
🎓 자율 주차 강화학습 실험 개요
본 프로젝트는 PPO(Proximal Policy Optimization) 알고리즘의 내부 동작 원리를 심층적으로 이해하기 위해 구상되었다. 이를 위해 Unity ML-Agents 플랫폼 상에 자율 주차 시뮬레이션 환경을 신규 구축하고, 해당 환경에서 에이전트를 학습시키는 과정을 수행하였다.
기존 다수 연구가 사전에 주어진(pre-defined) 환경에 알고리즘을 적용하는 데 집중하는 것과 달리, 본 연구에서는 강화학습의 핵심 요소인 환경 설계(Environment Design)와 에이전트 구현(Agent Implementation)에 초점을 맞추었다. C# 스크립트를 이용해 주차장 씬(Scene)을 구축하였으며, 그 위에 Python API로 제어되는 자동차 에이전트(Car Agent)를 탑재하였다. 에이전트는 차량의 속도, 조향각, 제동 상태를 관측 정보(Observation)로 사용하여 웨이포인트(Waypoint) 기반의 주차 과업을 수행하도록 학습 흐름을 구성하였다.
보상 설계(Reward Engineering) 측면에서는 에이전트의 행동을 정교하게 유도하고자 다각적인 접근법을 시도하였다. 단순한 최종 성공 보상만으로는 효율적인 학습이 어렵다는 한계를 인식하고, '신속성'보다 '정확성'을 기준으로 에이전트의 행동을 최적화하는 것을 목표로 설정하였다. 이를 위해 목표 지점과의 거리 기반 보상, 웨이포인트 통과 보상, 충돌 및 시간 초과에 대한 페널티(Penalty), 그리고 목표 주차 구역 내 체류 시간에 따른 추가 보상 등 여러 요소를 조합하여 적용하였다. 각 보상 요소가 학습 속도 및 안정성에 미치는 영향을 비교 분석하여 최적의 보상 함수를 도출하고자 하였다.
또한, 학습 초기 단계의 효율성을 높이기 위해 커리큘럼 학습(Curriculum Learning)을 도입하였다. 에이전트는 초기에 비교적 쉬운 지점에서 과업을 시작하며, 주차 성공률이 일정 기준을 충족함에 따라 점진적으로 더 어려운 위치에서 출발하도록 난이도를 동적으로 조정하였다.
학습의 전 과정에서 측정된 주요 성과 지표(에피소드 누적 보상, 주차 성공률, 정책 수렴 속도 등)는 Weights & Biases 툴을 사용하여 기록 및 시각화하였다. 이를 통해 PPO 알고리즘의 고유 특성과 연구자가 직접 설계한 환경, 에이전트, 보상 체계가 상호작용하는 양상을 종합적으로 분석하였다.
🎓 실습 환경
Python 및 주요 라이브러리
-
Python 버전: 3.9.x
-
C#
-
주요 패키지
-
numpy
-
gym (커스텀 래퍼 사용 시)
-
torch (PyTorch)
-
mlagents_envs (Unity ↔ Python 통신)
-
-
가상환경 관리 : conda
-
Code 관리 : Notion -> Git 사용 X
Unity 및 ML-Agents
-
Unity 버전 : 2021.3 LTS
-
ML-Agents 패키지 버전 : 3.0.0
🎓 환경(Environment)
주차장 레이아웃
-
전체 구조: 직사각형 평면 위에 주차 공간(Goal Spot)과 진입로(Entrance), 보행자용 인도(Sidewalk), 각종 장애물(주차된 차량·가로등·표지판 등)이 배치된 씬(Scene)
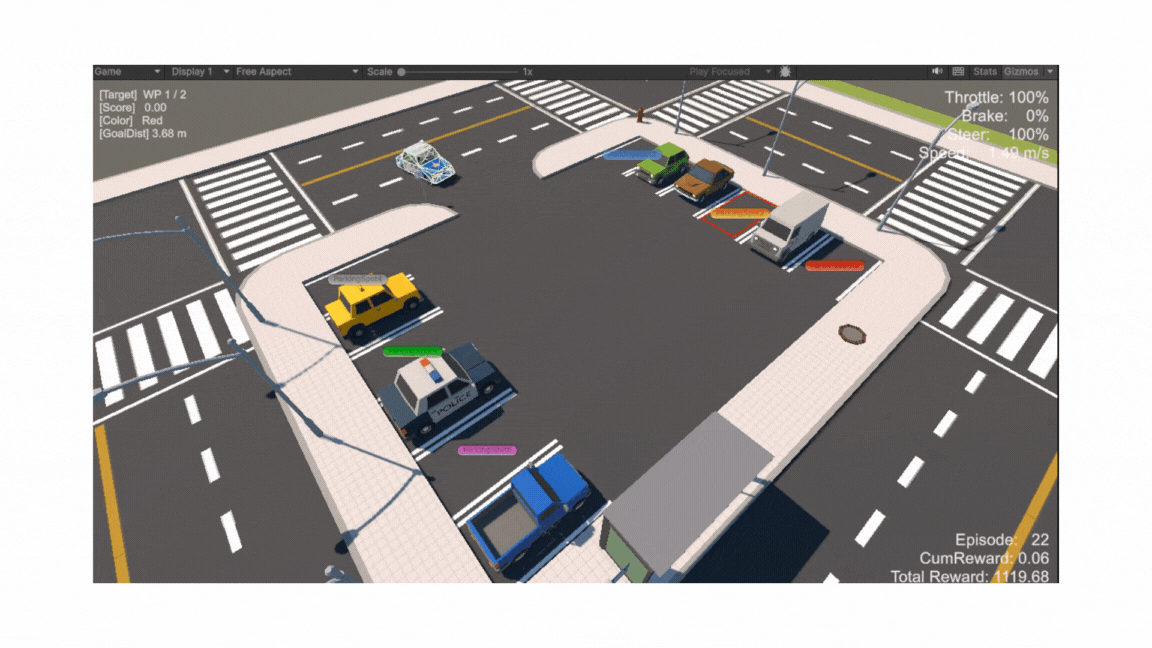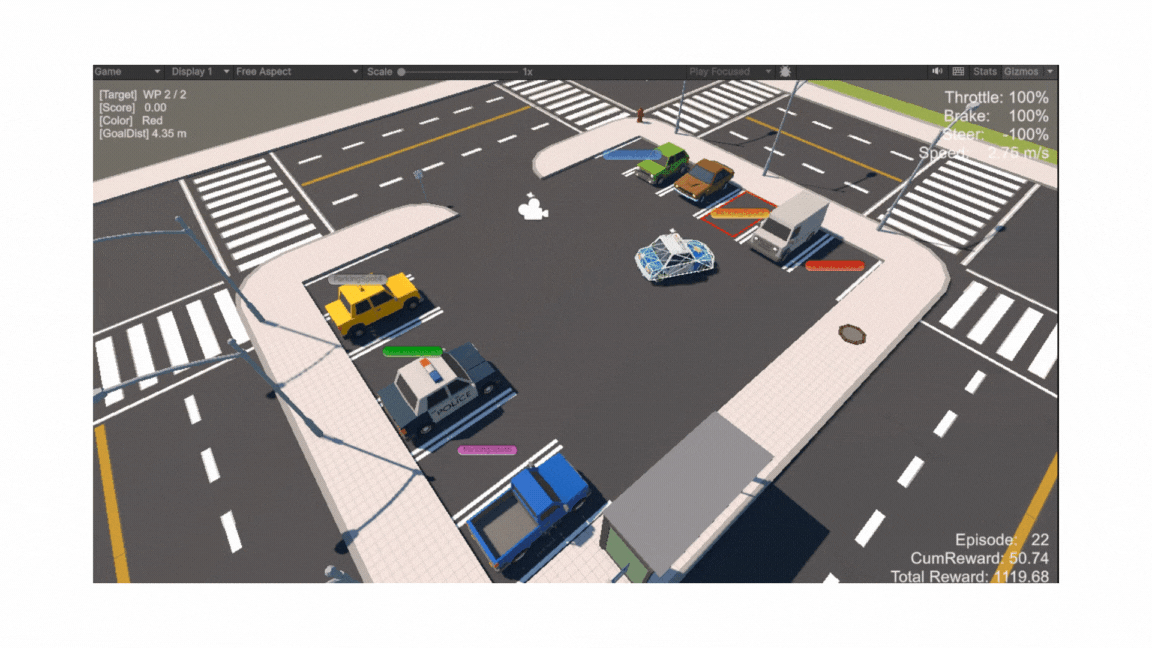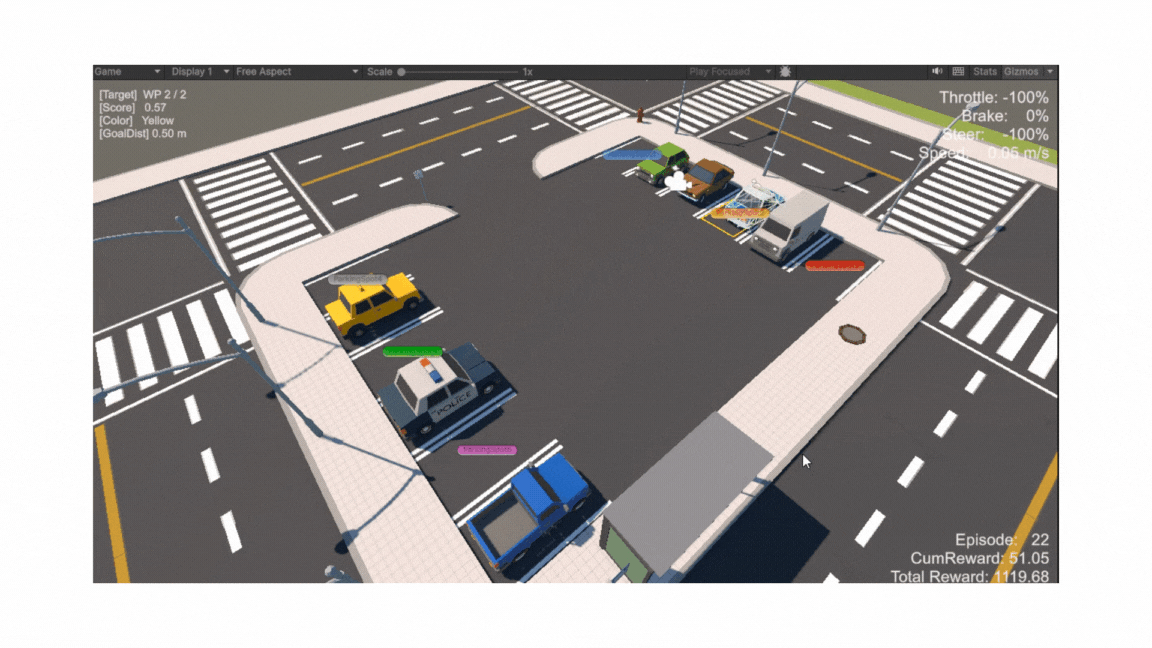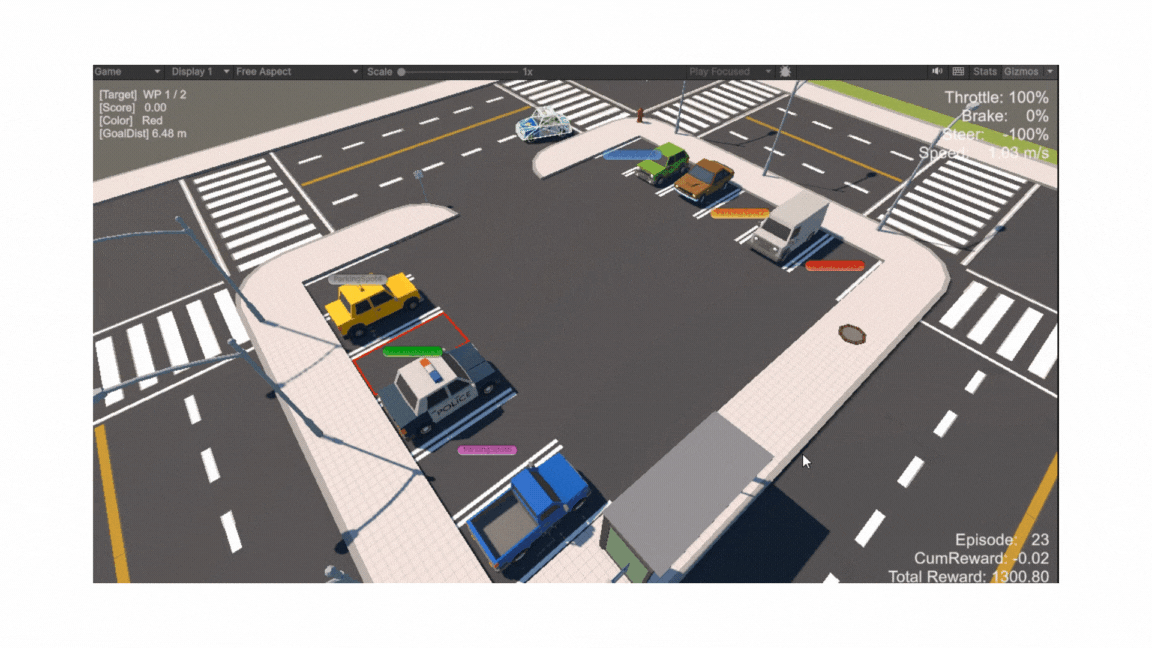
-
구획:
-
각 주차 라인에는 3개 정도의 주차 칸이 1열로 나열
-
입구 쪽으로는 차량이 진입했을 때 자연스럽게 꺾어 들어갈 수 있도록 완만한 곡선 진입로
-
경계선에는 울타리나 낮은 연석으로 둘러 안정적인 주차 동선을 유도
-
Goal Spot (주차 공간)
- 주차 스팟 표시:

-
parkingSpots 배열에 담긴 Transform 객체들로 구현
-
각 스팟마다 Flat Plane 위에 텍스처 또는 컬러로 시각화
-
하이라이트:
-
에이전트가 목표로 설정한 스팟에 LineRenderer로 테두리를 그려줌
-
주차 정확도(dbgScore)에 따라 실시간 색상(Green→LightGreen→Yellow→Orange→Red) 변경





-
주차장 입구 (Entrance)
-
정의
-
EntranceTransform 으로 지정된 게임 오브젝트
-
에이전트의 첫 번째 웨이포인트로 설정하여, 주차 공간으로 직행하지 않고 진입로를 거치도록 유도
-
-
역할
-
강화학습에서 중간 목표(Medium-Term Goal) 역할
-
입구 통과 시 WAYPOINT_REWARD 보상 지급
-
장애물 및 인도 (사이드워크)
-
장애물(Obstacles)
-
generalObstacleMask 레이어 마스크로 관리
-
주차된 차량(ParkedCar), 가로등(LampPost), 표지판(Sign), 소화전 등

-
충돌 시 COLLISION_PENALTY 부여하고 에피소드 종료
-
-
인도(Sidewalk)
-
sidewalkMask 레이어 마스크로 감지
-
WheelCollider 기반으로 바퀴가 인도를 밟으면 COLLISION_PENALTY 적용
-
PerformSphereCasts 관측에는 포함하되, 실제 페널티는 FixedUpdate의 실패 조건에서 처리
-
스폰(출발) 영역
-
Level별 스폰 범위 (GetRandomPositionForLevel 활용)
-
Level 1(Yellow): X∈[0,12] Z∈[–7,3] -
-
Level 2(Orange): X∈[–6,22] Z∈[–8,0]
-
Level 3(Red): X∈[–8,24] Z∈[–8,12]
-
Default(Black): 인스펙터에서 설정한 spawnMinX, spawnMaxX, spawnMinZ, spawnMaxZ 범위
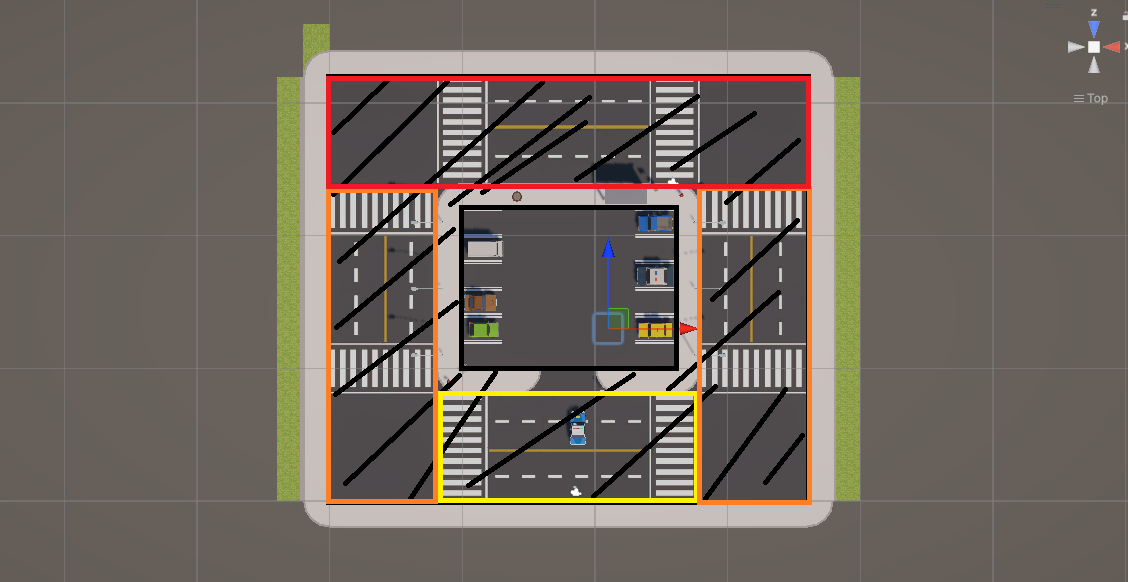
-
-
유효성 검사 (IsSpawnPositionValid)
-
불가 구역 체크: 인도·주차장·주차공간·주차된 차량 내부는 제외
-
Raycast & OverlapBox: 물리 레이캐스트 및 박스 오버랩으로 태그 검사
-
-
초기 회전:
-
Level 1: Y축 회전 –90°~+90°
-
그 외 레벨: 0°~360° 무작위
-
🎓 Agent

Agent는 CarAgent : Agent 형태로 ML-Agents의 기본 클래스를 상속하여 구현한다. 초기화(Initialize) 단계에서 물리 컴포넌트와 센서, 주차 스팟을 설정하고, 에피소드 시작(OnEpisodeBegin) 시 스폰 위치·웨이포인트·하이라이트를 재구성한다. 이후 CollectObservations를 통해 속도·위치·SphereCast 센서 값을 수집하고, OnActionReceived 또는 Heuristic으로 행동 명령을 받아 차량 컨트롤러에 전달한다. 물리 시점(FixedUpdate)에서는 시간·거리 보상과 웨이포인트 보상을 처리하고 실패 조건을 검증하며, 화면 업데이트(Update) 단계에서는 주차 정확도 기반 보상 및 최종 성공 판정을 수행한다. 이처럼 Agent는 “관측→행동→보상”의 사이클을 통해 자율 주차 학습을 수행한다.
초기화 & 에피소드 시작
-
Initialize()
-
컴포넌트 캐싱
-
유효 주차 스팟(validSpots) 구성
-
주차된 차량 초기 위치 백업
-
시각화·GUI 초기화
-
-
OnEpisodeBegin()
-
에피소드 상태 리셋 : 에피소드 초기화
-
주차 스팟·차량 태그 복원 : 모든 parkingSpots 태그를 “ParkingSpot”으로 재설정
-
하이라이트 숨기기 : 이전 에피소드의 라인 렌더러 비활성화
-
스폰 위치 결정 : 스폰 가능 위치를 결정하며 실패 시 기본 레벨 로직으로 한 번 더 위치 생성
-
웨이포인트 설정 : 중간지점 설정
-
초기 거리 저장
-
관측(Observations)
1. 차량 상태
-
전진 속도: 에이전트 로컬 좌표계에서의 전방 속도(rb.velocity.z)
-
조향ㆍ가속ㆍ제동 신호: 이전 액션으로부터의 입력 값
2. 목표 위치 정보
- 현재 목표 웨이포인트(입구 또는 주차 공간)까지의 상대 위치 벡터 (방향 + 거리)
- 거리 정규화: 최대 20 m 기준으로 0 ~ 1 사이
3. SphereCast 센서
-
장애물 센서 (generalObstacleMask)
-
좌·우 합쳐서 최대 (raysPerDirection×2 + 1) 개의 구형 캐스트
-
충돌 여부와 충돌 지점까지의 거리(정규화) 관측
-
-
인도 경계 센서 (sidewalkMask)
- 동일한 방식으로 인도까지의 거리 관측
-
센서 동적 길이 계산
- 자동차 크기(carDimensions)를 고려해, 캐스트가 차체를 뚫고 나가지 않도록 캐스트 최대 거리를 동적으로 산정
행동(Actions)
-
연속 액션 3개
-
Steer ([-1, 1]): 좌우 조향
-
Drive ([-1, 1]): 전진(+)·후진(–)
-
Brake ([0, 1]): 제동 세기
-
-
Heuristic 모드(직접 조종)
-
방향키 좌/우 → Steer
-
방향키 상/하 → Drive
-
스페이스 바 → Brake
-
보상과 패널티(Reward & Penalty)
-
웨이포인트 도달 보상
- 에이전트가 다음 웨이포인트(입구 또는 주차 공간)에 진입할 때마다 AddReward(50)를 통해 50점을 부여한다.
-
시간 경과 패널티
- 매 물리 스텝마다 AddReward(-0.001f)로 0.001점을 차감하여 불필요한 대기를 억제한다.
-
거리 기반 잠재 보상
- distanceShapingFactor = 0.1을 적용하여, 이전 스텝 대비 목표까지 거리 감소량에 0.1을 곱한 값을 보상으로 지급한다.
-
충돌·낙하 패널티
- 장애물 충돌 또는 지정 높이 이하 낙하 시 HandleEpisodeEndWithPenalty(-50)로 50점을 감점하고 즉시 에피소드를 종료한다.
-
타임아웃 패널티
- 웨이포인트 제한 시간(WAYPOINT_TIME_LIMIT, 기본 60초)을 초과할 경우 –5점을 부과하고 에피소드를 종료한다.
-
주차 존 체류 보상
- parkingScoreRewardMultiplier = 0.1을 활용하여, 마지막 웨이포인트인 주차 공간 내 체류 동안 매 프레임 주차 정확도 × 0.1 × Δt만큼 보상을 누적한다.
-
최종 주차 성공 보상
- 체류 시간이 2초를 초과하면 AddReward(100 + 50 × dbgScore)를 호출하여 기본 100점과 정확도 계수(50)×정확도 점수를 합산한 최종 보상을 부여한다.
모든 에피소드의 성공·실패 여부는 RecordEpisodeResult()로 기록되어 커리큘럼 학습에 활용한다.
물리 스텝 처리 및 종료 검증
-
FixedUpdate() 처리
-
시간 경과 패널티(–0.001)와 거리 기반 잠재 보상만 처리
-
웨이포인트 도달 시 보상(+50) 부여
-
충돌·낙하·타임아웃 검사 및 패널티만 적용
-
-
Update() 처리
- 주차 존 체류 보상(정확도×0.1×Δt)과 최종 성공 보상(기본100 + 정확도계수50×정확도)만 처리
마지막 웨이포인트(주차 공간) 내 체류 시 AddReward(dbgScore × 0.1 × Δt)로 지속 보상을 누적하고, 체류 시간이 2초를 넘으면 AddReward(100 + 50 × dbgScore)를 통해 최종 보상을 부여하며 에피소드를 종료한다.
🎓 커리큘럼 학습 제도
레벨별 난이도(스폰 영역)에 대한 자세한 내용은 환경 설명을 참조한다.
-
성공률 기반 레벨 업/다운 규칙
에피소드가 종료될 때마다 성공 여부를 기록하고, 최근 N회(curriculumWindowSize)의 성공률을 기준으로 레벨을 동적으로 조정한다.-
RecordEpisodeResult()를 호출하여 에피소드의 성공(true)·실패(false)를 큐에 저장한다.
-
큐 크기가 curriculumWindowSize에 도달하면, 성공 횟수를 전체로 나누어 성공률을 계산한다.
-
성공률 ≥ levelUpThreshold(예: 0.8)이면 currentLevel을 1 증가시키고,
-
성공률 ≤ levelDownThreshold(예: 0.3)이면 currentLevel을 1 감소시킨다.
단, currentLevel은 1 이상 maxLevel 이하로 항상 유지된다.
-
-
커리큘럼 관련 하이퍼파라미터
-
currentLevel: 현재 적용 중인 난이도 레벨
-
maxLevel: 허용 가능한 최대 레벨
-
curriculumWindowSize: 최근 에피소드 성공률을 계산하기 위한 기록 개수
-
levelUpThreshold: 성공률이 이 값 이상일 때 레벨 업 조건
-
levelDownThreshold: 성공률이 이 값 이하일 때 레벨 다운 조건
-
🎓 마무리 (회고 및 느낀 점)
이 프로젝트를 진행하며 가장 크게 느낀 점은, 머릿속으로 그리는 이론과 실제 구현 사이의 거리가 상상 이상으로 멀다는 것이었다. 특히 환경과 에이전트에 현실적인 물리 법칙을 적용하여 자연스러운 움직임을 구현하는 과정은 수많은 시행착오를 요구했다.
처음 야심 차게 설계했던 보상 시스템은 생각처럼 에이전트를 똑똑하게 만들지 못했고, 오히려 의도치 않은 방향으로 학습이 진행되는 결과를 낳기도 했다. '생각만 하는 것'과 '직접 부딪쳐보는 것'이 얼마나 다른지 뼈저리게 느낄 수 있었다. 결국, 중간 목표인 웨이포인트(Waypoint) 아이디어를 도입하고, 지금처럼 여러 종류의 세밀한 보상과 페널티 체계를 갖추게 된 것은 바로 이 어려움들을 해결해나가는 과정에서 얻은 산물이었다.
또한, 한 번 학습을 시작하면 적게는 하루에서 길게는 이틀까지 소요되는 긴 시간은 인내심을 시험하는 또 다른 도전이었다. 더불어 중간고사나 자격증 시험 같은 일정 때문에 짬 나는 시간에만 프로젝트를 진행하다 보니, 완성까지 두 달 가까운 시간이 걸리기도 했다.
하지만 이 모든 어려움을 극복하고 마침내 에이전트가 성공적으로 주차하는 모습을 보았을 때의 성취감은 무엇과도 바꿀 수 없었다. 무엇보다 강화학습의 가장 중요한 두 축인 환경(Environment)과 에이전트(Agent)를 내 손으로 직접 설계하고, 보상 함수를 만들며 밤새 씨름했던 모든 순간이 값진 경험으로 남았다. 이 프로젝트는 나의 공학도 인생에서 이론을 현실로 만드는 과정의 어려움과 즐거움을 동시에 알려준, 가장 소중하고 중요한 경험 중 하나였다고 생각한다.

