[CS 스터디 - 2회차]
발표자 : 민성재
날짜 : 4/17
범위 : 운영체제) 페이징과 세그맨테이션 , 페이지 교체 알고리즘
1. 페이징(Paging) : 외부 단편화에 대한 해결책 (고정 분할 방식)
먼저 페이징은 외부 단편화로 인한 메모리 낭비가 매우 심하고 그때 Compaction(압축)을 사용하면 외부 단편화를 해결할 수는 있지만, 그로 인해 생기는 오버헤드와 비효율적인 성능으로 사용하기 어렵기 때문에 나온 기법이다.
- 단편화란?
단편화에는 내부 단편화, 외부 단편화가 있는데 둘 다 메모리 공간이 낭비되는 상황을 의미한다.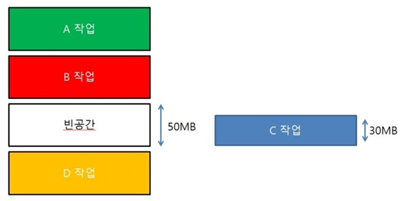
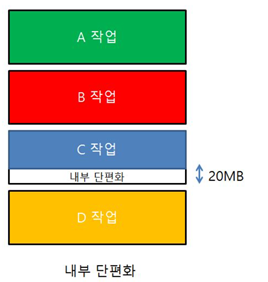
다음과 같이 메모리에 50MB의 공간이 남아있고 30MB의 신규 프로세스가 실행된다면, 다음과 같이 적재가 되고 이곳에는 20MB라는 내부 단편화가 생긴다.
이곳에 20MB이상의 프로세스는 적재되지 못하고 낭비되는 현상이 생긴다.
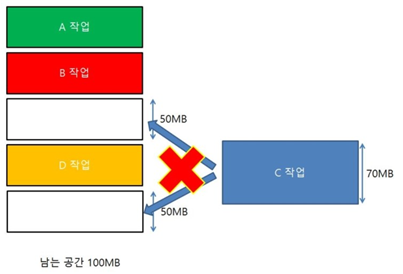
외부 단편화란 그림처럼 공간이 100MB나 있음에도 C작업이 적재되지 못하고 낭비되는 상황을 의미한다. 이런 경우 Compaction 이라는 압축기법을 통해 분산된 자유 메모리 공간을 모아서 큰 블록을 형성하는데 프로세스 주소 공간이 동적으로 재배치되어야 하므로 굉장히 오버헤드가 크고 비효율적이다.
따라서 남은 메모리 공간을 동적으로 재배치하지 않고 프로세스 자체를 잘게 쪼개서 곳곳에 넣는 개념이 바로 페이징이다. 페이징을 통해서 외부 단편화를 해결할 수 있지만 내부 단편화는 여전히 남아있다.
다만, 하나의 프로세스는 연속적으로 시간에 따라 계속 동작을 수행하는데 이를 잘게 쪼개서 여기저기 분산해버리면 프로세스가 정상 작동하는가??
이를 위해서 실제로는 메모리 주소가 연속적이지 않지만 연속적으로 CPU에게 보이게끔 하는 기술이 필요하다.
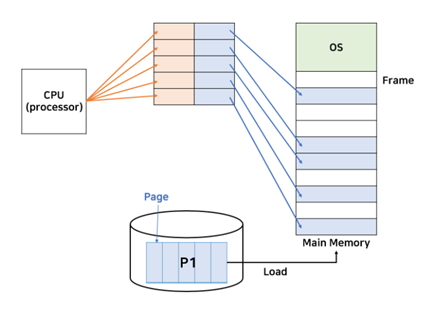
먼저 프로세스 P1 은 5개의 페이지로 나뉜다. 그리고 메모리의 조각은 프레임이라고 한다. CPU는 연속된 논리주소로 명령을 내리지만 실제 메모리 주소는 연속적이지 않으므로 실제 물리주소로 변환되는 과정이 필요하다. 이때 쓰이는 것이 페이지 테이블이다.
- 주소 변환
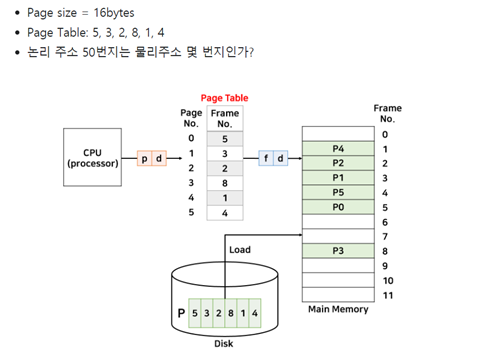
CPU가 논리주소 50번지에 간다고 하면 논리 주소를 p, d 값으로 나눠야 한다.
여기서 d를 구하는 방식은 페이지의 크기가 16byte 이므로 2^4인데 이때 제곱수 4의 크기 만큼 d가 가지고 나머지 2를 p가 가진다.
50은 2진수로 110010 이고 여기서 앞에 2칸 11 = p , 뒤의 4칸 0010 = d 가 된다.
이때 p, d로 이뤄진 논리주소가 실제 주소 f, d로 바뀌어야 하는데 p가 11 이므로 이는 십진수로 3이고 페이지 3은 프레임 8번에 적재되어 있으므로 f는 8 즉, 2진수로 1000이 된다.
최종적으로 물리주소는 f, d로 구성되어 2진수로 표기하면 10000010이 되고 이는 십진수로 130번지가 된다. 여기서 마지막으로 변위는 d를 의미하는데 0010은 2이므로 페이지 8의 물리주소는 128~130이 된다.
2. 세그맨테이션 : 내부 단편화의 해결책 (가변 분할 방식)
페이징은 프로세스를 물리적으로 나눠서 메모리에 할당하는 방식이라면 세그맨테이션은 프로세스를 논리적 내용을 기반으로 나눠서 배치하는 방식이다. 기본적으로 프로세스를 나눠서 메모리에 할당하는 것은 비슷한데, 세그먼트 크기가 일정하지 않기 때문에 세그먼트 테이블에는 limit 정보가 주어진다. CPU에서 해당 세그먼트의 크기를 넘어서는 주소가 들어오면 인터럽트가 발생해서 프로세스를 강제 종료시킨다.
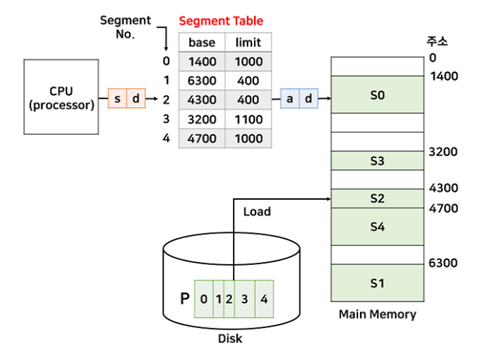
CPU에서 s, d라는 명령을 보내면 테이블을 통해 a, d로 변환하는데 물리주소 a는 base[s] + d로 계산된다.
예를 들어 논리주소 (2,100) 이 들어오면 a는 base[2] + 100 = 물리주소 4400번이 되고 limit 400인데 사이즈 100이니까 인터럽트 발생 x
논리주소 (1,500) 이 들어오면 base[1]의 limit 400을 넘기는 500이 들어오므로 인터럽트 발생하여 프로세스 강제 종료
3. 페이징 vs 세그맨테이션
페이징은 프로세스 고정 분할 방식으로 외부 단편화를 극복하기 위한 기법이지만 내부 단편화가 존재하며
세그맨테이션은 프로세스 가변 분할 방식으로 내부 단편화를 극복하기 위한 기법이지만 외부 단편화가 존재한다.
세그맨테이션은 보호와 공유에서는 나은 성능을 보이지만, 대부분 요즘은 페이징을 씀. 왜냐면 세그맨테이션에 치명적 단점이 존재하기 때문인데, 이는 프로세스마다 크기가 제각각이고 그때마다 메모리 사이사이 공간이 예측 불가능하게 구멍이 숭숭 뚫려서 다음 프로세스를 적재할 때 어디에 할당하는 것이 최적인지에 대한 알고리즘이 존재하지 않고 기본적으로 외부 단편화가 훨씬 메모리 낭비가 크기 때문이다.
그래서 나온게 세그먼트를 페이징 기법으로 나누는 Paged segmentation인데 이 역시 세그먼트 + 페이징 기법이긴 하지만 주소 변환도 2번해야되는 단점이 있다.
- 보호와 공유란?
1) 보호 : 접근하고자 하는 페이지에 대해 읽기나 쓰기 작업을 어떻게 제한할 것인 지 , 다른 프로세스의 주소공간으로 침범하지 못하도록 하는 것. 보호 비트를 두어 접근 제어를 하고 보호에 위반되면 트랩을 일으킨다.
2) 공유 : 프로그램의 한 부분만을 메모리에 두고 실행함으로써 메모리 공간 절약이 가능.
4. 가상 메모리
물리 메모리가 가지는 크기의 한계를 극복하기 위해 나온 기술이 가상 메모리이다. 각 프로세스에서 현재 실행에 필요한 부분만 메모리에 적재하여 효율을 극대화하는데 이때 현재 필요한 부분(보통은 페이지)만 올리는 것을 Demading Paging(요구 페이징)이라고 함.

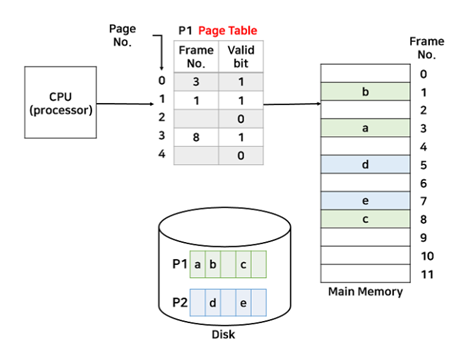
두 프로세스 P1, P2 는 현재 필요한 페이지만 메모리에 할당한 상태인데, 지금은 P1이 수행 중이다. 기존의 페이지 테이블과 다른 점은 Valid bit 를 두어서 현재 메모리에 적재된 부분은 1 , 아닌 부분은 0으로 표시한다.
그러나 CPU가 지금 P1의 3번째 페이지에 접근하려고 하는데 Valid bit 가 0이면 인터럽트가 발생하는데 이런 현상을 ‘페이지 부재’ Page Fault 라고 부른다.

다음과 같은 방식으로 페이지 부재를 처리한다. 즉 페이지 부재가 발생하면 프로세스로 가서 할당되어야 할 페이지를 찾아서 할당해줘야 한다는 의미이다.
이때 페이지 부재 상황에서 페이지 할당하는 방식이 2가지 있다.
1) Pure Demading Paging
프로세스가 맨 처음 실행될 때 어떤 페이지가 필요한지 모르므로 아무 페이지도 할당 안한다. 그러면 시작하자마자 페이지 부재가 발생하고 그때부터 필요한 페이지를 뽑아가는 형식. 메모리를 쓸데 없는 건 아예 안 올리므로 최대한의 효율로 쓰지만 속도는 당연히 느리다.
2) Preparing
위의 방식과 반대되는 개념으로 미리 필요할 것 같은 페이지를 미리 올려두는 것이다. 페이지 부재가 발생할 확률을 줄이므로 속도는 빠르지만, 이미 올라간 페이지가 쓰이지 않는다면 메모리가 낭비되는 단점이 있다.
현실적으로 페이지 부재는 얼마나 발생하는가? 지역성의 원리에 의해 페이지 부재 확률은 실제로 굉장히 낮다. 메모리 접근은 시간적, 공간적 지역성을 가진다.
그럼에도 페이지 부재를 더욱 효율적으로 관리하기 위해 페이지 교체 (Page Replacement) 기법을 사용한다.
5. 페이지 교체 (Page Replacement)
위에서 말한 요구 페이징은 그때 그떄 필요한 페이지를 가져온다. 그러나 프로그램들이 계속 실행되면 제아무리 가상 메모리를 쓴다 하더라도 메모리가 페이지들로 가득차게 된다.
이런 상황에서 메모리에 올라가 있는 페이지를 다시 내리고 새로운 패이지를 올리는 과정을 페이지 교체라고 한다.
- Victim Page(희생양 페이지)
그럼 어떤 페이지를 내릴 것인가? 기본적으로 CPU에 수정되지 않은 페이지를 고르는 것이 좋다. 수정된 페이지는 다시 내려갈 때 수정된 부분을 Write 연산을 해야하기 때문이다. 이를 위해서 페이지가 수정되었는지 안되었는지를 판단할 수 있는 Modified bit(=dirty bit)를 추가하여 수정된 페이지는 1 , 안된 페이지는 0으로 한다. 이를 이용해서 희생 페이지는 최대한 수정 안된 페이지를 우선적으로 한다.
하지만 이러한 방식 말고도 여러가지 방식들이 존재한다.
6. 페이지 교체 알고리즘
1) FIFO(First In First Out)
간단하게 먼저 메모리에 적재된 페이지가 먼저 나가는 알고리즘. 보통 처음에 초기화하는 코드는 프로세스 실행때만 초기화하고 안 쓰이므로 이런 경우에 적절한 방법이다. FIFO는 프레임의 수가 적다면 금방 프레임이 꽉 차서 계속 가장 오래된 놈을 내려야 되므로 페이지 부재가 일어난다. 그러나 프레임의 수가 많을수록 페이지 부재가 적어지며 이를 Belady’s Anomaly라고 부른다.
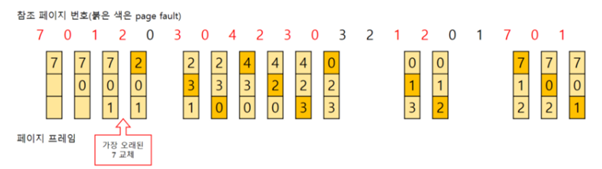
2) OPT(Optimal)
최적화 알고리즘이란 의미로 가장 사용 안 할 것 같은 페이지를 가장 우선적으로 내려보내는 알고리즘이다. FIFO에 비해 페이지 부재가 감소하긴 하지만 앞으로도 사용안될 것인지에 대한 예측이 보장되지 않으므로 실제로 많이 쓰이지 않는다.
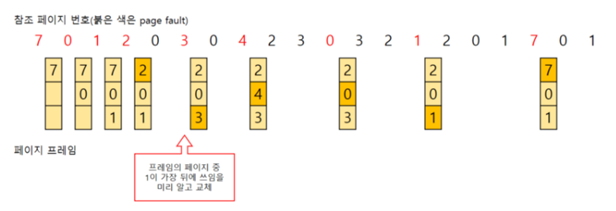
3) LRU(Least Recently Used)
최근에 사용하지 않은 페이지를 가장 먼저 내리는 알고리즘이다. 과거에 많이 안 쓰였다면 미래에도 많이 안 쓰일 것이라는 전제로 쓰인다. 실제로 그런 경우가 많아서 실 사용되는 알고리즘이다.
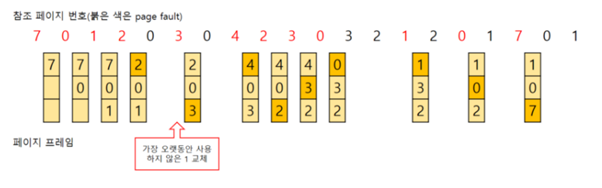
4) LFU(Least Frequently Used)
사용 빈도가 가장 적은 페이지를 교체해준다. LRU와 비슷한 것 같지만 전혀 다른 방식이다. LRU는 시간적으로 가장 오래된 페이지를 교체한다면 LFU는 사용 횟수 자체가 가장 적은 페이지를 교체해준다.
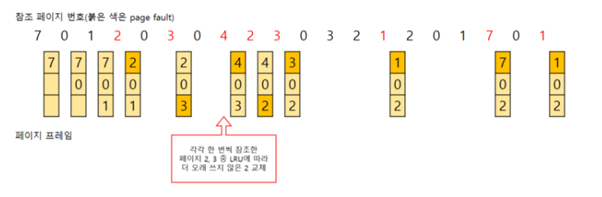
1) Global 교체 방식
메모리 상의 모든 프로세스 페이지에 대해 교체하는 방식
2) Local 교체 방식
메모리 상의 자기 프로세스 페이지에서만 교체하는 방식

