CH1
Language Model
- 문장이 얼마나 자연스러운지에 대한 확률을 계산하여 문장 내 특정 위치에 나타나는 데 적합한 단어를 확률적으로 예측하는 모델입니다
- 쉬운 방법으로, Language Model은 이전 단어들을 기반으로 다음 단어를 예측합니다

Large Language Model (LLM)
1) 대화 또는 기타 자연어 입력에 대한 인간과 같은 반응을 생성하기 위해 방대한 텍스트 데이터에 대해 훈련된 인공 지능(Large Language Models)
- 대화하듯 인간이 응답을 주듯이 답을 생성시켜주기 위해
2) Large Language Models는 많은 양의 데이터가 필요하고 다른 딥러닝 모델에 비해 파라미터(가중치) 크기가 큽니다
3) 유명 LLM : 트랜스포머, GPT, BERT 등.
LLM 의 파라미터는 무엇인가?
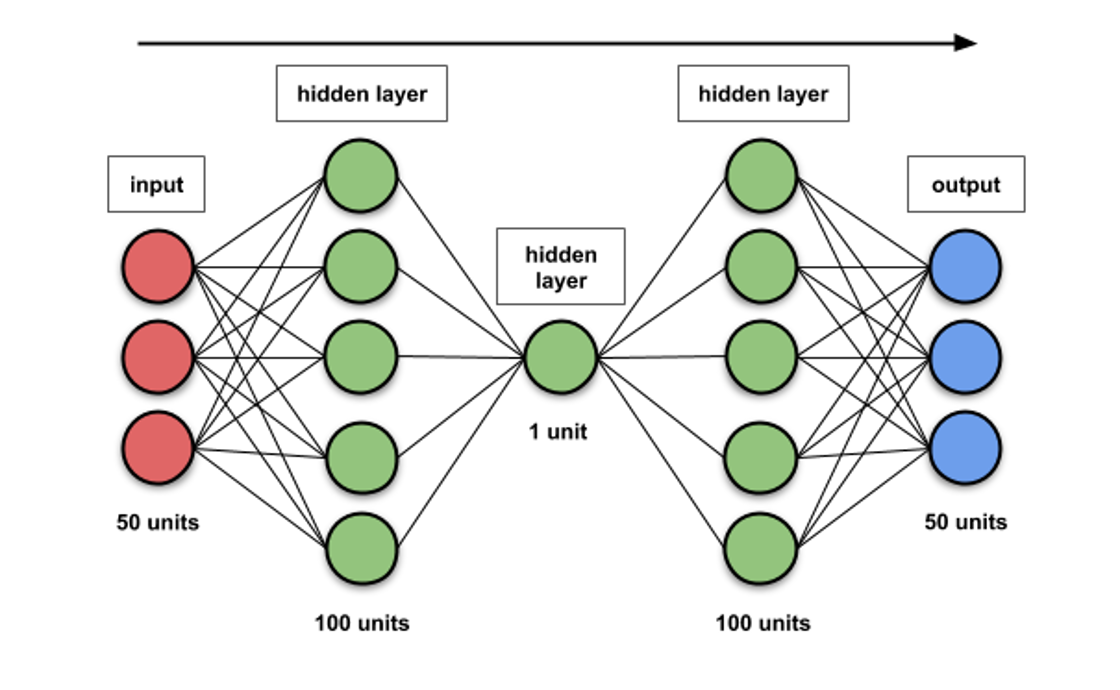
- 머신 러닝과 딥 러닝의 파라미터 는 학습 알고리즘이 학습할 때 독립적으로 변화할 수 있는 값(가중치)입니다.
- 이러한 값은 사용자(인간)가 제공하는 하이퍼 파라미터(hyper parameter, 히든레이언개수개수등등, 학습률노드)등등)의 선택에 따라 영향을 받습니다.
딥러닝과 지도학습
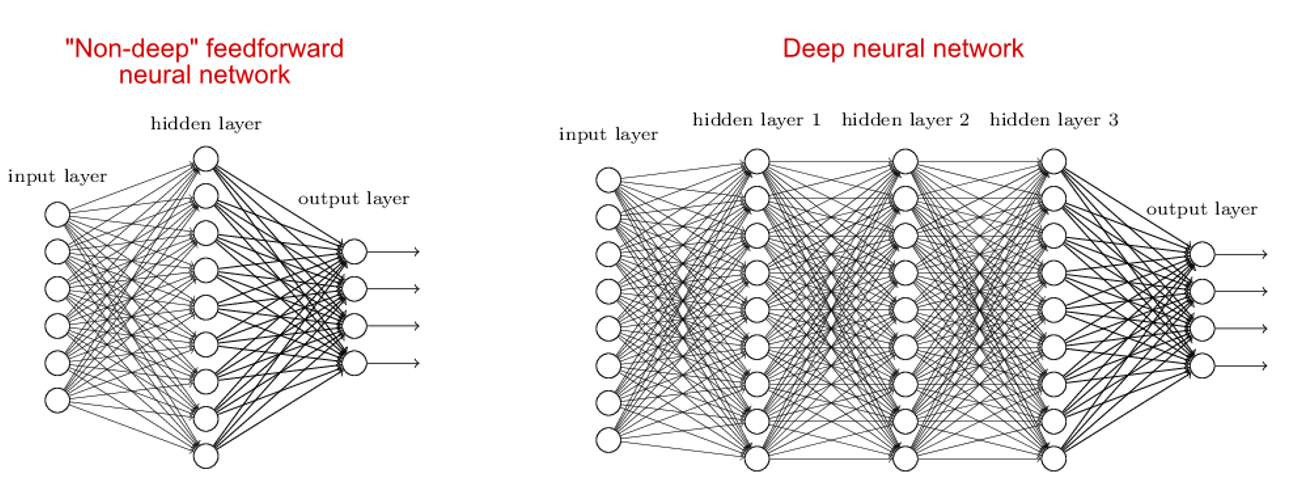
1) 네트워크에 3개 이상의 레이어가 있으면 깊이가 있는 것 (deep 하다) 입니다.
2) 딥 러닝 NN은 매우 복잡한 함수, 고도의 비선형 함수 문제를 학습할 수 있습니다
- 학습하기 위한 함수의 곡선이 더 비선형화 된다 -> 더 치밀한 예측을 한다.
2) 그러나 딥러닝 방법은 과적합 문제를 야기합니다.
- 히든레이어가 많으면 많을 수록 weight 값들이 증가 -> 마냥 좋은것만은 아니다.
- 과적합이 생기는 이유
- 히든 레이어의 차수가 너무 높았을 경우 degree?
- training data 가 충분하지 않을경우
- 학습 데이터 간 종속관계 생겼을 경우 : 한 학습 데이터와 다른 학습 데이터에 영향을 많이 줄 경우
역전파:
target과 y의 차이, 이전 레이어로 피드백(target-y) 값에 차이를 뒤로 가면서 무게 반영
딥러닝과 지도학습 (역전파)
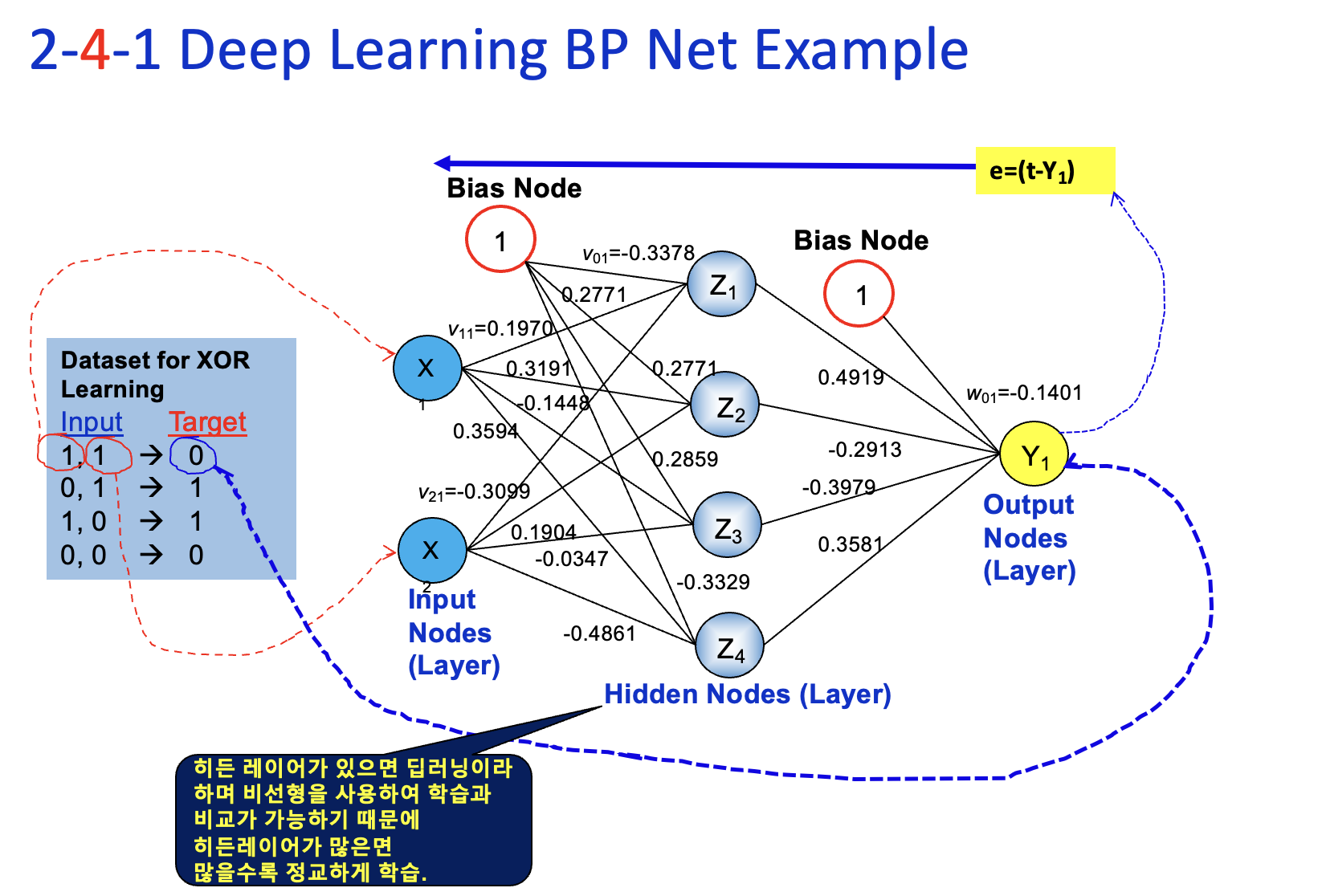
XOR 에 대한 데이터 셋 (레이블)
-
두개의 input 노드 x 가 1, 1 인 경우 Target 0 (supervisor 가 가지고있는 정답)
-
계산을 통해서 Y 이 0에 가깝게 값이 나와야하는데, 그렇지 않기 때문에 Error 만큼 뒤로 역전파, 학습 시킨다.
-
LLM 에서 파라미터 개수가 굉장히 중요하다.
파라미터 개수에 의한 LLM 과 sLLM
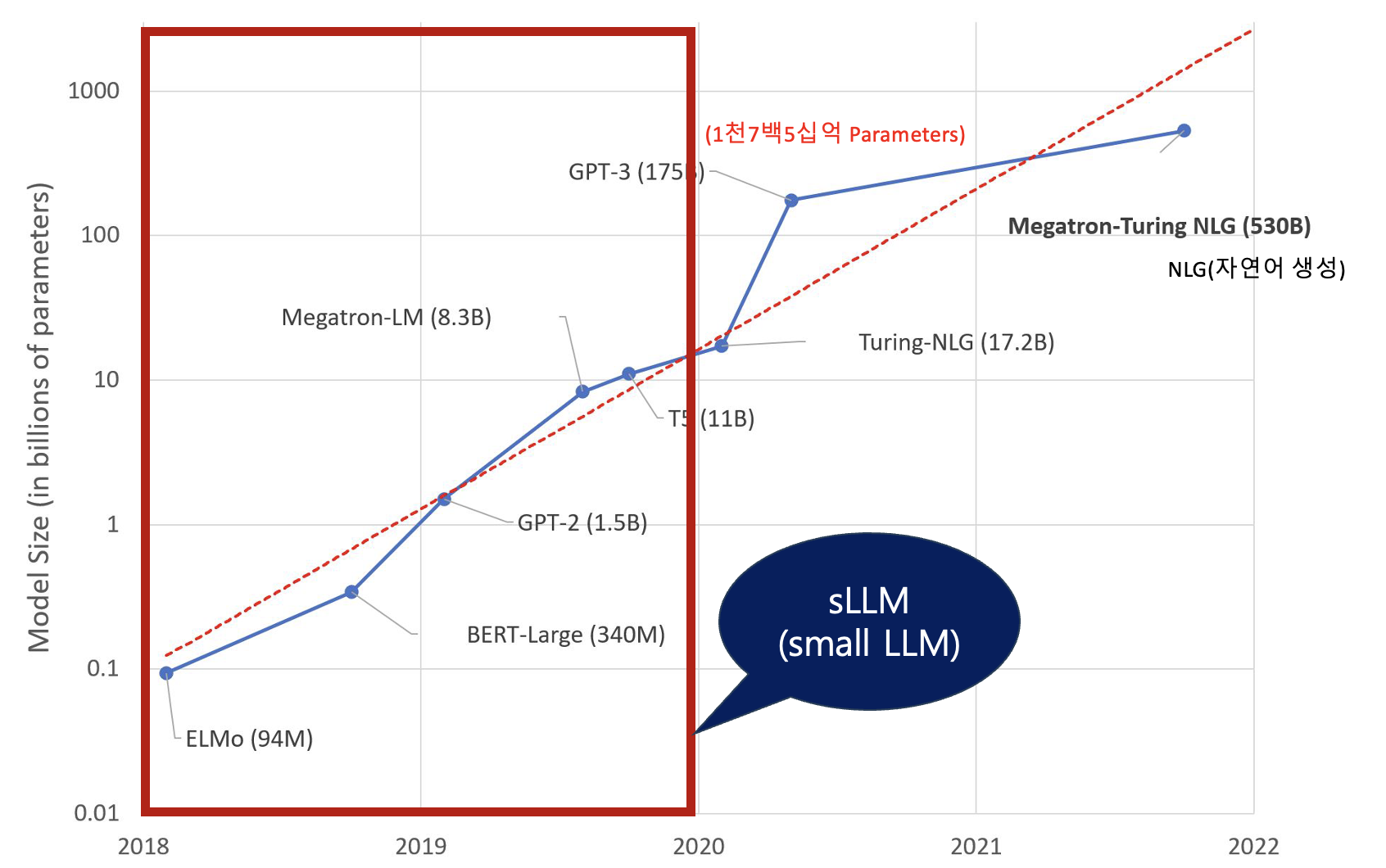
- GPT-3 의 파라미터 개수 : 1천7백5십억 parameters
- 파라미터를 적게 할순 없을까 해서 sLLM 모델들 등장.
- 미리에는 sLLM 쪽이 더 각광 받을 것이다고 예상
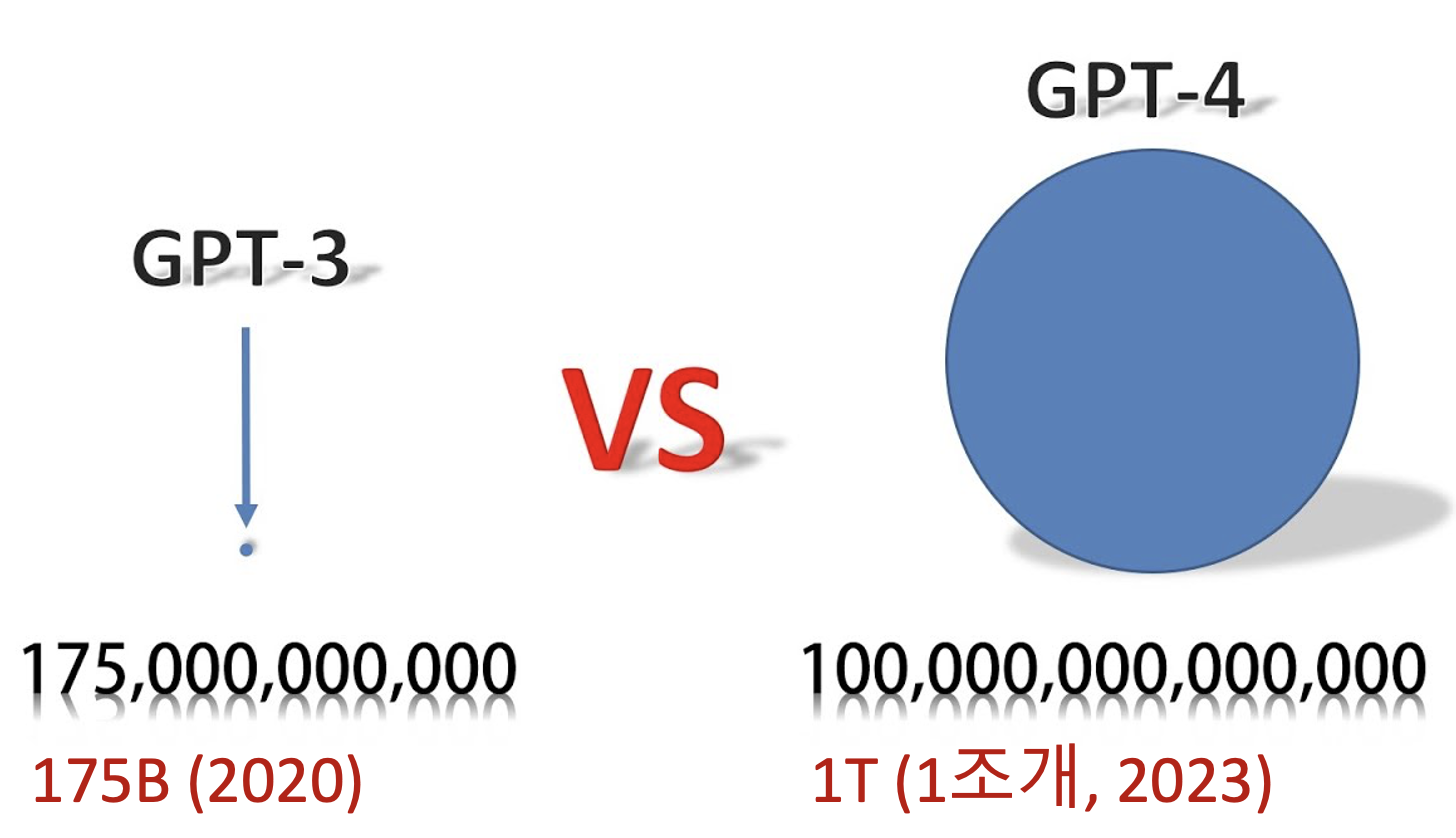
GPT - 3.5
- (175B, 2022)
- GPT-3의 강화학습에 의해 Fine-tunning 시킨 모델
- 기존 모델보다 더 복잡한 명령을 처리가능 (더 길고 고품질 결과물 생성)
- RLHF(Reinforcement Learning from Human Feedback) 기법 사용하여 Fine-tunning.
- 사람이 피드백을 주어 좋은 대답이면 +, 나쁜 대답이면 - 등등 강화학습 기법 사용
- GPT-3 에서의 인간윤리/상식과 반하는 질문 및 답변을 금지시키기 위해서 도입
1조개와 같은 파라미터를 학습시키기엔 엄청나게 큰 컴퓨팅 능력을 요구하므로 자이언트 IT 기업 아니면 GPT-4 와 같은 LLM 을 학습시키기 어려움. 따라서 sLLM 이 더 각광받을 것이다 - 조민호 -
LLM에서의 Fine-Tuning 이 무엇인가
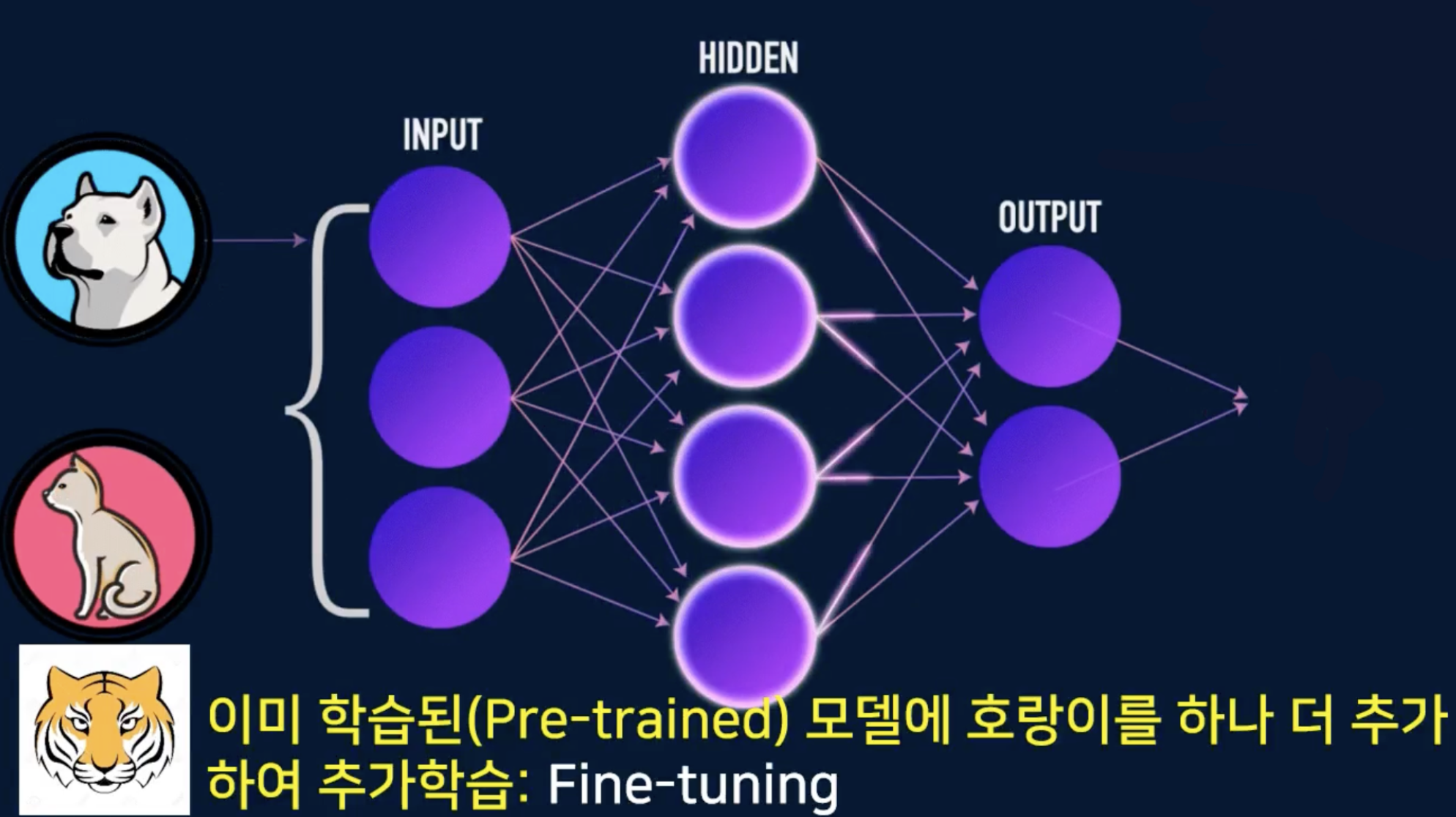
- 이미 학습된(pre-trained) 모델에 호랑이를 하나 더 추가하여 추가학습 : Fine-tuning
- 호랑까지 구별할 수 있도록
ChatGPT
- ChatGPT는 openAI에 의해 개발된 언어 모델 입니다
- GPT 아키텍처를 기반으로 하며(ChatGPT는 GPT-3.5 시리즈의 모델에서 fine-tuned 됨) 대화 컨텍스트 에서 인간과 유사한 텍스트 응답을 생성하도록 특별히 설계되었습니다
- 우리는 무료로 GPT-3/GPT-3.5 기반 ChatGPT을 사용할 수 있지만, GPT-4 기반 ChatGPT을 사용하려면 수수료를 지불해야 합니다
- ChatGPT는 많은 작업을 수행할 수 있습니다
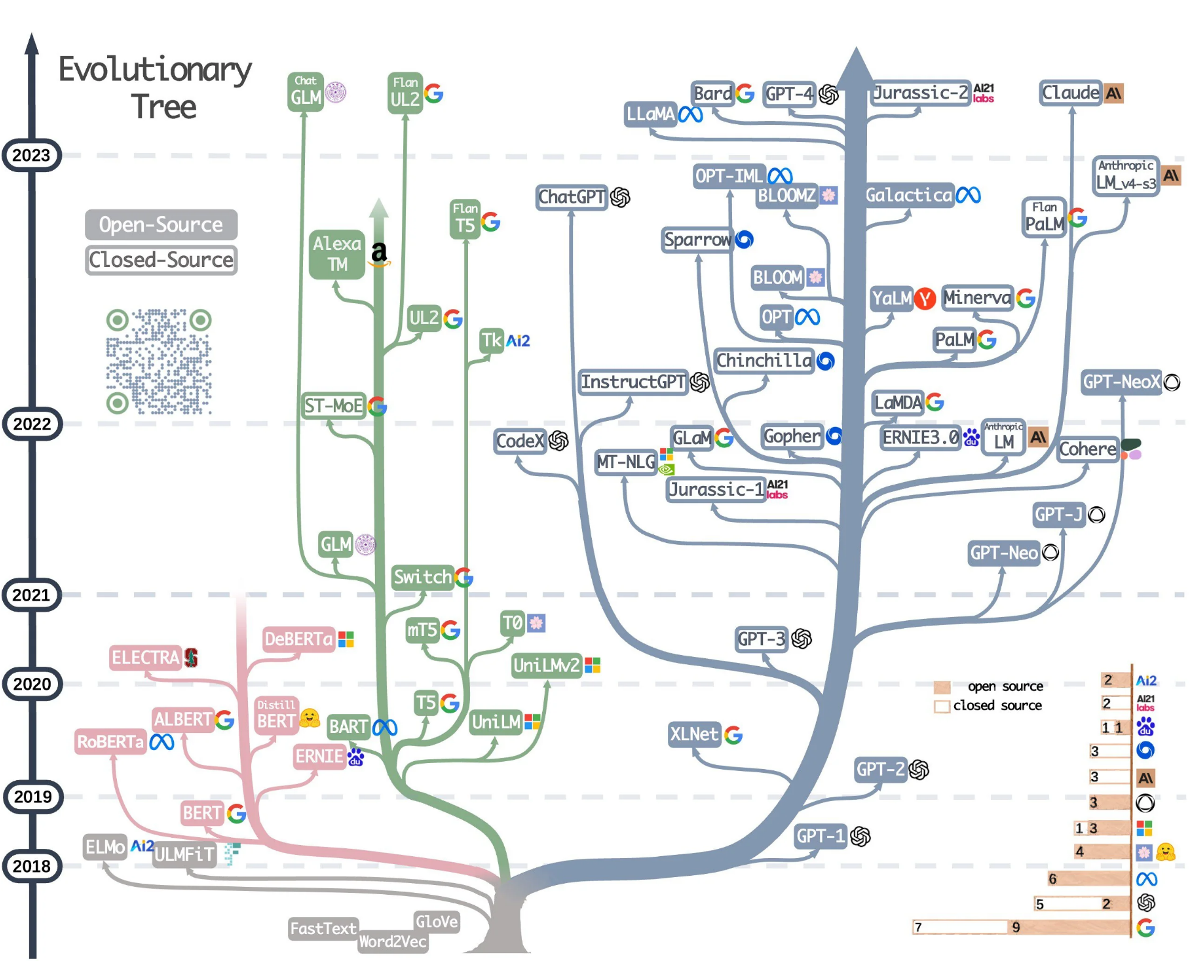
Large Language Model Tree
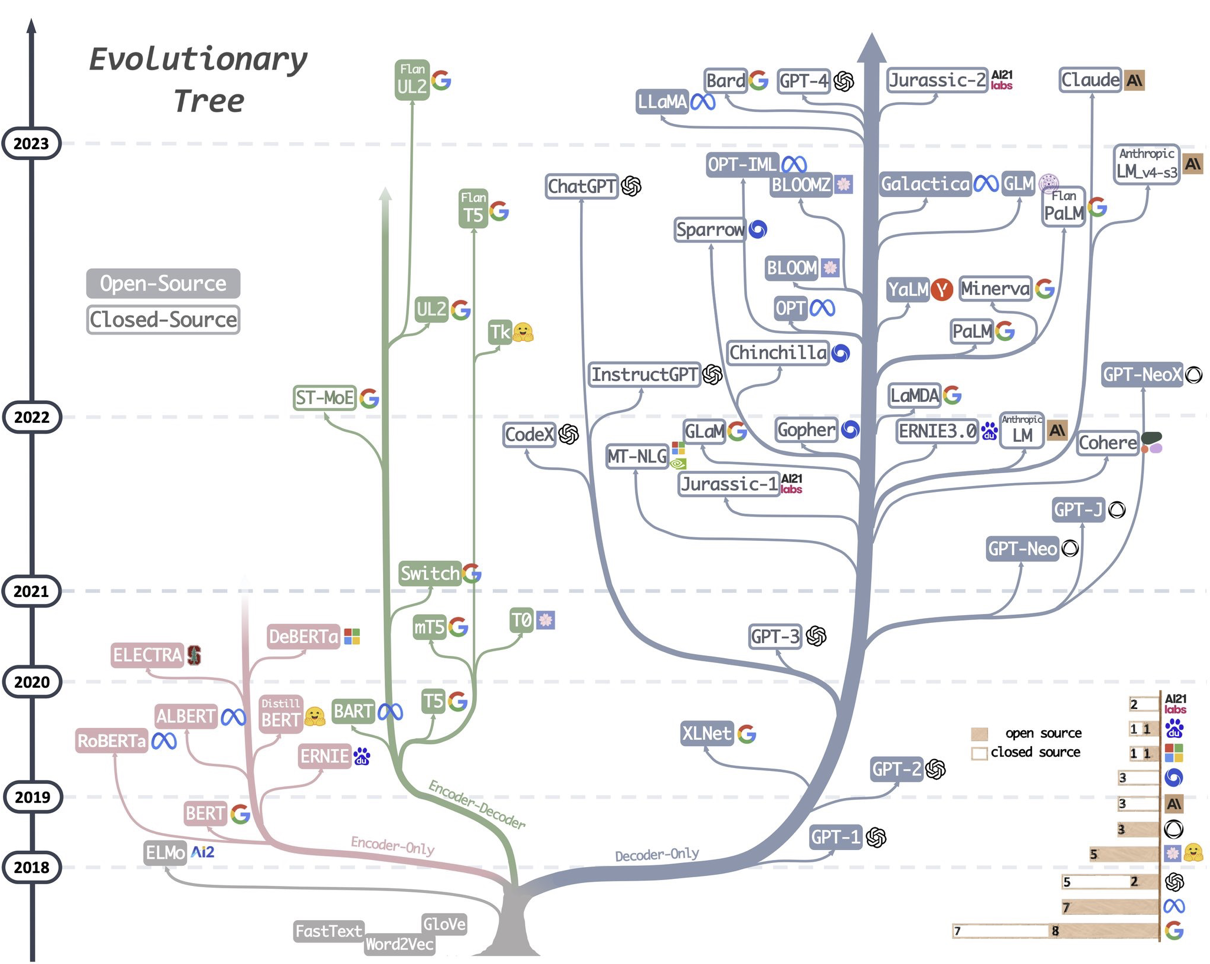
- 트랜스포머(Transformer) 아키텍처 를 기반으로 많은 LLM이 있습니다.
- 트랜스포머 : 인코더, 디코더
- Encoder-only : BERT, ALBERT(BERT 파인튜닝한 것)
- Encoder-Decoder : T5, BART
- Decoder-only : GPT, Meta 의 LLaMA 라는 LLM 모델
- 트랜스포머 : 인코더, 디코더
- 최근 트랜스포머의 디코더 아키텍처를 이용한 LLM이 인기를 끌고 있습니다
- 처음에는 대부분의 회사가 모델을 오픈하지 않았습니다
- 최근에 몇몇 회사들이 그들의 모델을 오픈하기 시작했습니다
- ex) LLaMA(메타), BERT(구글)
ChatGPT Task Example
- ❶ Text Summarization 이 가능하다.
- ChatGPT 는 텍스트를 요약할 수 있다.
- 텍스트는 한 문장 또는 여러 문장 또는 한 단락 또는 여러 단락이 될 수 있습니다
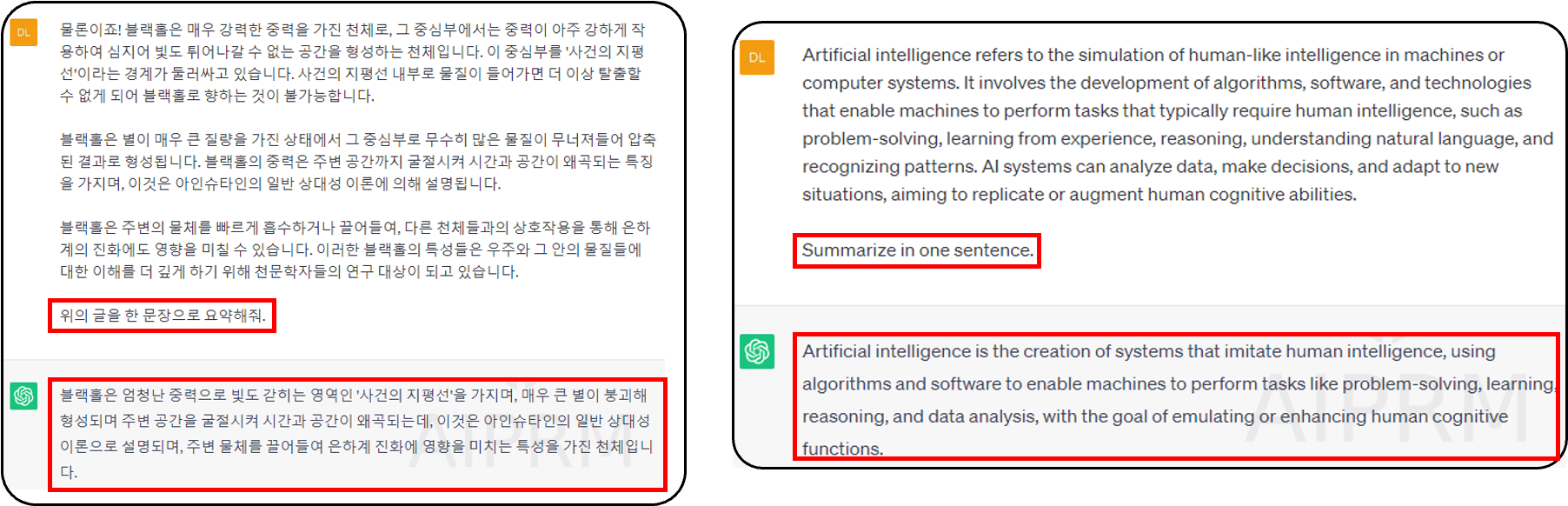
- ❷ Information Extraction 정보 추축 가능
- ChatGPT는 정보를 추출할 수 있습니다
- ChatGPT는 정보를 추출하는 것 외에도 추가적인 내용도 제공합니다
- 대화의 창을 prompt
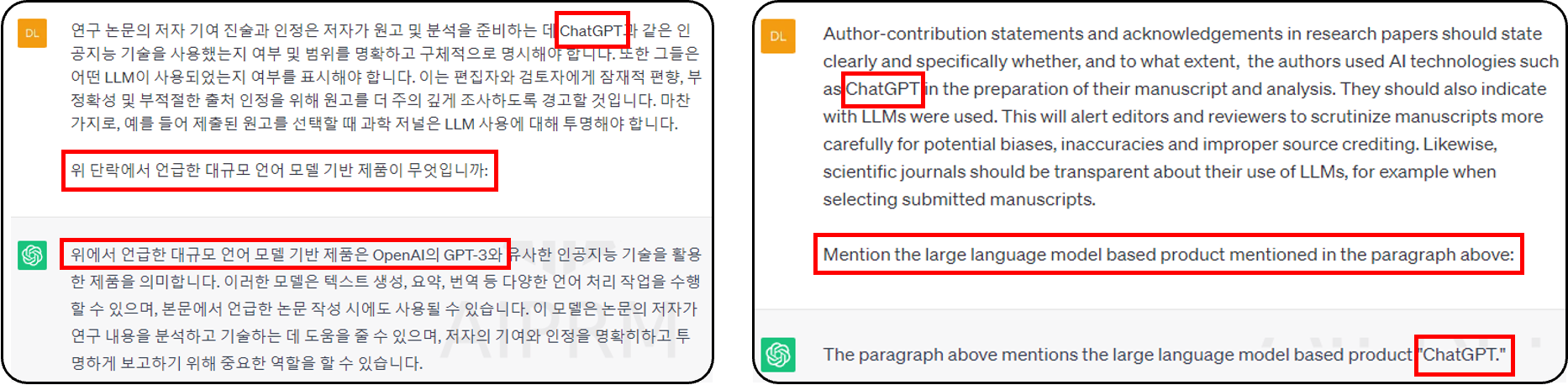
- ❸ Qustion Answering 질문 답변
- ChatGPT는 질문에서 대답할 수 있습니다
- 정보 추출과 마찬가지로, 답변은 프롬프트(질문)에 의해 이루어집니다.
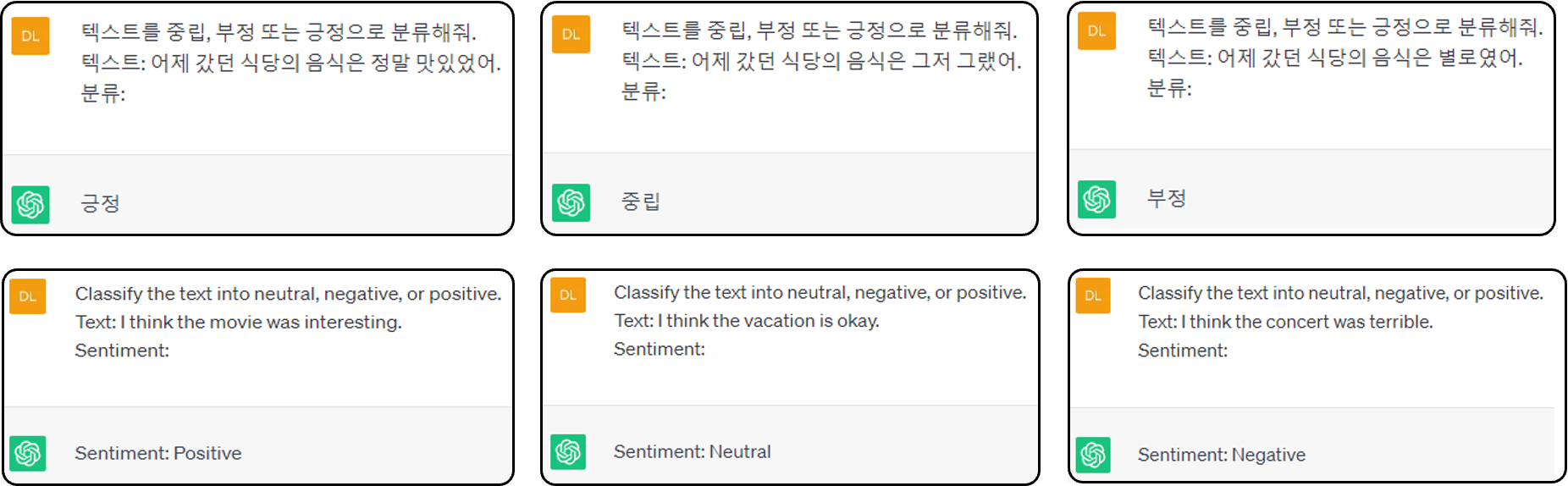
- ❹ Text Classification 텍스트 분류
- ChatGPT 텍스트 분류 작업 가능
- 감정 분석(Sentiment analysis)은 텍스트 분류의 유명한 예이며, 우리는 텍스트를 카테고리로 나누어 분류하는 과제를 줄 수 있습니다.
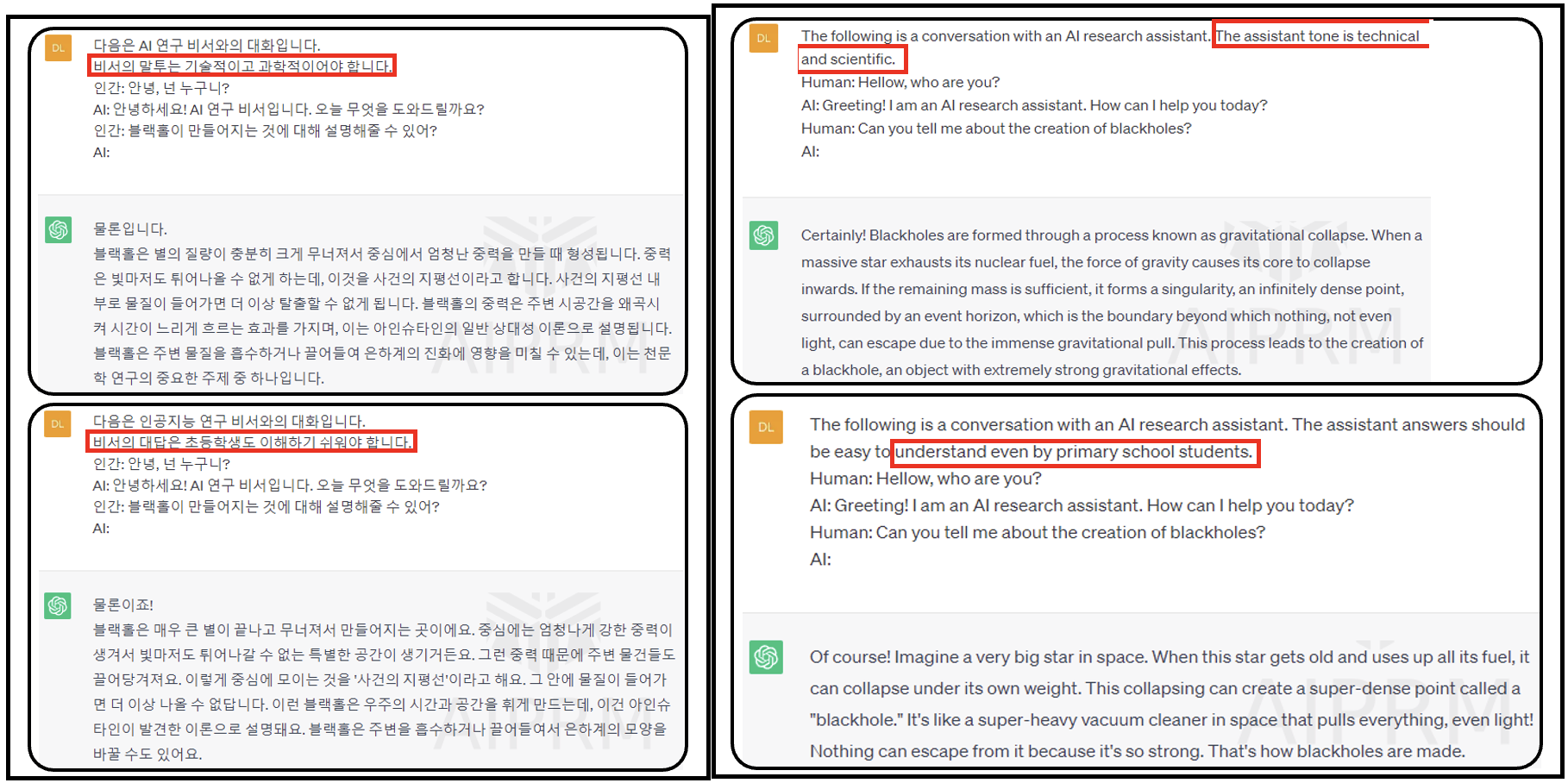
- ❺ Conversation 대화
- 챗봇으로 ChatGPT도 하고 모델과 직접 대화도 할 수 있습니다
- 우리가 챗봇의 역할을 지정하면 출력이 달라질 수 있습니다
- 두 번째 질문의 출력은 더 친근하고 더 쉬운 단어로 쓰여집니다
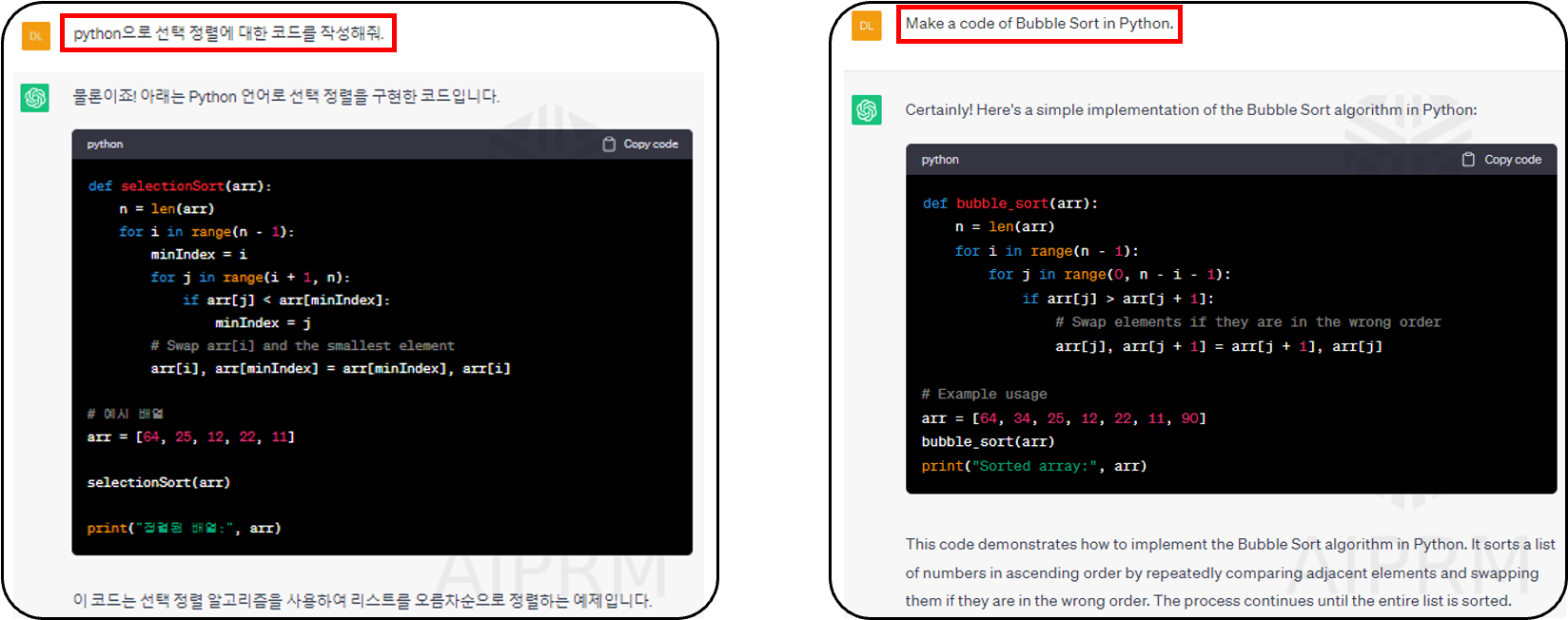
- ❻ Code Generation 코드 생성
- ChatGPT이(가) 코드를 생성할 수 있습니다
- 필요한 코드를 생성하도록 ChatGPT에 지시할 수 있습니다
- ChatGPT는 코드를 다른 프로그래밍 언어로 변환할 수도 있습니다(Python -> C++)
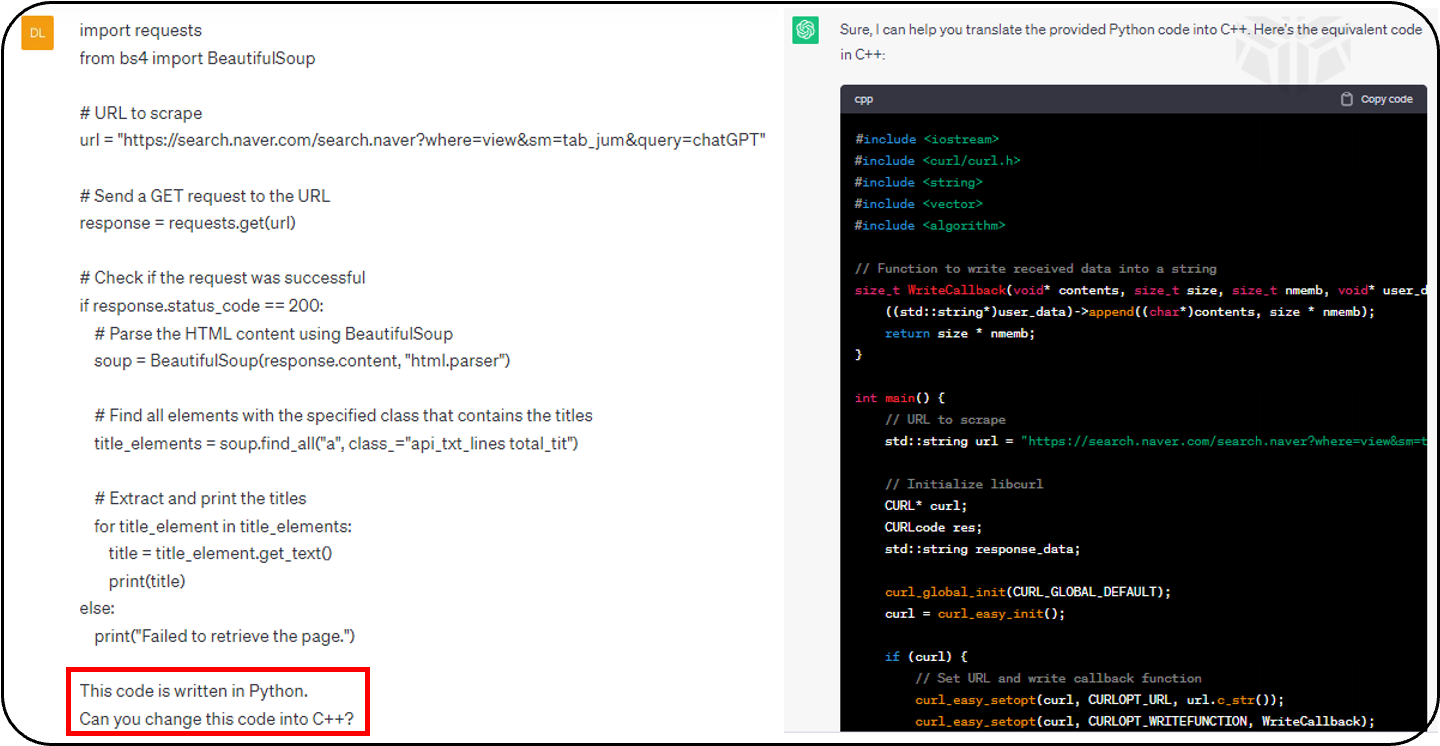
- Python -> R
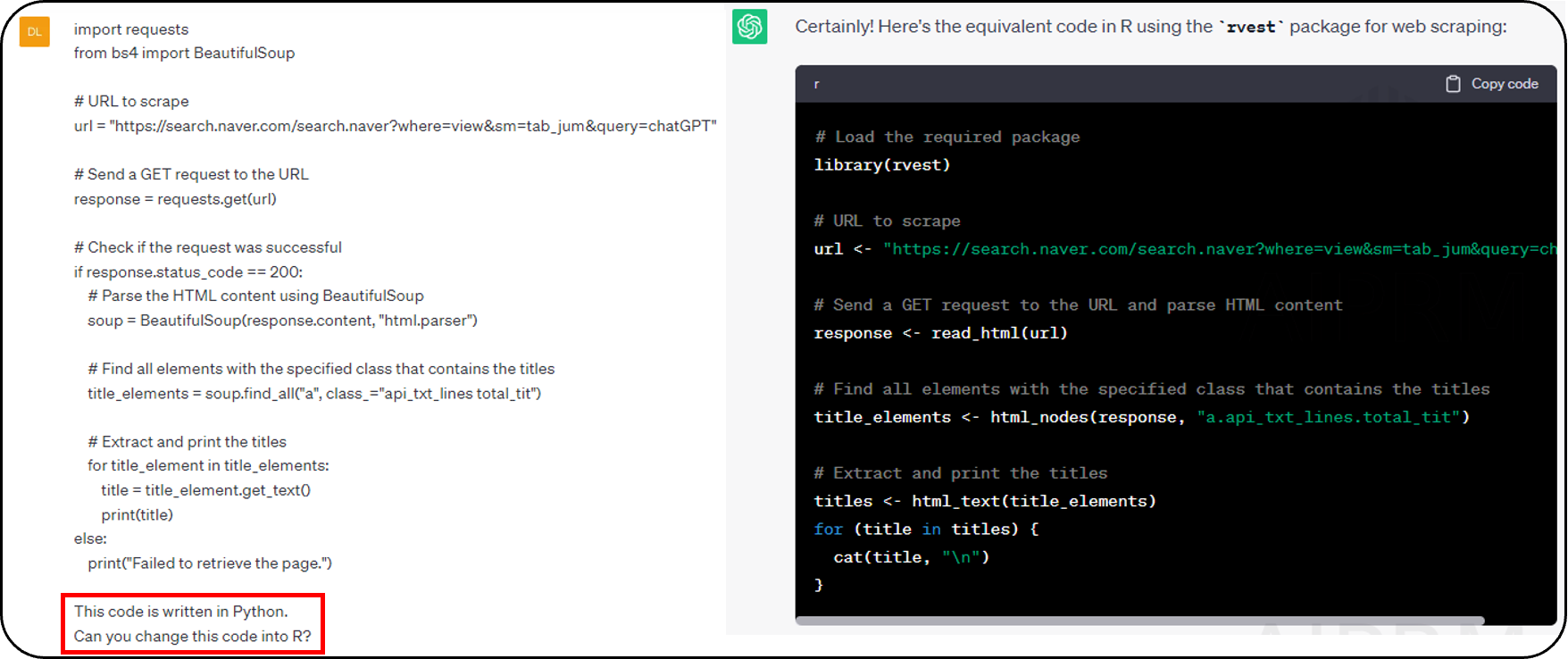
- ChatGPT에서 원하는 결과를 한 번에 제공하지 못하는 경우가 있습니다
- 질문 : 파이썬 라이브러리를 이용하여 검색결과 일부를 삭제하는 코드를 적어줘. 아래의 URL의 제목만 남기고 모두 삭제해줘
- 이 URL의 네이버 검색 결과는 제목이 없다 따라서 Result가 None
- 그럼 ChatGPT에게 추가적인 정보를 줘야겠네요
- 새로 title 을 추천해줌
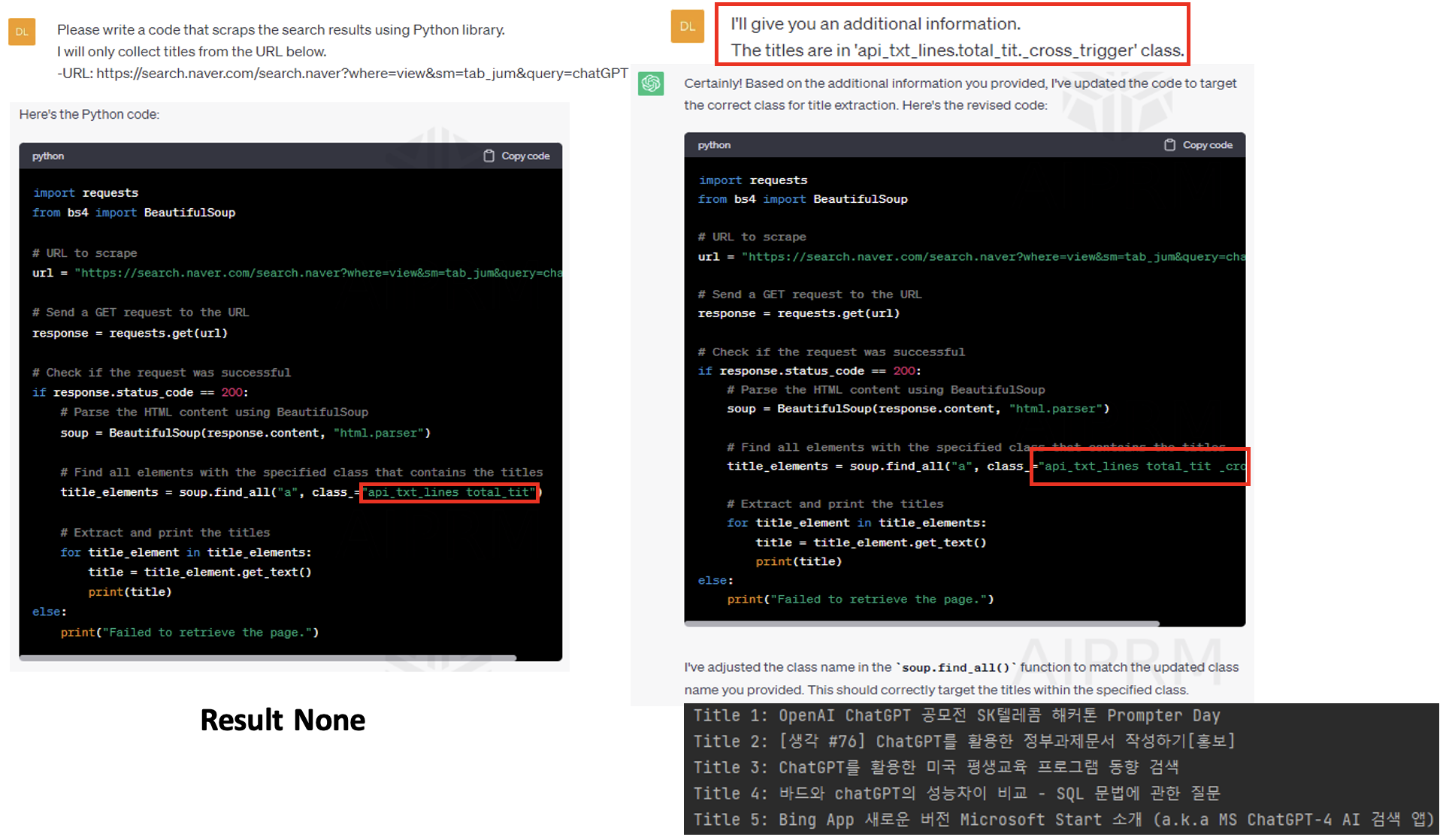
- 새로 title 을 추천해줌
- ❼ Code Interpretation 코드 해석
- ChatGPT 상세하게 코드를 해석할 수 있다. 영어도 물어봐야 정확하다.
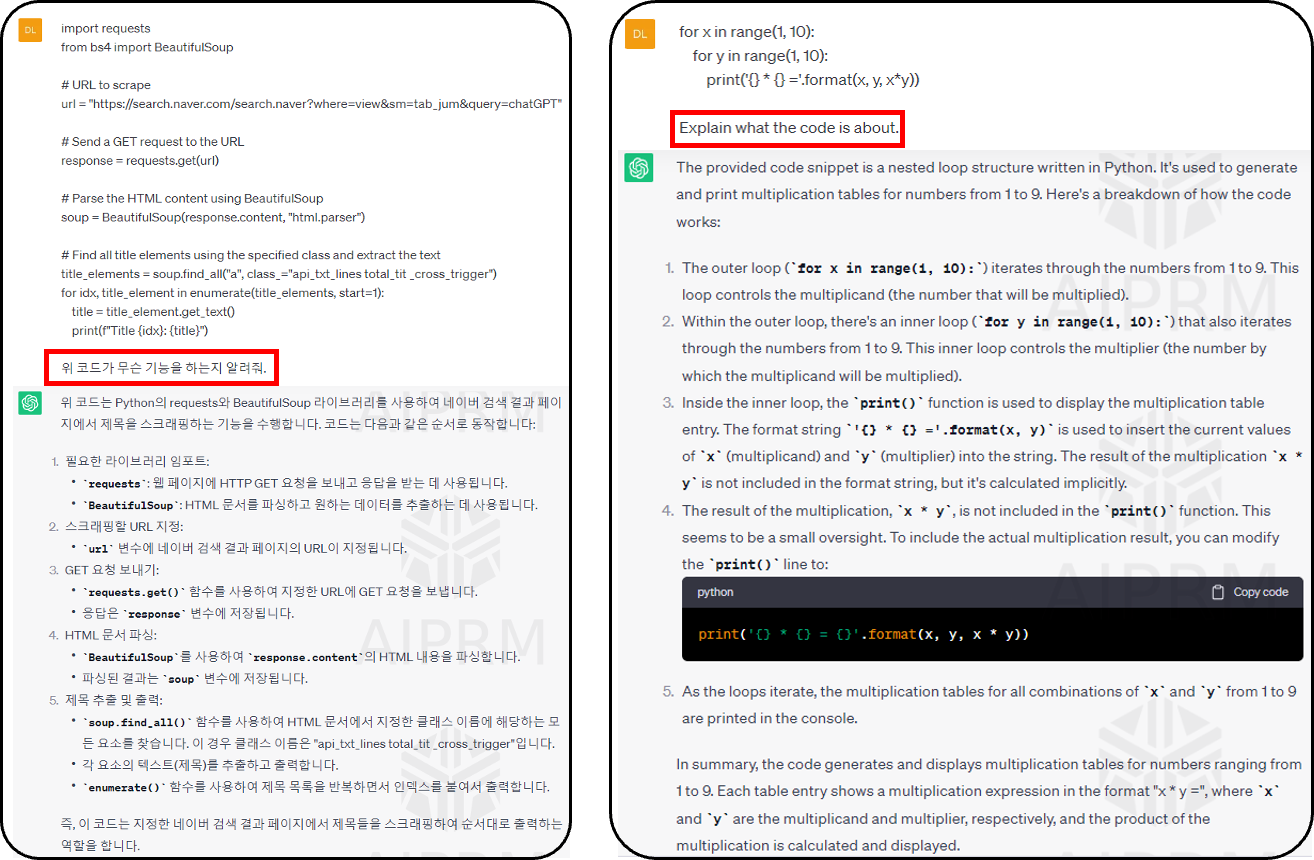
- ChatGPT 상세하게 코드를 해석할 수 있다. 영어도 물어봐야 정확하다.
- ❽ Reasoning (추론, 논리)
- ChatGPT는 추론문제를 풀수있습니다
- 어떤 경우에는, ChatGPT는 추상적인 질문보다는 수학문제와 같이 정해진 답을 가지고 질문을 받습니다
- 몇 달 전만 해도 ChatGPT는 추리 과정을 풀 수 없었습니다
- 하지만 openAI는 꾸준히 ChatGPT이 향상되고 있기 때문에 ChatGPT는 이제 추론 문제를 해결할 수 있습니다

- ChatGPT에게 추가적인 정보를 제공함으로써 우리는 정답을 제시할 수 있는 모델을 만들 수 있습니다
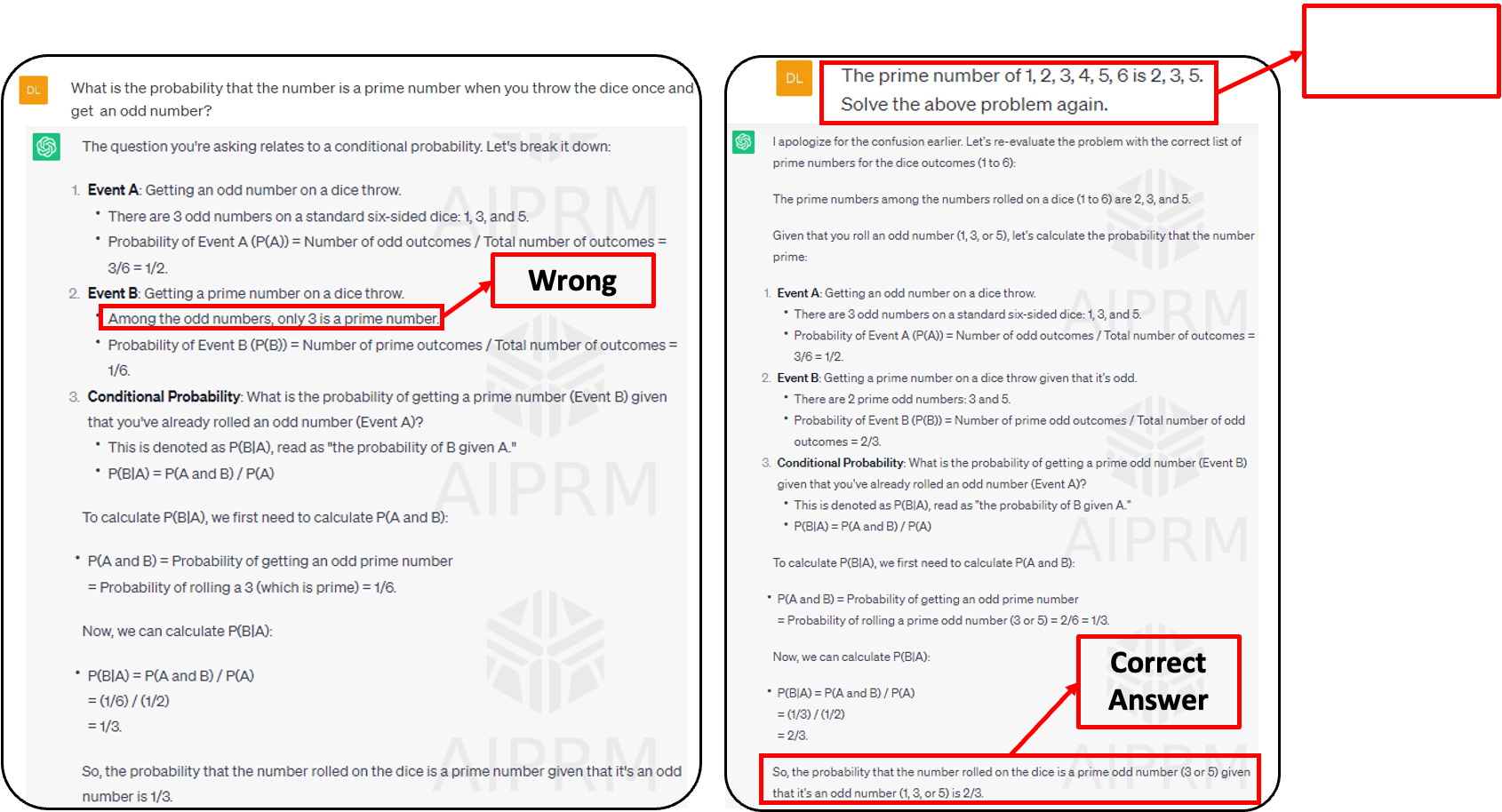
- 질문 : 주사위를 1회 던졌을 떄 그 숫자가 홀수이면서 소수일 확률은?
- Event B가 틀렸기 때문에 답이 틀렸었지만, 다시 질문해서 알맞은 정답을 도출해냄
ChatGPT 의 한계
- ❶ Misinterpretation and Biased Responses (Hallucination. 헐루시네이션 = 그럴싸한 오류)
- ChatGPT는 질문으로부터 답을 만들기 위해 최선을 다합니다
- 그러나 인공지능에서 "헐루시네이션"은 그럴듯하게 들릴 수 있지만 실제로는 부정확하거나 주어진 맥락과 무관한 출력의 생성을 의미합니다.
- 이러한 출력은 종종 AI 모델의 고유한 편향, 실제 이해 부족 또는 교육 데이터 제한에서 비롯됩니다.
- 예를들어 맥아더는 1880년에 태어났고 미국 남북전쟁은 1865년에 끝났습니다
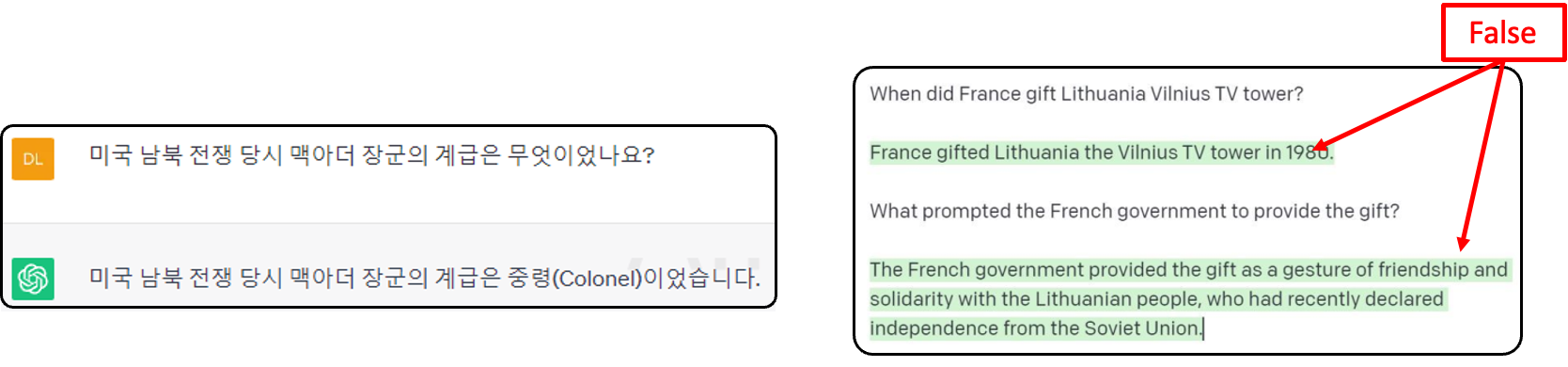
- ❷ Dependency on the train data 학습데이터에 과도하게 의존
- ChatGPT 2021년 9월까지 데이터에 대한 교육을 받았습니다
- 비교적 최근의 사건이나 기법에 대한 답이 부정확함

Prompt 가 무엇인가?
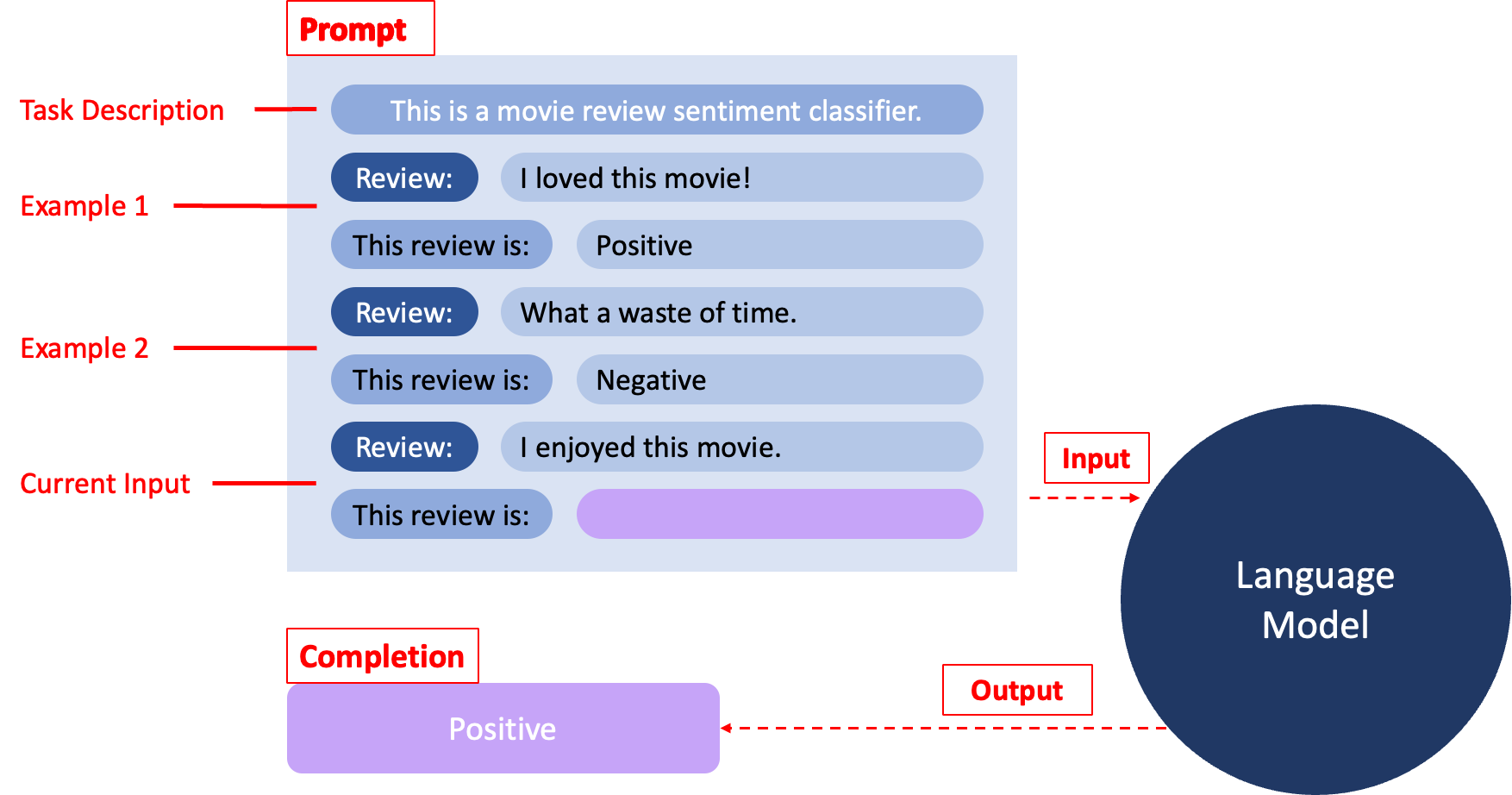
- 어떤 특정한 업무를 수행하기 위해서 입력하는 메세지, ChatGPT 가 응답하여 보여주는 메세지
- 그 의미는 자연어로 언어 모델에 무엇을 해야 하는지 설명하고 원하는 결과를 출력할 수 있도록 하는 방식으로 확장되고 있습니다
왜 Prompt 가 중요한가?
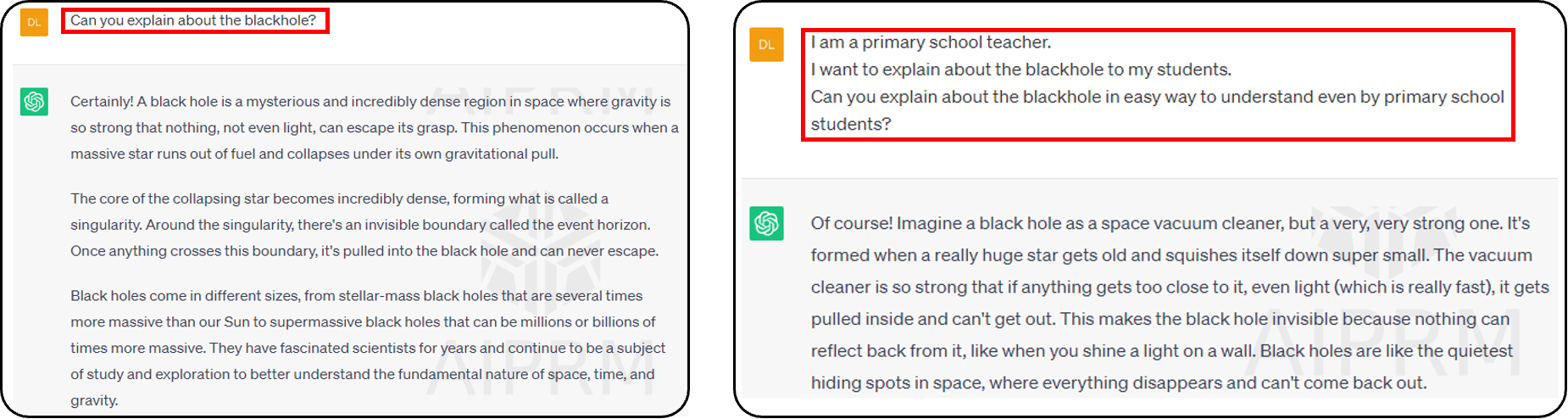
- 프롬프트에 따라 언어 모델과 다른 답변을 얻을 수 있습니다 (어떻게 물어보느냐에 따라 답변이 다름)
- 우리는 두번째 프롬프트의 출력이 우리가 원하는 답변에 더 가깝다는 것을 발견할 수 있습니다(초등학생이 이해하기 쉽게 설명해달라는 프롬프트)
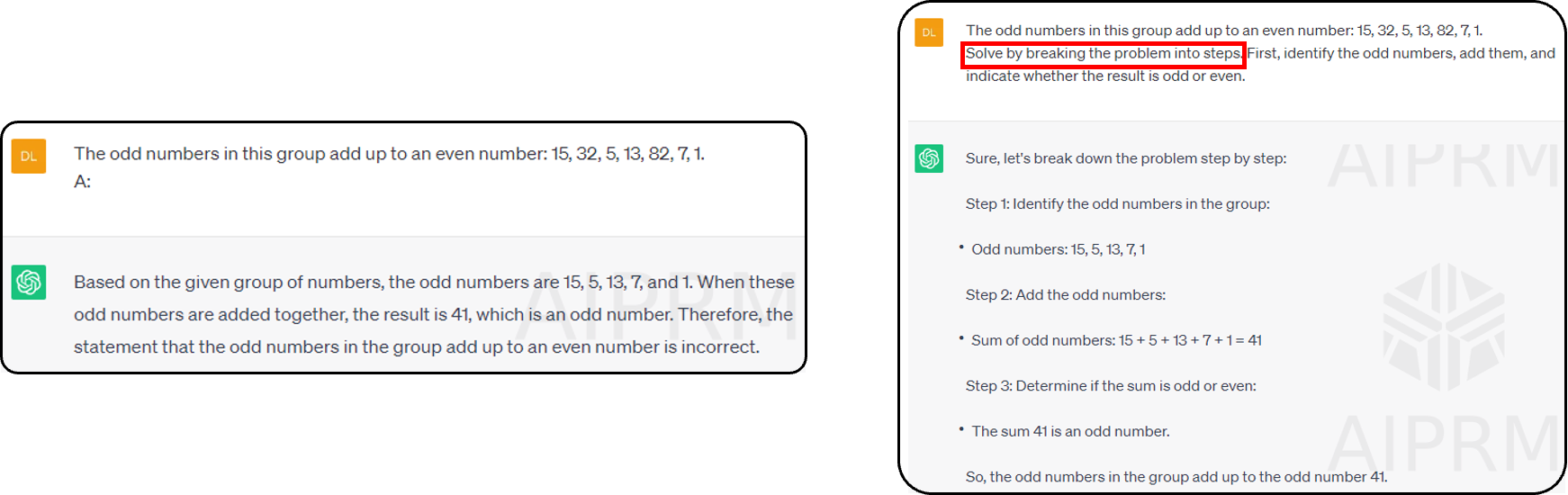
- 프롬프트에 따라 더 명확한 출력을 얻을 수 있습니다
- 우리는 두번째 프롬프트의 출력이 이해하기 쉽다는 것을 알 수 있습니다(이 문제를 step by step 으로 보여달라는 프롬프트)
Chain of Thought(CoT) - For better answers
- Chain of Though(CoT) 사용
- LLM은 수학 문제나 추론 문제를 해결하는 능력이 떨어집니다
- 이을 해결하기 위해, 우리는 단계별로 출력을 만들 수 있는 모델 을 제공할 수 있습니다
- 우리는 '질문-답변'을 주는 대신, 모델에게 'Question(질문)-Solution(푸는과정)-Answer(답변)'을 줍니다
- 우리는 CoT을 이용하여 추론 문제를 해결할 수 있는 모델을 만들었습니다(일종의 fine tuning 이라고 볼 수 있다)
- 9가 정답인데 98이라는 오답을 냄 -> Question-푸는 과정-Answer 을 보여주고 또 다른 질문을 했을떄 위 과정처럼 보여지도록 출력

- 9가 정답인데 98이라는 오답을 냄 -> Question-푸는 과정-Answer 을 보여주고 또 다른 질문을 했을떄 위 과정처럼 보여지도록 출력
Overview of Transformer
- Transformer : 2017년 구글이 발표한 논문 "Attention is all you need" 에서 제시한 언어모델 (Attention: 중요한 핵심 Feature를 최대한 유지시켜 줌)
- 기존의 seq2seq(RNN)의 구조인 Encoder-Decoder 따르지만 논문의 이름처럼 어텐션(Attention)만으로 구현한 모델 (RNN을 사용하지 않음)
- RNN 보다 더 우수한 성능을 보여줌. LLM의 기본 알고리즘으로 각광.
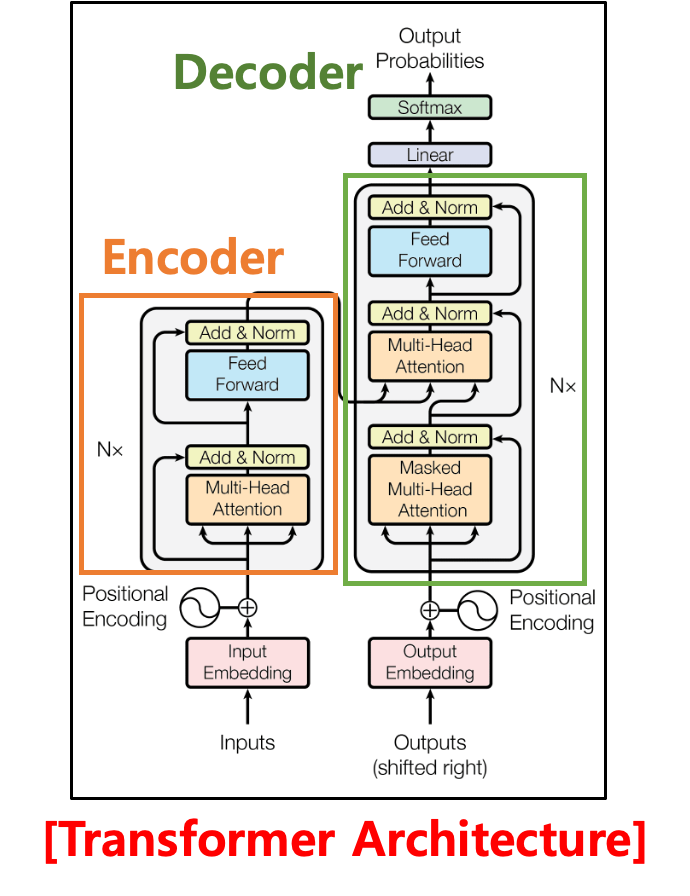
- Encoder
- 입력 정보를 압축 (feature, 핵심 정보는 유지하면서 압축)
- seq2seq (RNN) 의 경우 압축을 시키다 보니 중요한 핵심 feature 들이 손실을 입은 문제를 해결 -> 정확를 높임
- 압축된 정보를 디코더로 전달합니다
- 입력 정보를 압축 (feature, 핵심 정보는 유지하면서 압축)
- Decoder
- 인코더 에서 압축된 정보 가져오기
- 출력생성
- 디코더의 output 인 Embedding 시켜 별도로 입력이 되고, 인코더의 경우 input Embedding 시켜 입력을 시킨다 -> 그 다음 Positional Encoding(단어들의 유치 인코딩)을 시킨 후 Masked-Multi Attention 이라는 알고리즘 적용과 Add & Normalization (더하고 정규화)
- Encoder 에서 온 정보와 함께 Merge 해서 다시 Multi-Head Attention 알고리즘을 거치고 (이전에는 이 Multi-Head Attention 부분을 RNN 을 사용했었다 - 즉, 구글에서 Transformer 라는 구조에서 이 RNN 부분을 Attention 으로 대체했다)
- 그 다음 Feed Forward 과정을 거쳐서 Add & Norm 시키고 Linear 형태로 Output 이 만들어지면 Softmax(확률을 위한 것)
?- 마지막으로 Output Probabilities (어느 단어가 가장 적절하다고 보는지에 대한 확률을 구할 수 있음)
트랜스포머, RNN 기반 인코더 & 디코더를 어텐션 기반 인코더 & 디코더로 변경하여 장기 의존성 문제(long-term dependency problem) 해결
- RNN은 쓰지 않고 어텐션이라는 알고리즘을 사용
Overview of GPT (Generative Pre-training Transformer)
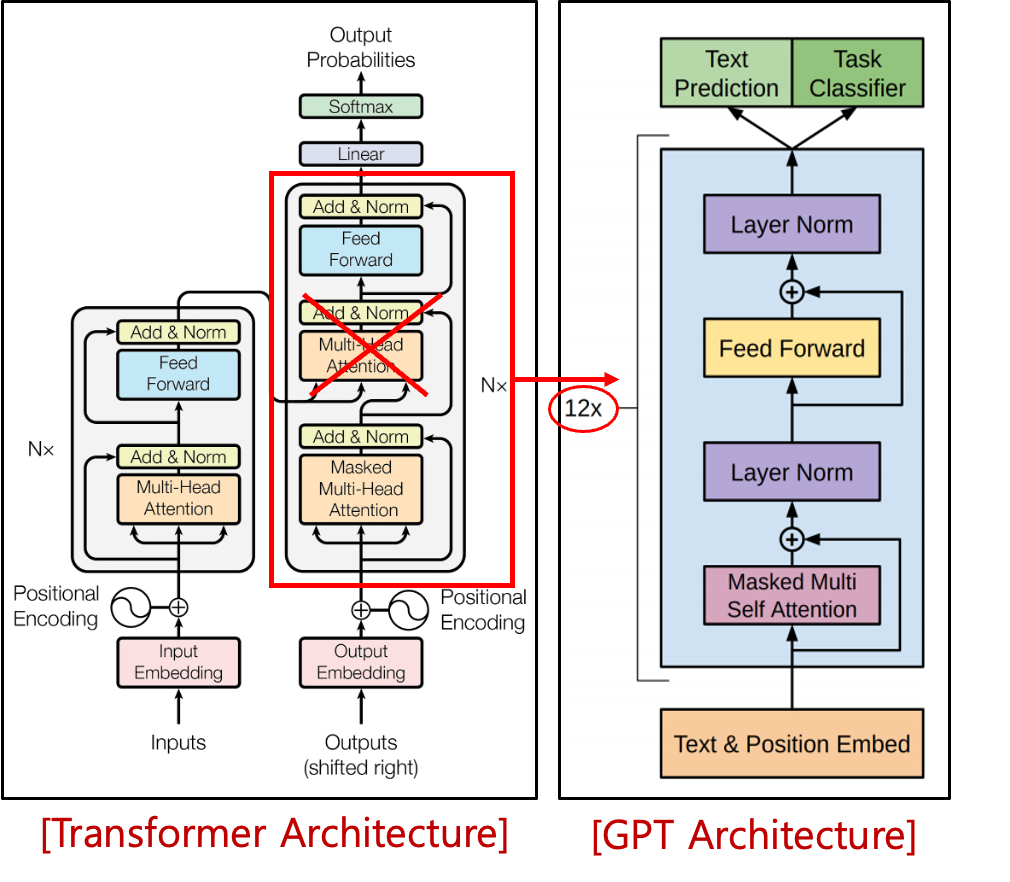
- OpenAI 에서 개발한 ChatGPT 가 비록 구글에서 만든 Transformer 를 사용했는데 변형시킨 것. (구글에서 만든 Transformer 보다 결과가 좋았다)
- GPT는 말 그대로 '자가학습'하여 답변을 '생성'하고 대량의 데이터와 맥락을 처리할 수 있는 '트랜스포머(변환기)' 기술이며 대규모 언어 모델을 기반으로 함
- GPT는 인코더 사용 x, 트랜스포머의 디코더 부분만 사용합니다 (인코더를 Merge 시켜주는 부분을 삭제함 - 빨간색 박스)
- 12개의 디코더를 쌓임
- 훨씬 단조로워 짐(Text & Position, Masked Multi Self Attention, Layer Norm, Feed Forward, Layer Norm -> Text Prediction or Text Classifier)
2단계 교육 및 트랜스포머 아키텍처로, GPT는 Target Tasks 을 이해하고 지도 학습에서 훈련된 최첨단 모델과 동등하거나 심지어 더 잘 수행하기 위해 매우 적거나 전혀 예를 필요로 하지 않습니다(targets.지도학습 불필요)
- 세상의 모든 Text 들이 label 되지 않은 상태(즉, target 이 없는 상태)인데 이를 supervisor(Teacher) 가 가지고있는 정답지 없이 그냥 입력되는 형태 (unsupervised 형태이다)
- solution 을 구하는 종류에 따라서 이러한 ChatGPT 의 아키텍처를 변형시키는 것 없이 input 부분(Text & Position Embed)의 형태만 변형시키도록 함. (매우 편리함을 제공)
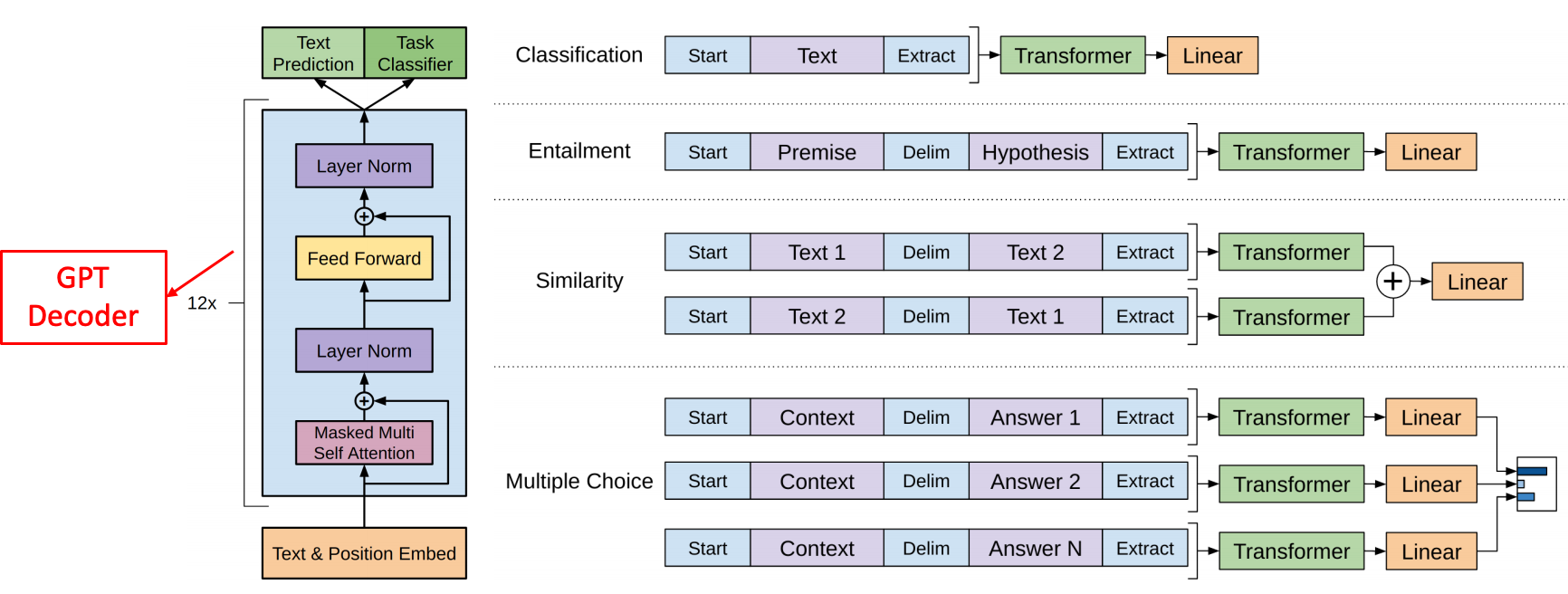
- Classification 문제라면,
- Text 를 입력해서 Transformer(GPT) 를 거쳐서 Linear 가 나오고 softmax 구하고 확률 구하고
- 입력형태 : Start(텍스트의 시작), Extract(텍스트의 끝)
- Entailment
- Premise(가정이 될만한 상황), Delim(구분자), Hypothesis(가설) 의 입력형테를 가지며 -> Transformer 를 거쳐 어떤 가설이 확률이 더 높은지 계산
- Similarity
- Text1 과 Text2 가 같은지, 정확도를 위해 자리 바꿔서 Text2 Text1 가 같은지 다른지 확률을 구한다.
- Multiple Choice
- 어떤 Context 가 있다면 Answer1, Answer2, AnswerN 중 어떤 Answer 가 확률이 높은 Answer 인가를 계산
- Classification 문제라면,
- 이전에 사전 교육을 받은 모델(pretrained model)은 미세 조정(fine-tuning)을 위해 아키텍처를 변경해야 하며 사용자 정의 프로세스(customizing process)가 많이 소요됩니다
- GPT는 아키텍처를 변경하지 않고 단순히 입력의 구조를 변환 합니다
Evolutionary Tree of LLM and sLLM