1️⃣ 쿠버네티스 네트워크 모델 원칙
각 파드는 고유한 IP 주소를 가진다.
-
각 파드별 IP는 파드 내부의 모든 컨테이너가 공유
-
각 파드별 IP는 내부의 모든 컨테이너가
공유한다. -
파드 간 통신은
NAT과정 없이 직접 IP로 통신할 수 있도록 보장해야 한다. -
쿠버네티스
Service Discovery와Network Policy는 파드 IP를 기반으로 동작해야 한다.
쿠버네티스는 각 파드에 고유한 IP를 부여하고, 클러스터 전체에서 해당 IP로 '직접' 통신할 수 있도록 네트워크 플러그인(CNI)이 네트워크 구조를 구현한다.
이러한 구조 덕분에 파드 간에는 NAT 없이 직접 IP 기반 통신이 가능한 것
- 도커에서는 컨테이너 별로 고유 IP(가상)를 가졌다면, 쿠버네티스는 파드 별로 고유 IP를 소유한다.
🔥 클러스터는 Flat Network로 구성된다.
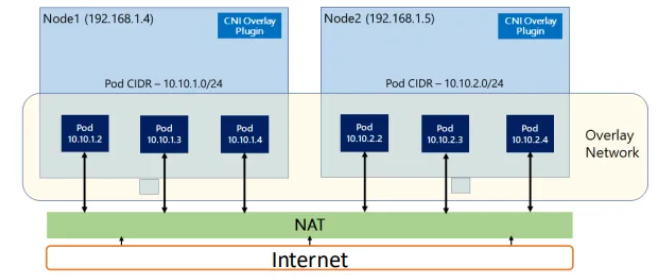
🤔Flat Network란?
- 한 클러스터 내에서는 모든 노드의 파드가 단일 IP 공간에 속함
- 기존 가상화 환경같이 NAT, Bridge, Fowarding 등을 고려하지 않고, IP 기반 직접 통신에 집중
- 라우팅을 통해 파드 간 통신 수행
Overlay Network기술이나BGP Protocol을 통해 논리적으로 가상화된 네트워크를 형성하여 라우팅
단, 파드 외부와 통신할 때는 NAT나 로드 밸런서를 이용하여 통신
클러스터 내 파드 간 통신을 할 때 NAT 과정 없이 통신이 가능하도록 해주는 주체는 컨테이너 네트워크 인터페이스(CNI)가 구현해준다.
🔥 노드는 서로 직접 라우팅이 가능해야 한다.
- 모든 노드가 서로의 파드 CIDR과 IP 주소를 인지하고 직접 라우팅할 수 있는 네트워크 경로 필요
- CNI 플러그인이 각 노드에 파드 CIDR을 할당하고, 라우팅 테이블을 구성하고 관리해줌.
💡리눅스 커널 관점에서 컨테이너 브릿지는 그저 인터페이스다.
즉, 컨테이너는 L3 스위치 방식으로 라우팅하는 것이 아니라 자신의 라우팅 테이블을 이용해 라우팅한다.
🔥서비스 추상화
- 파드는 탄력적으로 생성되고 삭제된다.
- IP 주소가 변경될 수 있다!
이는 애플리케이션이 직접 파드 IP로 접근하는 방식을 불안정하게 한다.
- IP 주소가 변경될 수 있다!
- 따라서 고정된 가상 IP를 통해 접근 경로를 일관성 있게 유지시켜주는 추상화 작업이 필요한데, 이를
서비스라고 한다.- 서비스를 통해 특정 파드가 삭제되거나 재생성되어 IP가 변경되어도 안정적인 네트워크 통신을 유지해준다.
- docker-compose의 경우 특정 서비스의 IP를 통해 통신하지 않고, DNS 방식을 이용해 name으로 통신 가능했다.
- 즉, 쿠버네티스도 이와 같은 작업을 위해
서비스 네임이 필요
2️⃣ 쿠버네티스 IP 할당 구조
🔥 IP-per-POD 모델
쿠버네티스는 각 파드별로 고유 IP를 부여한다고 했다.
- 파드 내 컨테이너들은
pause 컨테이너에 의해 같은 네트워크 네임스페이스를 공유한다. - 파드 내 컨테이너들은
loopback 인터페이스를 통해 내부 통신이 가능하다.
💡파드 IP가 변경될 수 있으므로 파드 내에서 동작하는 애플리케이션은 고정 IP 대신
Service나DNS기반으로 통신하는 것이 좋다.(권장)
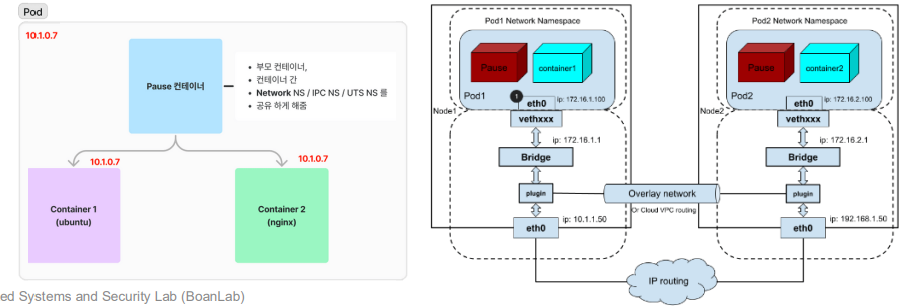
🤔pause 컨테이너가 뭐길래 파드 내 컨테이너들이 네트워크 네임스페이스를 공유할 수 있는걸까❓
✅ Pause 컨테이너
쿠버네티스가 파드를 생성할 때 가장 먼저 실행시키는 컨테이너로, 파드의 인프라 컨테이너라고 한다.
🤔왜 필요할까❓
쿠버네티스의 Pod는 하나 이상의 컨테이너로 구성될 수 있고, 이 컨테이너들은 다음과 같은 리눅스 리소스를 공유하는 형태로 구성된다.
- Network Namespace
- IPC Namespace
- PID Namespace(Option)
이 공유를 가능하게 하려면, 위 리소스들의 호스트(Owner)가 있어야 한다.
이때 이 호스트 역할을 하는 것이 바로 pause 컨테이너다.
어떻게 동작하나❓
1. 파드가 생성될 때 가장 먼더 pause 컨테이너가 생성됨
2. pause 컨테이너는 거의 '아무 일도 하지 않고' 단순히 sleep 상태로 머뭄
3. 이후에 생성되는 모든 애플리케이션 컨테이너들은 pause 컨테이너의 네트워크, IPC, PID 네임스페이스들을 공유하게 됨
즉, 모든 파드 컨테이너들이 pause 컨테이너의 네임스페이스를 붙잡고 거기에서 동작하는 것이다.
✅ Pod CIDR
쿠버네티스는 각 노드마다 Pod CIDR을 할당한다.
- Node CIDR은 클러스터 CIDR 블록을 기준으로
kube-controller-manater가 수행 - Pod CIDR 할당과 파드 IP 할당은
CNI플러그인이 수행 -> 라우팅 테이블 구성 - 쿠버네티스는 기본적으로
B Class대역 사용 - 그리고 각 노드마다
C Class를 할당
즉, 클러스터에 B 클래스 IP 대역을 할당하고 클러스터 내에 존재하는 각 노드에 C 클래스 대역을 할당
- 위 노드들을 다 합치면 하나의 B 클래스 IP 대역이 완성 -> 노드 간 통신이 가능한 이유
📜C 클래스 대역을 할당한다고 해서 2^8 개의 IP를 모두 할당하진 못한다.
-> 쿠버네티스는 보통 마스터 노드에 100개 정도의 워커 노드만 할당 가능하다고 스펙에 정의되어 있음(따라서 C Class의 절반 정도인 약 100개만 할당하면 적당. 그 이상 할당해도 어차피 못 띄움)
- CIDR 정리 : 클러스터한테 B 클래스 대역을 kube-controller-manager 가 할당하고, 노드한테 C 클래스 대역을 CNI가 할당하고 라우팅 테이블도 구현한다.
- 이때 할당되는 B 클래스 IP 대역은 직접 구매한 공인 IP가 아니라 내부 가상 IP임.
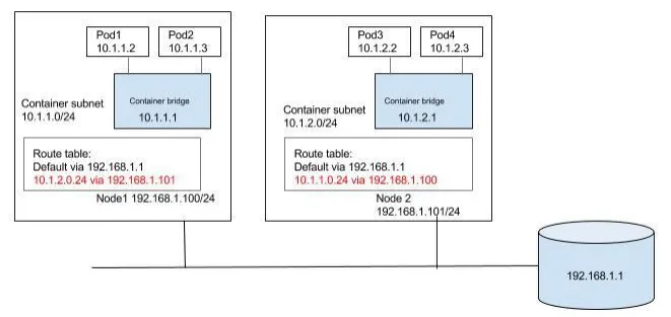
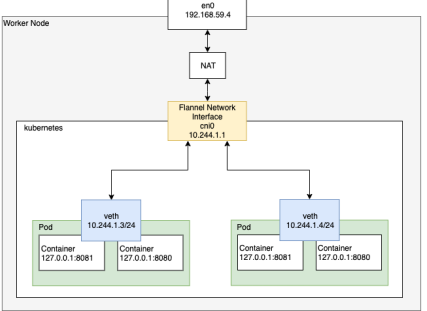
✅ 같은 노드 내 파드 간 통신
- 동일한 노드에 스케줄링 된 파드들은 물리적인 네트워크를 거치지 않고 로컬 네트워크 경로를 사용한다.
- 노드 내부의 리눅스 네트워크 스택과 브릿지 인터페이스를 통해 경로를 처리함
- 출발지 pod -> veth -> bridge -> veth -> 목적지 pod
- 각 파드는 veth(가상 이더넷 인터페이스)를 통해 브릿지 인터페이스에 연결되고, 브릿지 내에서 목적지 파드의 IP를 찾아 직접 전달되는 방식(L3를 거치진 않지만 내부적으로 L2 수준의 포워딩을 수행해주는 것)
- 각 파드는 veth(가상 이더넷 인터페이스)를 통해 브릿지 인터페이스에 연결되고, 브릿지 내에서 목적지 파드의 IP를 찾아 직접 전달되는 방식(L3를 거치진 않지만 내부적으로 L2 수준의 포워딩을 수행해주는 것)
🚨하지만,
요즘 나오는 CNI들은 위 방식이 아닌 pod -> veth -> veth -> pod 방식으로 성능 최적화 되어 나온다.
- 브릿지 인터페이스를 거치지 않음
- 인바운드 큐에서 아웃바운드 큐로 바로 라우팅 됨
📜이는 추후 CNI 포스팅에서 다룬다.
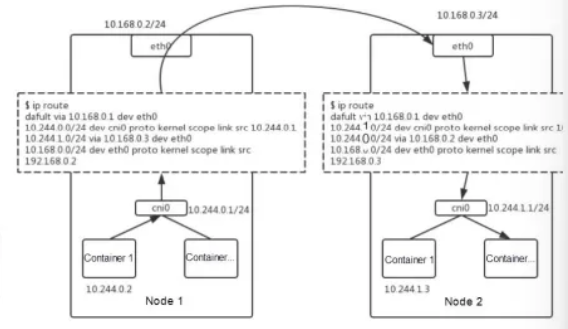
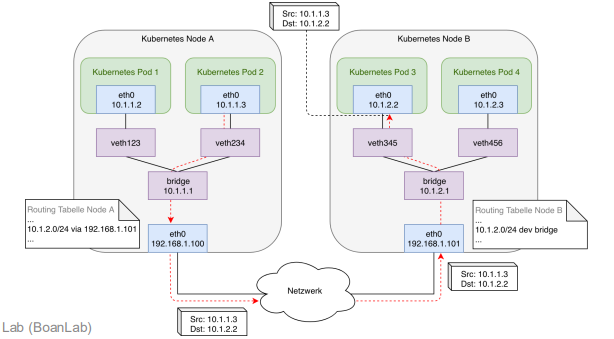
✅ 다른 노드 내 파드 간 통신
- 다른 노드의 파드 간 통신은 물리적 네트워크 인프라를 거쳐 오버레이 네트워크로 캡슐화된다.
- 노드의 CNI 플러그인이 라우팅 규칙을 구성하여 패킷이 목적지 노드로 전달됨
- pod -> veth -> cni0 브릿지 -> 캡슐화(VXLAN/IP-in-IP) -> 물리 네트워크 -> 대상 노드 -> 디캡슐화 -> cni0 브릿지 -> veth -> 대상 파드
특징
1. 같은 노드 내 파드 간 통신과 달리 물리 네트워크를 거쳐야 함
2. 터널(캡슐화)이 필요 -> 오버레이 네트워크는 다른 네트워크로 못 감
- 각 노드의 IP 주소가 담긴 패킷을 터널을 통해 대상 노드에 전달
따라서 만약 가용성 보다 속도(성능)가 중요한 상황이라면, 파드가 동일 노드에 존재하도록 적절히 배치해야 한다.
- 이렇게 파드들의 배치를 고려하는 과정을
Replacement라고 하고, 이는Deployment와는 다르다.
- EX) 물리 네트워크 통신을 40G 사양으로 설정했다면,
- 외부 노드 간 통신 : 40G
- 내부 노드 간 통신 : 200G(매우 빠름)
3️⃣ 서비스
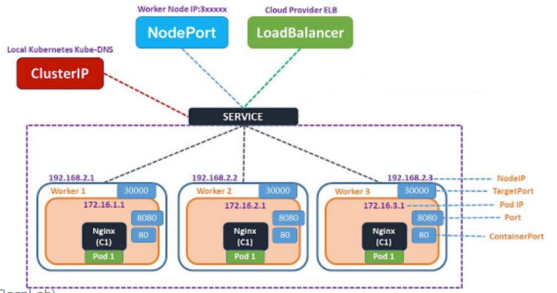
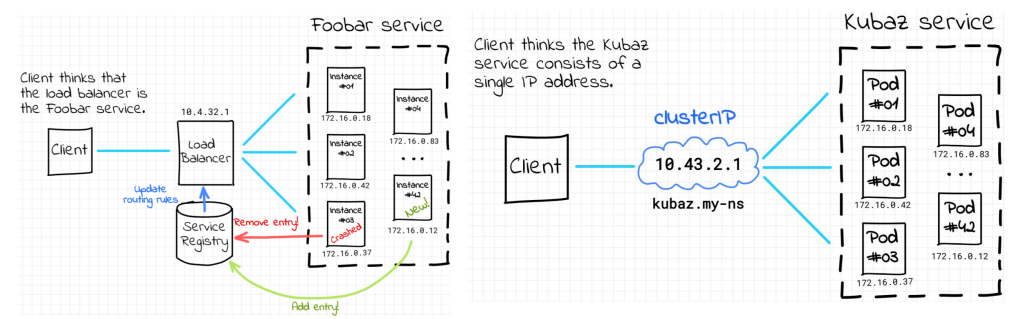
쿠버네티스에서 여러 개의 파드를 하나의 논리적 엔드포인트로 묶어주는 리소스
즉, 변동성 있는 파드 집합에 대해 고정된 접근 지점을 제공하는 역할
- 여러 노드, 파드들을 묶어 지칭하는 이름인
Label을 기준으로 파드들을 선택해 하나로 묶는 '추상화된 접근 지점'
- 특정 label을 갖는 replica, pod들을 묶고 그 집합에 대해 고정된 IP와 DNS 이름을 부여
- 도메인 네임 = 서비스 네임
- IP는 가상의 IP로 이해
가상 네트워킹의 끝판왕 = 서비스
🤔서비스는 왜 필요할까❓
- 파드 IP를 특정 서비스의 엔드포인트로 설정했는데, 이 파드가 사라졌을 때 대응 필요
- 쿠버네티스 자체적으로 서버 상태와 목록을 관리하는 리버스 프록시 리소스를 지원하기 위함
서비스를 얘기할 때는 파드를 파드라고 하지 않고, Endpoint라고 부른다.
🔥 특징
1. 파드 수에 관계 없이 가용한 파드로 로드밸런싱하여 트래픽 분산
2. 고정된 서비스 IP로 들어온 요청은 kube-proxy에 의해 실제 IP로 전달
3. 다른 파드들이 서비스명을 통해 쉽게 접근할 수 있도록 서비스 디스커버리 기능 지원
☑️ Kube-Proxy의 역할과 동작 방식
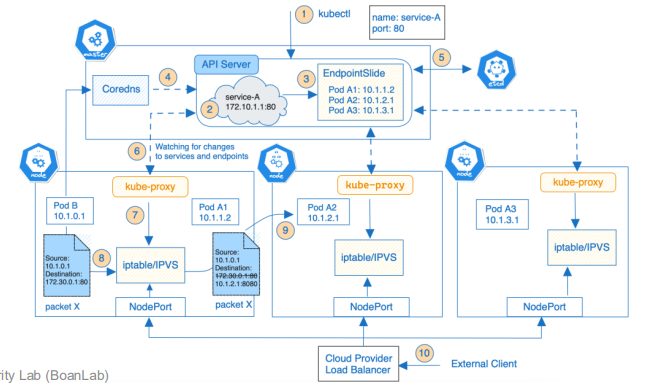
- 클러스터 내 서비스의 가상 IP로 들어온 트래픽을 실제 파드 IP로 라우팅
- 서비스 및 엔드포인트의 변경 사항을 감지하고 iptables, IPVS 규칙을 자동으로 생성, 관리
kube-proxy기술이 예전에는 많이 사용되고 중요했지만, 현재에는 그렇게 많이 사용되지는 않는다.- 파드에서 나온 패킷들은 iptables나 IPVS가 catch
- 여기서 가상 IP로 가는 패킷은 어떤 고정된 IP로 보내라는 규약을 미리 설정해놓고 사용
✅ 서비스 종류
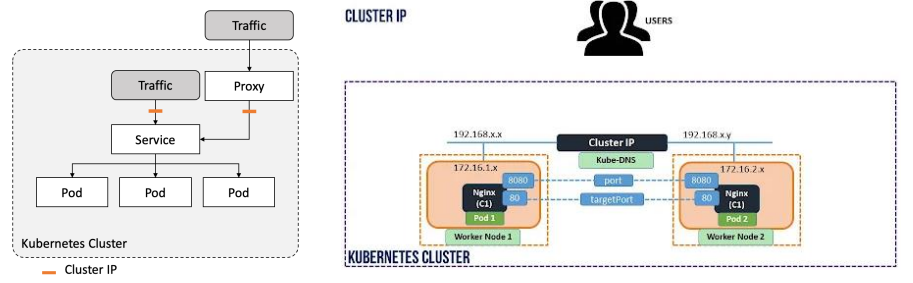
1. ClusetIP
- 클러스터 내부 통신을 위한 기본 서비스 타입으로, type을 명시하지 않을 경우 자동으로 설정된다.
- 내부 파드들은 자동 생성된 클러스터 내부 IP 주소 및 서비스 명 기반 DNS를 통해 접근 가능
- [ServiceName].[Namespace].svc.cluster.local 형태의 주소로 생성 → FQDN(Fully Qualifed Domain Name)
- 외부에서 직접 접근을 불가능하며, 내부 시스템 간 통신에 주로 사용
💡 세 개의 서비스가 있지만, 그 중
ClusterIP를 가장 많이 사용한다.
- 서비스의 이름을 이용해 통신한다 → ClusterIP 서비스를 사용하는 것
- naver.com, google.com → www.naver.com , www.google.com
이렇게 전체 네임을 말할 때는 FQDN 이라고 함.
즉, 클러스터 IP를 사용하지만, 그 IP를 알 필요는 없고, FQDN을 이용한다. → 내부 통신에만 사용되고, kube-proxy가 이 일을 수행
CoreDNS(kubeDNS) 라는 장치가 내부적으로 IP → name 으로 변환해주는 장치
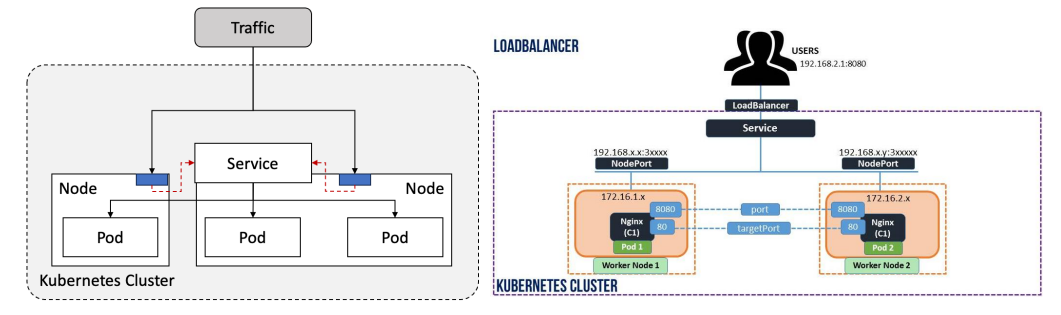
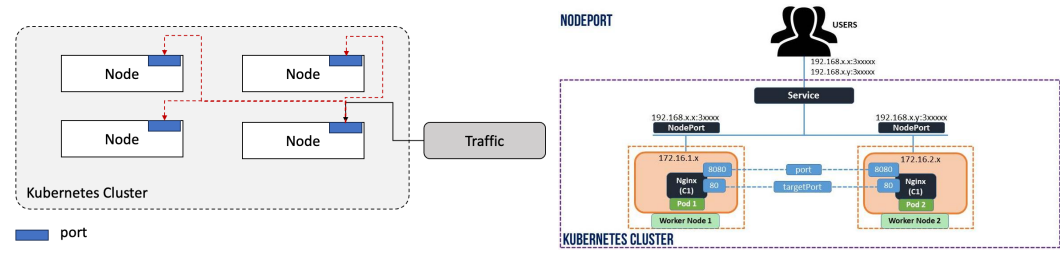
2. NoderPort
외부와 통신할 때 사용되는 서비스
- ClusterIP 기반으로 동작하며, 각 노드의 고정된 포트를 통해 외부에서 직접 접근 가능
- [NodeIP]:[NodePort] 형식으로 클러스터 내 파드에 직접 접근
- NodePort를 통해 유입된 트래픽은 kube-proxy에 의해 대상 파드로 라우팅됨
- 고정 포트 범위 제한과 노드에 직접 포트가 노출되는 보안 이슈 존재
- 이를 완화하기 위해 로드 밸런서 등과 같이 사용됨
- 노드의 IP, Port 를 클러스터의 IP, Port 로 매핑
- 클러스터는 내부 Pod의 IP,Port 로 매핑
외부 클라이언트 : 실제 물리 네트워크에 물려있는 클라이언트가 될 수 있음
3. LoadBalancer
NodePort를 기반으로 동작, 클러스터 외부에 로드밸런서 생성 및 Public IP와 NodePort를 연결
- CSP의 로드 밸런서, MetaILB 등의 자체 구축 LB와 통합되며, 객체 생성 시 Public IP가 자동 할당
외부 접근 클라이언트 → NodePort 로 변환 → 클러스터 IP → ..
- 로드 밸런서는 public IP와 매핑이 되어야 함
- 쿠버네티스에서 로드 밸런서를 사용할 때는
- AWS, AZURE 등이 제공하는 로드 밸런서를 연동 하거나
- MetaILB 등의 자체 구축 LB 와 통합
- on-premise 방식이 아닌 경우 대부분 AWS 와 같은 외부 서비스와 연동함
- 왜? 로드 밸런서는 IP 를 필요로 하고, IP 대역이 필요함.