개요
앞서 single-cycle design에서는 clock cycle을 제일 느린 load 명령어에 맞추어야 했기 때문에 성능의 저하가 있었다. 이를 Pipelining으로 해결할 수 있다
예시
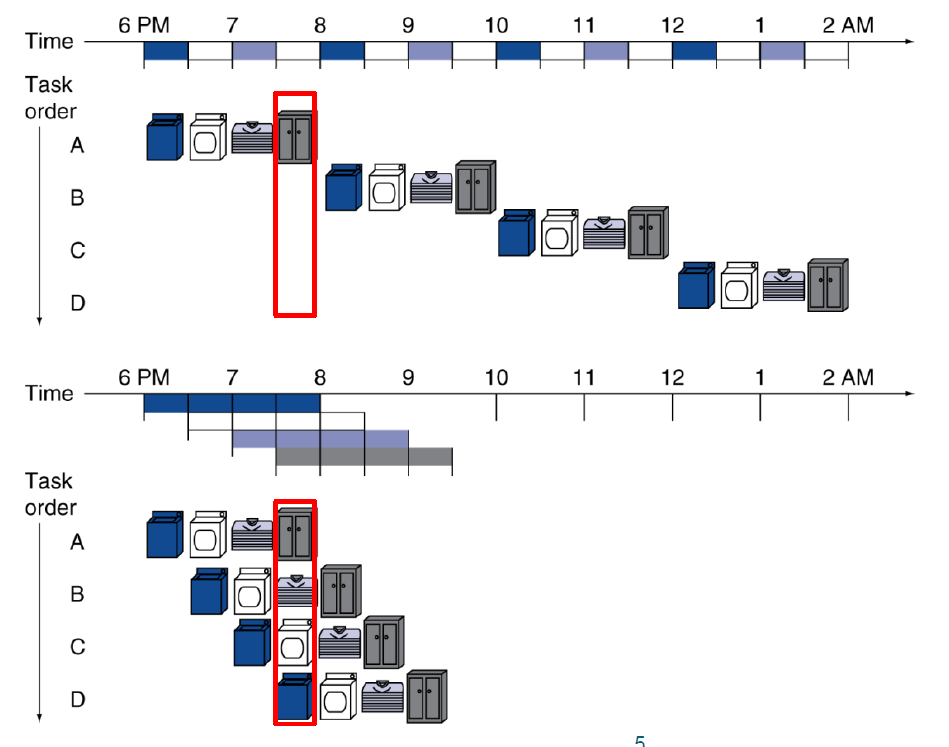
아래의 그림은 pipelining을 적용한 세탁과정이고, 위의 그림은 적용하지 않았다.
그림을 보면 A B C D라는 자원이 있는데, pipelining을 적용하지 않을 경우 각 시간(stage)마다 유휴 자원(놀고있는 자원)이 3개나 생긴다.
그러나 pipeline을 적용할 경우 유휴 자원이 줄어들게 된다.
이렇게 병렬적으로 작업을 처리하는 방법을 overlapping execution이라고 하며, pipelining 이라고도 한다.
pipelining을 적용하면 다음의 효과가 있다.
- 처리량을 향상시킨다
- stage의 수에 비례해 속도를 향상시킨다
Five Stages

파이프라이닝의 five stage는 다음과같다
- IF : instruction memory에서 명령어를 가져온다
- ID : 명령어를 해독하고, 레지스터 파일에서 데이터를 읽는다
- EX : 주소나 데이터 값을 연산한다
- MEM : data memory에 접근해 데이터를 읽거나 쓴다
- WB : 데이터를 레지스터에 쓴다
성능 비교
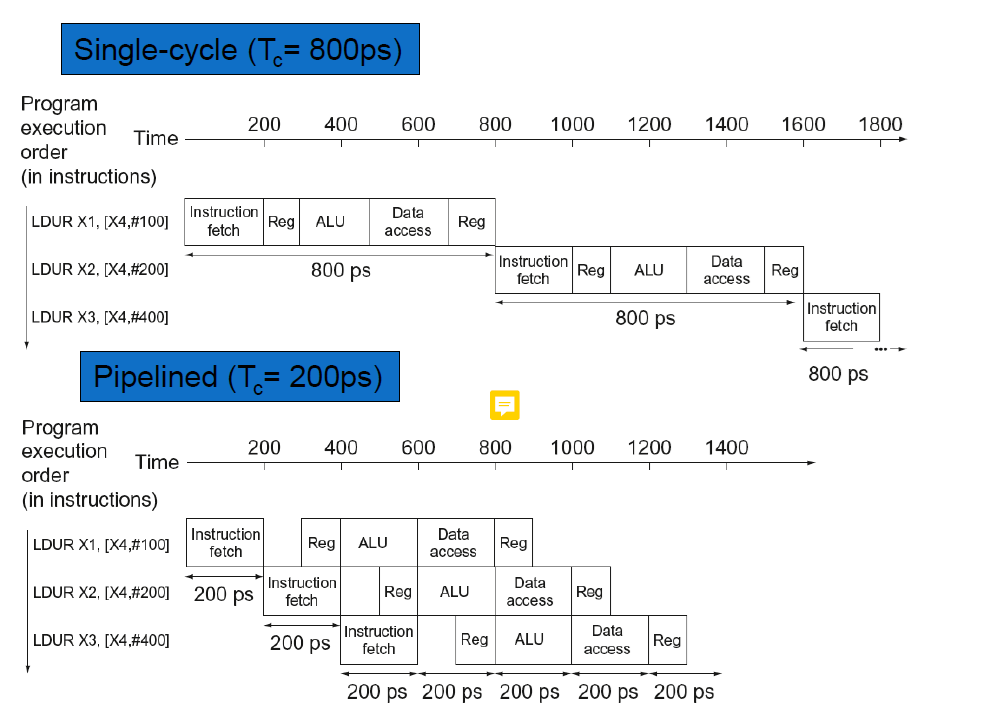
그림을 보면 파이프라이닝을 적용했을 때 작업의 처리량이 2400/1400 = 1.7배 정도 향상된다.
파이프라이닝에서는 각 stage에서 가장 오래걸리는 명령어에 clock cycle을 맞춰야한다.
그래서 100ps만 걸리는 reg task가 200ps를 차지한다.
따라서 단위 시간당 처리하는 명령어의 수(throughput)만 늘어난 것이지 각 명령어 당 실행 시간(execution time)은 줄어들지 않았다.
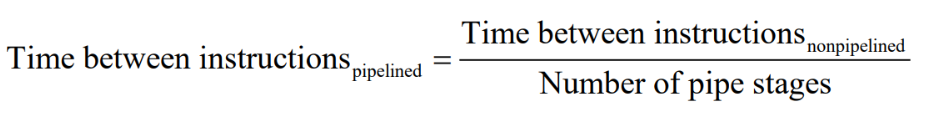
stage의 수가 5이기 때문에 이론적으로는 파이프라이닝을 적용했을 때 수행 속도가 5배나 더 빨라야하지만 그렇지 못하다 왜냐하면
- 각 stage가 실행되는 시간이 다르다(not balanced)
- hazard라는 overhead 발생한다(뒤에 설명)
따라서 Pipeline 기법은 각 명령어의 수행 시간을 줄이지 않고서도, 명령어 throughput을 향상시킬 수 있다
LEGv8에서의 파이프라이닝
LEGv8 아키텍처는 다음과 같은 특징이 있기에 파이프라이닝에 적합하다
- 모든 명령어가 32비트로 고정돼있고, 명령어 포맷이 정형화돼있어 IF,ID 단계를 one cycle에 처리하는데 용이하다
- 메모리에 접근하는 명령어가 load, store뿐이기에 EX, MEM 단계를 단순화시켜 하드웨어를 만들 수 있기 떄문이다
- 메모리 align을 잘해놓기 떄문에 불필요한 메모리 접근이 없다
Shading Component
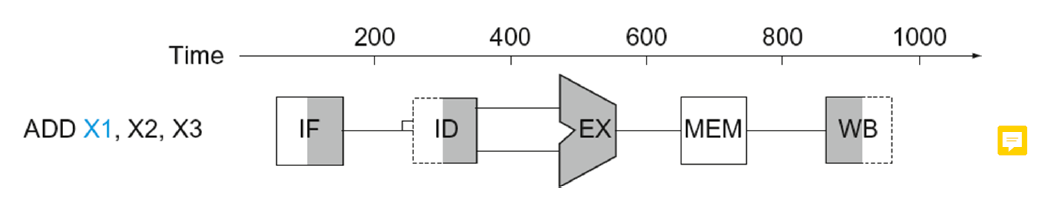
여기서 네모는 데이터가 읽혀지고 저장되는 저장소를 의미한다.
데이터의 흐름은 왼쪽에서 오른쪽으로 이루어진다.
회색으로 칠해져있는 것은 그 구성요소가 명령어에 의해 사용되고 있음을 나타낸다.
ALU가 칠해져있는 그림은 ALU가 연산을 하고 있음을의미한다
ADD는 Memory에 접근하지 않으므로 MEM은 칠해지지 않는다
왼쪽으로 칠해져 있을 시에는들어온 input값을 저장하는 것(write)이고,
오른쪽으로 칠해져 있을 시에는 output을 읽어내는 것(read)이다
Hazard
Hazard란 Pipelining에서 여러 명령어가 병렬적으로 수행되고 있을 때 이전 명령어가 다음 명령어의 수행을 방해하는 상황을 말한다
Structure Hazard
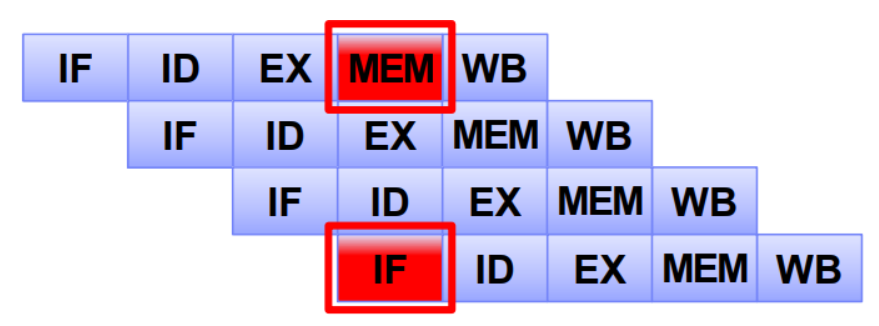
자원을 사용하려고 할 때 일어나는 충돌을 의미한다.
LEGv8 Pipline에서는 단일 메모리에 다음과 같이 MEM과 IF Stage에서 동시에 메모리에 접근을 하려고 할 때 발생한다.
앞의 single cycle 디자인에서 두 개의 메모리로 분리 (instruction memory, data memory)함으로써 이 충돌을 해결했다.
또한 CPU는 CPU, Reg, L1, L2, L3(캐시)의 계층구조를 가지는데, L1단계에서 I-cache,D(DRAM)-cache를 분리해서 해결한다
Data Hazard
데이터를 read or write 해야하는데 앞의 명령어가 수행될 때까지 기다려야 하는 상황이다.
데이터 종속성에 의한 충돌이다.

덧셈 결과를 x19에 저장해야 하고, 그 저장된 값을 바탕으로 sub 해야 하는데, 저장되기 전인 x19를 read 하려는 모습이다.
sub instruction이 앞선 add instruction에 의존하고 있다.
이를 해결하기 위해서는 3 clock cycle만큼 stall(지연) 해야 하므로, 그만큼 손해가 발생하게 된다.
그렇다면 stall 하지도 않고도, Data Hazard를 막는 방법이 무엇이 있을까?
Forwarding
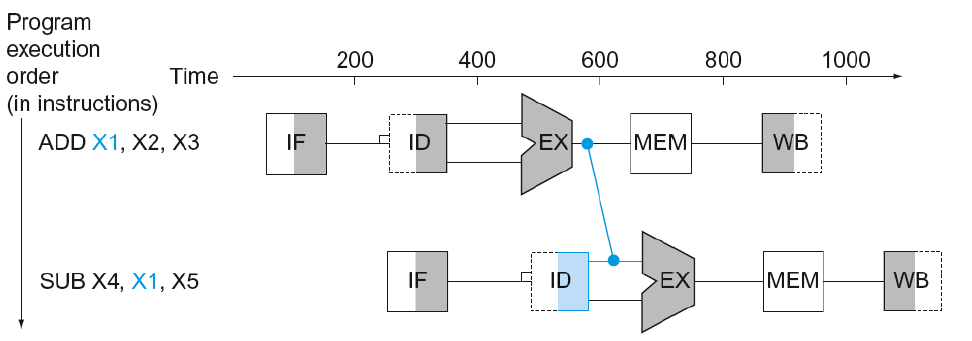
사실 이러한 문제는 컴파일러가 대부분 해결해준다.
dependency 문제가 발생할 것 같다면, 컴파일러는 중간에 x19를 참조하지 않는 명령어를 넣음으로써 이를 해결한다.
하지만 이러한 dependency는 너무 자주 발생하고, 만약에 긴 명령어가 있을 때 컴파일러가 해결하지 못한다면 손해가 너무 크다.
(하나의 명령어가 100 stage로 구성될 때, 만약 90번째 명령어에서 dependency가 발생한다면, 최소한 91번 stall 해야 함.)
이러한 문제는 하드웨어에서 발생하는 문제기 때문에, 소프트웨어로 해결하기에는 충분하지 않다.
따라서 하드웨어적으로 문제를 해결하는데, 이것이 바로 Forwarding이다.
Forwarding은 전방전달이라고도 한다.
이 방법은 하드웨어를 이용한 방법이며, ADD연산의 Ex가 끝나자마자 wiring을 통해 바로 SUB에게 데이터를 전달해주는 것으로 해결한다
Load-use Data Hazard
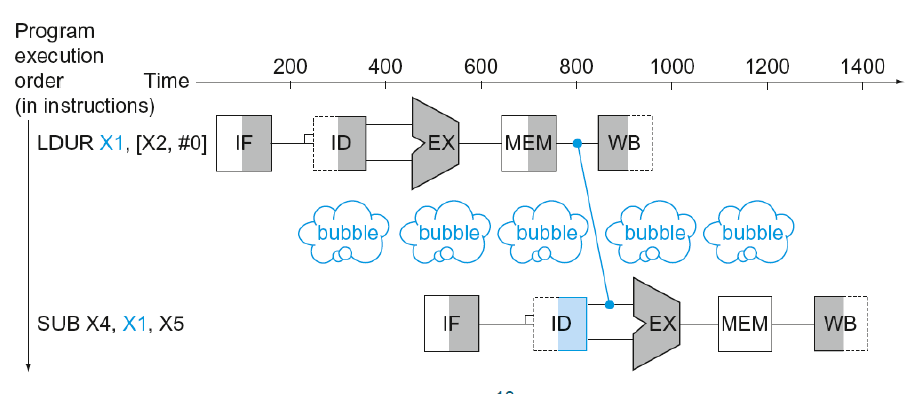
Load 명령어가 실행될 때 일어나는 Data Hazard이다.
MEM Stage가 완료돼야만 올바른 데이터를 참조할 수 있다.
따라서 Load-use data hazard의 경우에는 전방 전달을 하더라도 한단계 지연이 필요하다.
이는 파이프라인 지연(Pipeline stall)의 개념이다. 거품(Bubble)이라고 칭하기도 한다.
Code Scheduling

A = B + E;
C = B + F;
라는 명령어를 수행할 때 다음과 같이 Load-use data hazard가 일어난다.
컴파일러는 이때 code scheduling(코드의 재배치)을 통해 이를 해결한다
Control Hazard
Control Hazard는 conditional branch를 통해 PC 값을 바꿀 때, 이미 pipeline에 들어와 있는 명령어가 flush 되는 현상이다.
조건부 분기를 하는 명령어에서 분기는 MEM Stage에서 발생을 한다.
그래서 그 전에 3단계의 flush(stall)가 발생하는데, ID 단계에서 레지스터를 추가로 사용하여 분기를 결정하게 한다.
따라서 flush(stall)를 1단계만 하도록 할 수 있다.
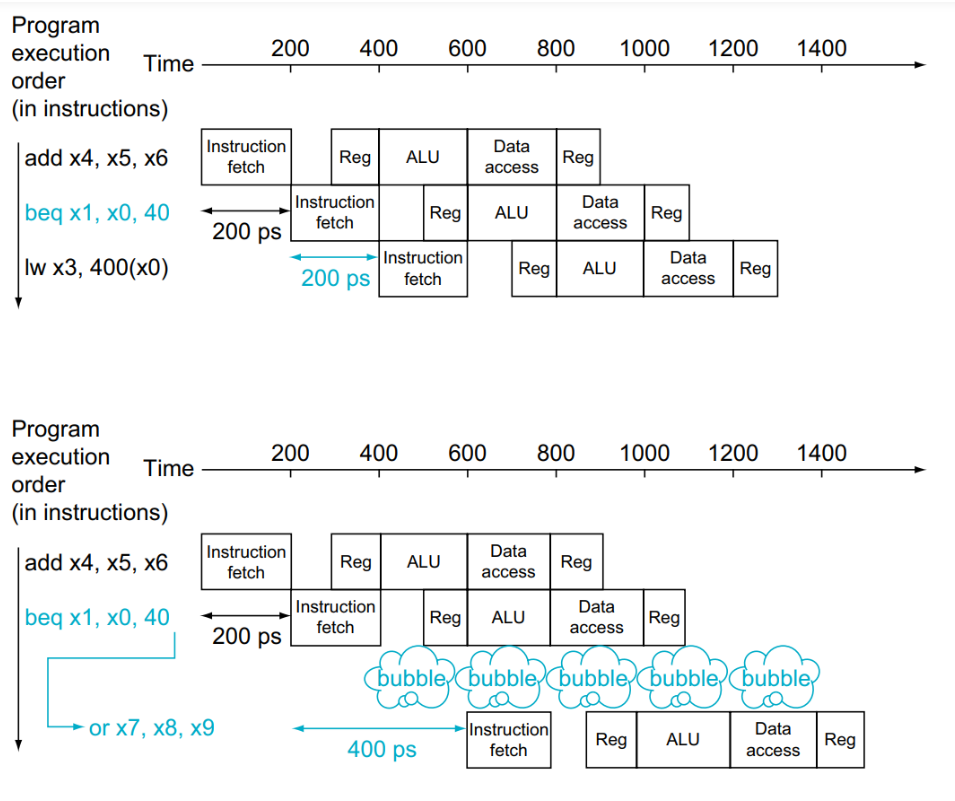
다음과 같이 1번의 stall만으로 control hazard를 해결할 수 있다.
이 1번의 stall마저 해결할 수 있는 방법이 있다. 바로 Prediction이다.
Prediction
Static branch prediction
for문이나 if문에서 backward(이전주소)로 분기할 것이라고 예측하는 것이다.
Dynamic branch prediction
하드웨어가 실제 branch behaivor을 측정해서 현재 trend를 파악해서 앞으로도 trend대로 움직일 것이라고 판단하는 것이다.
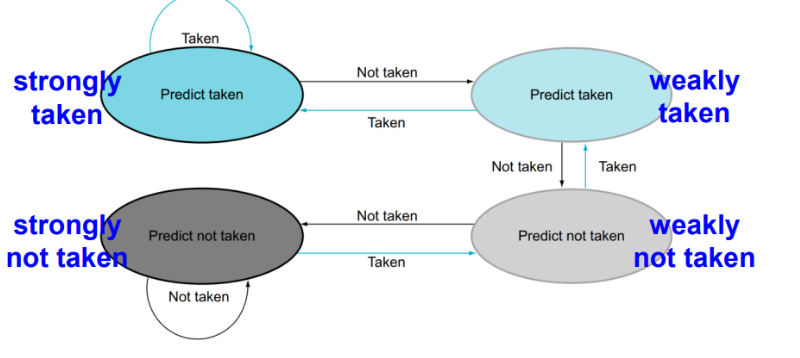
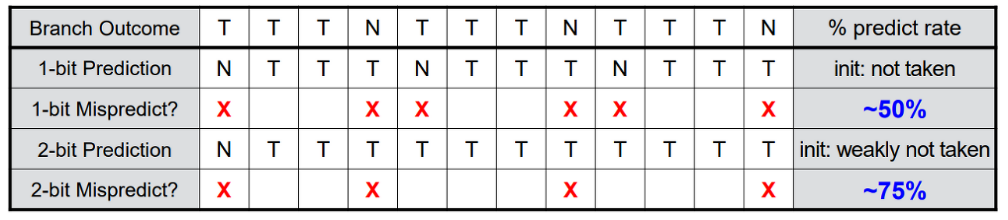
- N-bit dynamic branch prediction:현재 상태가 taken인데 n번의 not-taken이 발생하면 그 다음부터는 not-taken이 발생할 것이라고 예측하는 것이다.
과거의 branch 기록은 branch prediction buffer(branch history table)에 저장한다.
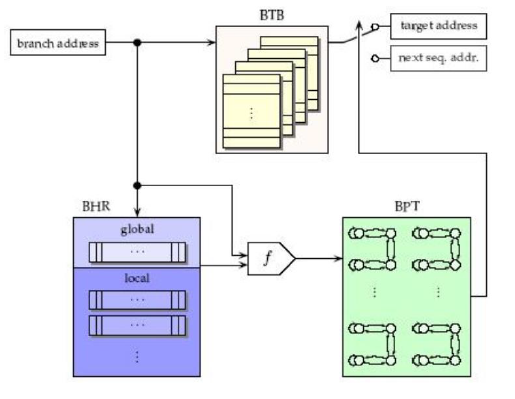
- Hybrid dynamic branch prediction: branch에 제일 best인 prediction을 골라주는 것
과거 브랜치의 기록이 있는 BHR(bracnch history register)를 이용하고 BTB(Branch Target Buffer)이 타겟 주소를 계산하는 것을 돕는다
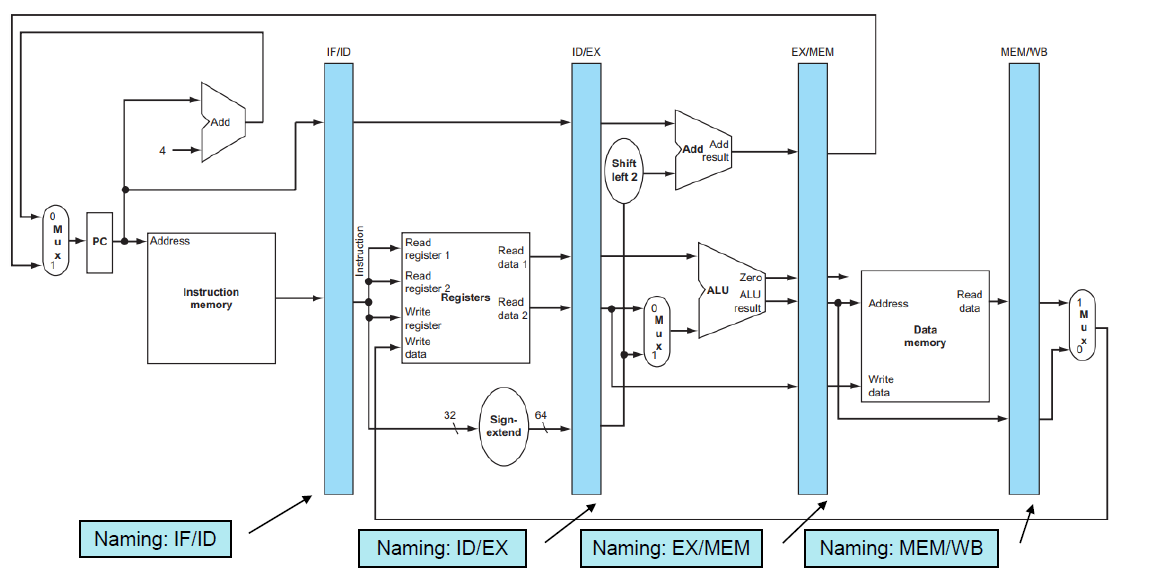
Pipeline Datapath
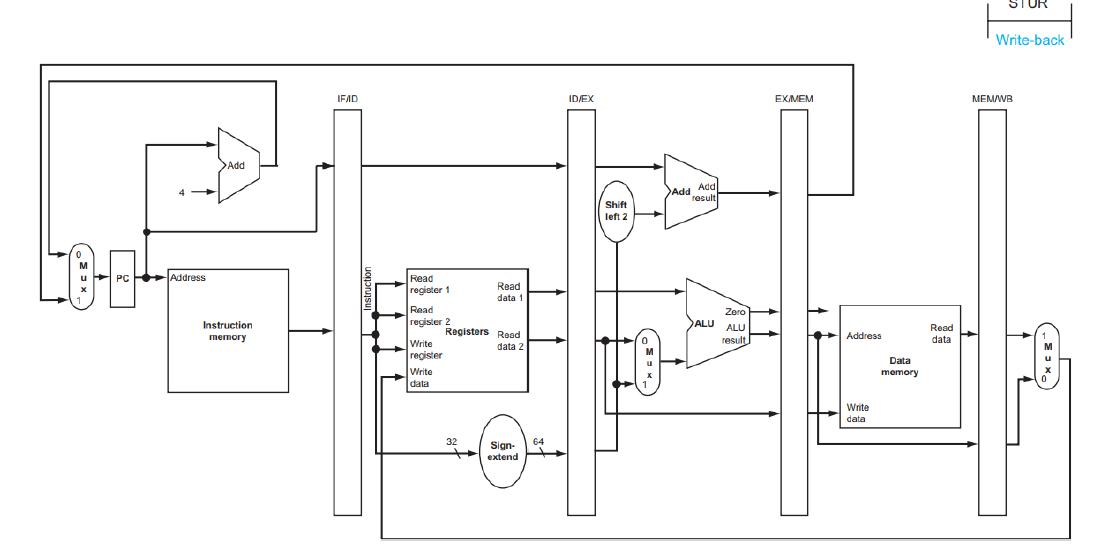
Pipeline에서는 앞선 stage의 정보를 저장하는 특별한 Register가 필요하다.
이를 Pipeline Register라고한다.
ID stage에서 사용하는 명령어나 레지스터 번호 등은 IF stage에서는 더 이상 없다.
왜냐면 ID stage에서 어떤 명령어를 실행하고 있으면, IF stage는 pipeline 기법에 의해 다른 명령어를 실행하고 있기 때문이다.
따라서 중간 중간 연산의 결과, 명령어 등을 저장하는 Pipeline Register가 필요하다.
WB Stage for Load
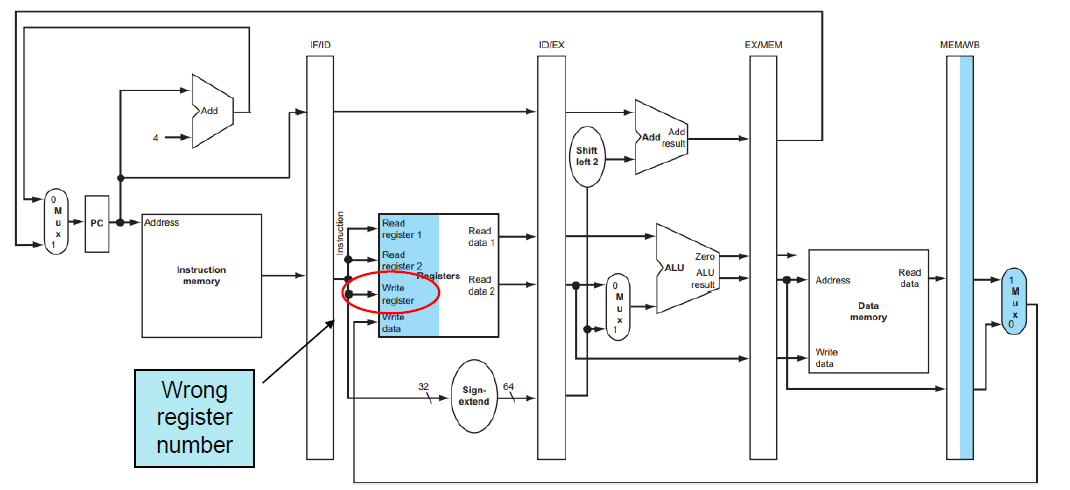
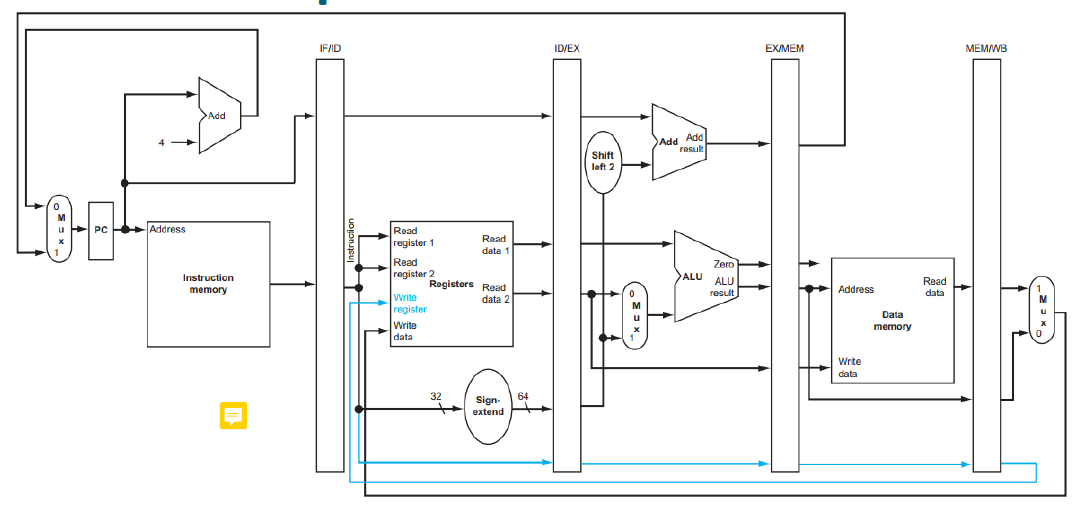
다음과 같이 Load 명령어에서 WB 스테이지에 도달하면 같은 시점에서 이미 다른 명령어가 ID 스테이지에서 레지스터 파일의 Write Register값을 업데이트했기 때문에 Write Register 값의 경우 2번째 그림과 같이 값을 따로 저장해서 전달할 필요가 있다.
WB Stage for Store
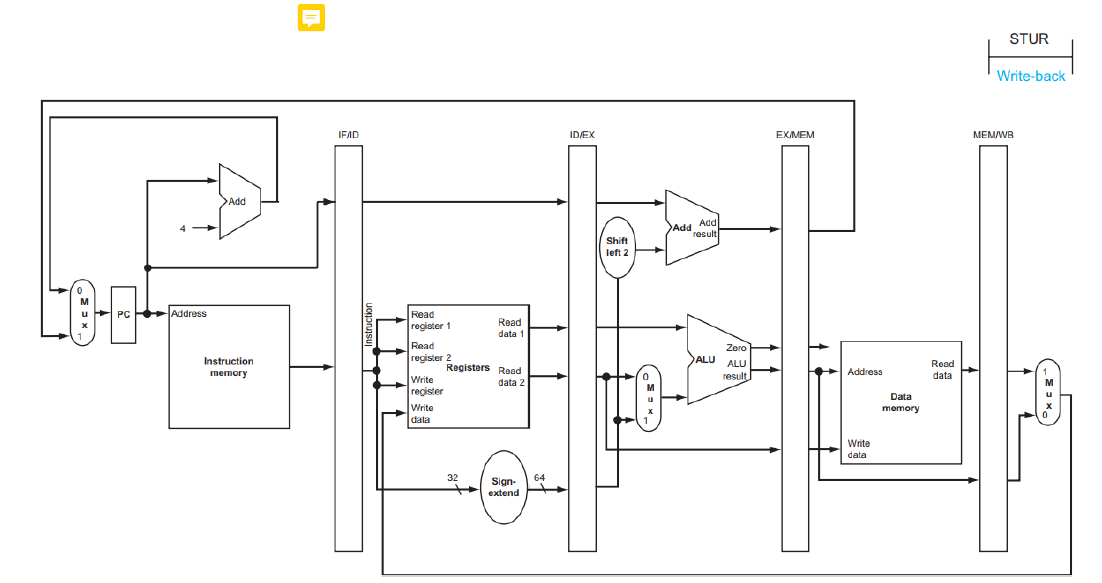
Store 명령어에서의 WB Stage는 필요는 없지만, clock cycle에 맞추기 위해 진행은 한다.
따라서 WB Stage가 없다는 말은 틀리고, 존재는 하지만 아무것도 하지 않고 흘러간다.
Steady State
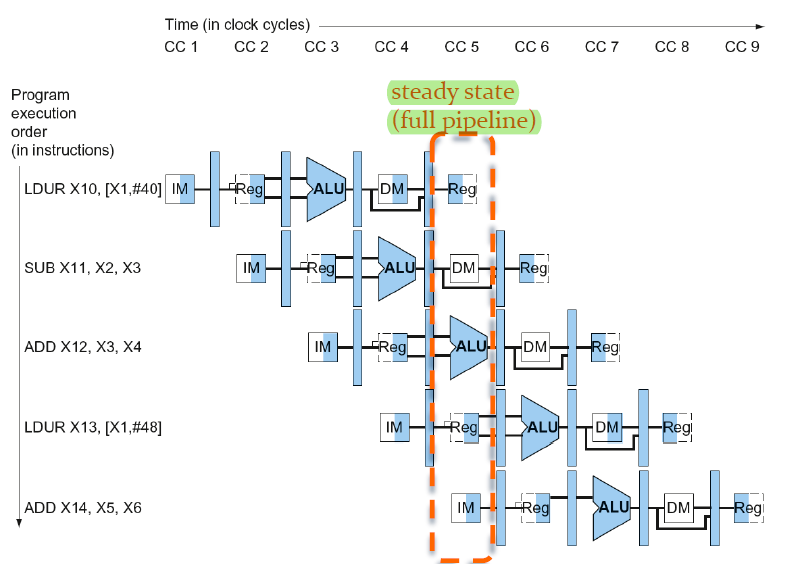
파이프라이닝은 다음같은 다이어그램으로 표현할 수 있다.
그림처럼 모든 stage가 명령어로 가득 찬 상태를 "steady state(full pipeline)"이라고 하며 그 이후에 실행중인 명령어가 줄어드는 단계는 flushing이라고 한다.
Pipelined Control
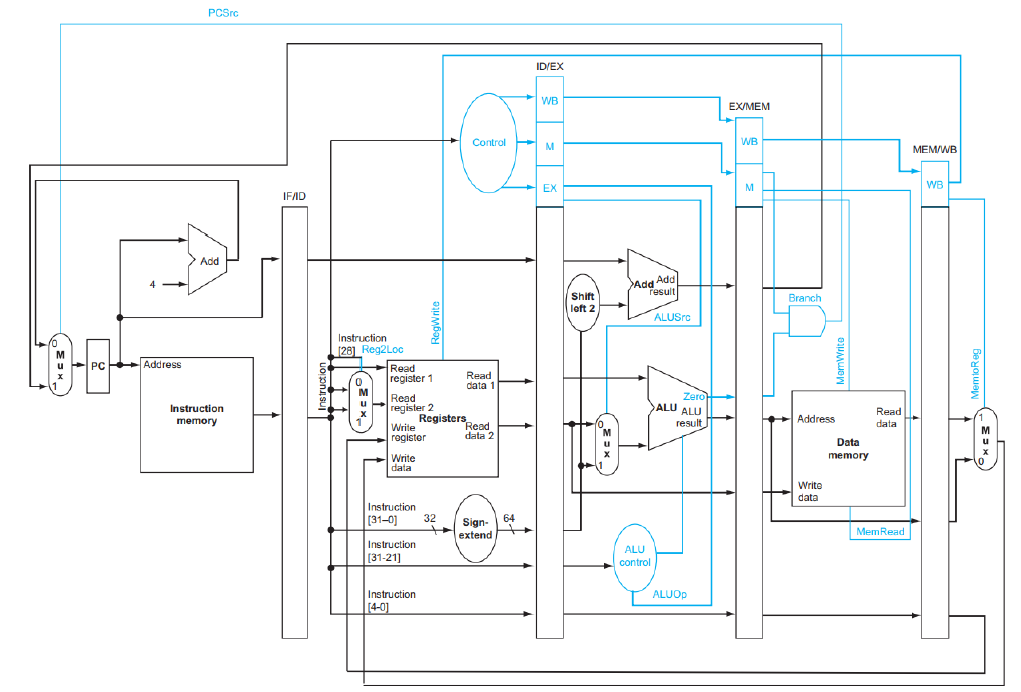
Control Signal이 추가된 Piplined Datapath이다.
각 stage 별로 다음과 같은 control 신호가 입력된다
IF : Nothing Special
ID : Nothing Special(Reg2Loc와 RegWrite은 Control에 의해 제어되지 않는다)
EX : ALUOp, ALUSrc
MEM : MemRead, MemWrite, Branch
WB : MemtoReg, RegWrite
-
ALUOp: 어떤 연산을 수행할 것인지에 대한 값
-
ALUSrc: sign-extend된 immediate 필드를 사용할 것이냐에 대한 값이다. 만약 ALUSrc가 0이라면 Register 2의 값을 사용한다.
-
MemtoReg: WB단계에서 레지스터에 쓸 값을 어디에서 가져올건지 정한다. 만약 값이 0이라면 ALU의 연산 결과를 Register에 쓰고, 1이라면 memory에서 읽은 값을 register에 쓴다.

-
Reg2Loc : R-type, D-type, branch instruction이 서로 포멧이 다르기 때문에 instruction의 어느 필드에서 register2의 번호를 가져올 것인지를 선택하는 mux를 제어한다.
- 0이면 R타입으로 판단하여 20:16에 속하는 Rm 필드에서, 1이면 Branch로 판단하여 4:0에 속하는 Rt 필드에서 가져온다
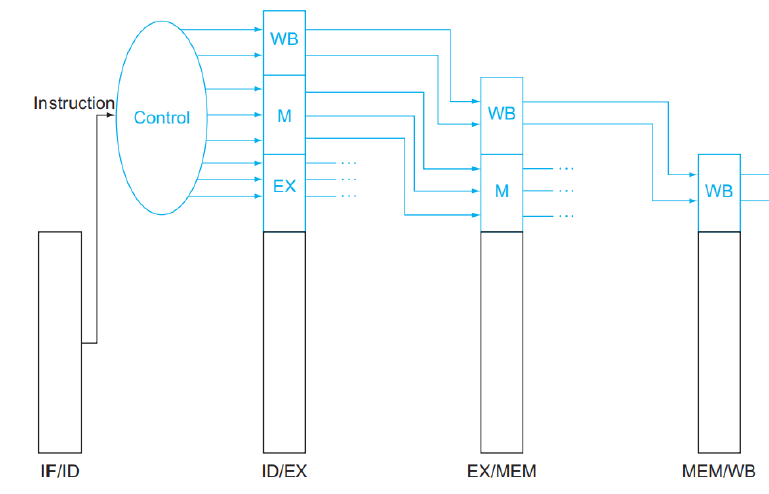
하지만 Control은 5개가 아니기 때문에, ID에서 생성된 Control 신호가 다음 Stage에도 계속해서 흘러가야 한다.
그렇지 않다면 Control은 매번 각 Stage 별로 신호를 생성해야한다.
매우 비효율적이기 때문에 Control 신호 또한 Pipeline Register를 통해서 흘러서 다음 Stage에 가야한다.
Hazard in Pipeline Datapath
Data Hazard
앞에서 설명했듯이 Pipelined Datapath에서는 Hazard가 일어날 수 있고, 그에 대한 해결방안으로 Forwarding, CodeScheduling 등이 있었다.
Hazard를 해결하려면, 먼저 Hazard를 탐지할 수 있어야한다.
Hazard Detection
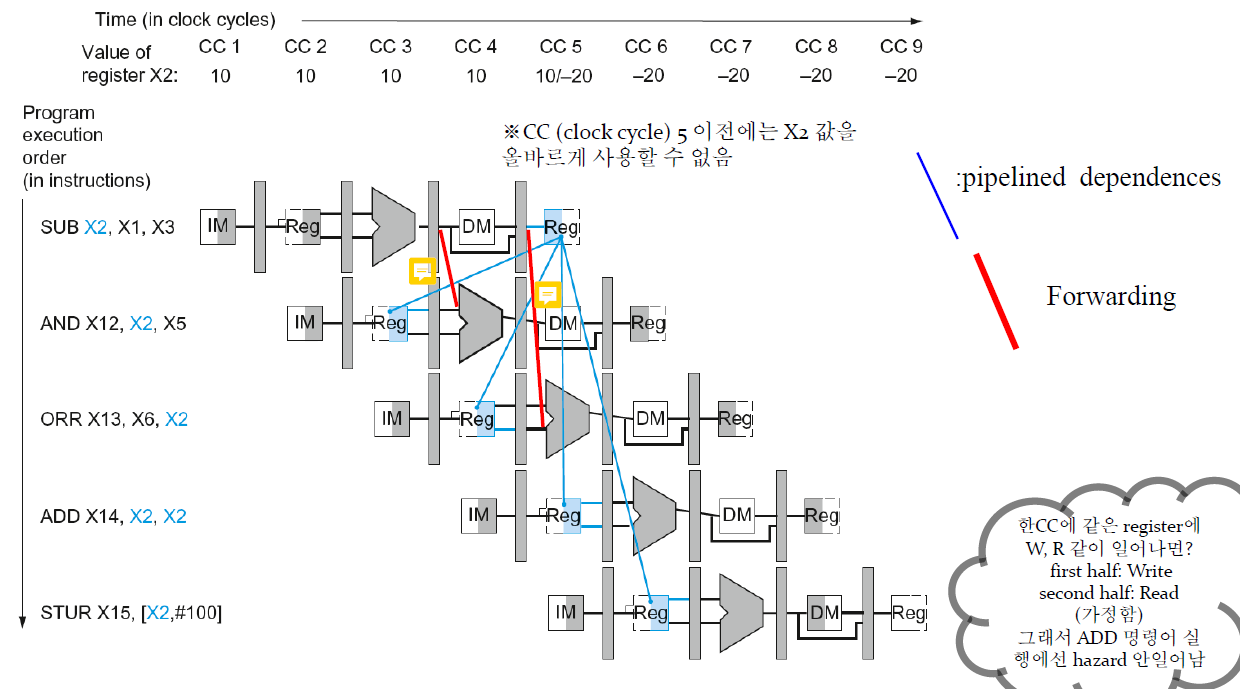
- EX hazard: 바로 이전의 stage에서 dependency가 발생한 상태이므로 EX/MEM에서 forward를 해야한다.
- MEM hazard: 이전 이전의 stage에서 dependency가 발생한 상태이므로 MEM/WB에서 forward를 해야 한다.
위 그림에서는 왼쪽의 빨간선이 EX hazard, 오른쪽이 MEM hazard이다.

여기서 1a, 2a 조건에 부합하는 경우 forwardA(첫번째 operand에게 자원 전달)를, 1b, 2b 조건에 부합하는 경우는 forwardB(두번째 operand에게 자원 전달)를 해주어야한다.
Double Hazard Detection

3번째 명령어의 1번째 피연산자가 이전 명령어의 결과값과 전전 명령어의 결과값에 종속성을 가지고 있으므로, MEM 해저드와 EX해저드의 중첩이다.
1번째 명령어의 결과가 3번째 명령어의 피연산자로 직접적으로 전달되는 것은 아니므로, MEM 해저드가 아니기 때문에 EX 해저드로 탐지해야한다.
따라서 double data 해저드를 탐지하는 조건식은
(EX/MEM.RegisterRd== MEM/WB.RegisterRd== ID/EX.RegisterRn1)이고, 조건식에 부합하면 MEM 해저드를 무시하고 EX 해저드로 판단하여, EX/MEM의 값을 forwarding한다

MEM 해저드를 탐지할 때는 EX 해저드가 아닌 경우라는 조건을 추가해 해저드 조건이 중첩되는 경우를 방지한다
Load-Use Hazard Detection
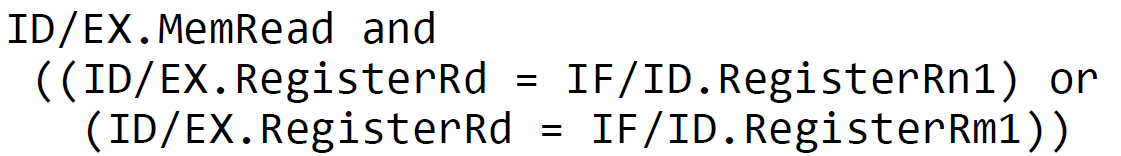
Load-Use 해저드는 다음 조건을 만족한다.
ID/EX.MemRead = 1 and
( (ID/EX.Register Rd = IF/ID.Register Rn1) or
(ID/EX.Register Rd = IF/ID.Register Rm2) )
아예 ID 단계에서 해당 조건을 만족한다면 stall을 진행한다.
How to Stall in Pipeline

이때 stall을 하기 위해서는 세 가지의 행동이 필요하다.
- PC의 업데이트를 막는다.
- IF/ID pipeline Register의 업데이트를 막는다.
- 뒷 단계에서 아무것도 하지 않도록, ID/EX Register의 값을 모두 0으로 만든다.(nop)
Data Hazard가 발생하면, 기존의 Register 값은 아무런 쓸모가 없기 때문이다.
ID/EX Register의 값을 모두 0으로 만들었을 때 EX, MEM, WB stage에서는 아무것도 하지 않고, 이것을 nop(no-operation)이라고 한다.
Reducing Branch Delay in Control Hazard

Branch는 MEM Stage에 도달하기 전까지 발생하지 않는다.
따라서 만약 Branch를 해야 한다면, MEM Stage 이전의 모든 Stage의 값은 날려야 하는 불상사가 생긴다.(3 clock cycle 뒤로 stall)
다만 ID Stage에서 미리 비교해 Branch인지 아닌지를 결정하는 하드웨어를 추가함으로써 한 번의 stall로 손실을 최소화 할 수 있다.
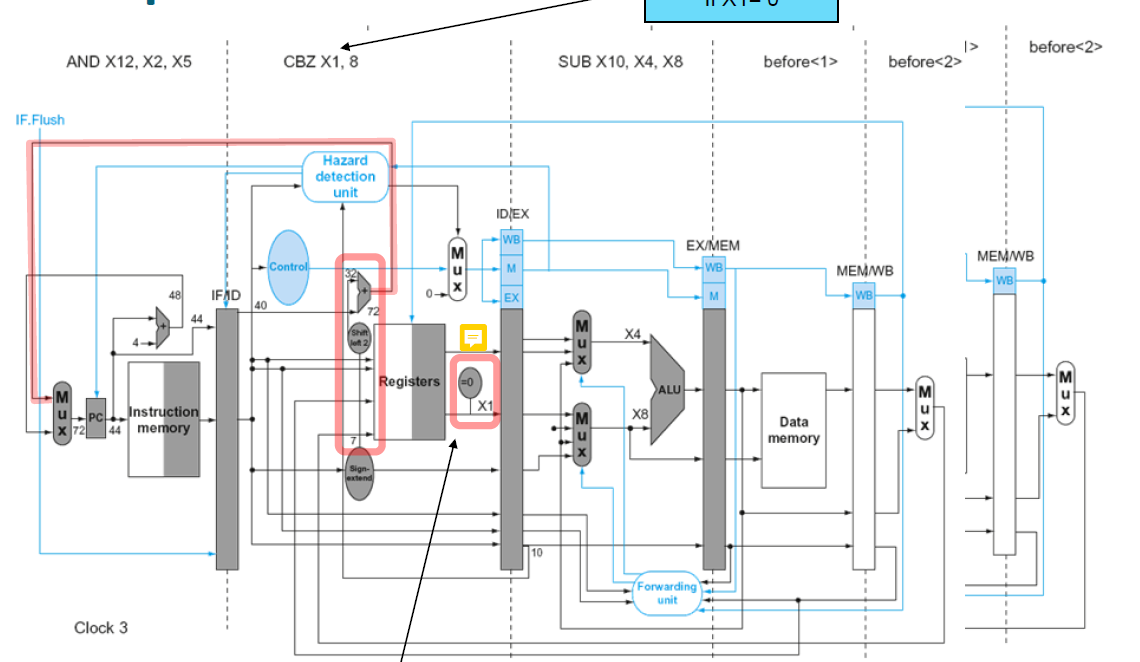
빨간색 네모가 새로 생긴 Unit이다.
맨 우측 Unit은 레지스터 두 개가 같은지를 판단한다.
PC에 신호를 전달하는 mux는 다음 명령어를 실행할지(PC + 4) 또는 PC + offset(immediate 64bit sign-extend) 값으로 분기할지 결정한다.
마지막으로 Branch Taken이 된다면 IF.Flush에서 IF/ID의 모든 정보를 날리며,
새로운 PC 값으로 업데이트 한다.
원래는 MEM Stage에서 Branch 결정이 났는데, 이제는 ID Stage에서 결정이 난다.
그와 마찬가지로 single cycle design에서 존재했던 ALU의 zero signal이 사라진 모습을 볼 수 있다.
Dynamic Branch Prediction in Pipeline
만약 이중 루프를 실행할 때 1bit predictor에서는 inner loop의 마지막 반복에서, outer loop에서는 첫번째 반복에서 mispredict가 일어난다.
mispredict를 줄이기 위해서 2번의 mispredict가 일어났을 때 비로소 branch predict값을 바꾸는 2bit predictor를 사용한다.
branch prediction buffer
과거의 branch 기록을 저장하기 위해 branch prediction buffer(branch history table)을 사용하는데,
다음의 역할을 한다
- 최근 branch instruction의 address에 따라 indexing
- outcome 저장
branch target buffer
predictor가 있음에도 target 주소를 계산하고 branch를 taken하는데
1 cycle의 penalty가 필요하다.
그에 따라 branch target buffer가 존재하고 다음의 역할을 한다.
- Branch target address를 IF 단계에서 계산해서 버퍼링
- branch taken 으로 prediction 되면, 바로 branching
