🎓 PPO(Proximal Policy Optimization) 알고리즘 개요
2017년, OpenAI는 "Proximal Policy Optimization Algorithms"이라는 논문을 통해, 기존 정책 기반 강화학습의 문제를 해결하고자 한 새로운 접근법을 제시했다.
이 논문에서 제안된 PPO는, 안정성과 성능을 동시에 확보하면서도 구현이 간단한 알고리즘으로 평가받으며, 이후 많은 강화학습 환경에서 사실상 기본값으로 자리 잡게 되었다.
강화학습에서 정책 기반 방법은, 행동을 결정하는 확률 분포인 ‘정책’을 직접 학습한다. 하지만 기존의 정책 경사법은 학습 안정성이 떨어지고, 때로는 정책이 지나치게 크게 변경되어 성능이 악화되는 문제를 자주 겪었다.
이러한 문제를 해결하기 위해 TRPO(Trust Region Policy Optimization)와 같은 안정적 알고리즘이 등장했지만, 이는 계산이 복잡하고 구현이 어려워 실제 적용이 제한적이었다.
PPO는 이 TRPO의 장점을 유지하면서도 단순한 클리핑 방식을 도입하여 안정적인 학습을 가능하게 만들었다. 정책이 너무 급격히 바뀌지 않도록 조정해주는 방식으로, 학습 도중 정책이 튀거나 무너지는 상황을 방지한다.
이처럼 PPO는 기존 정책 기반 강화학습의 불안정성과 구현 복잡성을 동시에 해결하기 위해 탄생한 알고리즘이다. 따라서 PPO를 배우기 전에, 먼저 왜 기존 정책 경사법이 불안정했는지, 그리고 PPO가 어떤 방식으로 그 문제를 해결했는지를 이해하는 것이 중요하다.
🎓 TRPO 알고리즘이란?
강화학습에서 정책 기반(policy-based) 접근은, 환경 내에서 행동을 결정하는 정책(policy) 자체를 학습한다. 그러나 기존의 정책 경사법(Policy Gradient)은 정책이 너무 크게 바뀌는 문제, 즉 학습 도중 성능이 오히려 악화되는 현상을 자주 겪는다. 이러한 불안정을 해결하기 위해 2015년, Schulman 등이 제안한 알고리즘이 바로 TRPO(Trust Region Policy Optimization)이다.
TRPO의 핵심 아이디어는 다음과 같다 : "정책을 바꾸되, 너무 많이 바꾸지 말자."
TRPO는 정책 업데이트 시 변화 폭을 제한하여, 학습 안정성을 높이고 성능 저하를 방지하는 구조를 갖는다. 이를 위해 정책 간의 차이를 측정하는 KL Divergence(쿨백-라이블러 발산)를 사용하여, 기존 정책과 새로운 정책 사이의 '거리'가 일정 수준을 넘지 않도록 제한하면서 업데이트를 수행한다.
이를 통해 기존 정책에서 벗어나지 않는 신뢰 영역(trust region) 안에서만 정책을 개선할 수 있도록 한다. 이러한 방식은 실제로 안정적인 수렴과 높은 성능을 보이며, 다양한 환경에서 효과를 입증했다.
그러나 TRPO는 다음과 같은 단점도 지닌다. 이차 미분 기반 최적화 (Second-order optimization)를 사용하므로 수학적으로 복잡하고 실제 구현이 어렵고 계산 비용이 크다.
이러한 한계를 해결하고자 등장한 알고리즘이 바로 PPO(Proximal Policy Optimization)이다. PPO는 TRPO의 핵심 개념인 “정책 변화의 억제”를 더 단순한 방식으로 구현하면서도, 성능은 거의 유사하거나 더 나은 경우도 많다.
🎓 PPO(Proximal Policy Optimization) 알고리즘 정리
✅ PPO의 핵심 아이디어: 정책 변화 억제
PPO는 현재 정책과 이전 정책이 특정 행동을 얼마나 선호하는지의 차이를 계산하고, 그 차이가 너무 크면 클리핑(clipping)을 통해 제한하는 방식이다.
이때 사용하는 값이 바로 정책 비율(importance sampling ratio)이다.
- : 현재 정책이 상태 에서 행동 를 선택할 확률
- : 이전 정책의 확률
- >1: 행동 확률이 증가함
- <1: 행동 확률이 감소함
이 비율이 1보다 크면 정책이 해당 행동의 확률을 높였다는 의미이고, 1보다 작으면 확률을 낮췄다는 뜻
데이터 재사용을 통한 샘플 효율성 향상 : PPO는 환경에서 데이터를 한 번 수집한 뒤, 이 데이터를 여러 에포크(epoch)에 걸쳐 반복 학습한다. 기존 방식에서는 데이터를 재사용하면 학습이 불안정해졌지만, PPO는 클리핑 기법 덕분에 정책이 안정적으로 유지되므로 높은 샘플 효율성을 달성할 수 있다.
✅ Clipped Surrogate Objective
그리고 이 비율이 너무 커지거나 작아지지 않도록 PPO는 다음과 같은 Clipped Surrogate Loss를 사용한다.
- : 어드밴티지 추정값 (advantage estimate)
- ϵ: 허용 가능한 정책 변화 범위 (예: 0.1 ~ 0.3)
이 손실 함수는 두 항 중 작은 값만을 사용
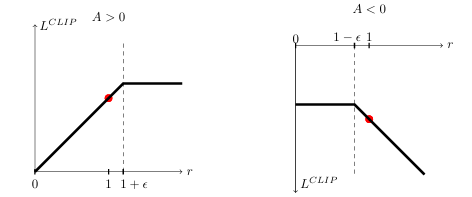
- Advantage가 양수이면 보상을 너무 많이 주지 않도록 제한하고
- → 보상 과다 → 클리핑하여 억제
- Advantage가 음수이면 벌점이 과도하지 않도록 막아줍니다.
- → 벌점 과다 → 클리핑하여 억제
이를 통해 정책이 안정적으로 개선되도록 유도
✅ PPO 손실 함수 구성
PPO의 전체 손실 함수는 다음 세 가지 항목으로 구성된다.:
📌
- : 정책 파라미터 (Actor)
- : 가치 함수 파라미터 (Critic)
- : 각각 값 함수 손실과 엔트로피 항의 가중치
1️⃣ 정책 손실
정책이 너무 급격하게 바뀌지 않도록 억제하는 항목으로, PPO의 핵심
📌
2️⃣ 값 함수 손실
가치 함수가 예측한 값과 실제 보상의 차이를 줄이는 항목으로, 평균제곱오차(MSE)를 사용
📌
- : 상태 에 대한 예측 가치
- : 실제 누적 보상
→ MSE 기반 회귀 손실
3️⃣ 엔트로피 보너스
정책의 무작위성을 유지해서 다양한 행동을 시도하게끔 도와주는 항목
📌
- : 정책의 엔트로피 (무작위성)
→ 탐험을 유지하고 과도한 결정론적 정책을 방지
✅ 적응형 KL 페널티 (Adaptive KL Penalty)
PPO 논문에서는 우리가 주로 사용하는 클리핑(clipping) 방식 외에, 정책 변화를 억제하는 또 다른 접근법을 함께 제안하고 비교해보았다. 바로 적응형 KL 페널티(Adaptive KL Penalty) 방식이다.
이 방법은 정책 업데이트의 크기를 클리핑으로 직접 제한하는 대신, 목적 함수에 KL 발산(KL Divergence) 항을 페널티로 추가한다.
목적 함수는 다음과 같다.
📌
여기서 핵심은 페널티의 강도를 조절하는 계수 를 고정하지 않고 동적으로 조절한다는 점이다.
업데이트 규칙: 매 정책 업데이트 후, 이전 정책과 현재 정책 사이의 실제 KL 발산 값()를 계산한다.
1️⃣ 실제 KL 발산 값 를 계산한다.
2️⃣ 이면, 정책 변화가 더 필요하다고 판단하여 페널티를 줄인다().
3️⃣ 이면, 정책이 너무 많이 변했다고 판단하여 페널티를 늘린다().
이 방식은 정책 업데이트 크기를 목표 범위 안으로 유도하는 합리적인 대안이다. 하지만 논문의 실험 결과에 따르면, 이 적응형 KL 페널티 방식은 클리핑을 사용한 주된 PPO 방식보다 전반적으로 성능이 다소 떨어졌다. 이 때문에 오늘날 PPO라고 하면 일반적으로 클리핑 방식을 의미하게 되었다.
✅ Advantage는 어떻게 계산할까? (GAE)
PPO에서는 보통 GAE(Generalized Advantage Estimation)를 사용하여 어드밴티지를 계산하며, 단기 보상만이 아니라, 미래 보상까지 고려한 좀 더 정교한 평가 방식이다.
📌
📌
- : 할인율 (미래 보상의 중요도)
- : GAE 계수 (편향 vs 분산 절충)
GAE는 다음과 같은 특징을 가진다.
- : 편향은 높지만, 분산은 낮다 (TD 방식에 가까움)
- : 편향은 낮지만, 분산은 높다 (Monte Carlo 방식에 가까움)
이 방식을 사용하면 Advantage를 더 신중하게 계산할 수 있어, 정책 업데이트의 품질이 높아진다.
🎓 마무리
지금까지 PPO(Proximal Policy Optimization) 알고리즘의 핵심 개념과 수학적 구조, 그리고 정책 안정화를 위한 Clipping 기법, 적응형 KL 페널티와 Advantage 계산 방법(GAE)에 대해 정리해보았다.
이제 이러한 이론을 바탕으로, 실제 강화학습 환경에서 PPO가 어떻게 작동하는지를 확인해볼 차례이다.
다음 단계에서는 Unity ML-Agents를 활용한 자율 주차 시뮬레이션 환경을 구성하고, PPO 알고리즘을 적용하여 에이전트가 실제로 장애물을 피해가며, 주차 공간에 정확히 정차할 수 있도록 학습시키는 과정을 실험할 예정이다.
