
현재 SPOT에는 에러 모니터링 도구인 Sentry가 적용되어 있다. Sentry의 도입 배경과 얻은 이점에 대해 설명 하고자 한다.
Sentry
도입 배경
본격적인 안드로이드와 연동이 시작 된 이후, 개발 과정에서 미쳐 생각하지 못한 서버 에러가 종종 발생 했다. Slack에서 서버팀을 언급하는 알림이 뜨면 나도 모르게 긴장했던 것 같다. 제발 내 담당 파트가 아니길 빌었다.

에러 로그를 확인하기 위해서는 배포된 서버에 접속 하여 실행되고 있는 Docker 컨테이너의 로그를 확인해야 했다. 하지만 배포된 서버에 접근할 수 있는 권한은 나에게만 있었다. 즉, 내 담당 파트가 아니라도 에러 로그 확인을 위해서 번거로운 과정을 반복해야했다. 로그 확인 과정을 정리하면 다음과 같다.
배포된 서버에 SSH 접속 → 실행중인 Docker Container 로그 확인 → 에러 발생한 부분 파악 → 로그 확인
위 과정은 상당히 번거로웠다. 에러 처리를 위한 시간이 상당히 많이 소요됐다. 하나의 에러를 파악하는 데만도 20분 이상 걸렸으며, 다른 팀원이 담당하는 기능에서 발생한 에러라면 더 많은 시간이 필요했다. 배포된 서버에 계속 직접적으로 접근 하는 과정도 부담스러웠다.
만일 여러개의 에러를 확인 하는 경우에는 해당하는 에러 로그를 찾기 위해 모든 로그를 한 줄 씩 읽어야 했다. 나는 추가적으로 요청 받은 API도 개발해야했지만 에러 로그 확인으로 인해 내 개발 일정에 큰 차질이 생기곤 했다.
이러한 문제를 해결하기 위해, 에러 모니터링 도구의 도입을 제안했다. 팀원과 협의를 통해 Sentry의 도입을 결정했다.
적용
Sentry를 통한 에러 모니터링은 Prod 환경에서만 진행 하도록 결정했다. 로컬 환경에서는 Sentry가 작동하지 않도록 아래와 같이 설정했다.
@Configuration
@Profile("prod")
@Slf4j
public class SentryConfig {
@Value("${sentry.dsn}")
private String sentryDsn;
@Value("${sentry.environment}")
private String environment;
@PostConstruct
public void init() {
Sentry.init(options -> {
options.setDsn(sentryDsn);
options.setEnvironment(environment);
});
}
}민감한 정보는 application.yml 파일을 통해 관리했다.
이점
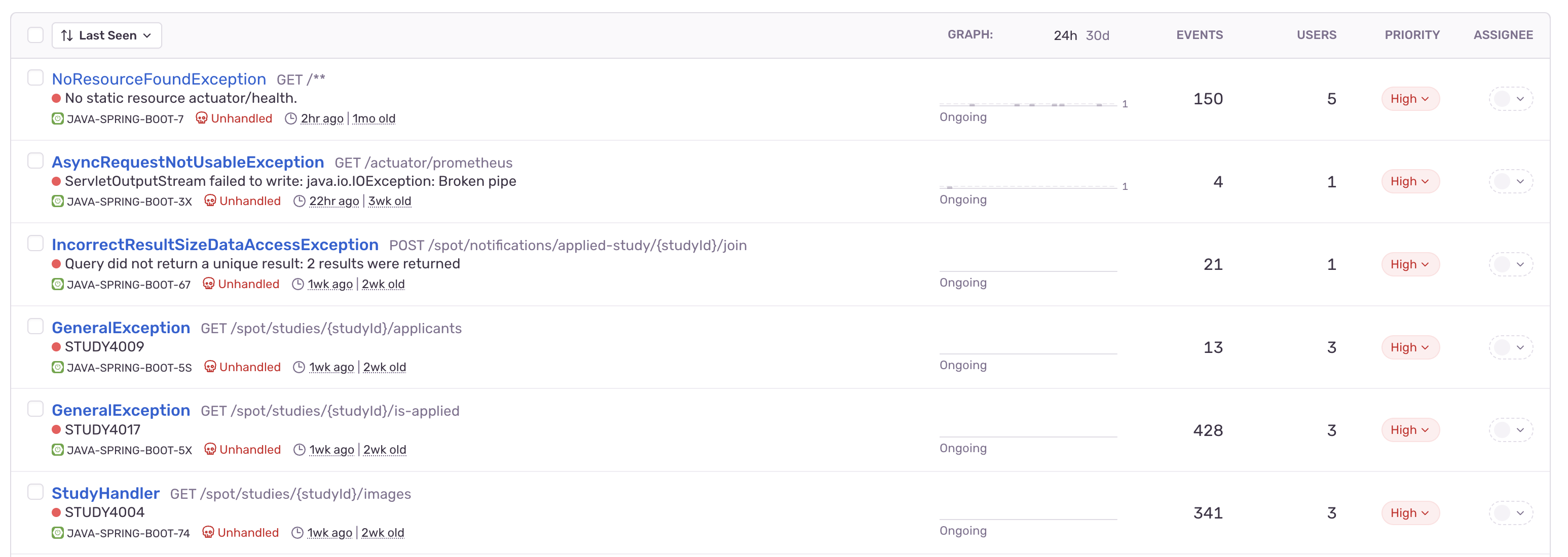
Sentry는 에러 발생 시 자동으로 이슈를 생성해주며, 발생한 에러 횟수를 집계해 한눈에 확인할 수 있었다.
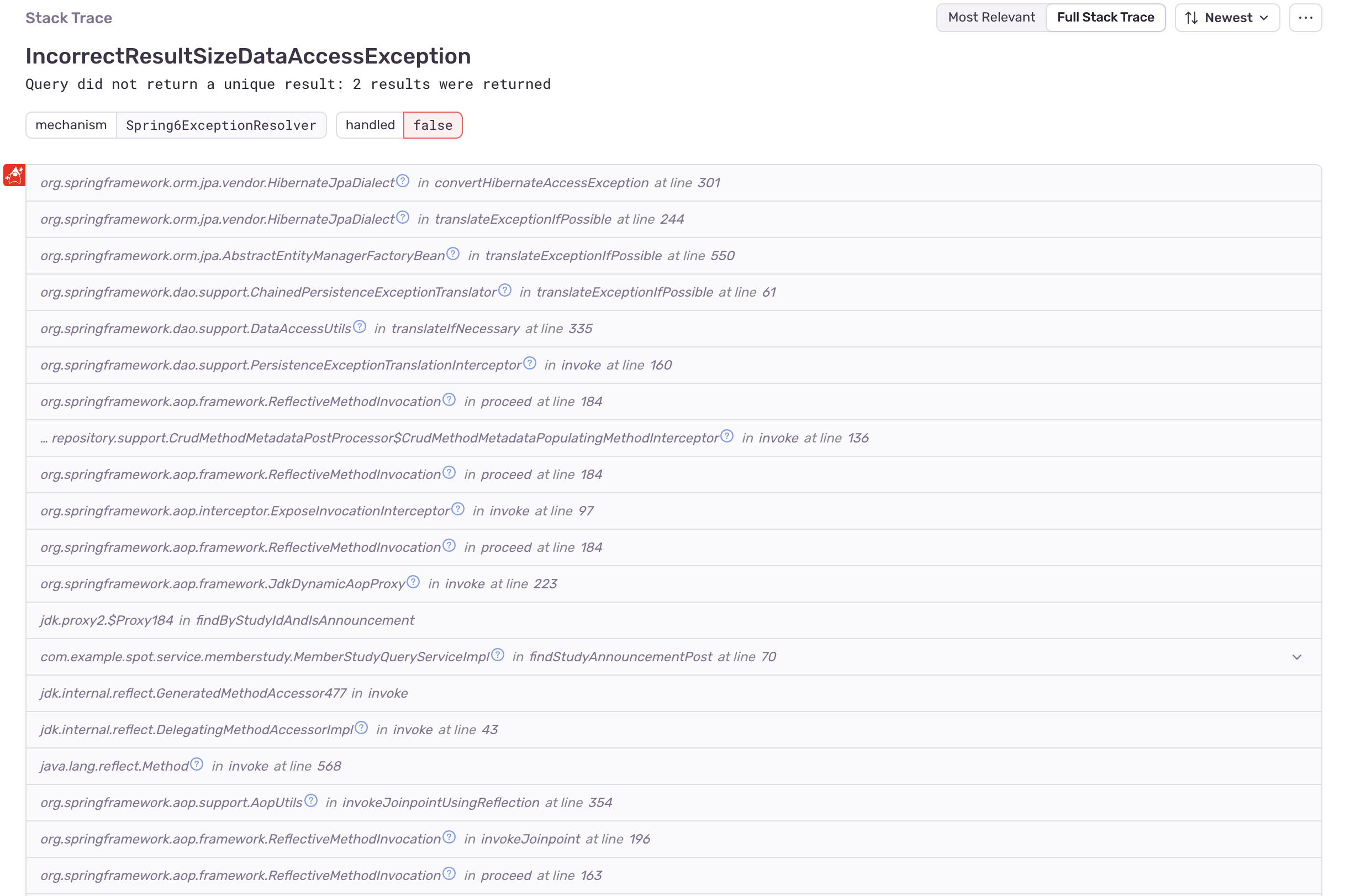

Sentry는 로그를 수집하여 시각화하여 제공한다. 에러 로그의 시각화, 스택 트레이스 제공 등으로 에러의 원인을 빠르게 파악할 수 있었다.
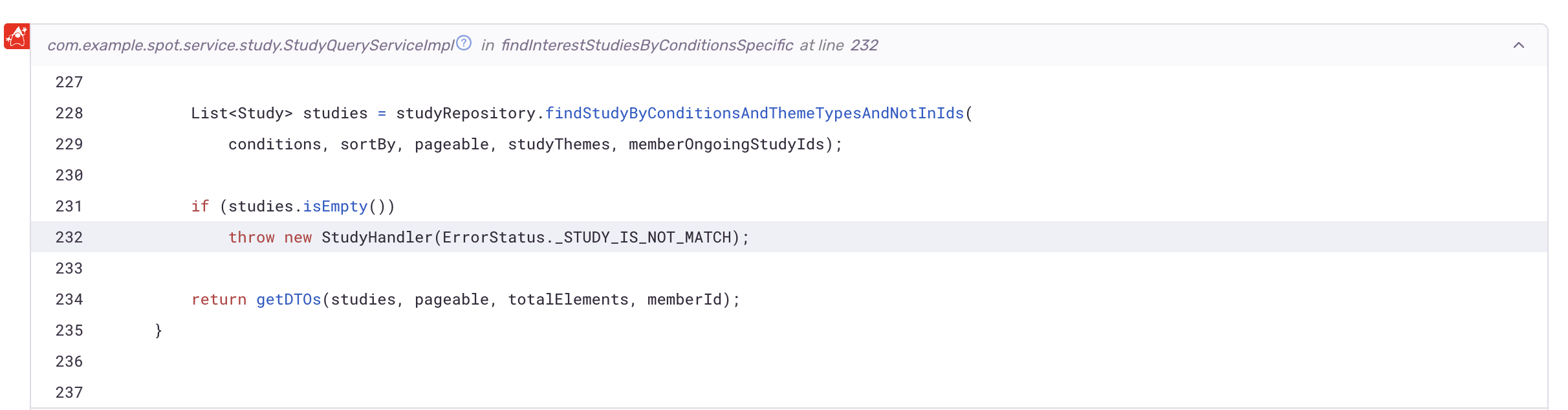
또한, 코드 어느 부분에서 해당 에러가 발생 했는지 파악할 수 있다.
해당 부분은 API 호출 과정에서 잘못된 값을 입력한 경우다. 하지만 안드로이드 파트에게 보다 더 빠르고 정확한 처리 및 정보를 제공하기 위해 해당 에러들도 모니터링 했다.
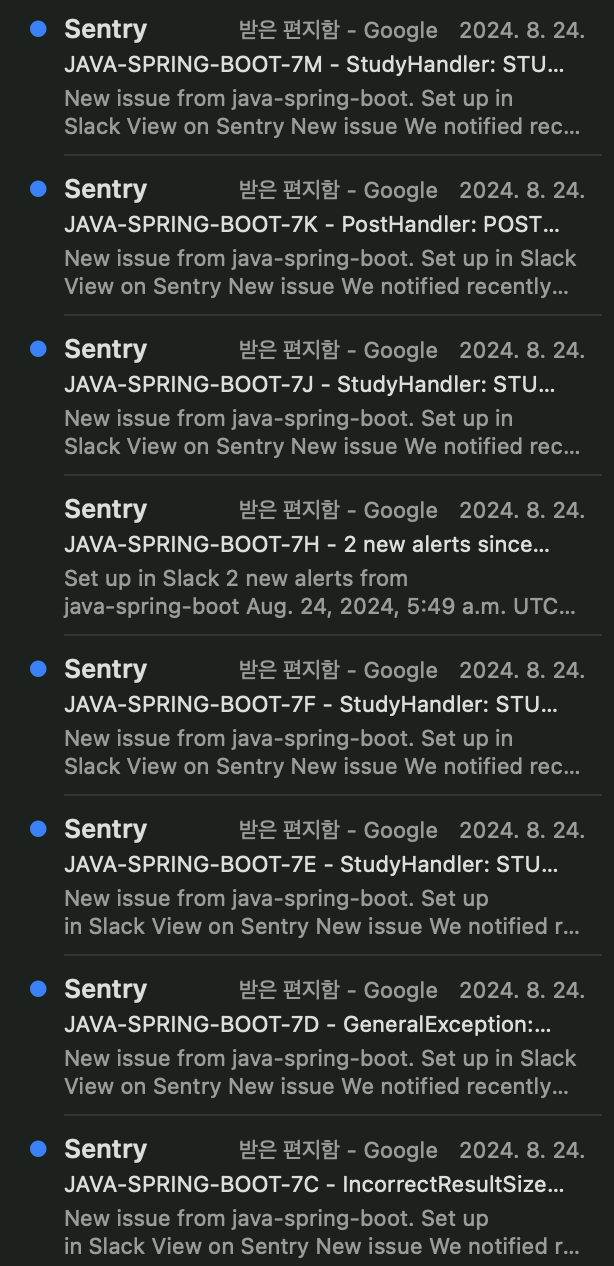
에러 발생 시, 메일을 통해 알림을 받을 수 있어 즉각적인 처리가 가능했다. 하지만, 무료 요금제를 사용 했기 때문에 Slack에 연동하여 에러 발생 시 메시지를 받는 기능이나, 팀원을 해당 프로젝트에 초대 하는 것은 제한됐다.
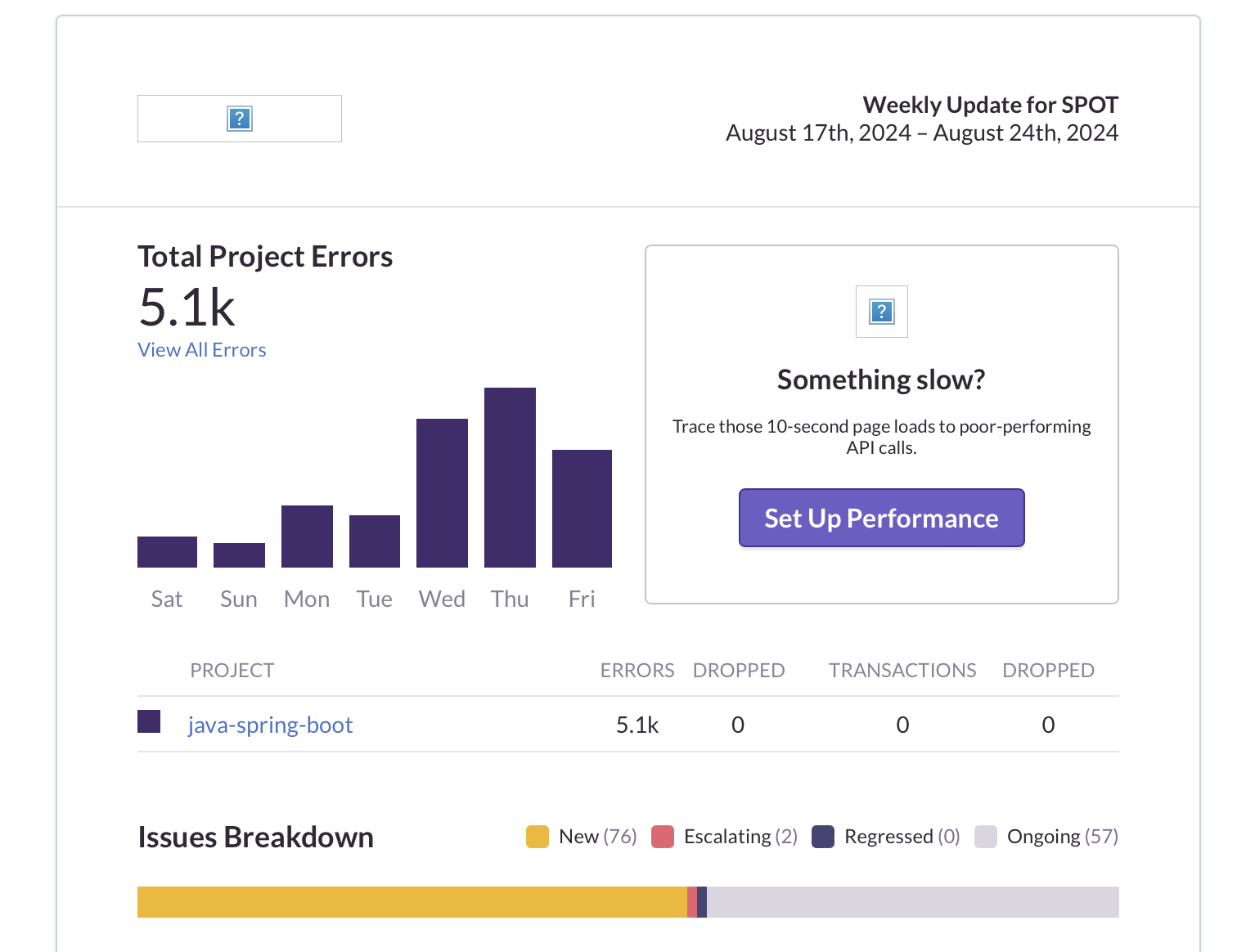
주 단위로 Report도 메일로 제공한다.
여전히 똑같이 모든 에러 로그에 대해 접근 하기 위해서는 나를 거쳐야 하지만 직접 배포된 서버에 접속하여 로그를 찾아야 하는 번거로움은 사라졌다. 단지 발생한 에러에 대한 정보를 제공해주면 됐다.
이로 인해 에러 처리에 소요되는 시간이 절반 이상 감소했으며, 서버 개발자들의 생산성도 크게 향상되었다. 더 이상 배포된 서버에 직접 접속해 로그를 확인할 필요가 없어 불필요한 서버 접근이 줄어들었고, 에러 파악에 소요되는 시간도 10분 이내로 크게 단축되었다.
추후 계획
향후 시스템 상태를 모니터링하기 위해 Prometheus와 Grafana를 도입할 계획이다. 프로젝트 초기, 서버의 메모리 사용률이 100%를 초과해 서버가 다운되는 일이 자주 발생했다. 그러나 며칠간 서버가 다운된 사실조차 파악하지 못했던 경험이 있다.
현재는 스왑 메모리를 사용해 성능은 다소 떨어졌지만 안정적으로 운영되고 있다.
앞으로는 시스템의 안정적인 운영이 매우 중요하므로, 모니터링 도구를 도입해 시스템 상태도 함께 모니터링하고자 한다.
