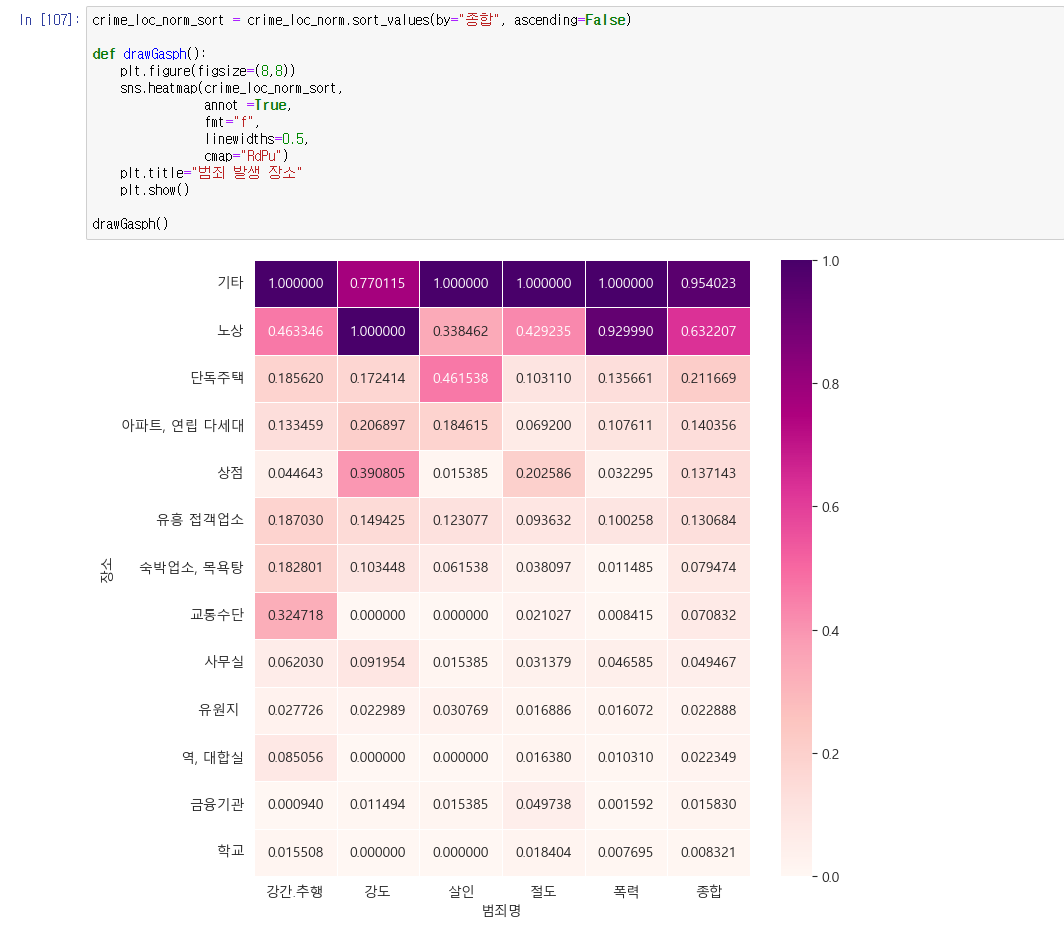
범죄는 기타(정해지지않은 장소),노상(길거리), 단독주택 등에서 많이 일어나는 것으로 보인다.
# 추가 검증
crime_loc_raw = pd.read_csv("../data/02. crime_in_Seoul_location.csv", encoding = "euc-kr", thousands=",")
crime_loc = crime_loc_raw.pivot_table(crime_loc_raw, index="장소", columns="범죄명", aggfunc=[np.sum])
crime_loc.columns = crime_loc.columns.droplevel([0,1])
col= ['살인', '강도', '강간', '절도', '폭력']
crime_loc_norm = crime_loc/crime_loc.max() # 정규화
crime_loc_norm["종합"] = np.mean(crime_loc_norm, axis=1)
crime_loc_norm_sort = crime_loc_norm.sort_values(by="종합", ascending=False)
def drawGasph():
plt.figure(figsize=(8,8))
sns.heatmap(crime_loc_norm_sort,
annot =True,
fmt="f",
linewidths=0.5,
cmap="RdPu")
plt.title="범죄 발생 장소"
plt.show()
drawGasph() 프로젝트 완성
- 프로젝트의 목표는 강남3구의 비교적 안전한지 확인하는것
- 프로젝트 정리
강남구 같은 경우 인구수가 많아 범죄 발생수가 가장 많은것으로 보였으며 다른 강남3구도 범죄수가 적은 편은 아니었다. 하지만 인구대비로 시각화 하여 보니 인구대비 범죄 발생이 높은 편은 아니었다. 범죄 발생수가 많은만큼 범죄 검거수도 높았지만 유의미할 정도로 높지는 않았다. - 프로젝트 결론
강남3구가 비교적 안전하다고 할 근거 부족하다.
이글은 제로베이스 데이터 취업스쿨의 강의자료 일부를 발췌하여 작성되었습니다.

데이터 공부합니다