
🎓 강화학습(Reinforcement Learning, RL)이란?
강화학습(Reinforcement Learning, RL)은 인공지능(AI)과 머신러닝의 한 분야로, 에이전트(Agent)가 환경(Environment)과 상호작용하면서 시행착오(Trial and Error)를 통해 최적의 행동(Optimal Action)을 학습하는 방법
🎓 기계학습(Machine Learning, ML) 분류
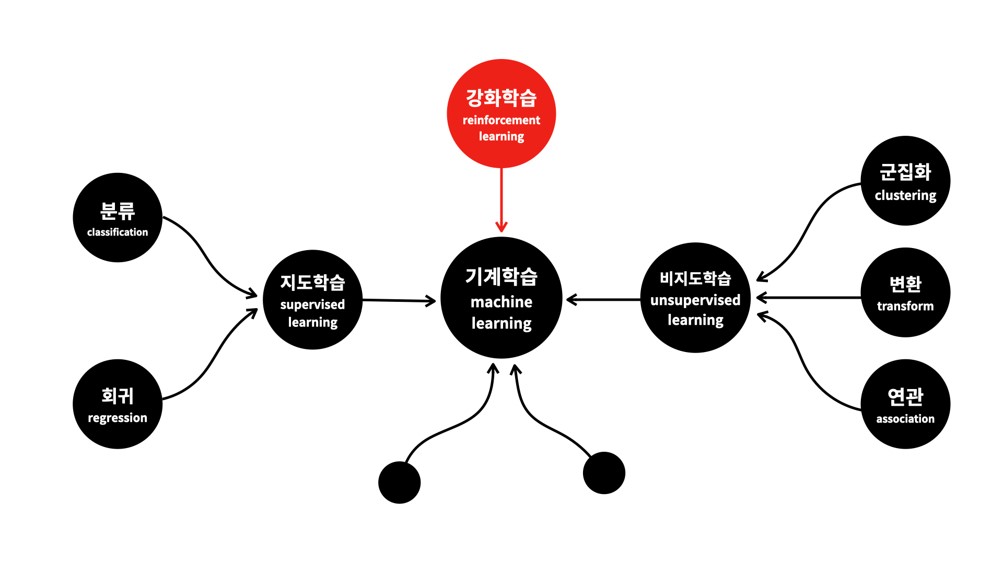
- 지도학습
입력 데이터와 정답(Label)을 사용하여 학습하여 새로운 입력에 대해 정확한 출력을 예측 - 비지도학습
정답(Label) 없이 데이터의 구조를 학습하여 데이터의 패턴이나 그룹을 발견. - 강화학습
에이전트가 환경과 상호작용하며 보상을 최대화하는 방식으로 학습 최적의 행동(정책)을 학습
🎓 강화학습(Reinforcement Learning, RL) 개념
"강화학습의 목적은 주어진 환경(Environment) 내에서 에이전트(agent)가 액션(Action)을 취할 때, 보상 정책(Policy)에 따라 관련된 변수 상태 s와 보상이 수정된다."
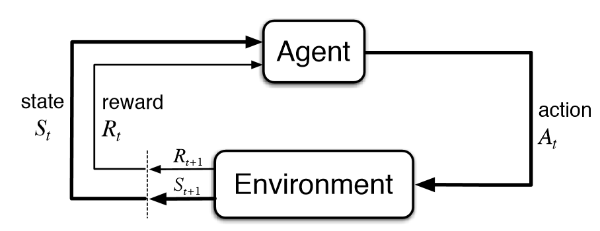
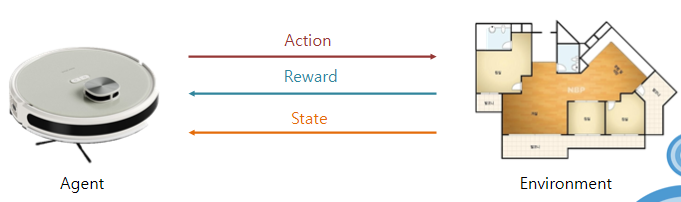
강화학습에서 에이전트는 환경(Enveironment)과 상호작용하면서 학습하며 이 과정에서 에이전트는 환경에 대한 사전 지식이 없기 때문에, 다양한 행동(Action)을 시도하며 시행착오(Trial and Error)를 거친다. 이를 통해 어떤 행동이 더 나은 보상을 가져오는지 점차 배우고, 최종적으로 보상(Reward)을 최대화하는 방법을 학습하게 된다.
🔎 예시
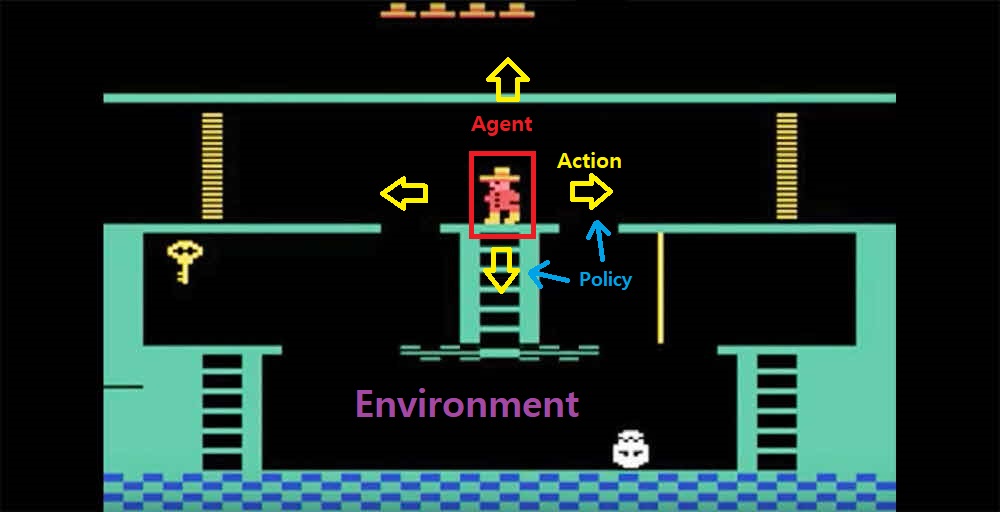
🎓 강화학습 분류

강화학습은 크게 2가지로 나뉘는데 바로 Model-Free RL과 Model-Based RL이다.
-
Model-Free RL:
모델이 없는 강화학습으로, 에이전트가 환경의 모델을 알지 못한 상태에서 시행착오(Trial and Error)를 통해 학습하는 방법으로 강화학습하면 Model-Free RL을 생각할 정도로 대표적인 방식이며 환경을 정확히 모델링하기 어렵거나 모델링이 필요하지 않은 상황에 사용된다. 환경의 모델이 없기 때문에 Model-Based RL에 비해 학습 시간이 오래 걸리는 단점이 있다. -
Model-Based RL:
환경의 모델을 학습하거나, 사전에 제공된 환경의 모델을 활용해 정책을 학습하는 방법으로 환경의 모델이 있으면 에이전트가 행동 결과를 미리 예측할 수 있어 학습 효율(Sample Efficiency)이 높아지지만, 현실 세계에서는 환경 모델을 정확히 아는 것이 어렵거나 불가능한 경우가 많아 적용이 제한적이다. 하지만 게임(바둑, 체스 등)처럼 규칙이 명확하고 환경 모델을 완벽히 정의할 수 있는 경우 Model-Based RL을 사용는 것이 유리하다.
🎓 용어 정리
- Model
환경 자체의 동역학을 근사하는 모형으로 환경이 아니라, 환경의 규칙(물리법칙, 게임 규칙)을 이해하고 있는 것 → 모델을 알고 있다면 학습 속도와 효율성이 높아질 수 있음
환경: 지구
모델: 지구상의 물리법칙(중력, 공기저항 등..) - Action
Agent가 실행한 실제 행동 Policy에 의해 도출되고 a로 표현 - State
Agent가 행동을 결정하기 위해 필요한 구체적 정보(ex. 위치, 속도)를 말한다. Agent가 action을 하면, 그에따라 환경이 agent의 상태를 변화시킴 흔히 s로 표현 - Environment
에이전트의 행동에 따라 변화를 일으키는 시스템 - Reward
에이전트가 행동을 수행한 결과로 받는 값으로 특정 행동을 유발시키기 위해 positive reward(보상)를, 특정 행동을 금지시키기 위해 negative reward(벌점)를 취할 수 있다. - Policy
Agent가 움직이는 행동 방향. 정책으로도 불리며, 크게 deterministic policy와 stochastic policy로 나뉜다.
🎓 향후 연구 계획
현재 연구의 목적 : "Playing Atari with Deep Reinforcement Learning"을 읽기 위한 기초 발판을 마련
-
마르코프 결정 과정(MDP)
상태, 행동, 보상, 상태 전이 확률, 할인율에 대한 수학적 정의와 이해 -
Q-learning과 딥 Q 네트워크(DQN)
Q-learning 알고리즘의 원리 이해 DQN의 구조와 주요 구성 요소 (Replay Buffer, Target Network 등)에 대한 탐구
