JPA란?
1. JPA와 ORM
JPA(Java Persistence API)와 ORM 을 이해하기 전에 등장 배경을 살펴봅시다.
객체지향적으로 개발하다보면 생기는 문제가 있다. 객체를 데이터베이스에 저장해야되는데, 만약 객체에 필드 데이터 하나가 갑자기 추가된다면? 지금까지 작성한 모든 SQL문에 칼럼을 하나씩 다 추가해줘야 합니다. 물론 하나가 빠져야 하는 경우에도 동일한 문제가 생깁니다.

이는 너무나 비효율적이고 에러가 생길 가능성이 너무 높습니다. 이런 문제가 생기는 가장 근본적인 원인은 객체지향 언어와 관계형 데이터베이스는 뿌리부터 다르기 때문이다. (상속, 데이터 타입, 연관관계, 데이터 식별 방법 등등)

또한, JDBC API를 사용하던 시기에는 Connection 객체 받아오고, 쿼리 적고, 마지막에 .close()로 자원 해제하는 등등.. 의 코드가 쿼리를 다룰때마다 반복적으로 등장했기에 코드 길이도 길어지고 가독성도 떨어졌습니다.

이후에 나온것이 MyBatis와 같은 SQL Mapper입니다. 자원관리는 이들이 해주기에 개발자는 순수 SQL 코드만 작성하면 되었습니다.

다만, 특정 객체 조회방식이 조금만 달라져도 각각 쿼리를 다 작성해야 했고, 직접 쿼리를 만지다보니 일일히 테스트를 다 해보지 않으면 Service에서 호출 해온 코드를 신뢰할 수 없다는 문제가 있죠.
ORM(Object-Relational Mapping)은 말그대로 자바의 객체(Object)를 관계형 데이터베이스(RDB)에 매핑해주는 기술입니다. (자바에만 존재하는 기술은 아니며, 대중적인 언어에는 대부분 존재하는 기술임)
SQL이 아닌 Method를 통해 DB를 조작한다는 것이 핵심이다. (내부적으로는 쿼리를 생성하여 DB를 조작하지만, 개발자는 이를 신경쓸 필요가 없음)
JPA는 자바 ORM 기술에 대한 API 표준 명세를 의미합니다.
Java 컬렉션에서 같은 키 값으로 객체를 조회하면 항상 같은 객체를 반환합니다.
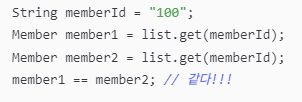
컬렉션에 저장하듯 DB에 간단히 저장하고, 간편하게 조회할 수 있으면서 항상 동일한 객체 반환이 보장되는 이러한 장점을 JPA는 제공해줍니다.
단순히 표현하자면 Java 컬렉션에 저장하듯이 DB에 저장할 수 없을까라는 물음의 답이 바로 JPA입니다.
JPA는 ORM을 사용하기 위한 인터페이스의 모임이며, 이러한 JPA라는 인터페이스들을 사용하기 위해서는 '구현체'를 사용해야합니다.
JPA의 구현체로는 Hibernate, EclipseLink, DataNucleus 등이 있습니다.
2. JPA 의 작동방식
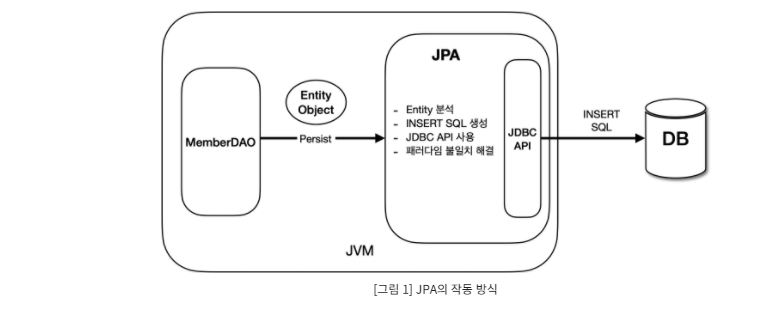
JPA는 Java 애플리케이션과 JDBC 사이에서 동작합니다.
JPA도 내부적으로는 JDBC API를 통해 쿼리를 생성해야합니다.
3. JPA 장점

JPA를 쓰는 경우의 CRUD입니다. 저 4줄의 코드만으로 쿼리를 손댈 필요없이 CRUD가 가능해집니다. 개발자들은 더이상 복잡한 쿼리를 짜지않고 객체지향적으로 개발에 몰두 가능해집니다.
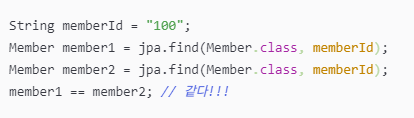
또한, 아까 언급했던 컬렉션의 장점처럼 JPA도 동일한 트랜잭션에서 조회한 엔티티(객체)는 동일함을 보장받기에 굳이 테스트를 다 해보지 않아도 된다는 장점이 있습니다.
성능 또한 개선이 가능합니다. JPA가 JDBC API를 가기전 한번 더 거치기 때문에 성능이 문제되지 않을까라는 염려를 하지만, 중간 계층이 존재하면 항상 할 수 있는게 있습니다.
- 모아서 쏘는 버퍼링
- 읽을 때 캐싱하기
이 두가지를 잘 활용하면 JPA로 오히려 성능향상이 가능합니다.
다음 3가지는 JPA에서 성능 최적화를 위해 제공하는 기능입니다.
- 1차 캐시와 동일성(identity) 보장
- 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
- 지연 로딩(Lazy Loading)
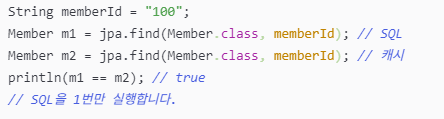
첫번째로 1차 캐시와 동일성 보장은 위에서 언급했듯, 컬렉션과 같이 동일한 키값으로 조회하면 동일한 엔티티 객체를 보장받는다는 것, 그리고 여러번 읽게되면 캐시에 있는 것을 바로 읽을 수 있다는 것입니다.

두번째로 자바 애플리케이션과 JDBC API 사이에 JPA라는 중간계층이 있다면 모아서 쏘는 버퍼링이 가능하다고 했는데 이러한 특징이 트랜잭션을 지원하는 쓰기 지연 기능입니다.
트랜잭션을 커밋할 때까지 INSERT SQL을 모았다가 커밋하면 한번에 SQL을 DB로 전송합니다.
세번째로, JPA에는 데이터를 조회하는 경우 즉시(EAGER) 로딩과, 지연(LAZY) 로딩이 있습니다.
즉시 로딩은 데이터를 조회하는 경우 연관된 데이터를 한번에 불러오는 것이고
지연 로딩은 필요한 시점에 연관된 데이터를 불러오는 것.
@XXToXX(fetch = FetchType.LAZY)라는 어노테이션을 엔티티 객체에 설정하면
지연 로딩을 할 수 있다.
예를 들어 Member 객체를 조회하면 연관된 Team 객체가 1000개 있다면 매번 Member을 조회할 때마다 Team 을 조회하는 쿼리가 1000개가 더 나가는 것임.
그래서 직접 Team 을 조회하는 경우에만 쿼리가 날아가도록 하는 것임.
