1️⃣ 배포
✅ 재생성(Recreate)
파드를 삭제하고 다시 생성하는 방식
- 이전 버전의 파드를 모두 삭제 후, 새로운 버전의 파드를 재생성
- 새로운 파드가 생성되기 전까지 서비스에 대한
DownTime발생
apiVersion: apps/v1
kind: Deployment
metadata:
name: recreate-deployment
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
app: recreate-test
template:
metadata:
labels:
app: recreate-test
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
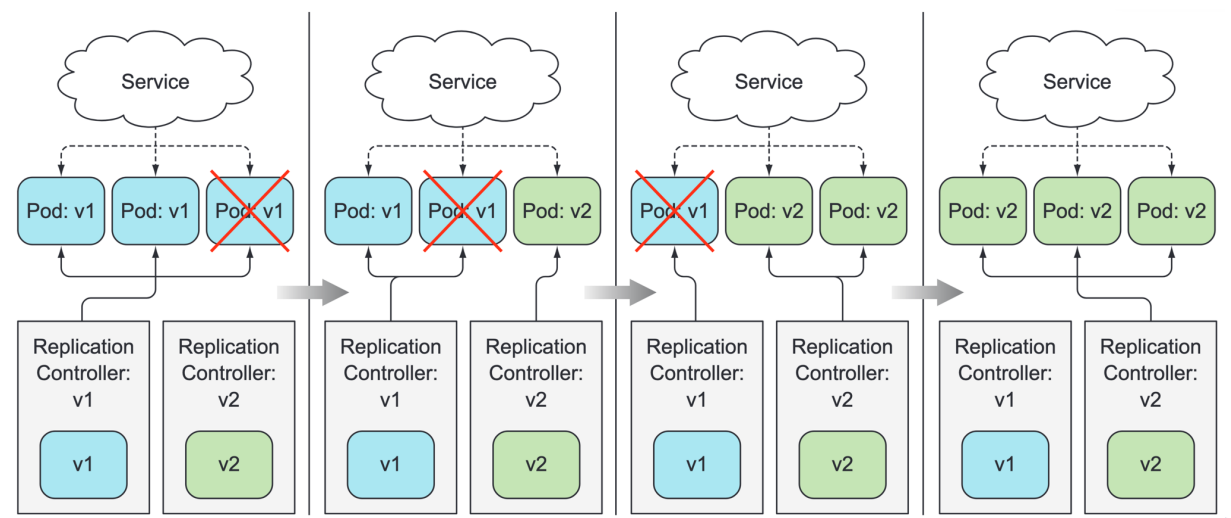
✅ 롤링 업데이트
새로운 파드를 한 번에 생성/삭제 하지 않고, 단계별로 교체하는 방식
-
이전 버전의 복제본 수를 점진적 축소, 새로운 버전의 복제본 수 점진적 증대
-
서비스 다운타임 존재 X
apiVersion: apps/v1
kind: Deployment
metadata:
name: rollingupdate-deployment
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
selector:
matchLabels:
app: rolling
tamplate:
metadata:
labels:
app: rolling
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
- maxUnavailable : 업데이트 중 동시 중단할 수 있는 기존 파드 최대 수
- maxSurge : 업데이트 중 새로 생성할 수 있는 파드 최대 수
kubectl apply -f rollingupdate-depoyment.yaml
kubectl set image deployment/rollingupdate-deployment nginx=nginx:1.20
kubectl rollout status deployment/rollingupdate-deployment2️⃣ 배포 시뮬레이션 : dry-run
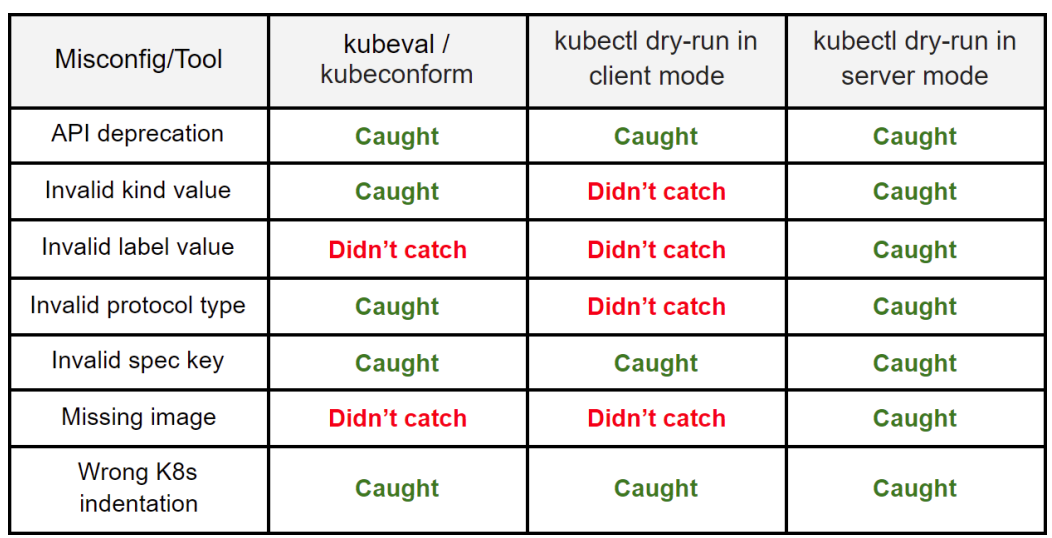
✅dry-run
- 리소스를 생성하지 않고도 파드 생성 요청을 검증할 수 있는 유용한 옵션
- client는 로컬에서만 검증하고, 서버는 실제 API 요청을 보내 유효성 검사를 수행한다.
- 실제 워크로드를 생성하진 않음
- 실제 배포를 수행하기 전에 리소스 정의 파일 내 필드 값의 존재 여부와 유효성 검증
- dry-run 사용 방법
#dry-run-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx
image: nginx
kubectl apply -f dry-run-pod.yaml --dry-run=server -o yaml
kubectl get pods # 파드가 생성되지 않음을 확인3️⃣ 워크로드 롤백
✅Rollback
- 워크로드 리소스(Deployment, ReplicaSet, etc)들을 이전에 안정적으로 동작하던 상태로 되돌리는 기능
- 새로운 버전의 배포에 문제가 발생한 경우 이를 즉시 이전 상태로 복구하여 서비스 가용성 확보
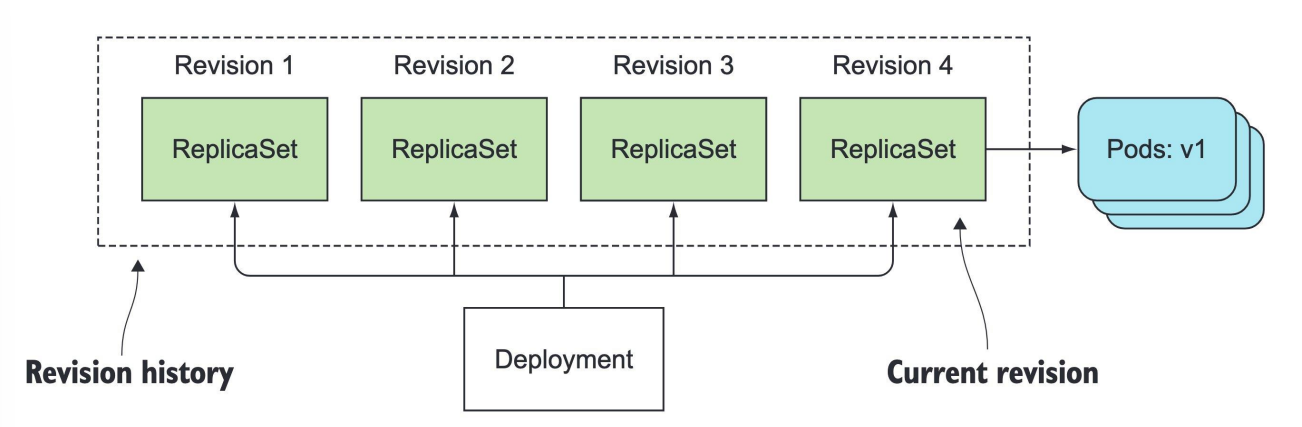
이전 버전의 기록은 누가 어디에 보관하기에 이게 가능할까❓
✅ 롤백의 핵심 원리: ReplicaSet 이력 관리
Kubernetes는 Deployment 리소스를 업데이트할 때마다 자동으로 새로운 ReplicaSet을 생성하고, 기존의 ReplicaSet을 보존한다. 이 ReplicaSet들이 바로 이전 버전의 상태를 담고 있는 기록이다.
- 롤백 예시
kubectl apply -f rollback-deployment.yaml # v1 배포
kubectl set image deployment/rollback-deployment.yaml nginx=nginx:1.25 # v2 배포
# v2 에러 발생
kubectl rollout undo deployment/rollback-deployment
🤔직전 버전이 아니라 2~N 개 이전 배포 버전으로 롤백하고 싶은 경우에는 어떻게❓
-
kubectl rollout undo는 기본적으로 직전 버전으로만 롤백한다. -
하지만 내부적으로 여러 버전의 이력(Revision)을 관리하고 있고, 원하는 경우 특정 Revision 번허로 롤백할 수도 있다.
-
이력 확인
kubectl rollout history deployment/rollback-deployment
deployment.apps/rollback-deployment
REVISION CHANGE-CAUSE
1 Initial deploy
2 Updated to nginx:1.25
3 Updated to nginx:1.26- 특정 Revision으로 롤백
kubectl rollout undo deployment/rollback-deployment --to-revision=1
4️⃣ 워크로드 오토스케일링
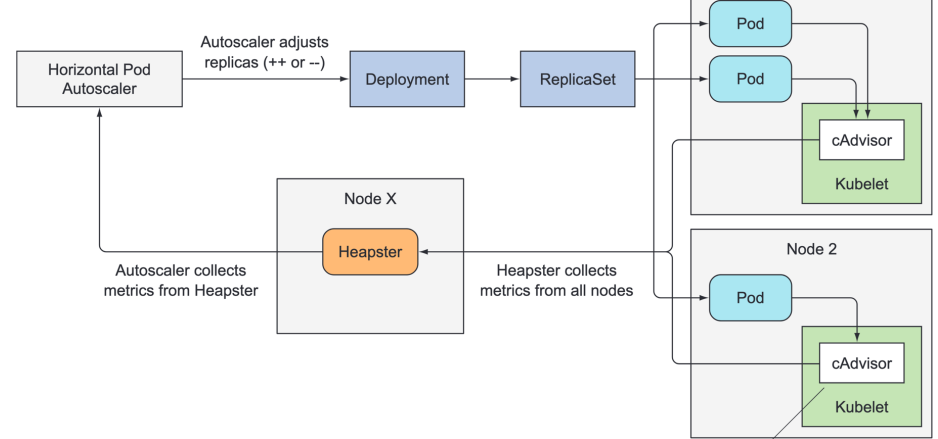
✅ HPA
파드의 CPU/메모리 사용률 또는 커스텀 메트릭에 따라 파드 개수를 조절하는 기능
- 부하가 증가하면 파드를 자동으로 확장 :
Scale-Out - 부하가 감소하면 파드를 자동으로 축소 :
Scale-In
- 운영중인 애플리케이션의 가용성과 효율성 향상
- HPA 예시
apiVersion: apps/v1
kind: Deployment
metadata:
name: hpa-ex
spec:
replicas: 1
selector:
matchLabels:
app: hpa-test
template:
metadata:
labels:
app: hpa-test
spec:
containers:
- name: php-apache
image: k8s.gcr.io/hpa-ex
ports:
- containerPort: 80
resources:
requests: # 최소 필요 리소스 정의
cpu: "200m" # 최소 0.2 코어 보장
limits: # 최대 사용 리소스 정의
cpu: "500m" # 최대 0.5 코어까지만 사용✅ VPA
Pod 단위의 CPU/메모리 리소스 요청을 자동으로 조정해 필요한 만큼의 리소스를 할당
- 리소스 과다 예약 방지 : 클러스터 활용도 향상
- 리소스 부족 방지 : 안정적 성능 보장
- 운영 중인 워크로드에 대한 리소스 요청 자동 튜닝
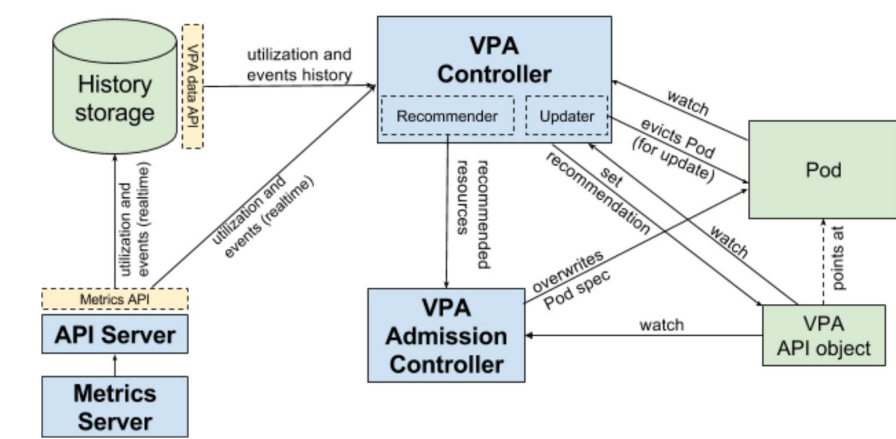
- VPA 예시
apiVersion: apps/v1
kind: Deployment
metadata:
name: vpa-example
spec:
replicas: 1
selector:
matchLabels:
app: vpa-test
template:
metadata:
labels:
app: vpa-test
spec:
containers:
- name: stress
image: vish/stress
resources:
requests: # 파드가 스케줄될 때 최소한으로 필요한 리소스 정의
cpu: "100m"
memory: "100Mi"
args:
- "-cpus"
- "1"
✅HPA vs VPA
| 항목 | HPA (Horizontal Pod Autoscaler) | VPA (Vertical Pod Autoscaler) |
|---|---|---|
| 📌 주요 기능 | Pod 개수를 자동으로 조절 | **Pod의 리소스 요청(requests)**을 자동 조절 |
| 🔄 스케일 방향 | 수평 (replica 수 조절) | 수직 (CPU/Memory 크기 조절) |
| ⚙️ 조절 대상 | replicas 필드 | resources.requests 필드 |
| 📈 기준 지표 | CPU 사용률, 메모리 사용률, custom metrics | 과거 및 실시간 자원 사용량 |
| 🔁 재시작 여부 | Pod 재시작 없이 동작 | Pod 재시작 필요 (스펙이 바뀌므로) |
| 🔀 즉각 반응성 | 실시간 반응 가능 (초 단위) | 데이터 수집 기반으로 반응 (분 단위) |
| 🔐 목적 | 트래픽 증가/감소 대응 | 리소스 낭비 방지, 안정적 성능 확보 |
| 🎛️ 적용 위치 | Deployment, ReplicaSet 등 | Pod 또는 Controller 수준 |
| ⚠️ 주의점 | 너무 잦은 스케일링은 오버헤드 유발 | Pod 재시작이 잦을 수 있음 |
| 🔗 대표 리소스 | HorizontalPodAutoscaler | VerticalPodAutoscaler (addon CRD) |
| 🔧 공존 가능 여부 | ⚠️ 부분적으로 가능 (설정 주의 필요) | ⚠️ cpu/memory requests만 조정 시 공존 가능 |
- HPA는 사용량에 따른 파드 수를 증감함으로써
트래픽에 유동적으로 대응하기 위한 목적으로 사용되고,- VPA는 리소스를 너무 적게/많이 줬을 때 자동 튜닝해
비용을 최적화하는 목적으로 사용된다.
💡
HPA,VPA은 하나의 포스팅으로 다뤄도 될 만큼 중요하고 내용이 많기 때문에 이번 포스팅에서는 간단하게만 짚고 넘어간다.

HARVEY