1. IPC
1) IPC
: Inter Process Communication 의 약자이다. 기본적으로 프로세스는 자신에게 할당된 메모리 내의 정보만 접근할 수 있다.
이를 벗어나는 경우 Segmentation Fault 등의 오류가 발생한다. 따라서 한 프로그램에서 병렬성을 키우면서 공유되는 데이터를 사용하기 위해 메모리 공간을 공유하는 스레드를 이용하는 경우가 많다.
하지만 이것은 하나의 프로그램에서만 의미가 있는 것이고, 서로 다른 프로그램의 데이터를 공유하려면 결국 다른 프로세스의 메모리를 접근할 필요가 발생한다. 수많은 프로세스가 OS 상에 상주하면서 user의 요구 사항을 수행한다. 그런데 여러가지 Process가 동시에 수행되고 있기 때문에 System Resource를 같이 사용함으로써 그 효율성을 증대시킬 수 있다.
이런 과정을 통틀어서 IPC라고 한다. IPC의 가장 큰 목적은 Process내에서 생성된 데이터들을 전달하는 것이라고 할 수 있다.
2) Pipe
: 여러 개의 프로세스가 공통으로 사용하는 임시 공간(통신을 위한 메모리 공간(버퍼)을 생성하여 프로세스가 데이터를 주고받게 끔 해준다.), 거의 모든 주요한 OS가 pipe라고 불리는 IPC를 지원한다. Pipe를 응용하면 외부 프로세스와의 통신에도 사용이 가능하지만 단방향의 통신이라는 단점이 존재한다. (하나의 파이프를 사용하여 생성하면 데이터 중복 문제가 발생) 파이프의 경우 자원의 낭비가 매우 심하다는 단점을 해결하지 못한 상태이다.

-
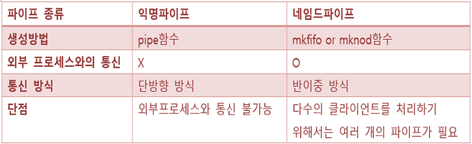
Anonymous Pipe (익명 파이프)
: 외부 프로세스에서 이 파이프를 사용할 수 없기 때문에 익명 파이프로 불린다. 이름이 없기 때문에 외부 프로세스에서는 이 파이프를 부를 수 없지만, 부모 프로세스가 자식 프로세스를 생성하는 경우에 파일 지정 번호를 상속받아서 익명파이프로 통신을 할 수 있다. (매우 제한적인 사용) -
Named Pipe (네임드 파이프)
: 외부 프로세스와 통신을 하기 위해서 파이프에 이름을 붙이자는 생각으로 등장하게 된다. 유닉스 및 유닉스 계열의 일반 파이프를 확장한 것이다. 일반 파이프는 사용하는 프로세스가 실행 중에만 존재하는 반면, Named Pipe는 영구 프로세스가 소멸해도 계속 존재하기 때문에 사용하지 않으면 제거할 필요가 있다. 명명된 파이프는 파일과 같이 취급할 수 있고 IPC를 위해 프로세스가 오픈 되어 사용한다. 또한 동작에서 명명된 파이프를 “FIFO”로 부르기도 한다. (실제로 두 프로세스 간 통신을 하기 위하여 FIFO 파일을 생성한다. FIFO는 mkfifo 함수에 의해 생성되는 특수 파일이다.) 네임드 파이프는 읽기와 쓰기가 모두 가능하지만 한번에 한 방향으로만 통신이 가능한 반이중통신이기 때문에 전이중통신을 위해서는 읽기 파이프와 쓰기 파이프 총 2개의 파이프를 생성해주어야 한다.
3) 대표적인 IPC 모델
-
Message Passing
: 기존에 형성되어 있던 kernel을 거쳐서 message를 전달하는 방식이다. (즉, user level과 kernel level을 넘나드는 작업이라고 생각할 수도 있다.) Kernel이 기존에 형성되어 있기 때문에 쉽게 구현할 수 있다는 장점을 가지고 있고, 같은 파일을 전달하는 데에 있어서 conflict가 발생하지 않는다. 하지만 무언가를 거치기 때문에 kernel에 이를 저장할 공간이 따로 필요하고, 속도도 직접 전달 방식에 비해서 느릴 것이다. 또 level 차이로 인해서 매번 System call이 호출되고, 이로 인한 overhead도 발생하게 된다. kernel을 통해서 통신을 하기 때문에 전달할 내용이 도착하기 전에 또 보내라는 신호를 보낸다면 문제가 발생할 수 있다. 이 때, 동기적으로 처리할 것인지 비동기 처리할 것인지에 따라 달라진다. 동기적으로 처리하는 방식을 보통 Blocking이라고 하는데 받은 결과가 올 때까지 나머지 접근에 대해 Block한다는 것이다. (MP 방식에서는 Send(), Recv()를 통해서 메시지를 주고 받는다. send나 recv를 수행할 때는 원하는 작업이 완료될 때까지 나머지에 대한 Block을 거는 것이다.) -
kernel이란
: 커널은 컴퓨터 운영체제의 가장 중요한 핵심으로서, 운영 체계의 다른 모든 부분에 여러 가지 기본적인 서비스를 제공한다. 비슷한 말로는 “뉴클리어스”라는 용어가 있다. 커널은 쉘과 대비될 수 있는데, 쉘은 운영 체계의 가장 바깥 부분에 위치하고 있으면서, 사용 명령에 대한 처리를 담당한다. -
Shared Memory
: Process 사이에 Shared된 공간이 존재한다. 이 때문에 System call을 부를 필요가 없어 kernel에 대한 의존성이 낮다. 속도가 빠르고 communication에 대한 편의성도 높다. 하지만 생성 공간에 대한 제한이 존재한다. 현존하는 IPC 기법 중 가장 속도가 빠르다. -
Producer-Consumer Problem
: 정보를 만든 producer, 정보를 소비할 consumer가 존재한다. 생산과 소비를 반복하다 보면, 아무것도 없는 상태에서 consumer가 소비하려고 시도하는 경우가 발생할 수 있다. 이러한 경우 shared memory 안에 원하는 데이터가 존재하지 않으니 정상 동작하지 못한다. 반대로 shared memory가 가득 찬 상태에서 producer가 추가로 생성을 시도하는 경우도 발생할 수 있다. 이런 문제를 보통 Producer-Consumer Problem 이라고 한다. 그렇기 때문에 shared memory 방식에서는 producer와 consumer사이의 동기화가 반드시 필요하다. 그러려면 Buffer의 상태를 지속적으로 확인해야 하는데 이런 방법을 Mornitoring이라고 한다. 이 밖에도 “세마포어”나 “뮤텍스”와 같은 Critical Section을 지정하는 방식으로 강제 동기화 하는 방법도 존재한다.
2. CPU Scheduling
1) Scheduling텍스트
: 한 프로세스가 CPU를 사용하고 다른 프로세스의 실행은 I / O 등과 같은 리소스를 사용할 수 없기 때문에 대기 상태에 있어 CPU를 최대한 활용할 수 있도록 하는 프로세스이다. CPU 스케줄링의 목표는 시스템을 효율적이고 빠르며 공정하게 만드는 것이다. 크게 스케줄링은 선점과 비선점 방식으로 나뉜다.
- 선점 스케줄링 (Preemptive)
: CPU가 어느 프로세스를 실행하고 있는데(아직 끝나지도 않았고 IO를 만난 것도 아닌데) 강제로 쫓아내고 새로운 것이 들어갈 수 있는 스케줄링 방식 - 비선점 스케줄링 (Non-Preemptive)
: 프로세스가 끝나거나 IO를 만나기 전엔 안됨
2) CPU Scheduling Criteria
- CPU 이용률 (CPU utilization)
: 모든 CPU 스케줄링 알고리즘의 주요 목적은 CPU를 최대한 바쁘게 유지하는 것이다. - 처리량 (Throughput)
: CPU에서 수행한 작업의 척도로, 시간당 실행되고 완료되는 프로세스 수를 의미한다. - 반환 시간 (Turnaround time)
: 프로세스 제출 시간에서 완료 시간까지의 경과 시간을 반환 시간이라고 한다. (레디큐에 들어간 작업이 나오는 시간) - 대기 시간 (Waiting time)
: 프로세스가 레디 큐에 들어가기 위해 대기한 시간이다. - 응답 시간 (Response time)
: 요청 프로세스의 제출에서 첫 번째 응답이 생성될 때까지 걸리는 시간이다. Interactive System에서 중요하다.
3) Process State텍스트
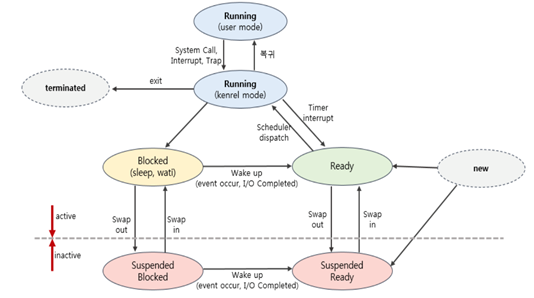
- New : 프로세스 생성 중 (커널 공간에 PCB가 만들어진 상태)
- Ready : 프로세스가 CPU를 기다리는 상태 (CPU를 제외하고 필요한 자원을 모두 얻은 상태)
- Running : 프로세스가 CPU를 할당 받아 명령어를 수행중인 상태
- Blocked : 프로세스가 CPU를 할당 받아도 당장 실행할 수 없는 상태 (현재 프로세스가 I/O 작업 등을 처리 중인 상태를 의미)
- Terminated : 프로세스의 실행 종료 (프로세스 실행이 완료되고 할당된 CPU를 반납, Kernel 내의 PCB는 남아있음)
- Suspended : 프로세스의 중지 상태 (메모리를 강제로 뺏긴 상태로 특정한 이유로 프로세스 수행이 정지된 상태를 의미한다. 외부에서 다시 재개시키지 않는 이상 활성화될 수 없음.)
- Suspended Ready : 준비 상태에 있던 프로세스가 디스크로 스왑 아웃
- Suspended Blocked : 봉쇄 상태에 있던 프로세스가 디스크로 스왑 아웃
※ Blocked
프로세스 A가 CPU를 할당 받고(running상태) 명령어를 실행하다 I/O 작업을 해야 하는 경우, 디스크 I/O 작업은 CPU 처리 속도에 비해 오래 걸리는 작업이기 때문에 디스크 I/O 작업 동안은 CPU를 점유하고 있어도 다음 명령어를 수행하지 못한다. (CPU 낭비 발생) 때문에 디스크 I/O 작업을 하는 프로세스는 CPU를 반납하고 장치 큐에 가서 줄을 서게 된다(blocked 상태). 이후 디스크 컨트롤러에 의해 서비스를 받아 일을 수행하면 디스크 컨트롤러가 CPU에게 일을 끝났음을 알린다 (인터럽트 발생). 이후 프로세스 A는 장비 큐에서 빼내어 레디큐로 넣어주고 프로세스 A가 한 일은 메모리에 올라가게 된다.
※ blocked 와 suspended의 차이
blocked : 잠시 중지되어 있다가 끝나면 다시 ready상태로 돌아온다.
suspended : 잠시 중지되어 있다가 누군가가 재개 시켜줘야 다시 ready상태로 돌아올 수 있다.
4) Scheduling의 종류
① FIFO(First In First Out) 스케줄링
: 가장 간단한 스케줄링 기법으로, 먼저 대기 큐에 들어온 작업에게 CPU를 먼저 할당하는 비선점 스케줄링 방식이다.
② Priority 스케줄링
: 각 작업마다 우선순위가 주어지며, 우선순위가 제일 높은 작업에 먼저 CPU가 할당되는 방법이다. 우선 순위가 낮은 작업은 Indefinite Blocking 이나 Starvation에 빠질 수 있고, 이에 대한 해결책으로 체류 시간에 따라 우선 순위가 높아지는 Aging 기법을 사용할 수 있다
③ Deadline 스케줄링
: 작업이 주어진 제한 시간이나 Deadline 시간 안에 완료되도록 하는 기법이다.
④ Round Robin
: FIFO 스케줄링 기법을 Preemptive 기법으로 구현한 스케줄링 방법으로 프로세스는 FIFO 형태로 대기 큐에 적재되지만, 주어진 시간 할당량(Time Slice) 안에 작업을 마쳐야 하며, 할당량을 다 소비하고도 작업이 끝나지 않은 프로세스는 다시 대기 큐의 맨 뒤로 되돌아간다. (선점 스케줄링) 사용자에게 적합한 응답시간을 제공해주는 대화식 시분할 시스템에 적합하다.
⑤ SJF(Shortest Job First) 스케줄링
: SJF는 비선점 스케줄링 기법으로, 처리하여야 할 작업시간이 가장 적은 프로세스에 CPU를 할당하는 기법이다. 평균 대기 시간이 최소인 최적의 알고리즘이지만, 각 프로세스의 CPU 요구 시간을 미리 알기 어렵다는 단점이 있다.
⑥ SRT(Shortest Remaining Time) 스케줄링
: SJF 스케줄링 기법의 선점 구현 기법으로, 새로 도착한 프로세스를 비롯하여 대기 큐에 남아 있는 프로세스의 작업이 완료되기까지의 남아있는 실행 시간 추정치가 가장 적은 프로세스에 먼저 CPU를 할당한다.
⑦ HRN(High Response Ratio Next) 스케줄링
: Brinch Hansen이 SJF 스케줄링 기법의 약점인 긴 작업과 짧은 작업의 지나친 불평등을 보완한 스케줄링 기법이다. (대기 시간 + 서비스 시간) / (서비스 시간)으로 우선순위를 결정한다. 서비스 시간이 분모에 있어 짧은 작업의 우선순위가 높아지고, 대기 시간을 분자에 둠으로써 긴 작업도 대기 시간이 큰 경우 우선순위가 높아지게 된다.
⑧ Multilevel Feedback Queue 스케줄링
: 다양한 특성의 작업이 혼합된 경우 매우 유용한 스케줄링 방법으로, 새로운 프로세스는 그 특성에 따라 각각 대기 큐에 들어오게 되며, 그 실행 형태에 따라 다른 대기 큐로 이동한다. 예를 들어 연산 위주의 프로세스들은 처음에 RR 방식의 대기 큐에서 주어진 시간 할당량이 만료되면 다음 단계의 큐에 배치되고, 실행 시간이 길수록 점점 낮은 우선 순위를 지니게 되어 마지막 가장 낮은 우선 순위의 큐에 도달하면 작업이 끝날 대까지 RR 방식으로 스케줄링된다.
※ Aging 기법
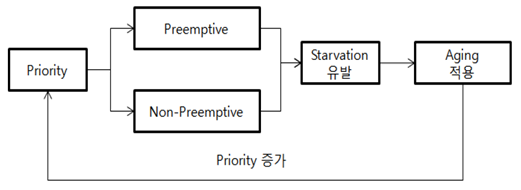
시스템이 어떤 자원을 얼마나 오래 대기했는지 확인하여 우선순위를 높여서 무기한 연기를 방지하는 기법이다.
3. DeadLock
1) DeadLock과 발생 원인
- DeadLock이란
: 프로세스가 자원을 얻지 못해서 다음 처리를 하지 못하는 상태로, “교착 상태”라고도 하며 시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할 때 발생한다. - DeadLock의 발생 상황
멀티 프로그래밍 환경에서 한정된 자원을 사용하려고 서로 경쟁하는 상황이 발생
임의의 프로세스가 자원을 요청했을 때 그 시각에 해당 자원을 사용할 수 없는 상황이 발생할 수 있고, 그 때는 프로세스가 대기상태로 진입
대기 상태로 들어간 프로세스들이 실행 상태로 변경될 수 없을 때 이러한 상황을 교착 상태라 함
2) DeadLock의 발생 조건
① 상호 배제 (Mutual Exclusion)
: 한 자원에 대한 여러 프로세스의 동시 접근 불가
② 점유와 대기 (Hold and wait)
: 자원을 가지고 있는 상태에서 다른 프로세스가 사용하고 있는 자원의 반납을 기다리는 것
③ 비 선점 (Non-preemptive)
: 다른 프로세스의 자원을 강제로 가져올 수 없음
④ 환형 대기 (Circle Wait)
: 각 프로세스가 순환적으로 다음 프로세스가 요구하는 자원을 가지고 있는 것
3) DeadLock 처리
교착 상태를 해결하는 방법에는 크게 두 방법으로 나뉜다. 사전 처리와 사후 처리로 각각 예방, 회피 / 탐지, 회복이 있다.
-
예방
: 교착 상태 발생 조건 중 하나를 제거하면서 해결한다 (자원 낭비 엄청 심함)
상호 배제 부정 : 여러 프로세스가 공유 자원 사용
점유 대기 부정 : 프로세스 실행 전 모든 자원을 할당
비 선점 부정 : 자원 점유중인 프로세스가 다른 자원을 요구할 때 가진 자원 반납
순환 대기 부정 : 자원에 고유번호 할당 후 순서대로 자원 요구 -
회피
: 교착 상태 발생 시 피해나가는 방법
※ 은행원 알고리즘
다익스트라가 개발한 알고리즘으로 은행에서 모든 고객의 요구가 충족되도록 현금을 할당하는 것에서 유래됨
교착상태에 빠질 가능성이 있는지 판단하기 위해 상태를 “
안전 상태”와 “불안전 상태”로 나눔
즉, 운영체제는 안전 상태를 유지할 수 있는 요구만을 수락하고 불안전 상태를 초래할 사용자의 요구는 나중에 만족될 수 있을 때까지 계속 거절함.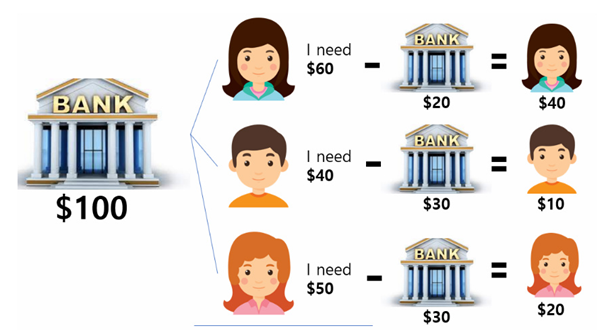
a. 은행이 고객1에게 20달러, 고객2, 고객3에게 각각 30달러씩을 빌려줌
b. 은행이 수중에 갖고 있는 돈은 20달러기 때문에 이 중 10달러를 고객2에게 빌려주고 고객이 어려운 상황을 해결하고 돈을 갚을 때까지 기다림
c. 은행은 10달러가 남지만, 고객2로부터 40달러를 돌려받아 50달러가 되므로 고객1이나 고객3을 도울 수 있음.
d. 이러한 방식으로 모든 고객들에게 돈을 빌려주고 은행이 다시 돈을 돌려 받을 수 있는 상태를 안전상태라고 함.
고객2 – 고객1 – 고객3
고객2 – 고객3 – 고객1
고객3 – 고객1 – 고객2
고객3 – 고객2 – 고객1
이런 순서로 모든 고객의 상황을 해결해 줄 수 있고, 이를 “안전 순서열”이 존재한다고 함
반면에 고객1의 상황이 긴박해서 최소 35달러는 필요하다는 상황을 가정함.
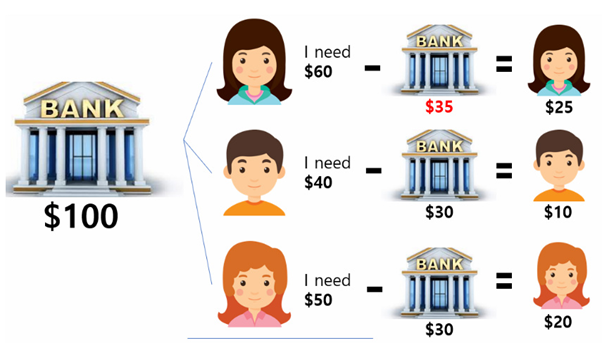
이러한 경우 은행에 남은 돈이 5달러 밖에 없기 때문에 누구의 문제도 해결해줄 수 없음. 이런 상태를 불안정 상태 또는 데드락 상태라고 한다.
즉, 은행원 알고리즘은 “최소한 고객 한 명에게 대출해줄 금액은 항상 은행이 보유하고 있어야 한다.”는 개념에서 나온다.
은행원 알고리즘이 제대로 수행되기 위해선 다음과 같은 조건이 필요함.
1. 각 고객들의 최대 돈 요구치[Max]
2. 각 고객들이 현재 빌린 돈이 얼마인지[Allocated]
3. 은행이 보유한 돈이 얼마인지, 빌려줄 수 있는 돈이 얼마인지[available]
은행원 알고리즘의 단점
ㄱ. 할당할 수 있는 자원의 수가 일정해야 한다.
ㄴ. 사용자의 수가 일정해야 한다.
ㄷ. 항상 불안전 상태를 방지해야 하므로 자원 이용도가 낮다.
ㄹ. 최대 자원 요구량을 미리 알아야 한다.
ㅁ. 프로세스들은 유한한 시간 안에 자원을 반납해야 한다.
ㅂ. 위의 단점들 때문에 굉장히 오버헤드가 크다.
- 교착상태와 은행원 알고리즘의 불안전 상태(Unsafe State)에 대한 설명으로 가장 옳은 것은?
① 교착상태는 불안전상태에 속한다.
② 불안전상태의 모든 시스템은 궁극적으로 교착상태에 빠지게 된다.
③ 불안전상태는 교착상태에 속한다.
④ 교착상태와 불안전상태는 서로 무관하다.
3) 탐지
자원 할당 그래프를 통해 교착 상태를 탐지한다.
자원 요청 시 탐지 알고리즘을 실행시켜 그에 대한 오버헤드가 발생한다.
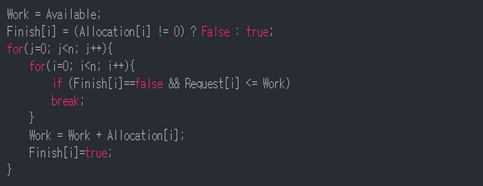
교착상태 탐지는 그러한 검토 없이 일단 자원 할당을 해주고 교착상태가 발생했는지 만을 주기적으로 검사하는 방법이다. 교착 상태 탐지 알고리즘은 현재 할당된 자원이 없다면 Finish값을 True로 처리해 놓는다. 자원을 갖고 있지 않은 프로세스는 교착상태에 연루되지 않을 것이므로 탐지의 대상에서 제외하는 것이다. 반복문을 모두 돌았을 때 모든 i에 대해 Finish가 true가 아니라면 시스템에 교착상태가 존재함을 탐지한 것이다.
4) 회복
- 순환 대기를 깨트리기 위하여 단순히 한 개 혹은 그 이상의 프로세스를 중지시키는 방법
: 교착상태의 모든 프로세스를 중지시키는 것이 가장 확실하지만, 해당 자료들을 전부 잃게 되므로 비용이 커진다. 따라서 교착상태 탐지 알고리즘을 통해 한 프로세스씩 중지시키는 방법을 차용할 수 있는데, 약간의 오버헤드는 감수해야 한다. - 교착상태에 있는 하나 이상의 프로세스들로부터 자원을 'preemption' 즉 선점해 오는 방법
: 선점이 가능하기 위해서는 rollback이 이루어져야 한다. 안정상태가 확인될 때까지 자원을 이동시키면서 rollback 시키고, 그 상태에서 다시 시작하는 것이다. 하지만 이러한 rollback은 안정상태를 결정하기 어렵고 프로세스들의 상태 정보를 더 많이 관리해야 하기 때문에 처리가 어렵다. 따라서 가장 단순한 방법은 앞서 설명한 '중지'이다. 또한 선점 방식은 특정 프로세스의 자원만 계속 선점하여 기아 상태를 유발시킬 수 있다. 프로세스의 선점 횟수를 유한하게 제한하거나 선점 당한 횟수를 비용 요소에 반영하는 방식으로 이를 방지할 수 있다.
※ 식사하는 철학자들
다섯 명의 철학자가 원탁에 앉아 있고, 각자의 앞에는 스파게티가 있고 양 옆에 포크가 하나씩 있다. 그리고 각각의 철학자는 다른 철학자에게 말을 할 수 없다. 이때 철학자가 스파게티를 먹기 위해서는 양 옆의 포크를 동시에 들어야 한다. 이때 각각의 철학자가 왼쪽의 포크를 들고 그 다음 오른쪽의 포크를 들어서 스파게티를 먹는 알고리즘을 가지고 있으면, 다섯 철학자는 동시에 왼쪽의 포크를 들 수 있으나 오른쪽의 포크는 이미 가져가진 상태이기 때문에 다섯 명 모두가 무한정 서로를 기다리는 교착 상태에 빠지게 될 수 있다.
또한 어떤 경우에는 동시에 양쪽 포크를 집을 수 없어 식사를 하지 못하는 기아 상태가 발생할 수도 있고, 몇몇 철학자가 다른 철학자보다 식사를 적게 하는 경우가 발생하기도 한다.
이를 해결하기 위한 다익스트라의 해결책은 다음과 같다. 각각의 철학자를 P1, P2, P3, P4, P5라고 하고, 각 철학자의 왼쪽 포크를 F1, F2, F3, F4, F5라고 하자. P5를 제외한 네 명은 먼저 Fn을 집은 후 Fn+1을 집는 방식을 취한다. 그리고 P5는 이와 반대로 F1을 먼저 집은 후 F5를 집는다 이것은 원래 방식의 대칭성을 제거하고, 따라서 교착상태를 막을 수 있다.
