
GPT 가 원래 출발했던 그러한 알고지름 매커니즘이 있는데, 그것을 Traditional Languate Model by Seq to Seq 라고 부르기도 한다. RNN 이 기반이 되어서 그동안의 전통적인 LM 을 구사해왔다.
GPT는 이러한 사전 연구로 부터 출발했다는 것이다.
CH2
Recurrent Neural Network (RNN)
- Sequence Model
- 입력: Sequence Input(, , ..., )
출력: Sequence Output (, , ..., ) - ex)
입력 : 질문, 출력 : 답변 --> 챗봇 모델
입력 : 문장, 출력 : 번역문 --> 기계번역 모델
- 입력: Sequence Input(, , ..., )
- 입출력 중간에 어떤 프로세스를 거친다
- 그것이 바로 메모리 셀(Memory Cell): 이전 값을 기억하는 일종의 메모리 역할을 한다.
- 이 메모리 셀을 구성하고 있는 function 은 동일한 함수(LSTM)를 사용한다.
- recurrent : 내 자신의 함수를 다시 한번 부르는 식의 원리로 동작하므로 Recurrent Neural Network 라 부른다.
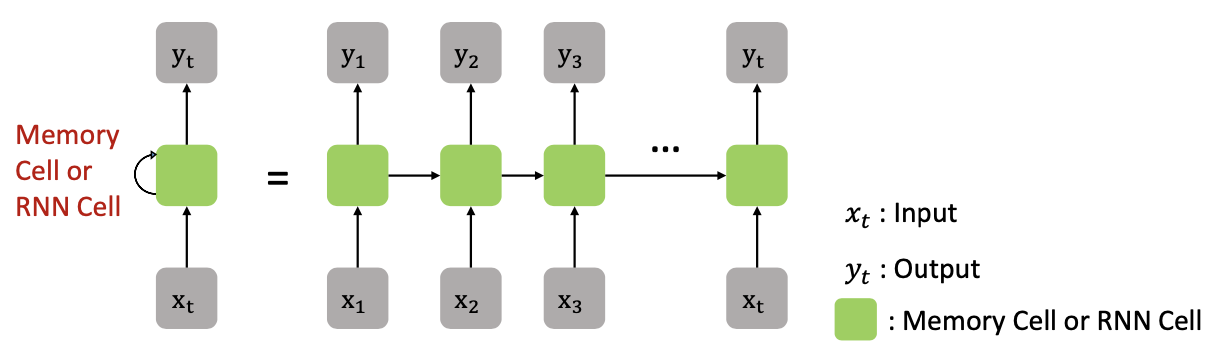
- 각 셀은 이전 셀의 값을 재귀적으로 사용합니다 (하나의 function 을 가지고 t만 바꿔가며 나 자신을 변경시키는)
- 시간 t에서의 메모리 셀의 값은 과거의 메모리 셀의 값에 영향을 받는다 는 것을 의미합니다
- 메모리 셀이 가지고 있는 값, 우리는 그것을 hidden state 라고 부릅니다
Type of RNN
- 입력, 출력의 사이즈는 특정 목저에 따라 다르게 설정할 수 있다.
- One to Many
- Image Captioning : 하나의 이미지를 입력 해, 에를들어서 자동차가 부딛히는 사진,... 의 출력 중 가장 확률이 높은 것 선택
- Many to One
- 영화를 예시로, 여러 사람들의 의견을 반영해 이것을 슬픈 영화다 라고 장르를 구분
- 여러 사람들이 스탬으로 신고를 하면 결론을 이게 스팸이냐 아니냐 구분
- "나는 오늘 기분이 짙은 구름 처럼 늘어져있다" 라는 sentence 가 입력으로 들어가서 "오늘 우울하시군요" 이런식으로 출력도 가능
- Many to Many
- 입력이 질문인 경우, 출력이 답을 주는 경우
- 챗봇
- 개체(Object) 인식 : 문장에서 각각의 단어를 가지고 팀 이름, ,., 의 개체로 분류
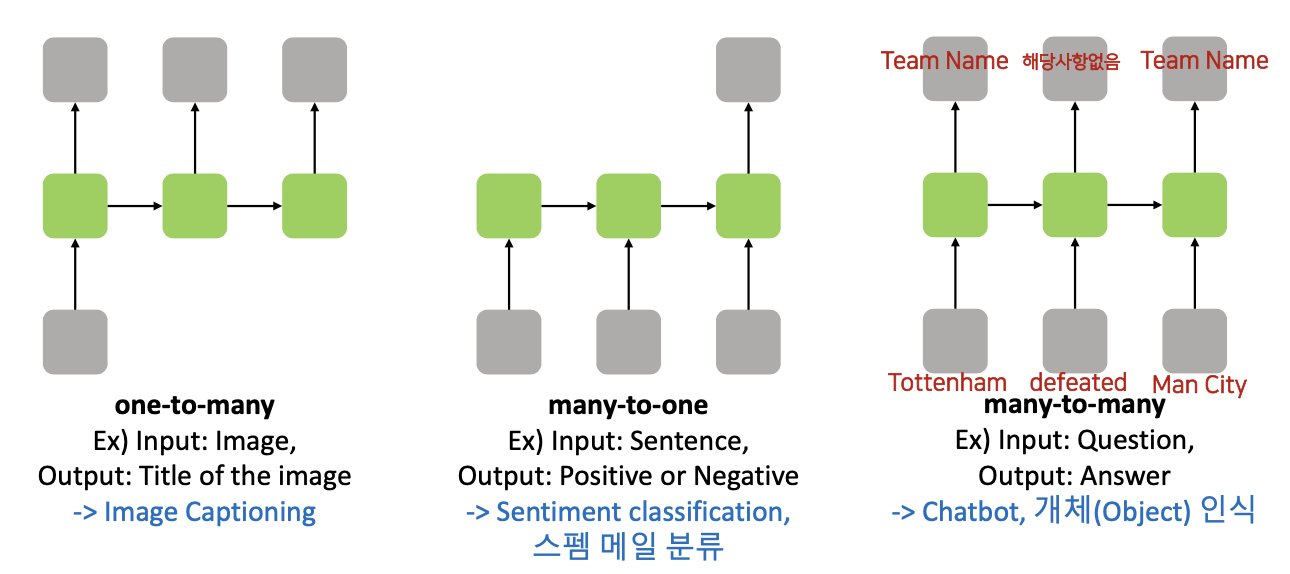
- One to Many
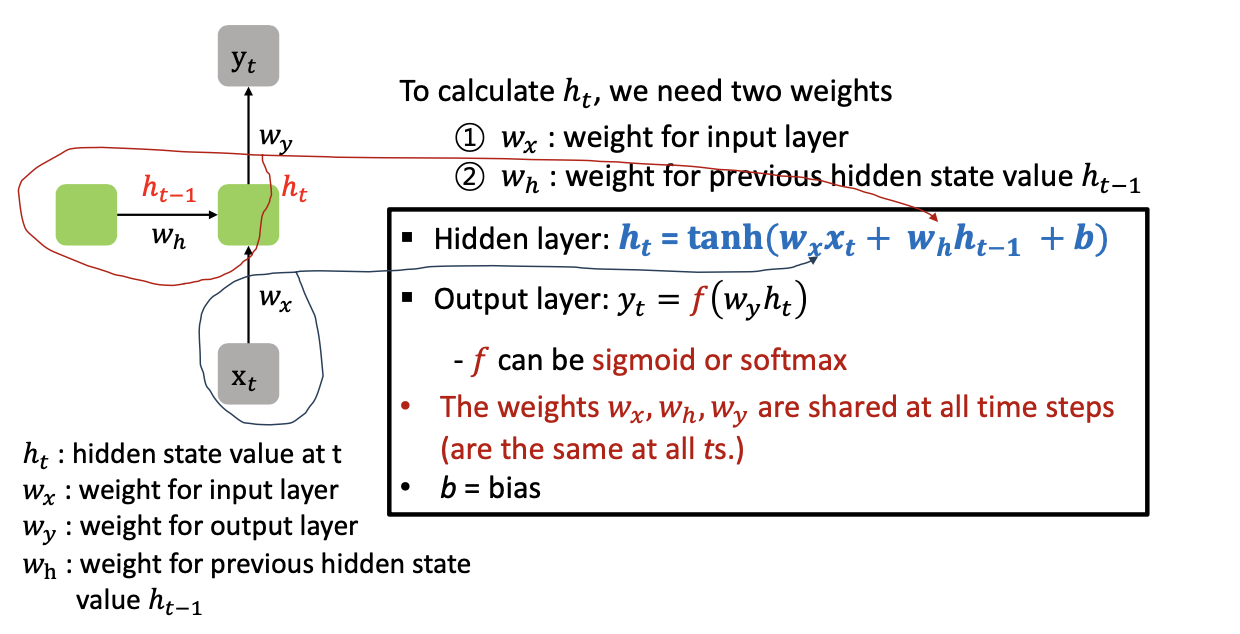
RNN with Numerical Example
- Hidden layer : 현재의 hiddens tate =
- 이전의 메모리 셀에 있는 에 weigit 값 곱
- 새로운 Input 에 weight 값 곱
- bias(0 이 되는 것 방지)
- 합에 tanh 넣은 결과가
- Output layer :
- 는 활성함수 (시그모이드, 소프트맥스)
- 일반적인 딥러닝과 다르게 모든 의 weight 값들이 시점에 상관없이 모든 t 스텝에서 동일한 w 값을 사용한다. (중요)
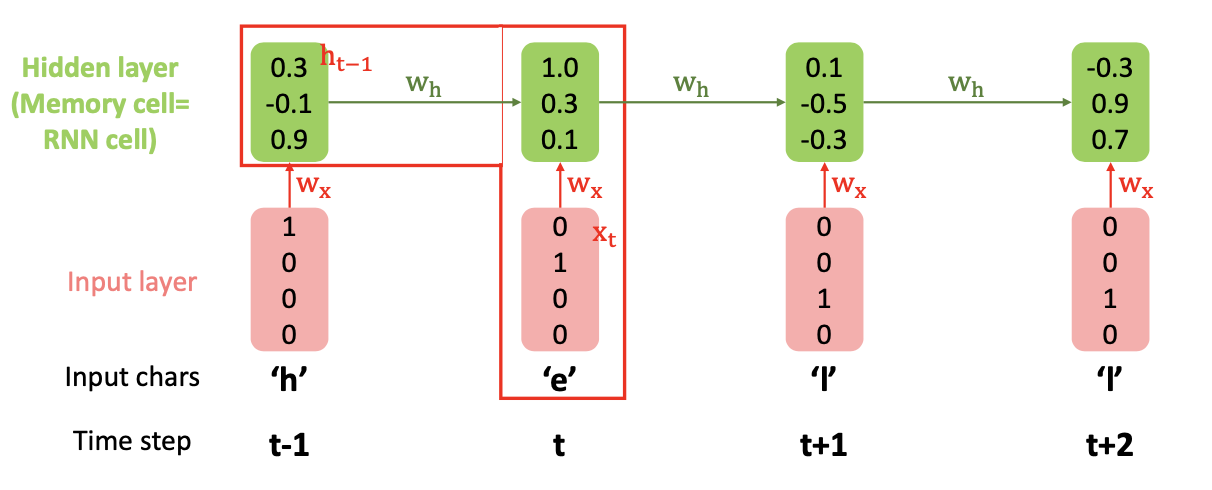
RNN with Numerical Example
- Hidden layer : = ( } + )
- h 라는 인풋이 들어가고 모범 답안 target 과 비교해서 그 다음에 들어갈것이 무엇이냐 (t-1)
- e 가 인풋으로 들어가고 다음 들어갈 문자는 무엇인가(모범답안은 t 시점에서 l 일것)
- 이런식으로 RNN 동작
RNN with Numerical Example
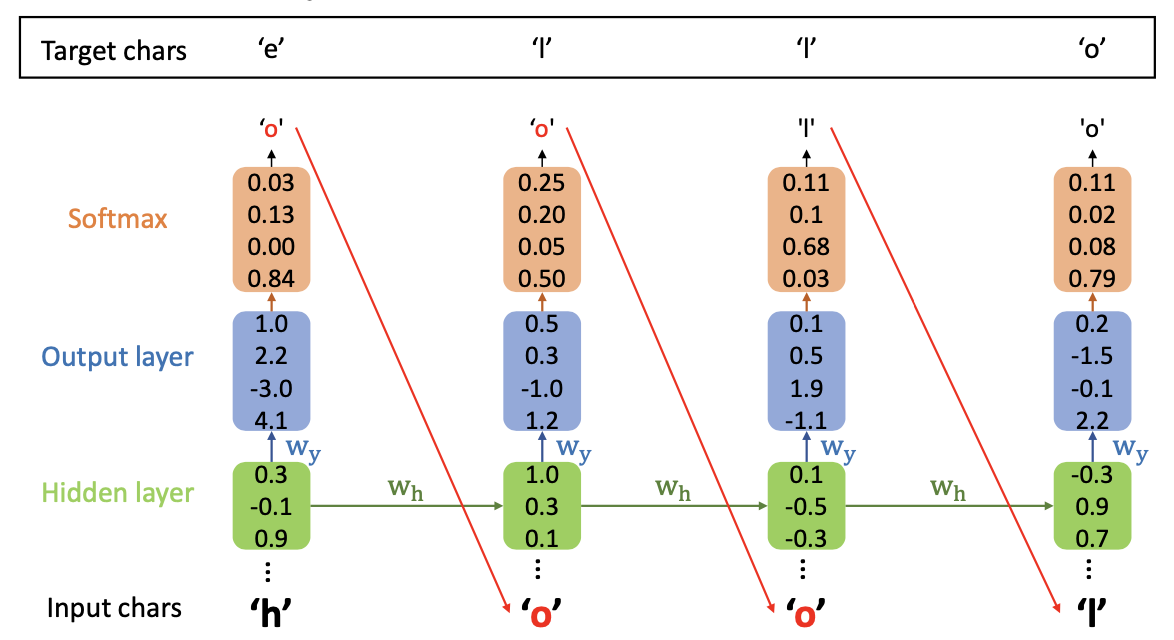
training process
- , at training process
- h 가 입력으로 주어지고 타켓 캐릭터가 ello 로 제공되어있는 상태
- Ouput 을 softmax 를 이용하여 확률값으로 계산하고 높은 확률 값을 가지는 캐릭터 o를 결과로 반환함 (타겟과 다른 값)
- 다음 단계에서는 이전 단계의 target 값을 넣어주고 이 과정을 반복하면 hidden state 를 변경시켜주고 하지만 각각의 깂은 동일함 (일반적인 딥러닝에서는 값을 업데이트해준다)
- 그렇다면 훈련이 덜 되어 반환한 "o" 라는 결과값은 어떻게 해야할까?
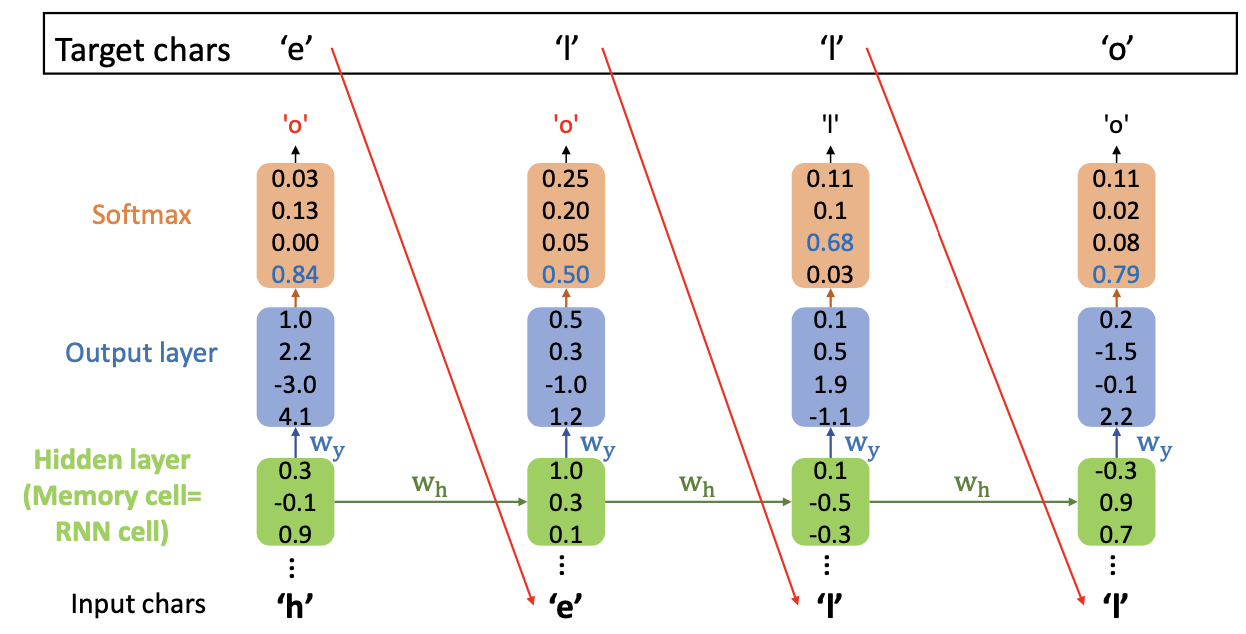
test process
- , at test process
- 이떄는 target 값을 input 으로 넣는 training process 와 다르게 매번 Iteration 될떄 나오는 그 결과("ㅐo") 를 input 으로 넣어줌
- 최종적으로 원하는 결과가 나오는지 테스트 하는 과정이다.
Sequence-to-Sequence (seq2seq) by RNN
- RNN 의 구조는 seq2seq 이다.
- 입력 시퀀스에서 다른 도메인의 시퀀스를 출력합니다
- Ex) 기계번역
- 입력 순서 : 영어 문장, 출력 순서 : 프랑스어 문장
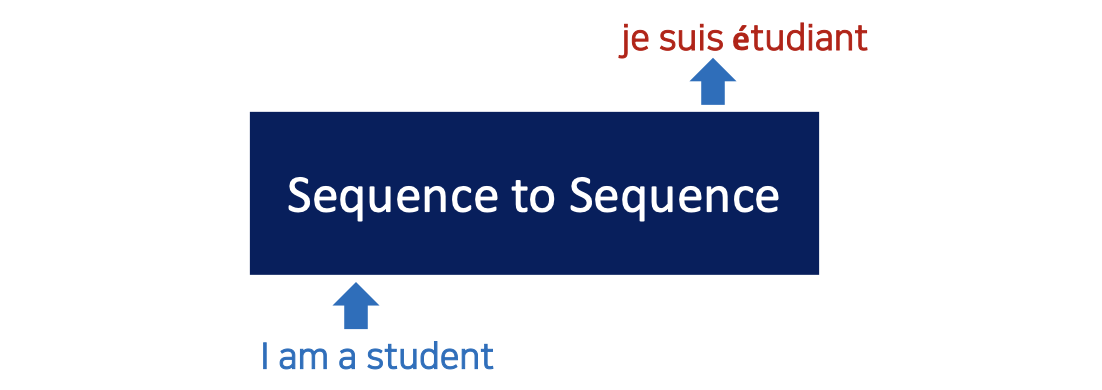
- 입력 순서 : 영어 문장, 출력 순서 : 프랑스어 문장
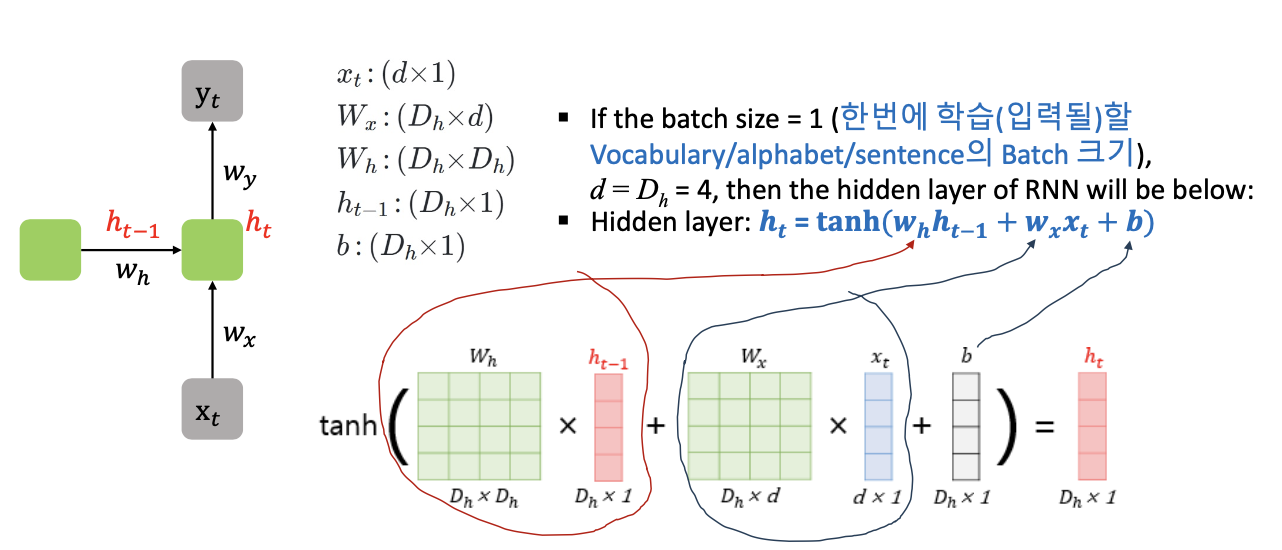
Calculation of # Parameters in RNN
- 파라미터 사이즈는 정해져있다 (하이퍼파라미터에 해당)
- 한번의 학습할 Vocabulary 의 Batch 크기는 1
- 로 가정 : 입려 벡터의 크기가 4x1 이다.
- 차원을 계산
- , 쪽과 , 쪽은 서로 독립적으로 존재하기 때문에 값들 더해주고()
- 그렇게 게산된 , 또한 독립적이기 때문에 마지막에 더해주어 의 Ouput 이 나오게 되는데
- 이 세개를 더해주는 것이 총 파라미터 개수가 된다.
- 최종적으로 차원은
문제
1, 2)
- 아래의 단계들은 모두 독립적이므로 덧셈 (Total : 529441)
-
- 메모리 셀의 크기를 128 로 했다는 소리는 그림에서 보이는 , 의 차원이 차원이라는 뜻이다.
- 의 크기도 차원을 맞춰줘야 하기 떄문에 강제로
- bias 크기도 마찬가지로 강제로
- 마지막 Ouput 으로 가는 weight 인
- bias = 1
-
3) 훈련에 사용하는 모든 샘플의 길이는 30으로 가정합니다.
- 30이 파라미터 계산하는데에는 관여 x
모든 t 에서 동일한 weight 값을 사용하기 때문에 즉, 입력 샘플의 길이가 어떤 값을 가지든지 상관없이 weight 의 개수가 동일하게 고정되어 있기 때문에 파라미터 개수를 구하는데에는 샘플 길이가 직접적인 영향을 미치지 않는 것 같다.
Sequence-to-Sequence (seq2seq)
- 인코더
- 모든 단어를 순차적으로 받는다
- 이 모든 단어 정보를 벡터(Context vector)로 압축합니다
- 4x1 크기의 벡터 : I am a student 라는 문장을 숫자로 압축시켜 간단한 4개 짜리의 벡터로 만듦
- 디코더
- 번역된 단어를 context vector 로 순차적으로 출력
Sequence-to-Sequence (seq2seq)
- Tokenizing : 문장을 단어로 토큰화 분리
- Word Embedding : 분리된 단어를 Embedding vector 로 변환
- 예를 들어서 Hello 라는 입력에서 H 는 1000, e 는 0100, ㅣ 은 0010 이런식으로 벡터로 암호화하는 것이 Embedding
메모리 셀 계산
- 인코더
- LSTM 은 매모리 셀의 function 중 하나이며, t 별로 순차적으로 배치가 되어있다.
- 이러한 값들이 Context vector 로 압축되어 나온다.
- 디코더
- 이전의 정보(Context vector 가 previous hidden state 의 역할을 한다.)를 Decoder 가 받는다
<sos>(start of sequence 토큰) 을 시작으로 I am a student 에 맞서는 정답 je suis etudiant 가 입력이 된다.- target 의 의미 : "시작하는 부분서는 je 가 답이 되어야 합니다."
- "je" 가 다음 시퀀스의 입력 -> "je 다음에는 suis 가 와야 합니다" ...
<eos>(end of sequence) 를 마지막으로로 "마지막입니다" 를 의미하도록 함.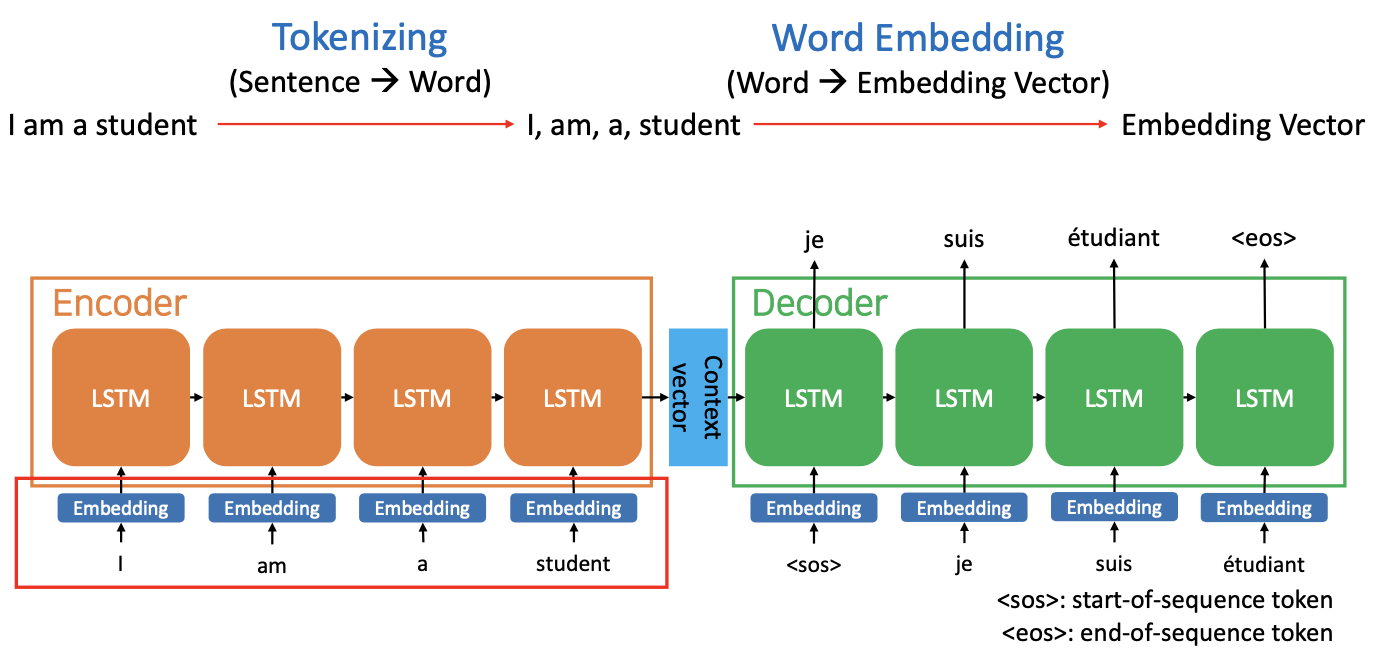
Word Embedding-Word2Vec
- 우리가 10,000개의 단어로 구성된 데이터 집합을 가지고 있다고 가정합니다
- 데이터 집합에 'dog'라는 단어를 인덱스 반호 4로 지정되어 있다.
1) One-hot Vector
- 인덱스 4번에 1이 들어감
- 1 이후에 9995 개의 0이 있는 것
- One-hot Vector 를 사용하여 각각의 단어를 코딩하는 것은 문제가 없다
- 하지만, 단어와 단어 사이의 similarity 동질감이 있는지 표현을 못한다 (단순히 0아니면 1로 표현할 뿐)
2) Word2Vec
- 위의 One-hot Vector 를 해결하기 위해 등장
- dog 만 숫자로 표현하는 것이 아니라 다른 것들도 숫자로 표기하여 유사성을 부여
- 개(0.7) 과 유사한 것이 고양이 이기 떄문에 아마도 왼쪽 0.5 는 고양이로 라벨링 되어있을 것이다 (추측)
- 다른 단어들과의 유사성을 표현할 수 있다
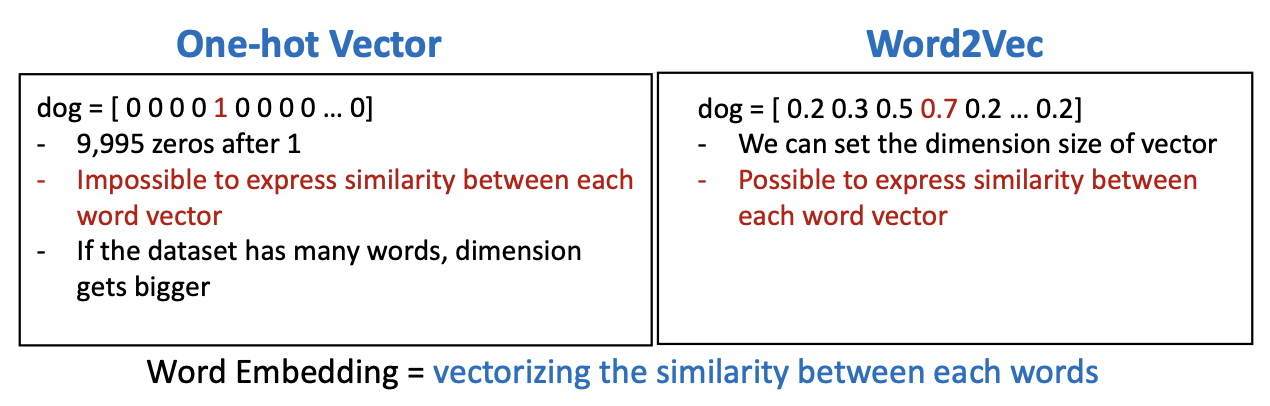
- word2vec 는 음수도 사용 가능

RNN Cell
- 시간 t-1에서 hidden state를 가지고 시간 t에서 입력 벡터가 -> 시간 t에서 hidden state를 출력한다.
- 다른 hidden layer 또는 Output layer(multiple)이 있는 경우 hidden state를 다른 layer으로 전달하거나 무시할 수 있습니다
- 시간 t의 hidden state를 시간 t+1의 RNN 셀에 입력으로서 전달합니다
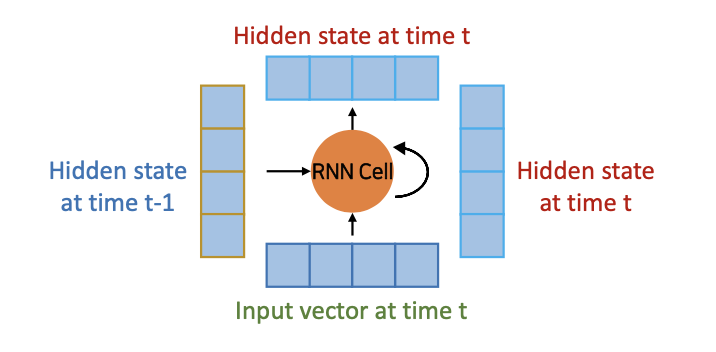
seq2seq 정리
1)
- 인코더 RNN 셀의 마지막 숨겨진 상태를 디코더 RNN 셀로 전달합니다
- 인코더 RNN 셀의 마지막 숨겨진 상태 = 컨텍스트 벡터
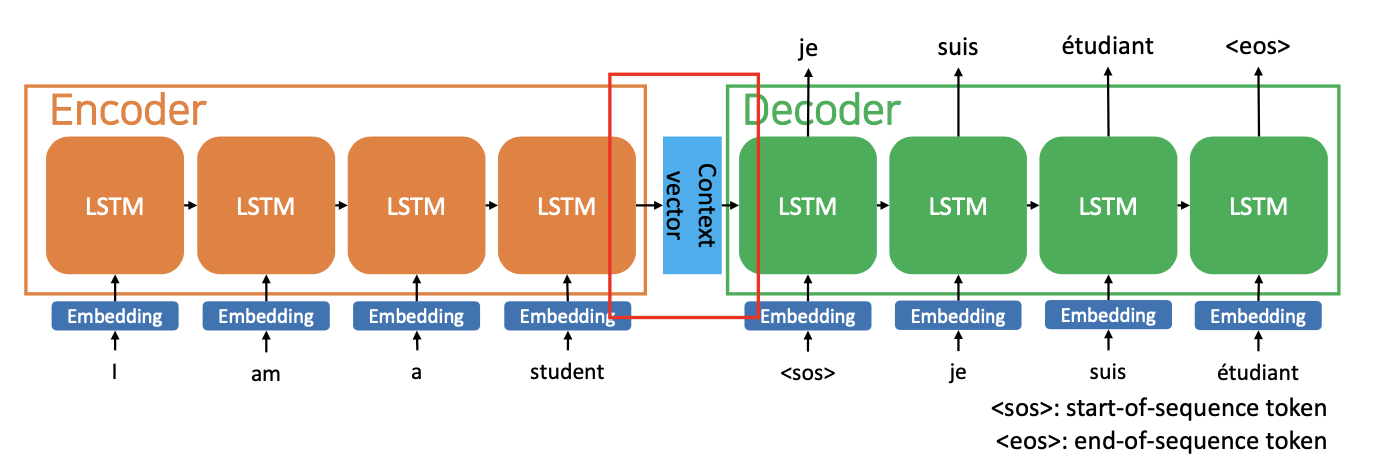
2)
- 각 디코더 셀은 가능한 타겟 워드의 확률 분포로 다음 워드를 예측합니다
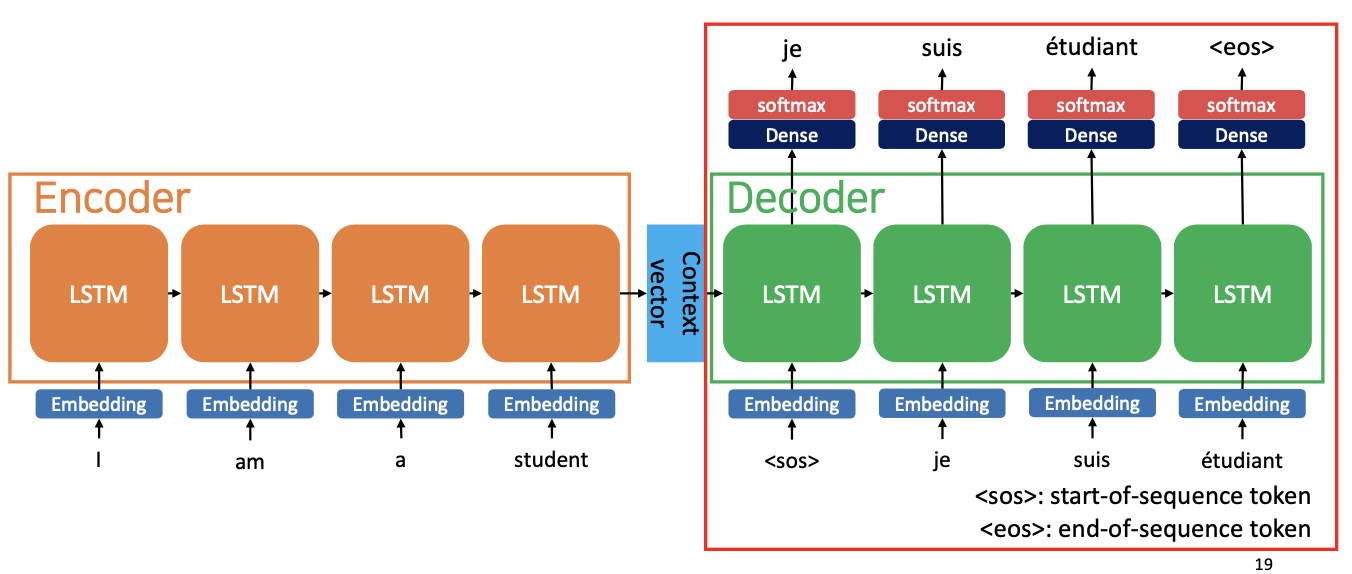
(중요) Limitations of RNN based Language Model
- RNN 기반 언어 모델에는 두 가지 문제가 있습니다:
- ❶ 모든 정보를 하나의 고정된 크기 벡터로 압축하면 정보 손실이 발생합니다!!! (단점)
- ❷ 경사소실 : 기울기가 사라지는 문제
- 현재까지 계산된 결과 Error = 를 Loss function 이라고 하는데
- 경사하강법은 loss 만큼 원래 원하는 목표치와 현재 수치의 차이를 최소화시키는 방향으로 역전파를 시켜 이전의 weight 업데이트시켜준다.
- 계속해서 이전 슬라이드에서는 weight 값을 업데이트 안해준다고 했는데, 하지만 result 가 나온 이후로는 target 값과 비교한 이후 weight 값들을 업데이트 할 수 있다.
- loss 값만큼 미분을 해서 기울기를 변화시켜서 minimal 에 도달하면 최적의 값을 도달하게 되는것 (그 전까지 w 업데이트)
- 하지만 미분한 값이 0에 가깝게 되면 학습이 되지 않게 되버리면 경사소실문제가 발생
❶ 모든 정보를 하나의 고정된 크기 벡터로 압축하면 정보 손실이 발생
- 인코더 부분을 통해, 모든 입력의 정보는 하나의 컨텍스트 벡터로 압축됩니다
- 벡터를 포함하는 100개 단어의 모든 정보를 하나의 컨텍스트 벡터에 압축하면 정보 손실을 초래할 수 있습니다
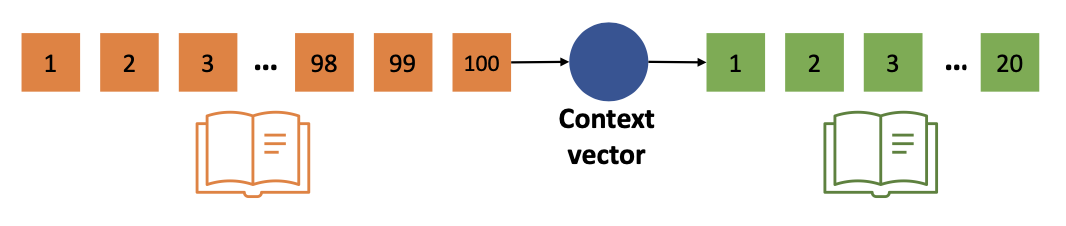
❷ 경사소실 문제
- 딥러닝에서는 매개 변수를 잘 업데이트하기 위해 그라디언트 값을 너무 크지 않거나 너무 작지 않게 유지하는 것이 중요합니다
- Sigmoid 함수의 도함수의 최대값은 입력이 0일 때 0.25입니다
- 역전파하는 동안 시그모이드 함수의 도함수가 반복적으로 곱해질 경우 그래디언트 값이 작아집니다
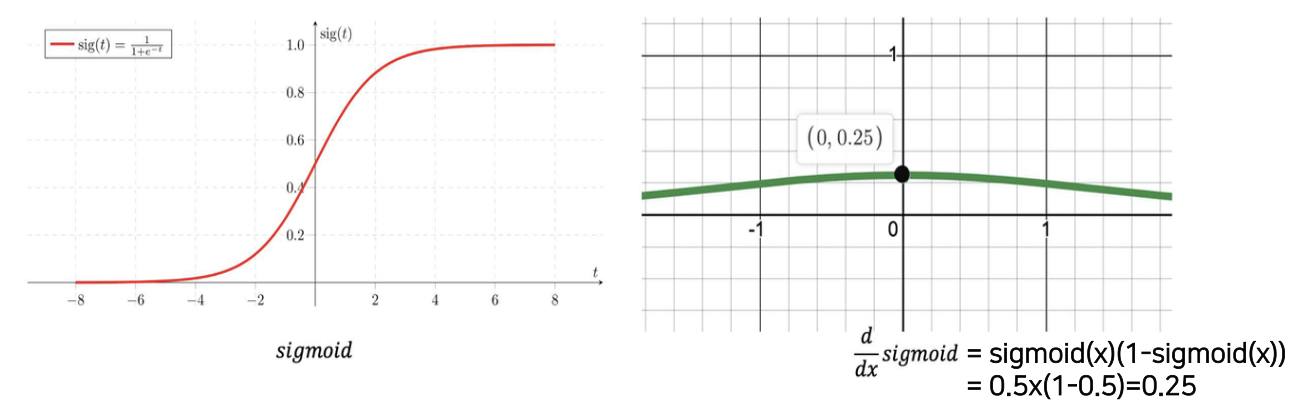
- 시그모이드 미분 결과 : x 가 0 라면
- 0.5 x 0.5 = 0.25
- 시그모이드 미분 결과 : x 가 0 라면
9/21)
text vs context
: 전 후 문장을 통해 숨겨진 내용이 contex
문장이 너무 길어지면 과거의 정보들이 잊혀지기 떄문에, 이를 해결하기 위해서 transformmer 사용
gradient : target 과 현재값의 error 를 미분을 통해서 줄여나가는 것
vanishing : data set 200 개라고 가정하고 학습을 하는데, 얼마 못가서 최적이 값이랍시고 0에 가까운 값을 내놓음(학습이 잘 되지 않는 것으로 볼 수 있다)
activation function : 여러 범위의 값들을 0~1 사이의 압축을 시켜서 정규화
매 t 마다 경사하강법에 의해서 미분하고 sigmoid 적용하는데, sigmoid를 한번 미분하고 나서 가장 높은 값을 구허기 위해서 t=0을 넣어보니 0.25 가 나옴 -> 그 다음에 또 미분하니 0.25 x 0.25 ... -> 이게 함정임 (학습을 제대로 하지 않았음에도 기울기값이 기하급수적으로 줄어서 0에 도달하게 되는 것임) -> 이 대안으로 LSTM 대신에 attention 이라는 중요한 알고리즘을 적용(transformer)
질문)

