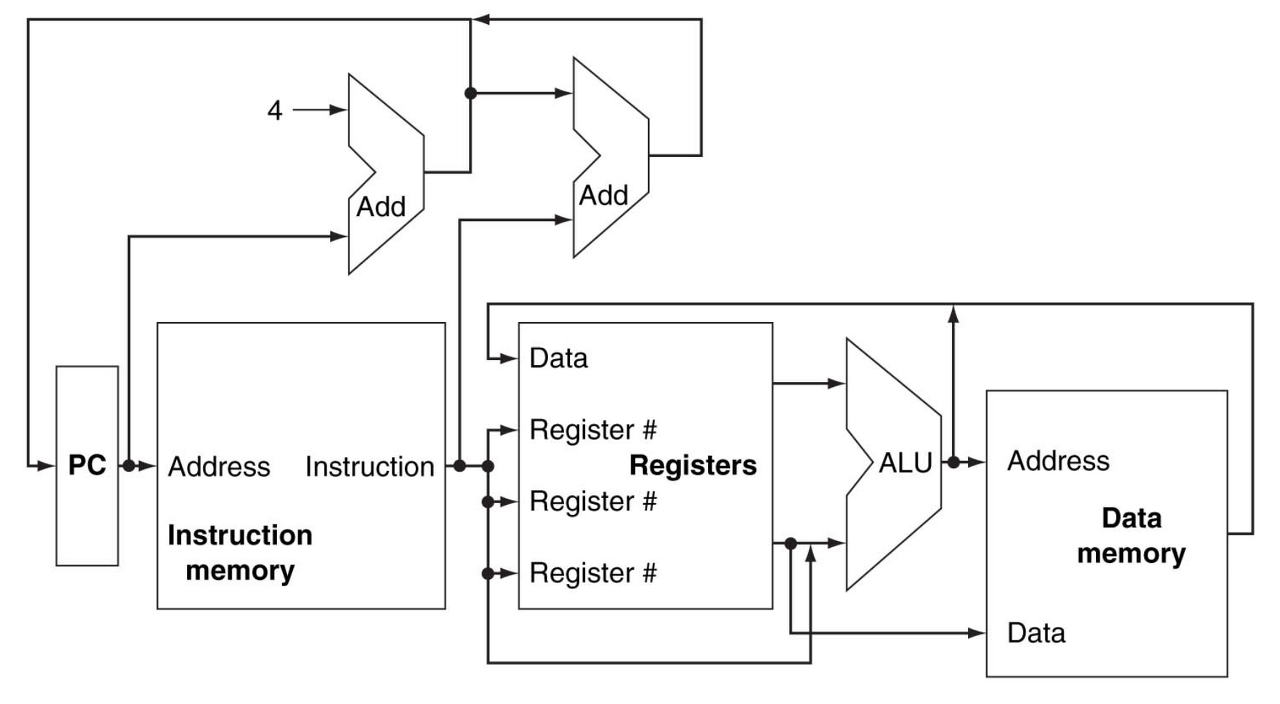
Exceptions and Interrupts
-
Exceptions : CPU 내부 동작으로부터 예외사항이 일어나는 것, 논리, 산술 연산에서 일어날 수 있음
-
Interrupts : 외부 I/O controller(CPU가 아닌 외부장치. OS 등..)로부터 발생
-
Trap(=Software Interrupt)
- syscall 활용. 명령어가 인터럽트를 발생.
- 원래 인터럽트는 하드웨어에서 발생시키지만, 소프트웨어적으로 호출해서 발생시키는 경우
우리는 이러한 예외사항이 발생 시 성능 저하를 피할 수 없으므로 성능 저하를 최소화하면서 처리할 방법이 필요하다
Handling Exceptions
하드웨어는 이러한 예외사항을 처리하는 소프트웨어를 위해 예외에 대한 다음의 정보들을 저장한다.
- where(어디서) : 예외처리가 끝나고 복귀할 명령어(예외를 유발시킨 명령어)의 PC값 ELR*(Exception Link Register)에 저장
- why(왜) : 왜 예외가 발생했는지에 대한 이유(1bit의 flag값)를 ESR(Exception Syndrome Register)에 저장, opcode값이 잘못된 경우 0을, overflow의 경우에는 1을 저장
Handler Actions
예외 발생 시 핸들러의 동작은 다음과 같다.
- 원인을 읽고, 관련된 handler로 넘겨준다(handler로 jump).
- 필요한 동작을 결정한다.
- 만약 해당 명령어를 재시작 가능하다면,
ㆍ적절한 동작으로 시정하여 동작시킨다.
ㆍELR을 이용하여 원래의 PC로 돌아갈 수 있도록 한다. - 그렇지 않다면,
ㆍ프로그램을 중단한다(terminate).
ㆍESR, cause, ... 등을 이용하여 error를 보고한다(Report error).
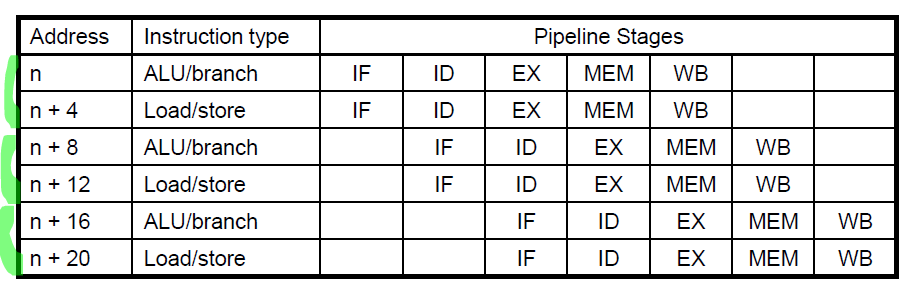
Exceptions in a Pipeline
다음의 이유로 exception은 control hazard의 또 다른 유형이다.
- control hazard는 프로그램의 flow가 바뀔지도 몰라서 직후 명령어가 바로 실행될 수 없는 hazard
- exception도 발생하면, 다음의 명령어들이 실행되지 못하고 exception을 처리해야 함
overflow가 일어났는지는 EX stage에서 판단할 수 있다.
add명령어의 EX stage에서 overflow가 발생했다고 생각해보자.
add X1, X2, X1
- X1에 잘못된 값이 쓰여지는 것을 막는다.
- 이전 명령들은 제대로 완수될 수 있도록 한다.
- add 명령어와 이후 명령어들을 비운다(flush).
- ESR와 ELR의 값을 세팅한다.
- handler로 제어권을 넘긴다(handler가 처리할 수 있도록 jump).
mispredict branch가 발생 시 실행하는 루틴과 비슷하다.
예외가 발생하면 발생이후 stage(exception이 일어나기 전에 실행되던 명령어)는 그대로 실행해주고, 이전 stage는 bubble 처리(nop)를 해주어야한다.
Pipeline with Exceptions
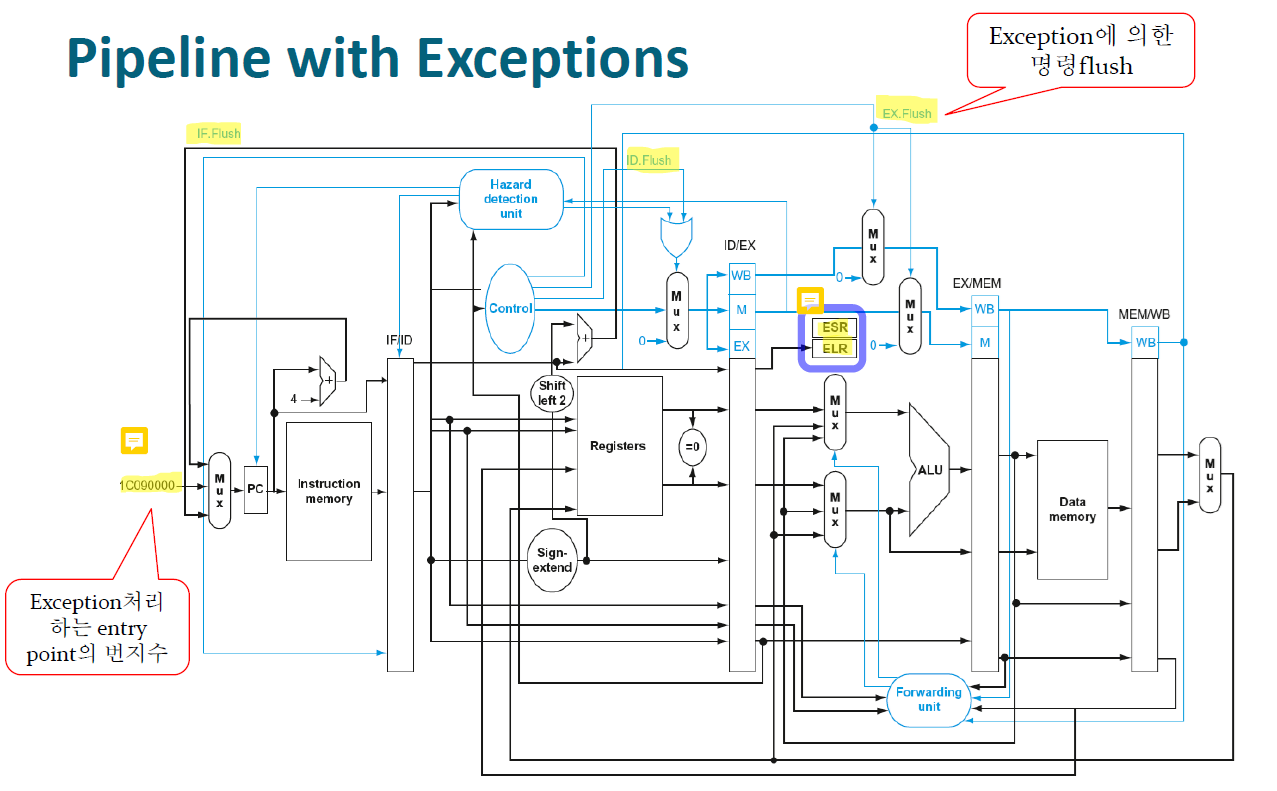
-
만약 예외가 발생한 명령어가 재실행 가능하다면
- 파이프라인의 명령어를 flush
- handler가 처리 후, 원래의 instruction으로 돌아간다.
- 이번엔 시정된 instruction을 실행한다.
-
ALU 연산의 결과를 보고 예외를 판단해야하기 때문에 ESR, ELR는 EX단계에 위치한다.
-
돌아가야될 위치가 저장된 ELR에는 PC값의 싱크를 맞추기 위해 파이프라인 레지스터에서 PC값을 가져온다.
Exceptions Example

다음과 같이 ADD명령어에서 예외가 발생했다면?
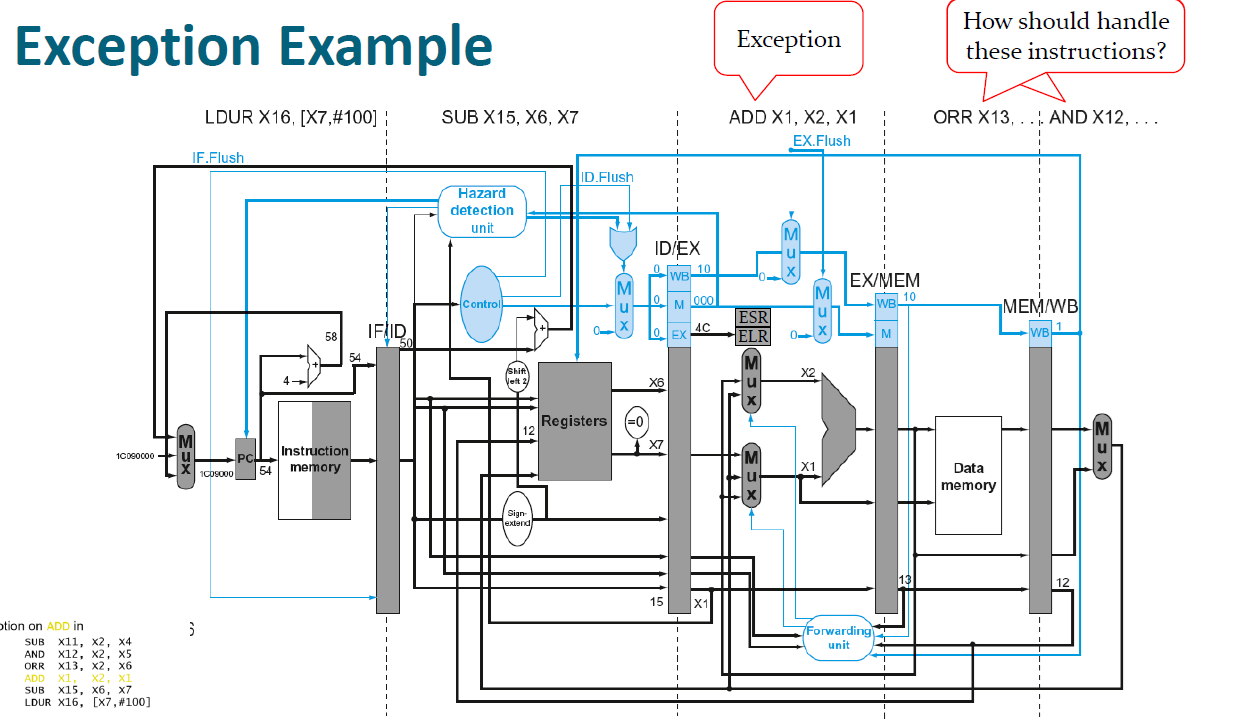
현재 instruction과 이후 instruction들 모두 flush
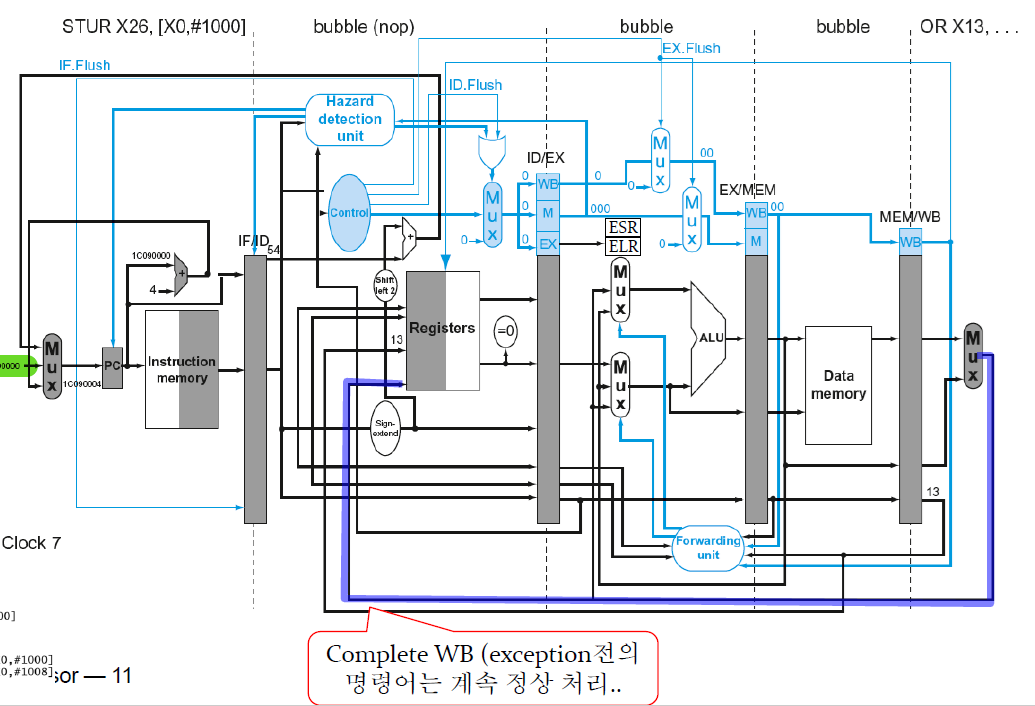
nop로 flush(bubble), 그리고 handler로 jump한다.
따라서 예외가 발생한 이후의 명령어는 bubble처리, 이전의 명령어는 그대로 흘러가게 nop 처리를 한다.
Instruction Level Parallelism (ILP)
CPU를 어떻게 빠르게 할 수 있을까?
여러 개의 명령어를 병렬적으로 실행할 수 있으면 된다
이것에 대한 척도가 ILP이다.
ILP를 증가시키는 방법
- pipeline stage를 증가시키면 됨
- 각각의 stage마다 하는 일이 적어지면 clock cycle이 짧아져 성능이 향상됨
- 그러나 hazard와 같은 예외를 처리하기 위해서 더 많은 하드웨어 리소스와 power 소모량이 기하급수적으로 늘어나기 때문에 궁극적인 해결책은 될 수 없다
- 여러 개의 명령어를 동시에 실행 (issue: instruction fetch 과정) -> mutiple issue라고도 부른다
- 여러 개의 파이프라인을 만들어, 각 cycle마다 실행하는 명령어가 여러 개가 될 수 있음
Mutiple Issue
- 여러 개의 명령어를 동시에 실행하는 것을 의미한다(issue: instruction fetch 과정)
- IPC(사이클 당 수행하는 명령어 수)는 1 cycle에 여러 개의 명령어가 동시에 실행되는 것을 의미한다.
- 파이프라이닝에서 IPC는 1이지만, Multiple issue에 비례하게 IPC값이 2이상으로 증가할 수 있다.
- 이론적으로는 IPC값이 4까지 증가할 수 있지만, 실제로는 힘들다
Static multiple issue
-
어떤 명령어가 어느 cycle에서 실행할지 이미 결정이 되어 있는 것(컴파일러가 runtime 전에 결정)
-
컴파일러가 instruction들이 함께 issue될 수 있도록 묶어줌(group).
-
issue slots으로 패키지화함
-
컴파일러가 hazards를 감지하고 회피시켜 준다
-
컴파일러가 명령어의 그룹을 issue packet으로 만듦
-
issue packet이 매우 긴 명령어처럼 보이게 됨. 이런 아키텍쳐를 Very Long Instruction Word(VLIW) 라고 부름
Scheduling Static multiple issue
- 컴파일러가 hazard를 감지하고 없애야 함
- 명령어를 reorder하고 dependency가 없는 packet를 만듦
- packet 사이에는 dependency가 생길 수 있는데 이럴 경우 nop operation를 두어 hazard를 해결
VLIW
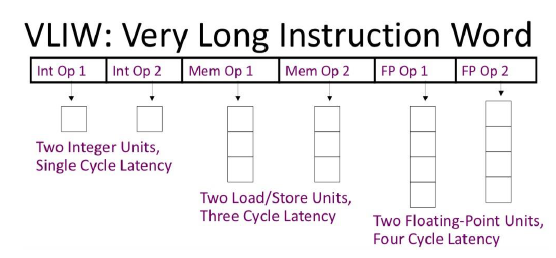
만약 최대 6개의 명령어를 함께 실행할거라면 32비트짜리 6개 붙여서 하나의 명령어로 보며, 데이터 타입에 따라 묶어 하드웨어 연산의 복잡도를 낮추며 데이터 타입에 따라 연산 속도가 다를 수 있다.
LEGv8 with Static Dual Issue
LEGv8에서는 서로 다른 타입의 명령어들을 2개씩 묶어 64비트의 각 명령어를 수행할 수 있다
서로 다른 타입의 명령어로 묶는 이유는 연산에 필요한 하드웨어 리소스를 줄이기 위해서이다.

명령어를 2개씩 묶어 수행할 경우 ALU와 sign-extend, 결과 데이터를 전달하는 path를 1개씩 추가하면된다
검은색 ALU : 산술 논리 연산 ALU
파란색 ALU : 메모리 address계산 ALU
Dynamic multiple issue
- CPU가 동적으로 어떤 명령어를 실행할 cycle를 결정
- CPU가 runtime hazard를 감지하고 해결
- Superscalar processor: dynamic multiple issue를 지원하는 프로세서
- 필요에 따라 컴파일러가 도움을 줄 수 있음
Loop Unrolling

Loop를 펼친다라고 생각하면 된다.
Loop를 펼침으로써 그룹핑지어 동시에 실행할 수 있는 명령어의 개수를 늘릴 수 있다(가능성을 늘린다)
데이터 종속성 문제가 있기에 펼친 개수에 비례해서 속도가 증가하는 것은 아니다.
그러나 가짜 dependency인 anti-dependencies가 존재한다.
왼쪽의 코드를 Loop Unrolling을 통해 오른쪽으로 바꾸었다.
그 결과 IPC가 1.2 -> 1.88로 증가함을 볼 수 있다
