
Beautiful Soup
- Beautiful Soup
HTML정보로 부터 원하는 데이터를 가져오기 쉽게, 비슷한 분류의 데이터별로 나누어주는 파이썬 라이브러리
(보통 html정보를 가져오는 urllib.request.urlopen() 모듈과 함께 사용되곤 한다.)
Beautiful Soup을 사용하여 해당 페이지의 html정보를 가져올수있다.
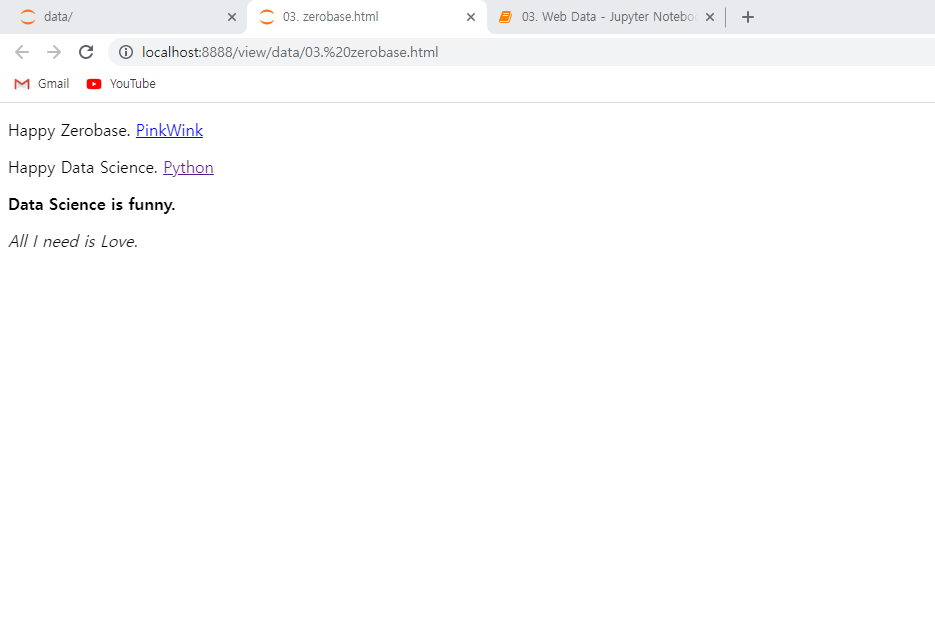
from bs4 import BeautifulSoup
page = open("../data/03. zerobase.html", "r").read()
soup = BeautifulSoup(page, "html.parser")
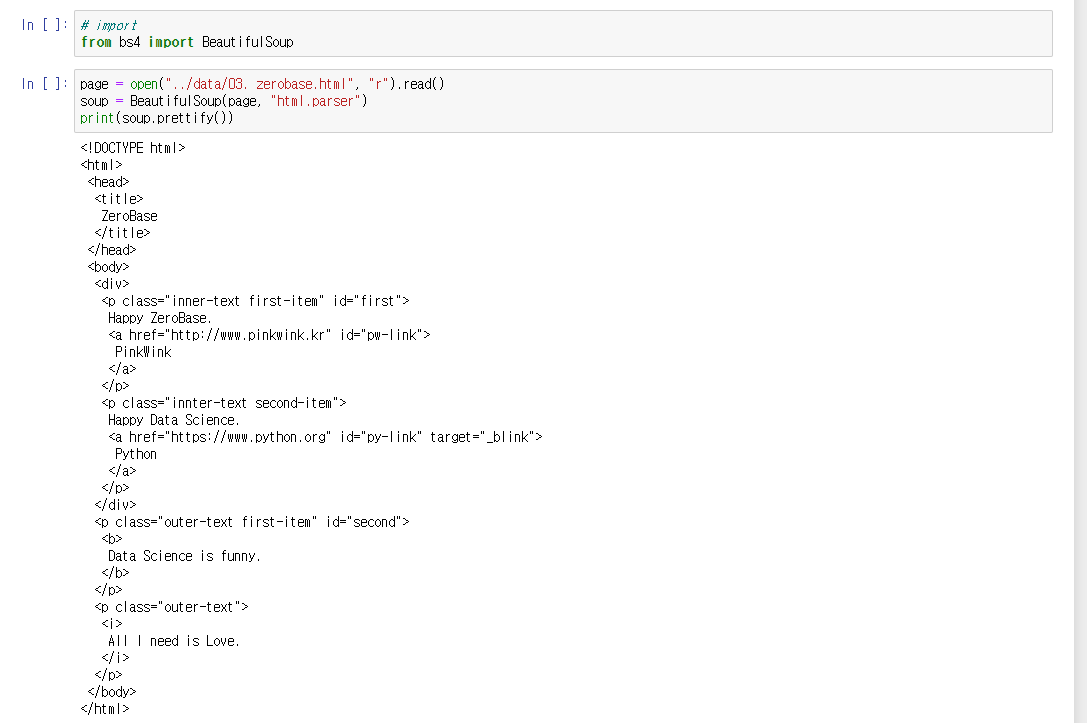
print(soup.prettify())코드를 이용해 html의 태그정보를 확인할 수 있다.
# head 태그 확인
soup.head
# body 태그 확인
soup.body
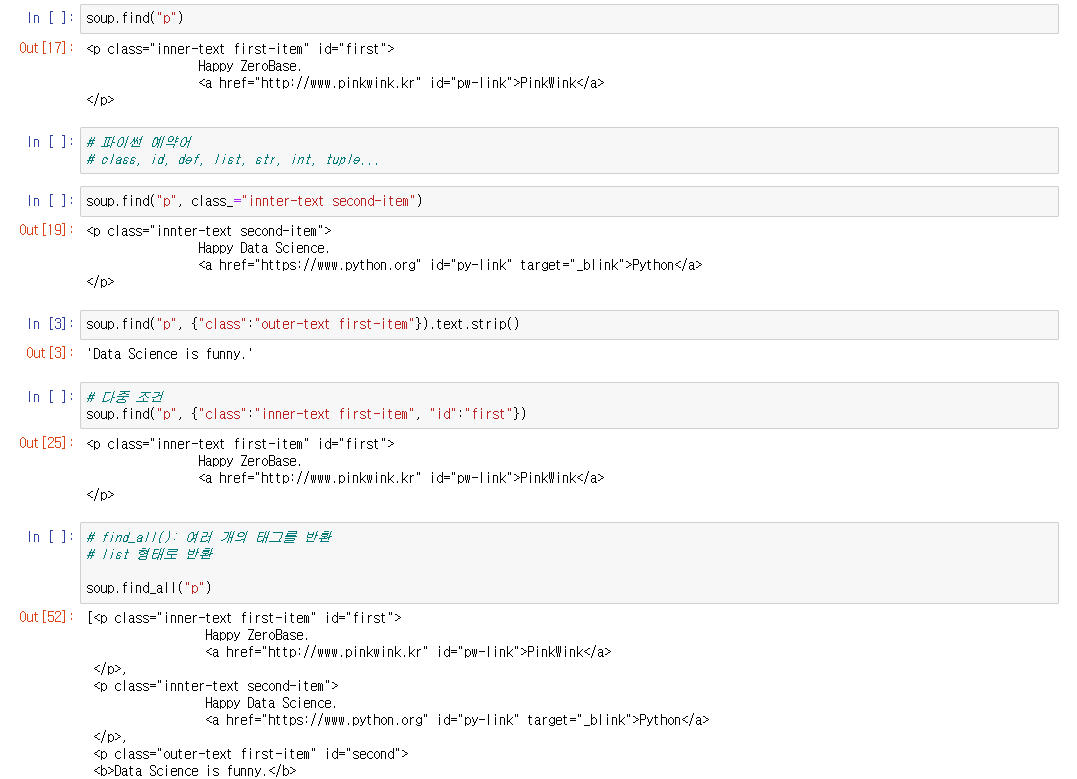
# find(): 첫번째 태그만 출력
soup.find("p")
# 다중조건
soup.find("p", {"class":"outer-text first-item"})
# find_all(): 여러개의 태그를 반환
soup.find_all("p")
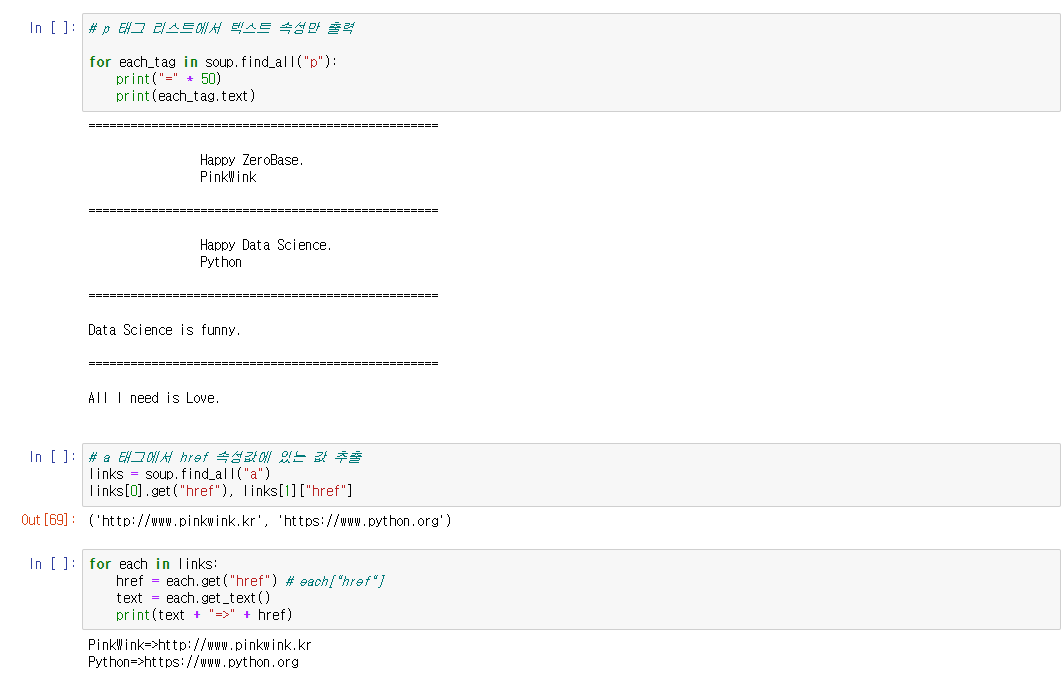
# p 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all("p"):
print("=" * 50)
print(each_tag.text)
# a 태그에서 href 속성값에 있는 값 추출
links = soup.find_all("a")
for each in links:
href = each.get("href") # each["href"]
text = each.get_text()
print(text + "=>" + href)BeautifulSoup 예제1 - 네이버 금융
urlopen과 BeautifulSoup를 사용하여 웹사이트(네이버 금융정보)의 html 정보를 받아온다.
사이트의 태그정보를 가져오는 방법은 아래 3가지
from urllib.request import urlopen
from bs4 import BeautifulSoup
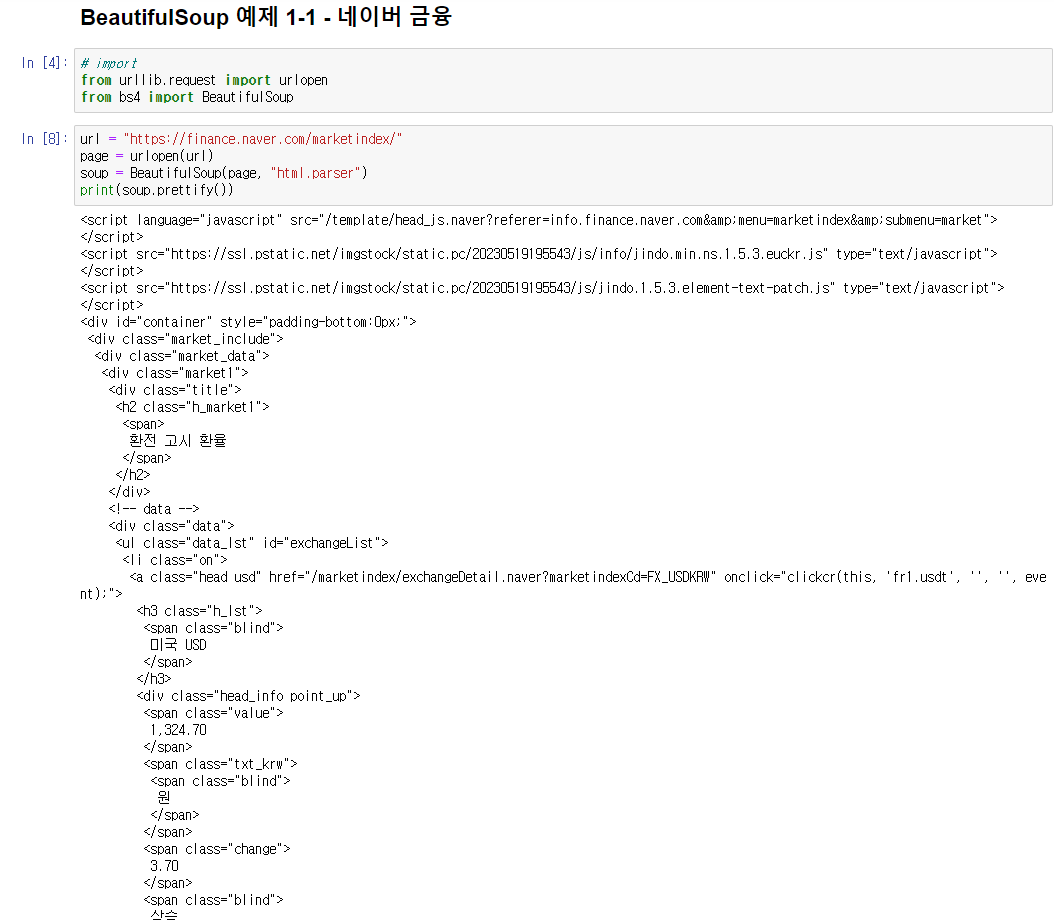
url = "https://finance.naver.com/marketindex/"
page = urlopen(url)
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())
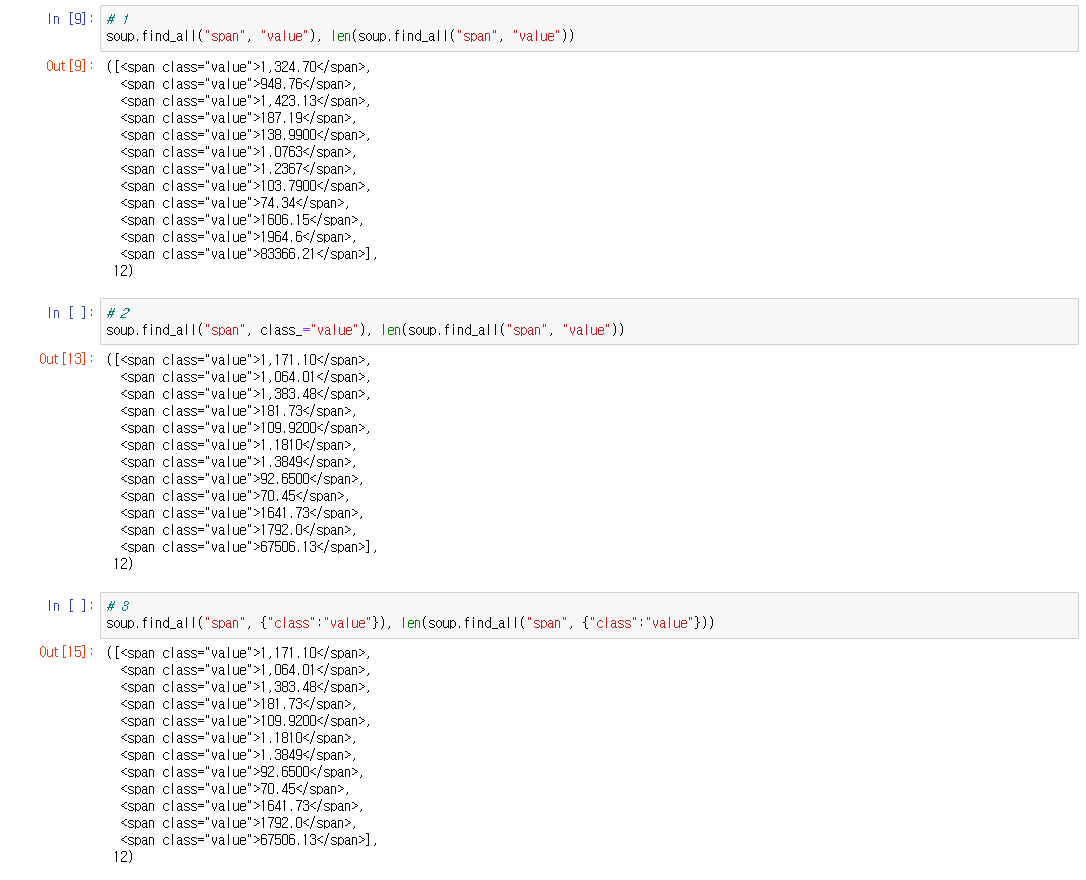
# 1
soup.find_all("span", "value"), len(soup.find_all("span", "value"))\
# 2
soup.find_all("span", class_="value"), len(soup.find_all("span", "value"))
# 3
soup.find_all("span", {"class":"value"}), len(soup.find_all("span", {"class":"value"}))requests를 사용해서 html정보를 요청받아 올 수 있다.
필요한 정보를 해당 태그를 이용하여 정보를 받아온다.
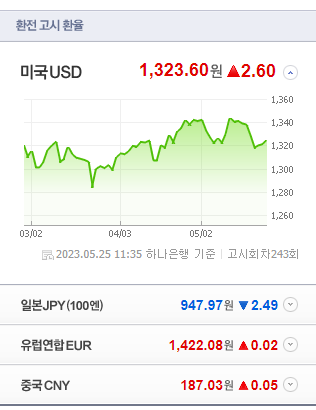
4가지의 환율정보를 반복문을 통해 가지고 온다.

import requests
# from urllib.request.Request
from bs4 import BeautifulSoup
import pandas as pd
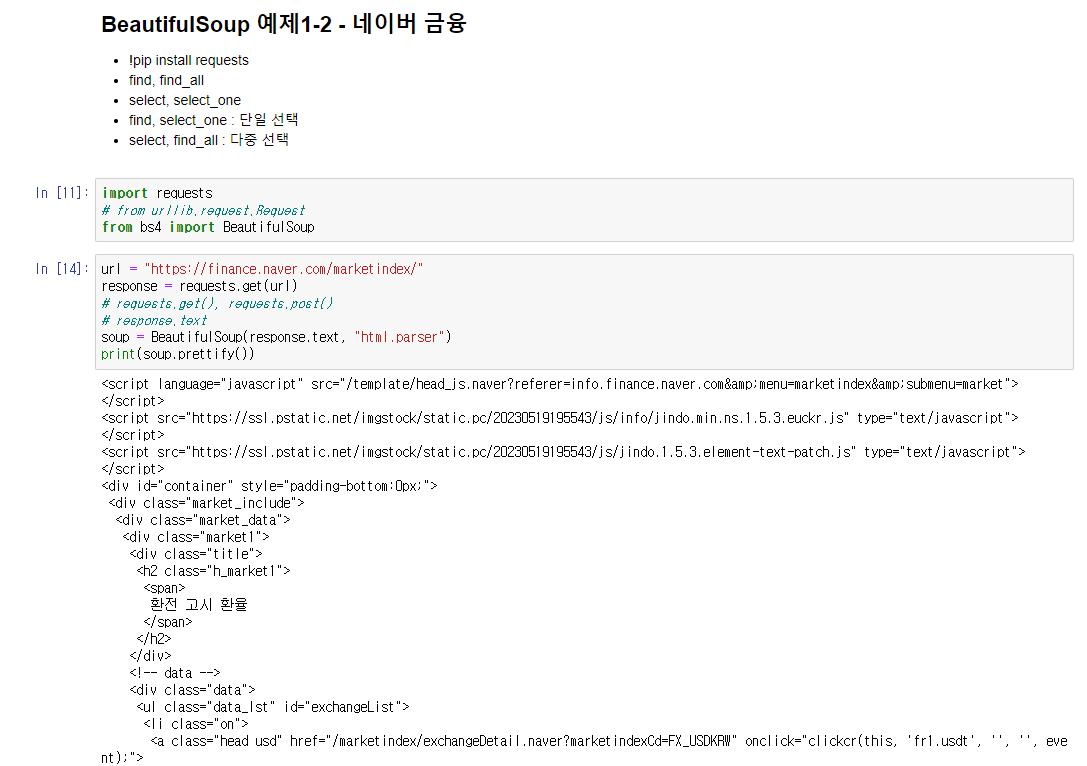
url = "https://finance.naver.com/marketindex/"
response = requests.get(url)
# requests.get(), requests.post()
# response.text
soup = BeautifulSoup(response.text, "html.parser")
print(soup.prettify())
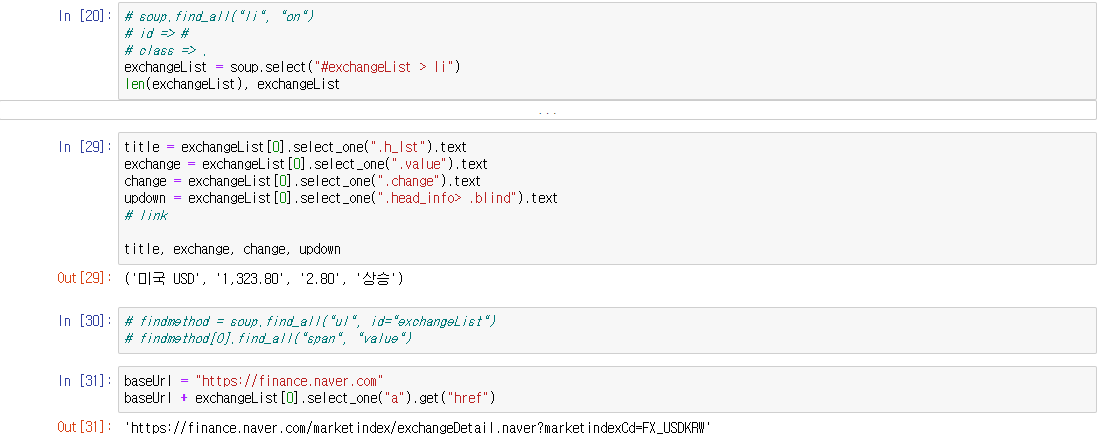
exchangeList = soup.select("#exchangeList > li")
len(exchangeList), exchangeList
title = exchangeList[0].select_one(".h_lst").text
exchange = exchangeList[0].select_one(".value").text
change = exchangeList[0].select_one(".change").text
updown = exchangeList[0].select_one(".head_info> .blind").text
# 4개 데이터 수집
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title": item.select_one(".h_lst").text,
"exchnage": item.select_one(".value").text,
"change": item.select_one(".change").text,
"updown": item.select_one(".head_info> .blind").text,
"link": baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel("./naverfinance.xlsx", encoding="utf-8")BeautifulSoup 예제2 - 위키백과 문서 정보 가져오기
url에 한글이 있으면 오류가 날 수 있어서 중괄호로 처리하고 urllib.parse.quote로 글자를 URL로 인코딩해준다.
import urllib
from urllib.request import urlopen, Request
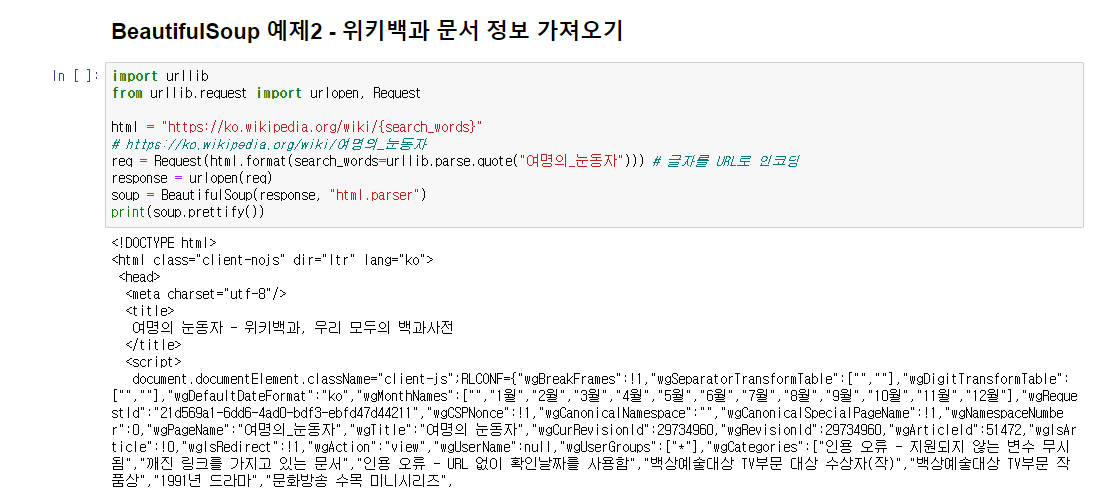
html = "https://ko.wikipedia.org/wiki/{search_words}"
# https://ko.wikipedia.org/wiki/여명의_눈동자
req = Request(html.format(search_words=urllib.parse.quote("여명의_눈동자"))) # 글자를 URL로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())
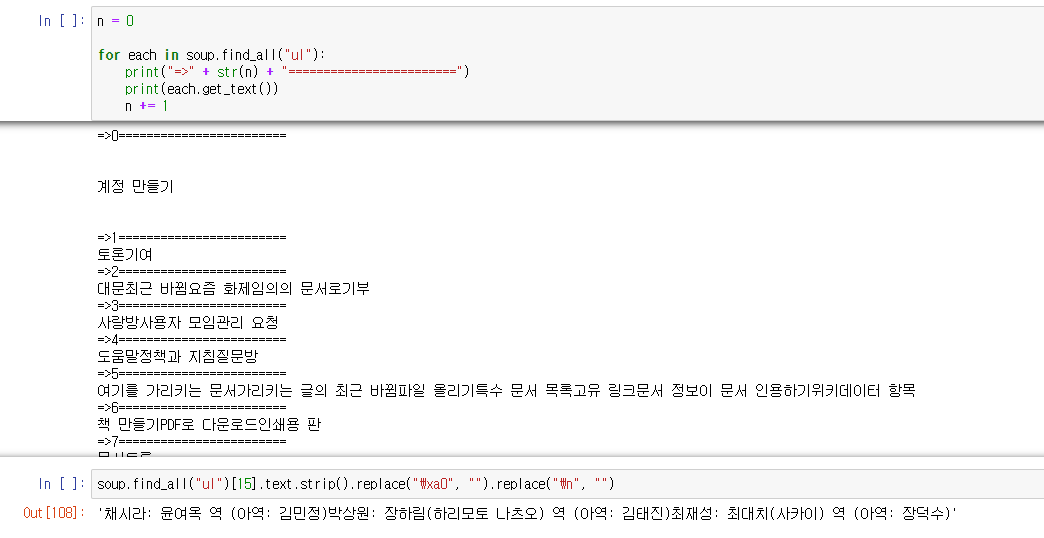
n = 0
for each in soup.find_all("ul"):
print("=>" + str(n) + "========================")
print(each.get_text())
n += 1
soup.find_all("ul")[15].text.strip().replace("\xa0", "").replace("\n", "")이글은 제로베이스 데이터 취업스쿨의 강의자료 일부를 발췌하여 작성되었습니다.

데이터 공부합니다