
CH1
학습목차
- 영상처리 문제 이해
- 영상처리 문제 해결 방법
- 성능지표 : 정확도 & 처리속도
- 딥러닝 소개
2. 영상처리 문제 해결 방법
2.1) 컴퓨터 비전 문제의 과학적 접근이 어려운 이유
- 어려운 이유
- 역 문제 : 3차원 세계를 2차원 영상으로 입력받아 3차원 세계를 인지
- 불량 문제 : 정렬(sorting) 처럼 답이 유일한 우량 문제 와 달리 컴퓨터 비전 문제는 답이 유일하지 않은 어려운 문제(예를 들어, 영역 분할 문제에서 사람 몸 전체를 하나로 분할하거나 부분별로 구분하여 분할하는 등 여러 답이 가능)
- 다양한 변형(기하학적 변환, 광도 변환) 발생.
- 조명의 상태, 배경의 색상 등등에 따른 고양이 식별 문제가 쉽지 않다.
3. 성능지표 : 정확도 & 처리속도
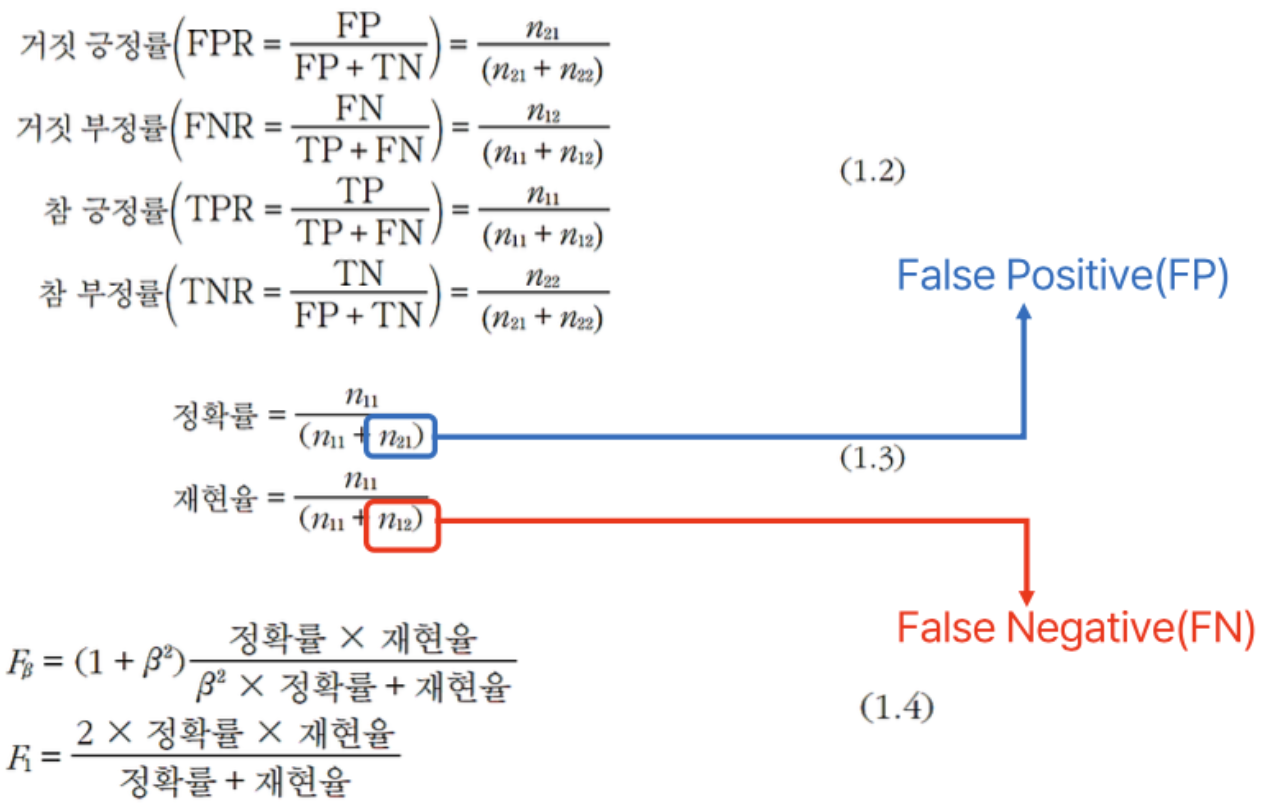
3.1) 혼동행렬
- 오류 경향을 세밀하게 분석하는데 사용

- 참/거짓 긍정률, 참/거짓 부정률, 재현율 과 정확률(정밀률), F 측정
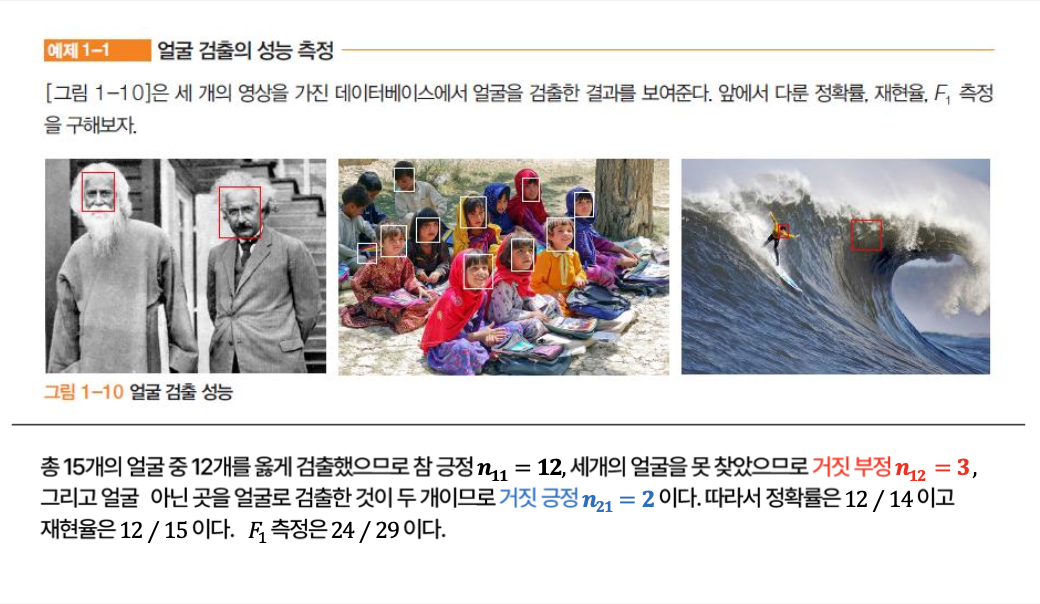
- TP (참 긍정) : 맞는건데 맞다고 한 것. 총 15개의 얼굴 중 12개를 옳게 검출.
- FN (거짓 부정) : 맞는건데 틀렸다고 한 것. 총 15개의 얼굴 중 3개의 얼굴을 못 찾았으므로.
- FP (거짓 긍정) : 틀린건데 맞다고 한 것. 얼굴이 아닌 곳을 얼굴로 검출 한 것 2개
- TN (참 부정) : 틀린건데 틀렸다고 한 것. 얼굴 아닌 곳을 얼굴이 아니다 라고 검출 (무수히 많다.)
- 정확률 :
- 재현율 :
- :
- 정확률과 재현률을 가지고 숫자 하나로 표현 가능한 지표
4. 딥러닝 소개
- 전통적인 방식과 달리 깊은 학습 방식에서는 '특징 추출' 과 '분류'를 하나의 학습 모델로 처리
4.1) 전통적인 방식 :
즉 입력 영상에서 지식에 기반한 120차원의 특징 벡터 x 를 먼저 추출한 후, x가 2개의 은닉층(fully-connected 노드로 구성) 신경망에 입력되는 경우의 기계 학습 및 테스트 과정
- 기계학습 과정 1
- 강아지 영상의 특징 벡터가 입력으로 들어간다
- forward propagation 을 통해 학습
- 출력층에는 각각 동물일 확률이 나온다.
- 하지만 정답지(label) 인 과는 다른 출력값이 나와버렸고, 그 출력값과 정답지와의 차이를 error 라고한다.
- 그 error 를 줄이기 위해 error-backpropagtion 을 진행하므로써 weight 값을 보정해준다.
- 기계 학습 과정 2
- 그 다음 강아지 영상의 특징 벡터를 입력으로 넣어줬다.
- error 가 점점 줄어듦 (이 과정을 반복)
- 테스트 과정 N
- 충분히 오류가 줄었다면, test data 를 넣어서 확인
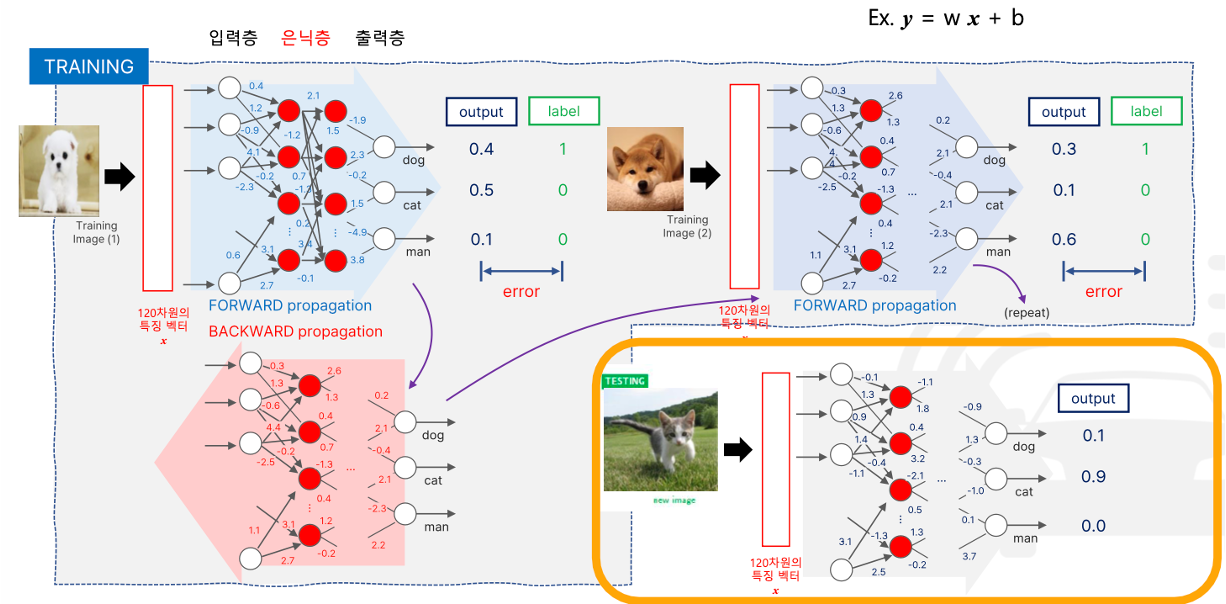
- 충분히 오류가 줄었다면, test data 를 넣어서 확인
4.2) 딥러닝 방식
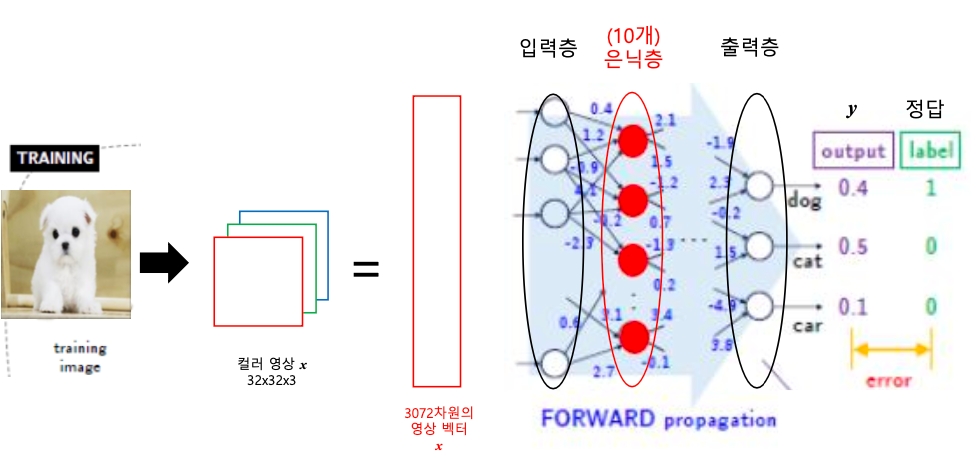
- 즉 컬러 영상 통째로 x(= 32x32x3 = 3072 픽셀) 벡터가 10개의 은닉층을 갖는 신경망에 직접 입력되는 경우의 기계 학습 과정. 만약 학습 파라미터가 1억개(10개 은닉층당 fully-connected 노드가 각각 3072라 가정)인데, 학습 데이터수가 6백장밖에 없다면?
- 픽셀 하나당 0~255까지의 256개를 가질 수 있으니까 계산하면 너무 큰 입력공간
- 3차원 이상의 배열을 텐서(tensor)라 하고, 이러한 기계 학습에서 텐서 처리 전용으로 구글에서 개발한 칩을 TPU(Tensor Processing Unit)
- 입력 영상 경우의 수
4.3) CNN
- 간단히 정리하면 좋을거같다.

공부한 것 기록용