
CH4
목차
1. 지역 특징 검출 기초
2. 이동/회전/스케일에 불변한 특징점
3. 특징 기술자의 조건 & 관심점을 위한 기술자
4. 주성분 분석 & 얼굴 인식 에
Preview
- 지난주에 배운 내용
- 가장 기본적인 특징인 '에지' 추출
- 이번주에 배울 내용 : '지역 특징' 추출 및 기술(묘사)
- 대응점 찾기
- 같은 장면을 다른 시점에서 찍은 두 영상에서 대응하는 점의 쌍을 찾는 문제
- 파노라마, 물체 인식/추적, 스테레오 등 컴퓨터 비전의 중요한 문제 해결에 사용
- 세 단계로 해결 : 검출/추출 기술(묘사) 매칭

- 대응점 찾기
1
1. 지역 특징 검출 기초
1.1) 특징 검출의 역사 : 지역 특징의 대두
- 무엇을 특징점 으로 쓸 것인가?
- 에지?
- 에지 강도와 방향 정보만 가지고, 다음 프레임에 새로운 물체가 찍혔을때, 이전 프레임과 동일한지 매칭하기 어려움
- 에지?
- 다른 곳과 두드러지게 달라 풍부한 정보 추출 가능한 곳
- 에지 토막에서 곡률이 큰 지점을 코너 ( 특징점 또는 관심점 ) 로 검출
- 코너 검출, dominant point 검출 등의 주제로 80년대 왕성한 연구
- 90년대 소강 국면, 2000년대 사라짐
- 더 좋은 대안이 떠올랐기 때문
- 지역 특징 이라는 새로운 물줄기
- 이미지 또는 영상에서 유용한 정보를 추출하기 위해 사용되는 특정한 위치 또는 지역을 나타내는 패턴이나 특징을 의미
- 명암 영상에서 '직접' 검출
- 의식 전환 : 코너의 물리적 의미 반복성(영상 매칭에서 중요) 강조
- 물리적으로 코너를 해석하는것이 아닌, 의미적으로 코너를 판단
- 에지 토막에서 곡률이 큰 지점을 코너 ( 특징점 또는 관심점 ) 로 검출
1.2) 지역 특징의 성질
- 지역 특징
- <위치, 스케일, 방향, 특징 벡터> = 로 표현
- 검출 단계 : 위치와 스케일 알아냄
- 기술 단계 : 방향과 특징 벡터 알아냄
- 지역 특징이 만족해야 할 특성
- 반복성
- 분별력
- 지역성
- 정확성(위치)
- 계산 효율
- 적당한 양 파라미터 조정
- 이들 특성은 trade-off 관계
- 정확도에만 치중해서 한 프레임을 보는데 1초가 걸린다면 30fps 처리 환경에서는 계산 효율이 떨어지게 된다.
- 응용에 따라 적절한 특징을 선택해야함.
- <위치, 스케일, 방향, 특징 벡터> = 로 표현
1.3) 지역 특징 검출 원리
- 원리
- 인지 실험
대응점을 찾기가 쉬운(좋은) 점은? 사람에게 쉬운 곳이 컴퓨터에게도 쉽다. - 좋은 정도로 어떻게 "수량화" 할까?
여러 방향으로 밝기 변화가 나타나는 곳 일수록 높은 점수
- 인지 실험
이동과 회전에 불변한 특징점 검출 알고리즘 : 모라벡, 해리스코너
1.4) 이동과 회전에 불변한 특징점 검출 알고리즘 : 모라벡 알고리즘
- 인지 실험에 주목한 모라벡 [Moravec80]
- 이미지에서 특정 위치와 강도 변화를 분석하여 특징점을 검출하는 것이 아닌, 강도 변화가 큰 모서리를 감지하는 알고리즘
- 이 알고리즘은 픽셀 값의 차이를 기반으로 한 간단한 윈도우 슬리이딩 방식을 사용하여 이미지에서 모서리를 검출한다.
- 제곱차의 합으로 밝기 변화 측정
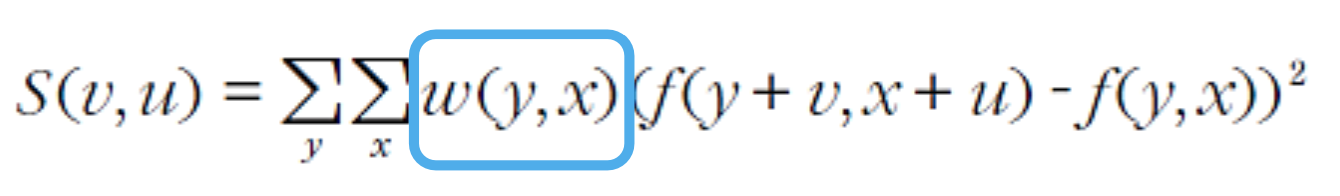
- 예제 4-1)
- 위, 아래, 왼, 오 방향으로 전부 1로 된 3 by 3 마스크를 씌워 모라벡 알고리즘 진행하여, b가 주변 명암값과 얼마만큼 차이가 나는지를 계산.
- 제곱차는 이동 전과 이동 후의 픽셀값의 차이를 제곱한 값으로, S(0,1)은 다음과 같이 계산
- S(.) 맵을 관찰해보면,
- a와 같은 코너에서는 모든 방향으로 변화가 심함
- b와 같은 에지에서는 에지 방향으로 변화 적지만, 에지의 수직 방향으로 변화 심함
- c와 같은 곳은 모든 방향으로 변화 적음
- 즉, a에 높은 값, c는 아주 낮은 값, b는 그 사이의 값 을 부여하는 함수를 만들면 된다.

- 모라벡 함수
- 특징 가능성 값 C
- 그림 4-3에서 점 a에 대한 (최솟값)C 값은 2, 점 b와 c에 대한 C (최솟값) 값은 0
- 변화가 없는 c 보다 한방향 변화가 있는 b 가 낫고, 한방향 변화가 있는 b보다 여러방향 변화가 있는 a가 낫다.
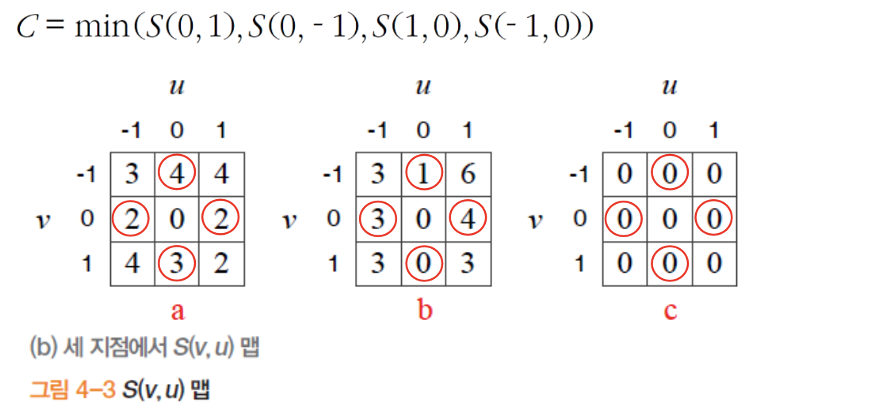
- 한계
- 한 화소만큼 이동하여 '네 방향'만 봄
- '잡음'에 대한 대처 방안 없음
- 특징 가능성 값 C
1.5) 이동과 회전에 불변한 특징점 검출 알고리즘 : 해리스 코너: '1차 미분' 이용
-
해리스의 접근
- 이미지의 픽셀 강도 변화에 대한 주변 픽셀의 변화도를 측정하여 관심 특징점을 감지하는 알고리즘
- 이 알고리즘은 이미지에서 화전, 크기 조정, 이동에도 상대적으로 일관된 특징점을 검출할 수 있다.
- "가중치" 제곱차의 합 을 이용한 잡음 대처 (3x3 이 모두 1인 마스크가 아닌 가우시안 마스크 사용!!!!!!!!)
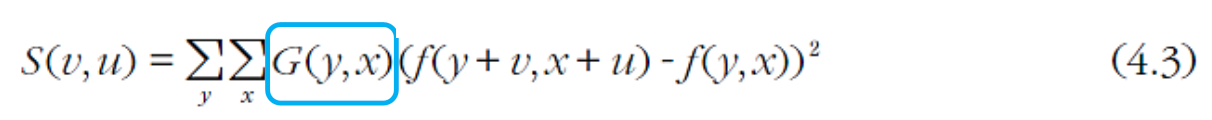
- 모든 방향을 고려한 등방성 을 만족하기 위하여 "1차 미분" 도입
- 테일러 확장을 대입하면
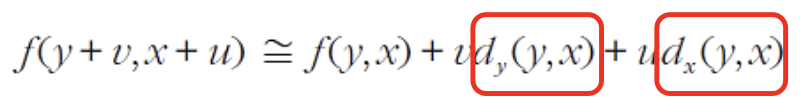
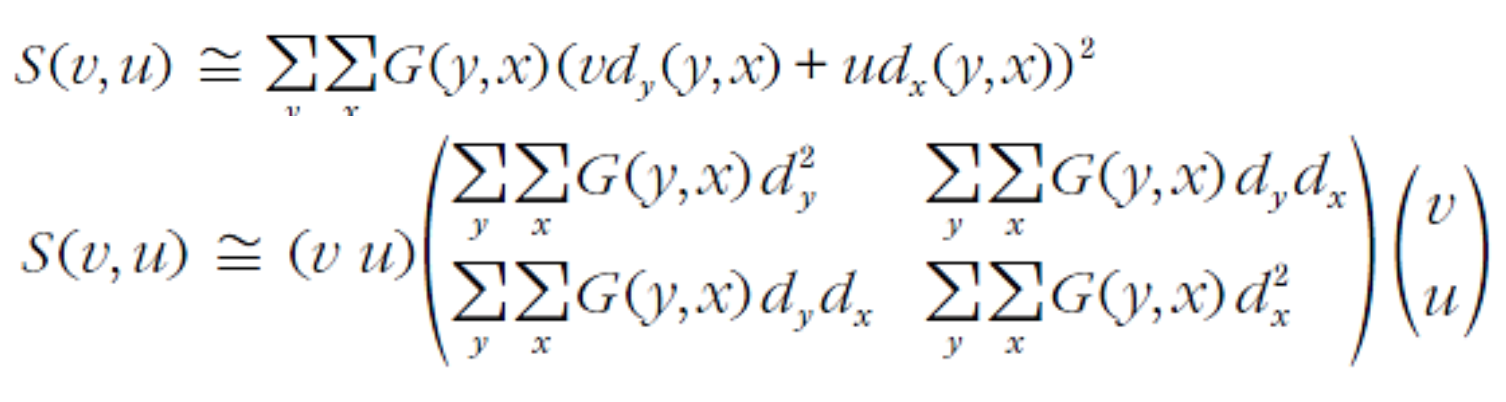
-
2차 모멘트 행렬 A
- 어떤 점의 행렬 즉, 2차 모멘트 행렬 A 를 구할 수 있다.

- 어떤 점의 행렬 즉, 2차 모멘트 행렬 A 를 구할 수 있다.
2차 모멘트 행렬의 고유값 분석
- c와 같이 두 개의 고유값 모두 0이거나 0에 가까우면 변화가 거의 없는곳
- b와 같이 고유값 하나는 크고 다른 하나는 작으면 한 방향으로만 변화가 있는 에지
- a와 같이 고유값 두 개가 모두 크면 여러 방향으로 변화가 있는 지점. 특징점으로 적합!
2차 모멘트 행렬의 고유값 분석
- 아래 식은 고유값이 모두 클 때만 크므로, 특징점일 가능성을 측정 하는데 사용
- 고유값 2개를 통해 C 값 추출 하여 특징점의 가능성이 높은 점을 찾을 수 있다.
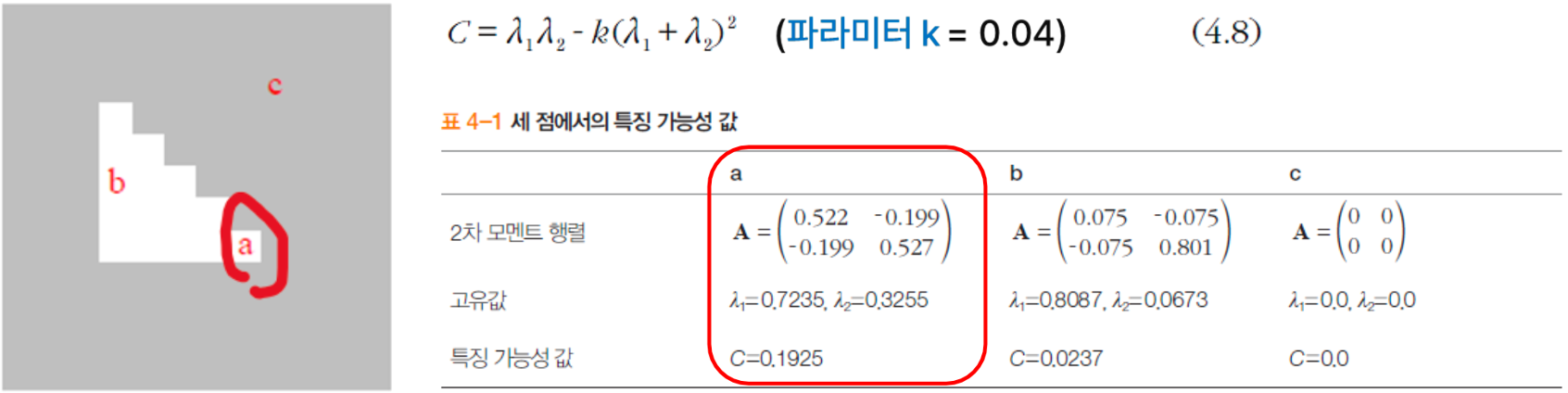
위치 찾기 문제 대두
- 큰 C 값을 가진 큰 점들이 밀집되어 나타나므로 대표점 선택 필요(like 분기점 선택)
'2차 미분'을 이용한 해리스 코너도 가능
코너라는 용어가 적절한가?
- 코너 특징점 또는 관심점
- 예를 들어, 사슴의 경계 부분 외에도 명암 변화가 심한 '사슴의 눈' 등도 특징점으로 선택

1.6) 위치 찾기 알고리즘
해리스 적용 예
- 큰 값이 밀집되어 나타남 대표점 선택 필요
- 특징 가능성 맵 C 값으로 계산된 결과를 왼쪽 표로써 얻어내고, 값들이 밀집되어있는데, 대표점을 선택하는 문제가 위치 찾기 문제
- m(j,i) 를 숫자로 표시하지 않고 영상으로 표현하면 0값은 검정색으로 표현됨,
- 간단한 삼각형 예처럼 그림으로 표현 가능, 여기서 빨간색은 가장 변화가 큰 특징점

- 큰 값이 밀집되어 나타남 대표점 선택 필요
-
비최대 억제
- 특징점 검출 알고리즘(모라벡, 해리스코너)은 이미지에서 여러 위치에서 유사한 특징점을 검출할 수 있는데, 이 경우 비최대 억제는 겹치는 특징점 중 가장 강한 특징점을 선택하고 나머지는 제거하여 중복을 방지한다.
- 이웃 화소보다 크지 않으면 억제됨 즉, 지역 최대만 특징점으로 검출됨
- 이 상,하,좌,우 임계값보다 클 경우 특징점으로 판정하여 F 에 점을 추가하는 알고리즘
- if else 룰
- c가 5번 등장함 즉 c라는게 m(j,i) 값을 여기다 대체를 하면, 메모리를 3번(i를 읽고, j를 읽고, 해당m을 읽고) 엑세스를 해야함.
- 총 15번 해야하는데, m(j,i) 값을 c를 카피하면 실제로는 총 메모리 엑세스가 9번으로 줄어듬
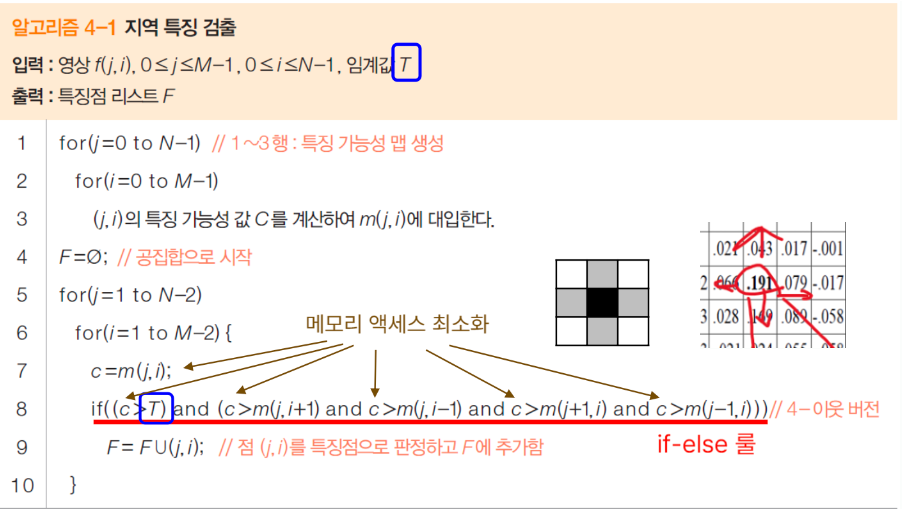
-
이동과 회전에 불변인가?
- 이동이나 회전 변환이 발생하여도 같은 지점에서 관심점이 검출될까? YES
- 우리가 찾은 특징점이 회전과 이동에 불변한지 -> 코너에 해당하는 특징점이 검출되어 불변

-
스케일에 불변인가?
- 스케일이 변해도 같은 지점에서 관심점이 검출될까? NO
- 연산자 크기가 고정되어 있기 때문에
- 스케일 변화에 대처하려면 연산자 크기를 조절하는 기능이 필수적임
- 큰 원으로 작은 삼각형에서의 특징점을 검출하는 경우 모든 점이 특징점으로 선택이 되는 문제
- 연산자의 크기를 조절해야함 (작은 이미지는 작은 연산자, 큰 이미지는 큰 연산자 사용)
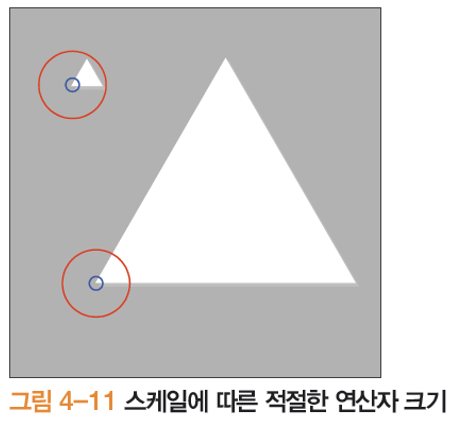
- 스케일이 변해도 같은 지점에서 관심점이 검출될까? NO
2
2. 이동/회전/스케일에 불변한 특징점
2.1) 스케일에 불변한 특징점(위치+스케일) 검출
거리에 따른 스케일 변화
- 예) 멸면 작고 윤곽만 어렴풋이 보이다가, 가까워지면 커지면서 세세한 부분이 보임
- 사람은 강인하게 대처하는데, 컴퓨터 비전도 대처 가능한가?

다중 스케일 접근 방법
- 스케일을 포함한 3차원 극점 (지역 최대 또는 최소점) 검출

- 스케일을 포함한 3차원 극점 (지역 최대 또는 최소점) 검출
다중 스케일 영상을 구현하는 두 가지 방식
- 가우시안 스무딩 : 스케일에 해당하는 가 연속 공간에 정의
- 가우시안 스무딩을 써서 다양한 영상을 얻을 수 있다
- 피라미드 : 씩 줄어들므로 이산적인 단점
- 실제로 영상 자체를 다운 스케일링 해서 멀티 스케일 영상 얻기

- 실제로 영상 자체를 다운 스케일링 해서 멀티 스케일 영상 얻기
- 가우시안 스무딩 : 스케일에 해당하는 가 연속 공간에 정의
가우시안 스무딩에 의한 스케일 공간
- 스케일 축(분산 을 의미하는 t를 scale parameter 라 하고, )을 추가한 3차원 공간
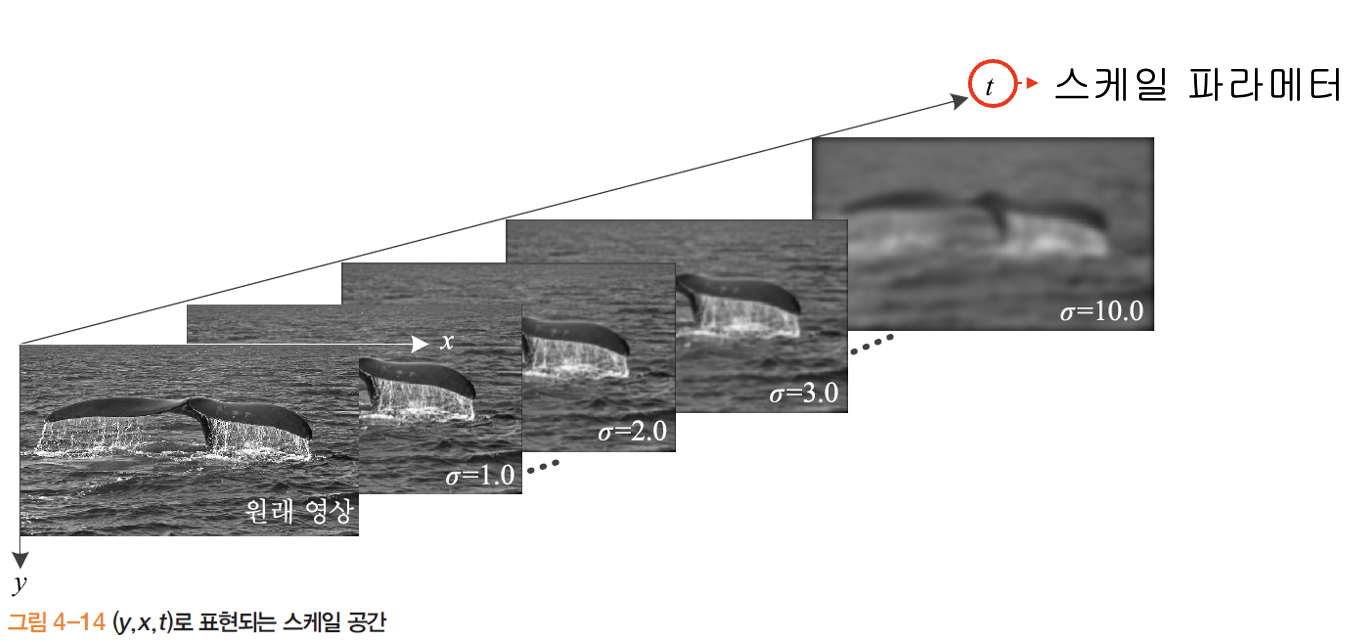
- 스케일 축(분산 을 의미하는 t를 scale parameter 라 하고, )을 추가한 3차원 공간
t 축에서 지역 극점 탐색
- 영상 f 에 대하여 t축을 따라 정규 라플라시안 측정해 보면, 극점 발생함

- 영상 f 에 대하여 t축을 따라 정규 라플라시안 측정해 보면, 극점 발생함
- 공간에서 극점의 위치를 안다고 가정할떄, 실험에 따르면 t축에서 정규 라플라시안이 가장 안정적으로 극점 생성
- 극점의 값은 "물체의 스케일" 에 해당
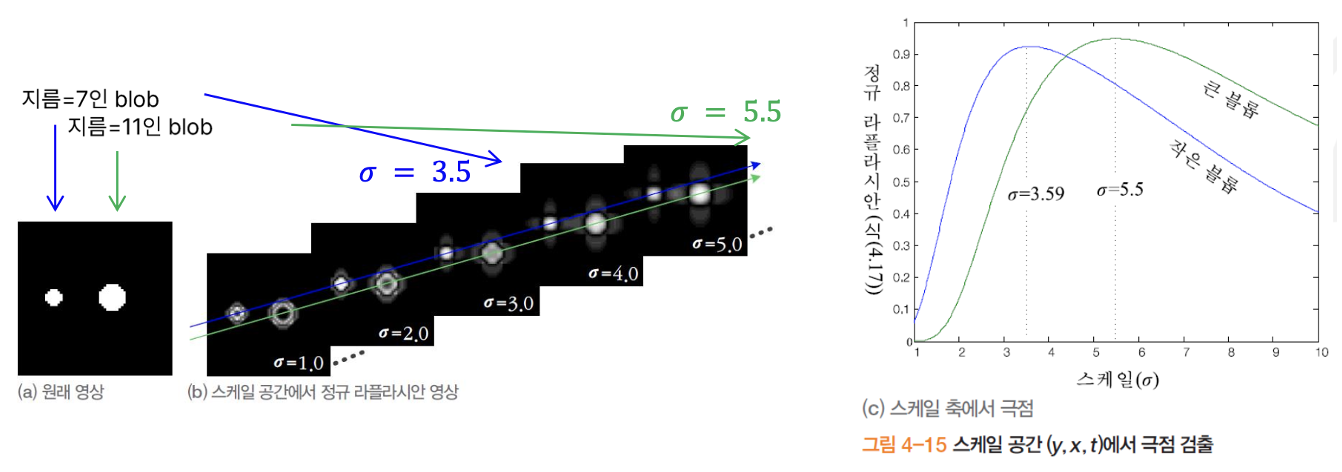
2.2) SIFT 검출 : 영상과 스케일을 "통합"하여 검출
-
SIFT 의 스케일 공간
- 피라미드 + 가우시안 구조 (sift 는 1/2 씩 줄인 파리마드 영상과 가우시안을 합한 구조)
- 계산 시간을 줄이기 위해서 DOG 라고 오른쪽 영상과 같이 가우시안 두개를 빼기
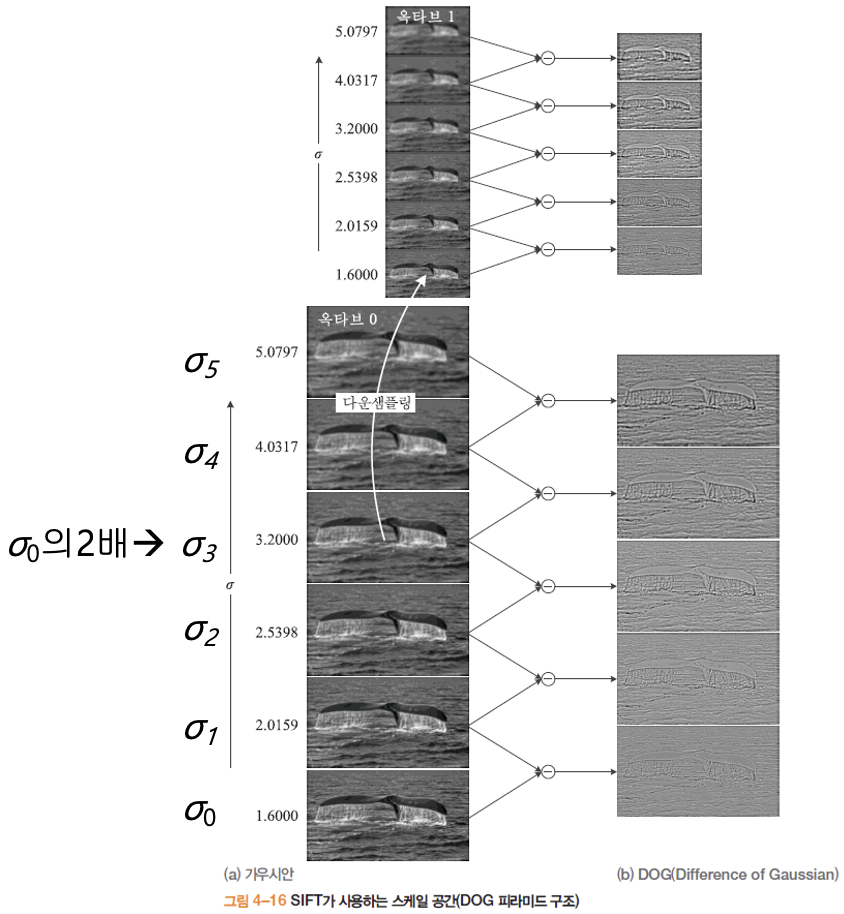
-
정규 라플라시안 맵 구축
- [Mikolajczik2002a] 의 실험 결과에 따르면, 정규 라플라시안이 가장 안정적으로 극점 형성
- 정규 라플라시안(2차 미분)과 유사한 DOG 게산으로 대치
- DOG는 단지 차영상을 게산하므로 매우 빠름
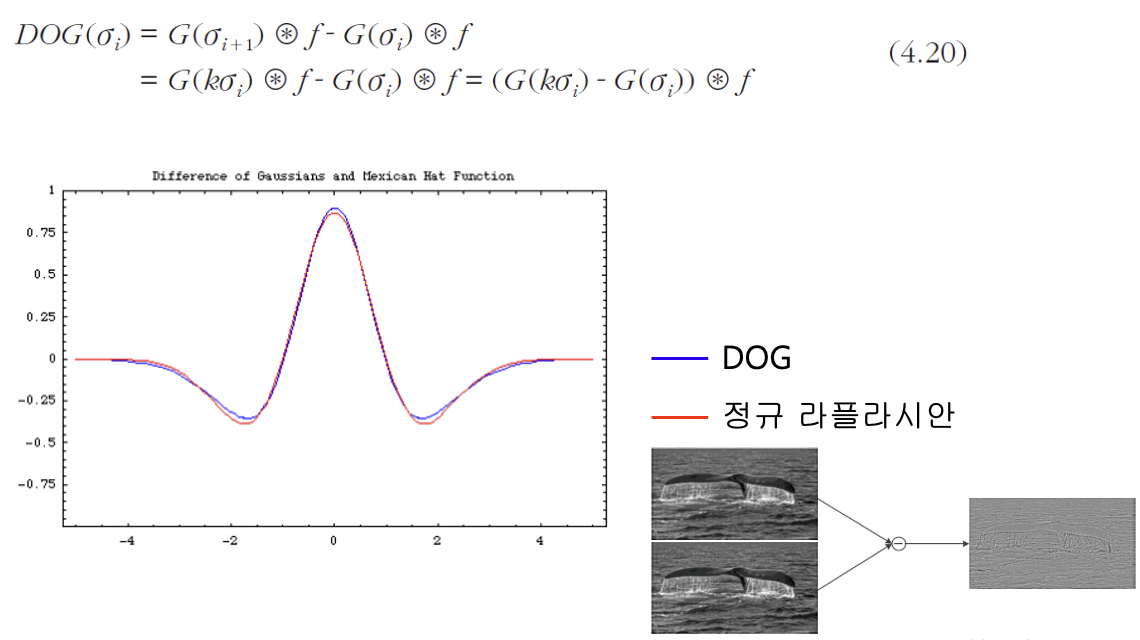
- DOG는 단지 차영상을 게산하므로 매우 빠름
-
특징점 (키포인트) 검출
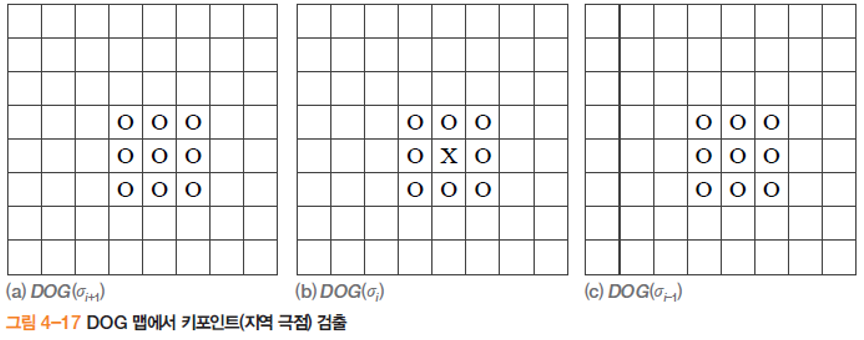
- 한 옥타브에는 다섯 장의 DOG 영상
- 중간에 끼인 세 장의 DOG 맵 각각에서 극점 검출
- 주위 26(=9+8+9)개 이웃에 대해 최저 또는 최대인 점
- 검출된 극점을 키포인트 라 부름
- DOG 이미지 5개중 현재 선택된 이미지의 위 아래를 비교하기 때문에 중간에 3개만 연산에 참여한다.
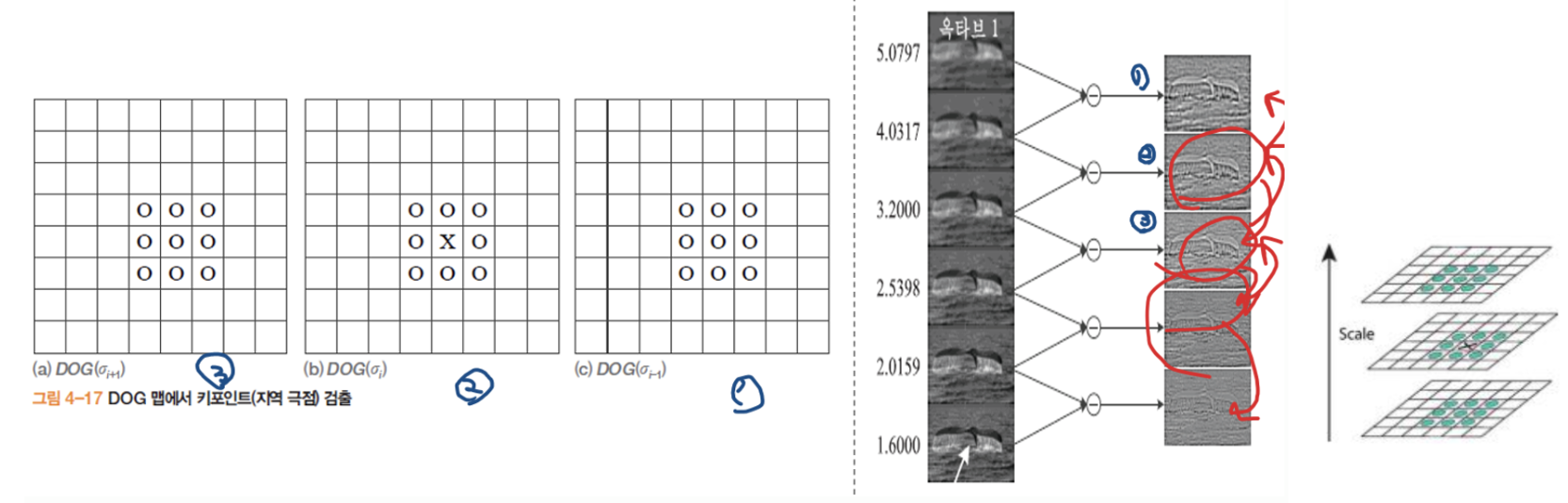
- DOG 맵 -> 샌드위치 처럼 나 자신이 포함된 부분은 나를 제외한 8개, 위로는 9개 아래로도 9개 해서 3x3x3 의 마스크 를 씌워 이웃에 대해 최저 혹은 최대인 극점을 키포인트라 부른다.
- DOG 이미지 5개중 현재 선택된 이미지의 위 아래를 비교하기 때문에 중간에 3개만 연산에 참여한다.
위치와 스케일 계산
- 키포인트는 <y,x,o,i> 정보를 가짐 : 옥타브 o의 i 번째 DOG 영상의 (y,x) 에서 검출되었다고 해석 가능
- 미세 조정 (부분 화소 정밀도)를 거쳐 <y',x',o',i'> 로 변환됨
- (옥타브 0에서의) 위치와 스케일 계산 식 적용

- 일부만 보일 때에서 각 장난감을 찾아낼 수 있다.

2.3) SURF 검출
SURF
- 정확도 희생 없이 SIFT 보다 빠른 알고리즘 추구 (sift 발전시킨 surf 검출)
- 헤시안의 행렬식 이용
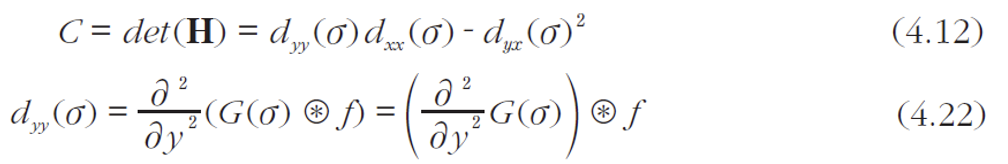
- 행렬식을 빠르게 계산하기 위해 , , 를 9x9 마스크 로 근사 계산
마스크 계산은 적분 영상 이용(ex. 14번의 덧셈 3번의 덧셈)
'왼쪽 위 구석부터 현재 화소까지 합' 으로 표시되는 적분 영상은 9강에서 자세히 설명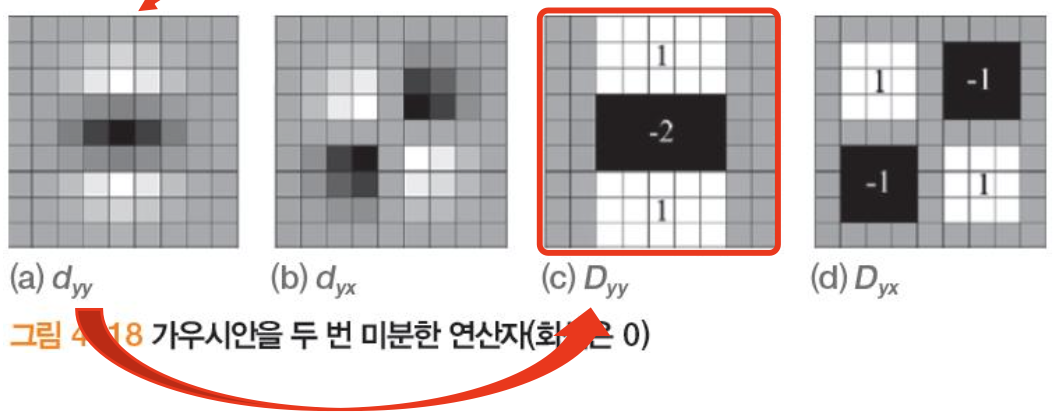
SURF 의 스케일 공간
- 원본 영상을 그대로 둔 채 다중 스케일 마스크를 적용 가우시안 스무딩 회피
- 가우시안의 시그마를 크게 증가시키는 것하고 원 영상의 마스크를 9x9 에서 15x15 로 확장하는 것과 거의 비슷한 효과가 있다.
- 이런식으로 마스크를 늘리면 가우시안 스무딩을 이용하지 않아도 됨
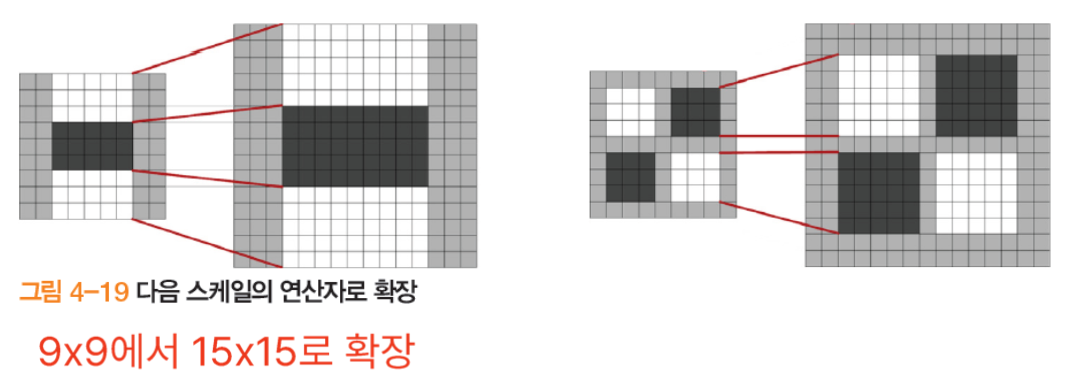
- 옥타브 구성 (가우시안 스무딩 대신에 마스크 크기를 증가시키는 방법 채택)
- 첫 번째 옥타브 9x9, 15x15, 21x21, 27x27 마스크(컴볼루션) 적용 (6씩 증가)
- 이미지의 크기를 줄이는 것x 연산자를 확대
- 마스크로 생성된 이미지중 예를 들어 DOG 를 적용하여 15를 기준으로 큰것 작은것, 또는 21을 기준(DOG)으로 한다면 1515 와 2727 과 비교여 26개 이웃에 대해 극점을 구하기
- 두 번째 옥타브 15x15, 27x27, 39x39, 51x51
- 첫 번째 옥타브의 두 번째 마스크 15x15에서 시작하고 6의 두 배인 12씩 증가
- 세 번째 옥타브 27x27, 51x51, 75x75, 99x99
- 두 번째 옥타브의 두 번째 마스크 27x27에서 시작하고 12의 두 배인 24씩 증가
TIP : SIFT 는 단일 스케일 연산자를 다중 스케일 영상에 적용하는 반면 SURF는 단일 스케일 영상에 다중 스케일 연산자를 적용한다고 볼 수 있다.
- 두 번째 옥타브의 두 번째 마스크 27x27에서 시작하고 12의 두 배인 24씩 증가
- 첫 번째 옥타브 9x9, 15x15, 21x21, 27x27 마스크(컴볼루션) 적용 (6씩 증가)
지역 극점 검출
- 첫 번째 옥타브에서 중간에 끼인 15x15 와 21x21 에서 지역 극점 검출 (그림 4-17)
- 두 번째 옥타브에서 중간에 끼인 27x27 과 39x39 에서 지역 극점 검출
- ...
SURF 의 속도 개선 보고 [Bay2008]
- 800x640 영상에서 SURF 70mx, SIFT 400ms, 해리스 라플라스 2100ms
3
3. 특징 기술자의 조건
3.1) 특징 기술자의 조건
-
지금까지 공부한 특징 검출 단계
- 에지, 지역 특징 매칭에 사용하기에 턱없이 '빈약한' 정보

- 에지, 지역 특징 매칭에 사용하기에 턱없이 '빈약한' 정보
-
'풍부한' 정보를 어떻게 추출할까?
- 특징 기술 단계는 검출된 특징의 '내부' 또는 '주위'를 들여다 보고 풍부한 정보를 추출
- 특징의 '성질' 을 기술해주므로 기술자 또는 여러 개의 값으로 구성된 벡터 형태이므로 특징 벡터라 부름
- 또한 '잠자리를 포함하는 영상을 찾아라' 와 같은 검색어를 처리하기 위해서는 영상 전체를 대상으로 특징 벡터를 추출할 수 있어야 함.
-
매칭이나 인식에 유용하기 위한 몇 가지 요구 조건
- 특징은 높은 분별력을 가져야 함
- 특징은 다양한 변환에 불변이어야 함
- 기하 불변성과 광도 불변성
- 변환에도 불구하고 같은(유사한) 값을 갖는 특징 벡터 추출해야 함
-
매칭은 특징 벡터 간의 거리를 계산하여 판단
- 적절한 특징 벡터의 크기(차원)를 선택해야 함
- 차원이 낮을수록 계산 빠름 정확도와 계산시간의 tradeoff
4
4. 관심점을 위한 기술자
관심점을 어떻게 기술할 것인가?
- 들여다볼 윈도우의 크기 가 중요
스케일 정보 없는 관심점 (예, 해리스 코너)- 윈도우 크기를 결정하는데 쓸 정보가 없음
- 스케일 불변성을 위한 계산 불가능
- 스케일 에 따라 윈도우 크기 결정
스케일 불변성을 위한 계산 가능
- 들여다볼 윈도우의 크기 가 중요
4.1) SIFT 기술자
-
앞에서 검출한 SIFT 키포인트(관심점)의 위치+스케일
- 검출된 옥타브 , 옥타브 내의 스케일 , 그 옥타브 영상에서 위치 정보를 가짐
-
SIFT 기술자(특징 벡터)의 불변성
- 스케일 불변 달성
- 윈도우를 옥타브 , 스케일 인 영상의 위치 에 씌움
- 회전에 대한 불변성 달성
- 얼만큼 회전을 했는지를 알아보기 위해 지배적인 방향 계산 (윈도우 내의 그레디언트 방향 히스토그램을 구한 후, 최대값을 갖는 방향 찾음)
- 광도 불변 달성
- 특징 벡터 를 단위 벡터 로 나누어 정규화함=
- 스케일 불변 달성
-
SIFT 기술자 추출 알고리즘 [Lowe2004]함
- 윈도우를 4x4 의 16개의 블록으로 분할
각 블록은 그레디언트 방향 히스토그램을 구함
그레디언트 방향을 8개로 양자화 - 4x4x8=128 차원 특징 벡터 x
- 화소 값은 보간으로 구함
- n개의 키 포인트가 검출됬다고 하면, 각 키포인트에 대한 지배적인 방향 를 구한다.
- 그 에 윈도우를 씌워서 특징 벡터를 구한다.
- 계산된 특징 벡터를 정규화 해서 기술자가 추가된 키포인트 집합을 얻는다.

- 윈도우를 4x4 의 16개의 블록으로 분할
4.2) SIFT 의 변형
- HOG
- 객체(예, 보행자) 탐지용 특징 기술자(+SVM)
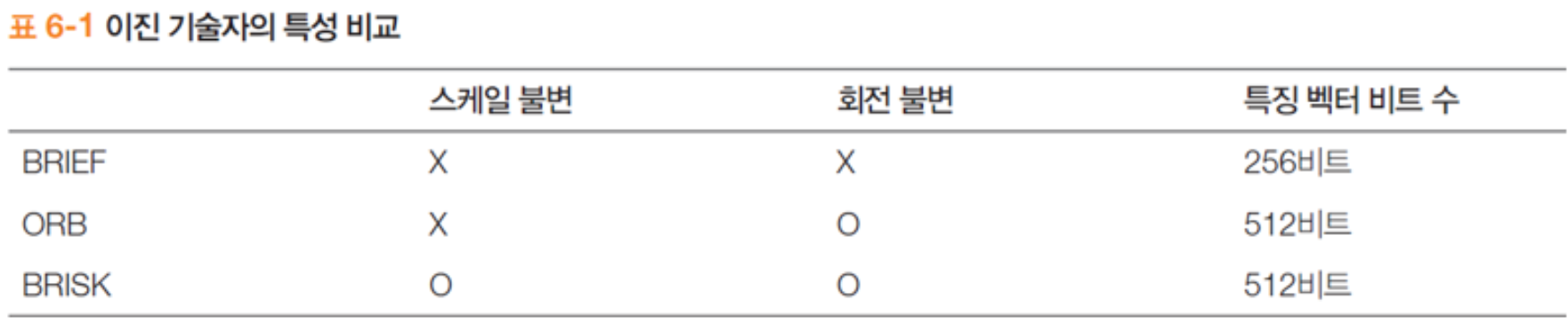
4.3) 이진 기술자
- 비디오 처리 등 빠른 매칭을 위해 특징 벡터를 "이진열"로 표현
- 비교 쌍의 대소 관계에 따라 0 또는 1
- 비교 쌍을 구성하는 방식에 따라 여러 변형
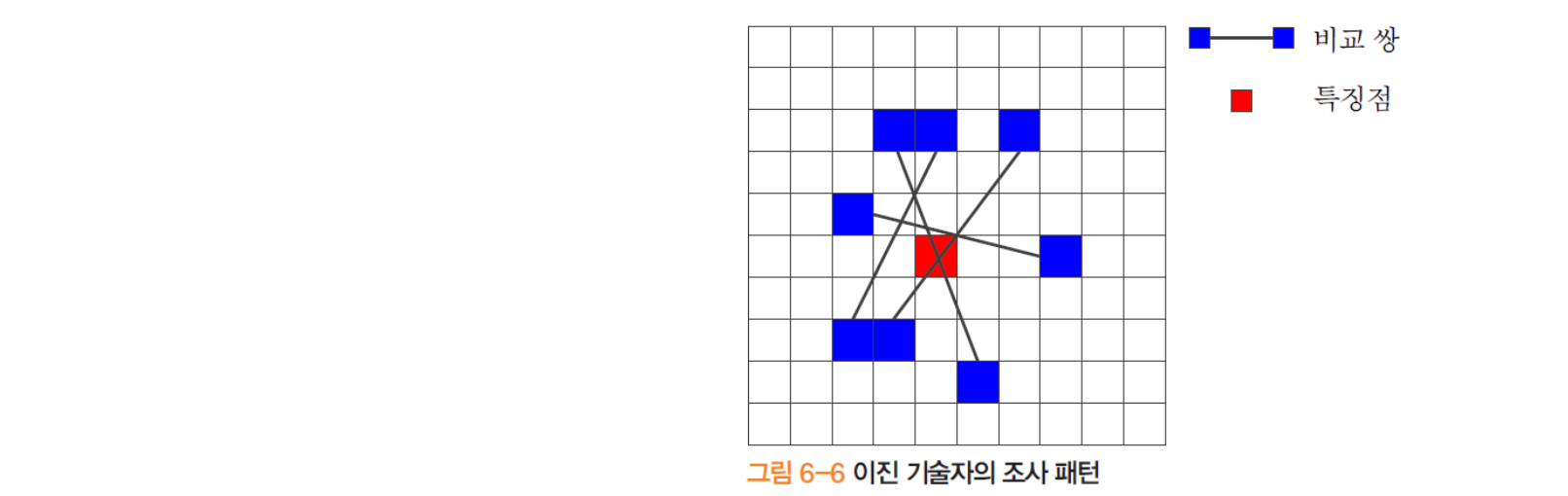
- SIFT 특징점 하나가 512Bytes 이라면, 이진 기술자는 512bits (SIFT에 비하여 메모리가 8배 적음)
- 매칭은 해밍 거리 를 이용하여 빠르게 수행 (SIFT 에 비하여 수십배 빠름)
- 단, 별도의 특징점 검출 알고리즘은 불포함 (단지 특징점 기술만 효과적으로)
- BRIEF, ORB, BRISK
- Binary Robust Independent Elementary Feature
- Oriented Fast & Rotated BRIEF
- Binary Robust Invariant Scalable Keypoint
4.4) 텍스처
-
텍스처란?
- 일정한 패턴의 반복
- 구조적 방법과 통계적 방법

-
전역 기술자
- 영역 내 에지 기반

- 영역 내 명암 히스토그램 기반
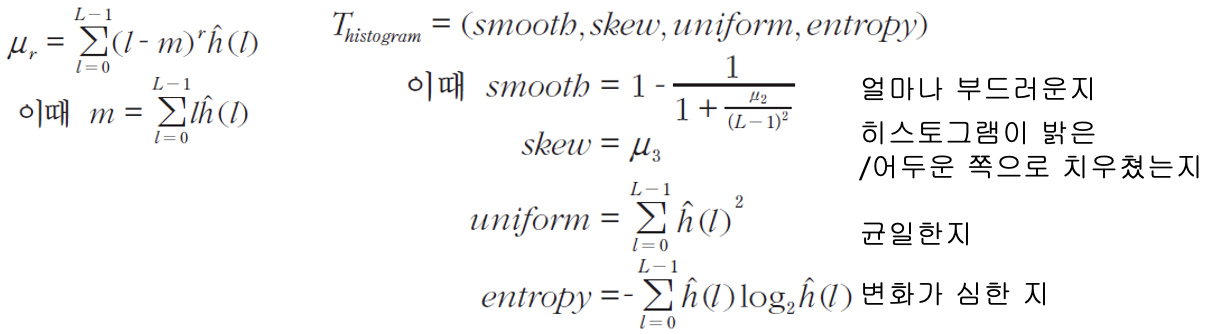
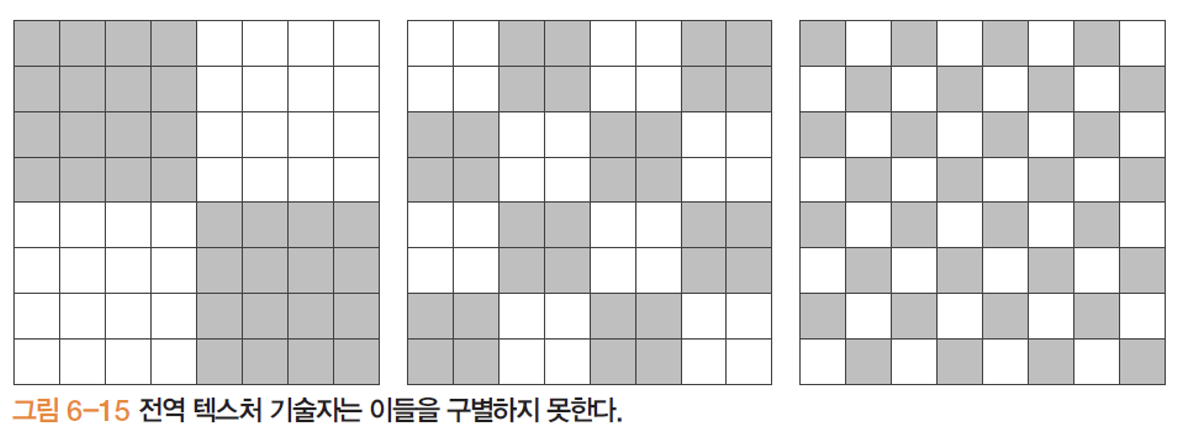
한계
- 지역적인 정보 반영하지 못함
- 3개의 이미지에서 뽑은 히스토그램이 각각 같음, 따라서 똑같은 패턴의 전역 정보만 가지고는 텍스처를 구별 못함
- 영역 내 에지 기반
-
지역 관계 기술자
- 원리
- 화소 사이의 이웃 관계를 규정하고, 그들이 형성하는 패턴을 표현
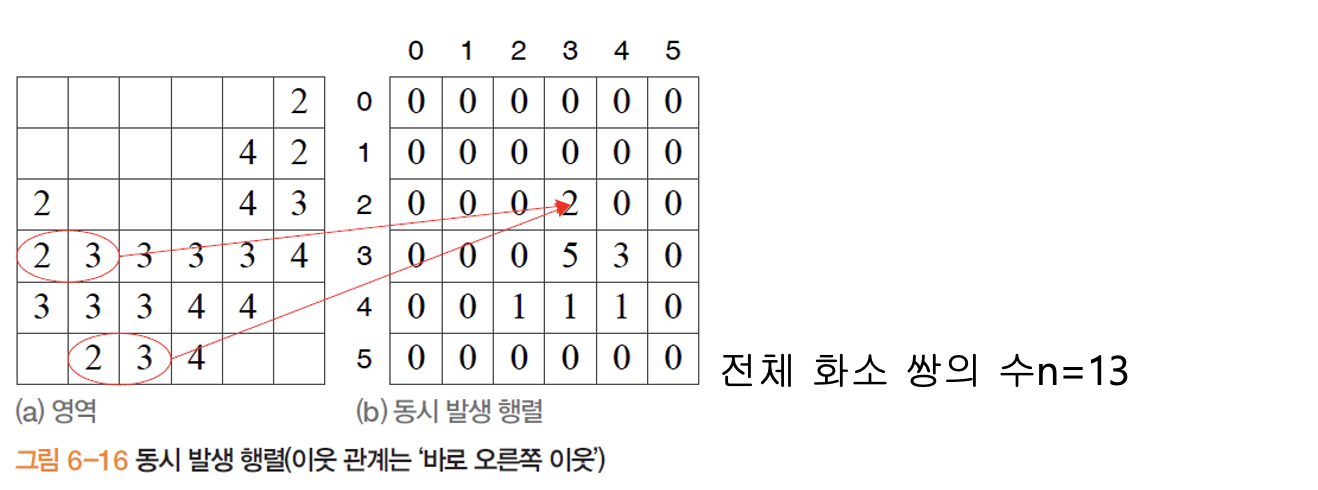
동시 발생 행렬
- 이웃 관계를 이루는 화소 쌍의 명암이 인 빈도수 세어, 행렬 의 요소 에 기록
- 이웃 관계는 '바로 오른쪽 이웃'
- 에서 으로
- 에서 으로 넘어가는 픽셀의 쌍의 개수는 개이므로, (b)동시 발생 행렬 좌표 에 로 표시
- 원리
-
동시 발생 행렬에서 특징 추출 가능

-
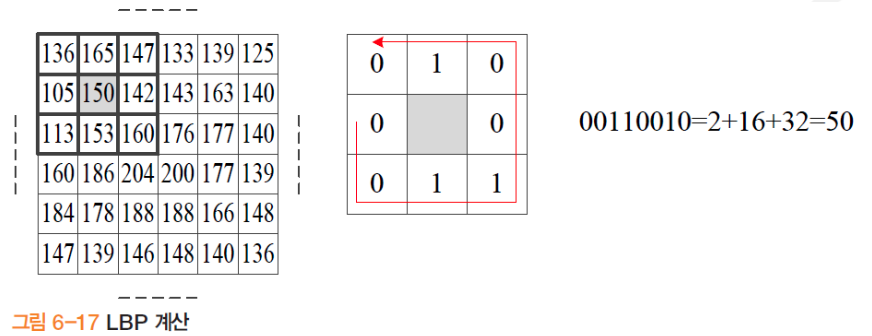
지역 이진 패턴 (LBP ) [Ojala96]
- 8개 이웃과 대소관계에 따라 이진열을 만든 후 [0,255] 사이의 십진수로 변환
- 가운데 150을 기준으로 8방향 계산 150보다 작은것은 0, 큰것은 1
- 모든 화소를 가지고 히스토그램 구성 ( 개의 이웃을 본다면, 차원의 특징 벡터 생성)
- 8개의 2진수를 구할 수 있는데 이들을 오른쪽 부터 표시 (10진수)
- 한계 : 노이즈에 민감(예: 등을 구분)
- 150을 중점으로 잡았을떄, 주변 픽셀값이 148 과 152는 큰 차이값이 아닌데도 불구하고 0과 1로 나누어지는 것 처럼 큰 차이를 보일 수 있다.
- 150을 중점으로 잡았을떄, 주변 픽셀값이 148 과 152는 큰 차이값이 아닌데도 불구하고 0과 1로 나누어지는 것 처럼 큰 차이를 보일 수 있다.
- 8개 이웃과 대소관계에 따라 이진열을 만든 후 [0,255] 사이의 십진수로 변환
-
지역 삼진 패턴 (LTP )
- 현재 화소 값이 이고 매개변수가 라면, 이웃 화소 보다 작으면 , 보다 크면 , 사이면 을 부여
- 가운데가 150 이고 왼쪽 105 가 더 작기 떄문에 -1 , 113 도 150보다 작으므로 -1 로 표현 153 같은 경우는 150과 3의 차이를 가지는데 스레시홀드 5를 기준으로 결과적으로 0이라는 값을 가지게 된다.
- 두 개의 LBP로 분리(두개를 이어붙여 총 512 차원 벡터 생성)
- 2개의 LBP 로 만들어서 다음 그림과 같이 +1 -1 표현 가능
- 모든 화소를 가지고 히스토그램 구성
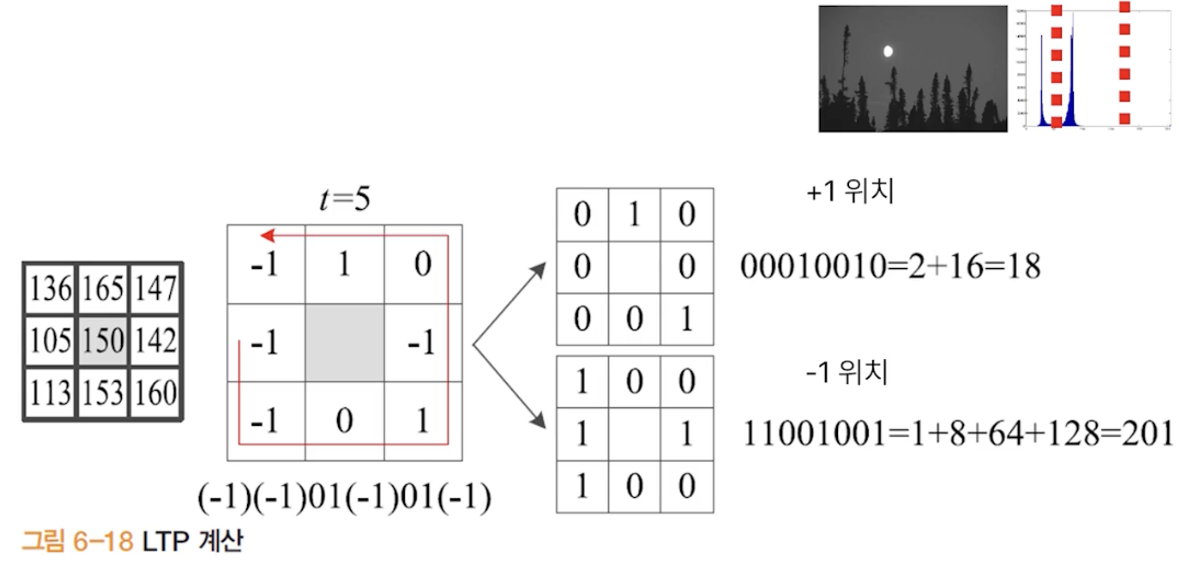
- 현재 화소 값이 이고 매개변수가 라면, 이웃 화소 보다 작으면 , 보다 크면 , 사이면 을 부여
4.5) 주성분 분석
-
고차원 백터를 저차원으로 축소
- 정보 손실을 최소화 하는 조건 (like 압축)
- Karhunen-Loeve(KL) 변환 또는 Hlteling 변환이라고도 부름

-
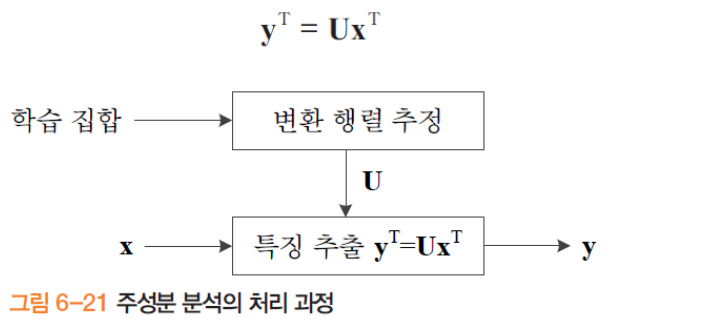
원리
- 학습 집합(n명의 얼굴) 로 변환 행렬 를 추정
- 는 로써 차원의 (영상 전체의 얼굴 사진) 를 차원의 (출력)로 축소 변환
- 차원
-
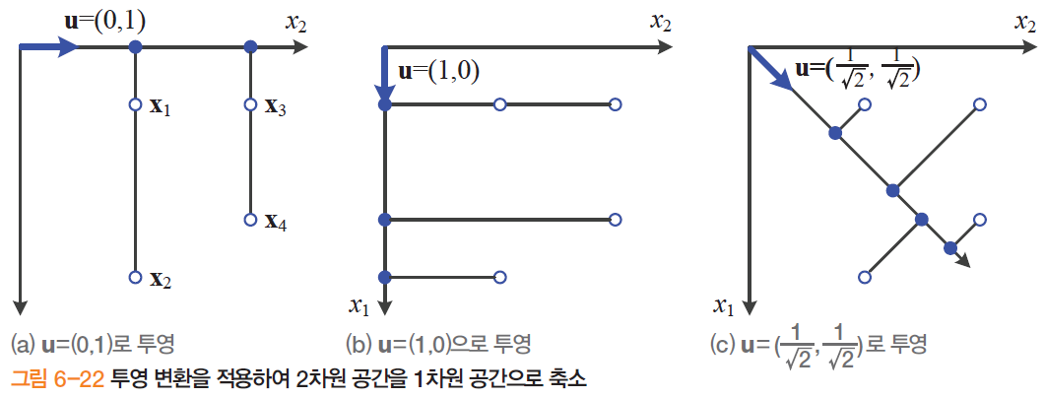
차원 축소를 어떻게 표현하나?
- 축 상으로 '투영'으로 표현
- 그림 6-22 는 2차원(D)을 1차원(d)으로 축소하는 상황
-
정보 손실을 어떻게 표현하나?
- 정보란? 점들 사이의 거리나 상대적인 위치 등
- 어느 것의 정보 손실이 최소인가? 직관적으로 판단하면 맨 오른쪽
- 변환행렬 를 으로 표현하여 투영 : 2개의 정보 손실
- 2차원 공간의 모든 정보를 1차원 공간에 표현할 수 없기 때문에
- 따라서 변환 후에는 원래 2차원 좌표상에서 y축 정보가 완전히 손실됨 (4 2)
- 변환행렬 를 으로 표현하여 투영 : 1개의 정보 손실
- 2차원 좌표 상에서 축의 정보가 완전히 손실됨
- 과 가 동일한 표인트로 구별이 됨
- 2차원에서 1차원으로 표기하니 3으로 표현됨 정보손실이 1만큼 일어남
- 변환행렬 로 투영
- 4개의 포인트를 1차원으로 표현하면 4개가 정보 손실 없이 유지됨
- 차원이 줄어듦에도 불구하고 동일한 포인트를 다 나타낼 수있으므로 pCA 를 사용
-
PCA 의 정보 손실 표현
- 분산 계산하여 얼마만큼 퍼져있는지 계산(분산이 잘 퍼진, 완만한 분산이 목표)
- 원래 공간에 '퍼져 있는 정도'를 변환된 공간이 얼마나 잘 유지하는지 측정
- 이 수치를 변환된 공간에서 분산 으로 측정
-
최적화 문제 (like Otsu)
- 분산을 최대화 하는 벡터 u 찾기
- 그림 6-22에서 맨 오른쪽이 최적의 축인가?

-
알고리즘
최대화 문제
- 우리가 주어진 샘플 x 의 분산 구하기
- 각각의 샘플 :
- 평균 :

-
u가 '단위 벡터'라는 조건을 포함시키면, 조건부 최적화 문제가 되고 라그랑주 승수 로 표현

-
도함수를 구하고, 도함수를 0으로 두고 정리하면,
- (6.39) 식의 의미 : 우선 학습집합의 공분산 행렬 를 구한다. 그런 다음 (합)의 고유 벡터를 계산하면 그것이 바로 최대 분산을 갖는 u 가 된다.
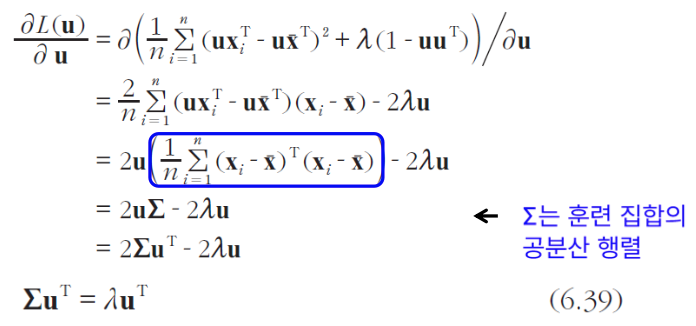
- (6.39) 식의 의미 : 우선 학습집합의 공분산 행렬 를 구한다. 그런 다음 (합)의 고유 벡터를 계산하면 그것이 바로 최대 분산을 갖는 u 가 된다.
- D차원을 d차원으로 축소
- 지금까지는 D차원을 1차원으로 축소함
- 공분산 행렬 을 D * D 이므로, D 개의 고유 벡터가 있음
- 이들은 서로 수직인 단위 벡터, 즉 이고
- 고유값이 큰 순서대로 상위 d 개의 고유벡터 를 선택 (주성분) 하고 식 (6.40)에 배치(U는 d*D)

- U를 이용한 차원 축소

- 알고리즘

4.6) 응용 사례 : 고유 얼굴을 이용한 얼굴 인식
-
컴퓨터 비전에서 PCA 의 응용 사례
- 기술자 추출 : PCA-SIFT, GLOH 등
- 가장 혁신적인 응용 얼굴 인식
-
평균 얼굴
- 이때 계산된 평균 이미지의 의미를 가지려면 다음 조건 만족해야함
- 눈과 입의 위치가 대략 일치해야하고 조명이 비슷해야함.
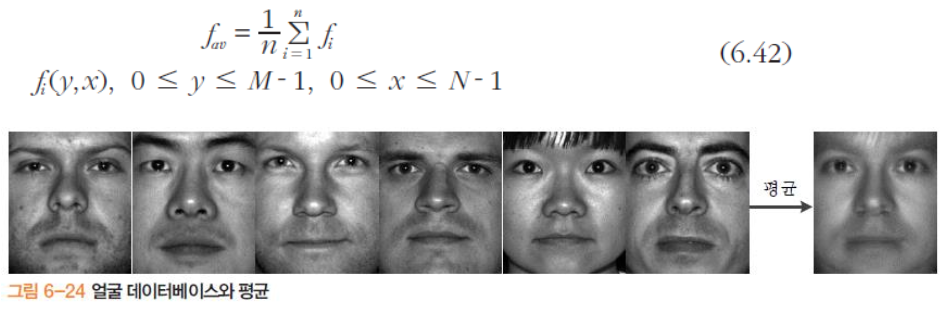
- 눈과 입의 위치가 대략 일치해야하고 조명이 비슷해야함.
- 이때 계산된 평균 이미지의 의미를 가지려면 다음 조건 만족해야함
-
얼굴 영상에 PCA 적용
- 영상 벡터 형태로 변환 (벡터 차원 ) : 행 우선으로 배치
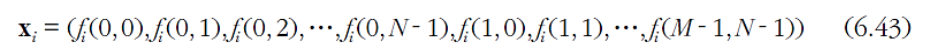
- n개의 얼굴 영상으로 구성된 학습 집합 을 입력으로 PCA를 적용
- 이렇게 얻은 d개의 고유 벡터 를 고유 얼굴이라 부름
- 이들에 (6.43)을 역으로 적용하여 영상 형태로 바꾸면, 그림 6.25
- 영상 벡터 형태로 변환 (벡터 차원 ) : 행 우선으로 배치
-
고유 얼굴의 활용 : 얼굴 영상 압축

-
역 변환으로 원 영상 복원 가능
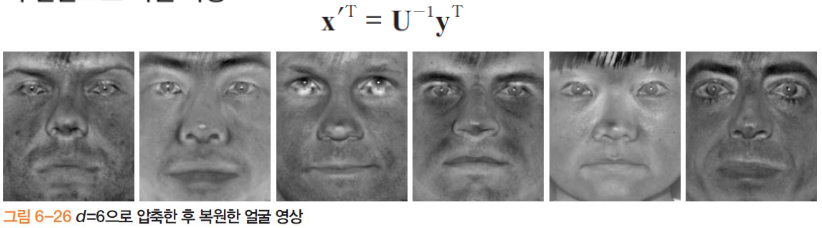

공부한 것 기록용