🚨기록용이며, 아래의 기록은 실패한 테스트다
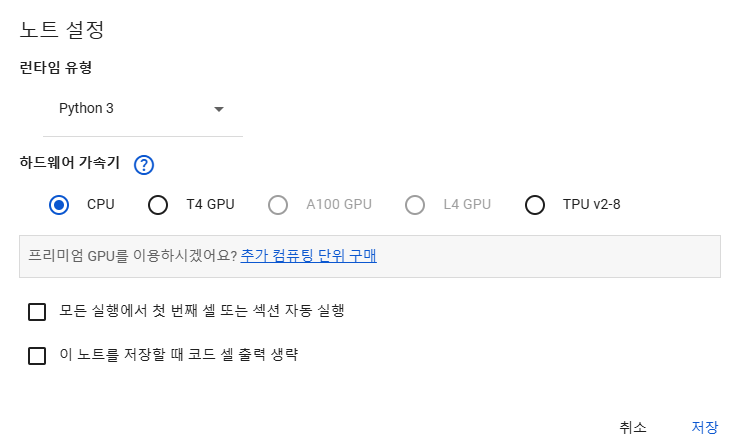
💡 코랩 GPU설정
코랩에서는 무료로 GPU를 지원해준다(T4 GPU)
처음 코랩에 들어가면 GPU가 아닌 CPU로 설정되어있는데,
수정 > 노트설정 에 들어가서 GPU로 바꿔주어야 한다.
💡TinyLlama 불러오기
Hugging Face Transformers와 같은 라이브러리에서 쉽게 불러올 수 있다.
📌 Hugging Face란?
오픈소스 AI 및 라이브러리, 플랫폼을 제공하는 커뮤니티
이곳에서 제공하는 Transformers 라이브러리를 이용하면 모델을 쉽게 불러와서 사용할 수 있다. Transformers 라이브러리 뿐만 아니라 다양한 기능을 제공하는 라이브러리가 있다.
!pip install transformers위 코드를 실행하면 transformers 라이브러리를 설치한다.
from transformers imoprt AutoTokenizer, AutoModel
# Hugging face 모델 허브에서 TinyLlama 불러오기
# Hugging face에 적힌 TinyLlama의 정확한 이름
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
# tokenizer 정의
tokenizer = AutoTokenizer.from_pretrained(model_name)
# model 정의
model = AutoModel.from_pretrained(model_name)위 코드를 실행하면 Hugging Face에서 모델을 불러올 때 필요한 구성파일들과 모델 파일들이 다운로드 된다.
💡TinyLlama 사용해보기
# 텍스트 생성 예시
# 질문
input_text = "You are an AI assistant who provides concise answers. Explain about Colab"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs, max_length=400)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)위 코드를 실행하면 TinyLlama가 질문에 맞게 답변을 해준다.
max_length의 값을 이용해서 답변의 길이를 조절할 수 있다.
💡언어 모델을 교육시키기 위한 과정
-
데이터 준비
'질문-답변'처럼 키-값 형식의 데이터셋 준비 -
데이터셋을 모델에 맞게 전처리
-
학습시킬 언어모델 불러오기
-
학습 파라미터 설정하기
Hugging Face의 Trainer 클래스를 이용하여 -
모델 학습 시작
-
모델 평가 및 저장
📌 데이터셋 모델에 맞게 전처리하기
!pip install datasets
from google.colab import drive
drive.mount('/content/drive')
from datasets import Dataset
import json
# 파일 경로
file_path = "/content/drive/My Drive/trainJsonData.json"
# 데이터 로드
with open(file_path, "r", encoding="utf-8") as f:
data = json.load(f)
# 데이터를 Hugging Face Dataset으로 변환
dataset = Dataset.from_list(data)
# 데이터 확인
print(dataset)간단하게 약 50개 정도의 데이터를 넣은 json을 google drive에 업로드 하였으며,
이를 코랩에 가지고 왔다.
(Json 내용은 소설에 관련 된 내용으로 다음과 같이 작성하여 약 50개의 데이터를 넣었다)
[
{
"instruction": "한국 문학에서 가장 많이 번역된 소설은 무엇인가요?",
"response": "박경리 작가의 '토지'입니다."
},
{
"instruction": "토지 소설의 줄거리는 무엇인가요?",
"response": "'토지'는 한국의 일제강점기를 배경으로, 여러 인물들의 삶과 고난을 그린 대하소설입니다."
}
]from datasets import Dataset
import torch
def preprocess_data(data, tokenizer, max_length=128):
inputs = []
for item in data:
# 질문과 답변을 하나의 문자열로 결합
input_text = f"질문: {item['instruction']} 답변: {item['response']}"
# 토큰화
encoding = tokenizer(
input_text,
max_length=max_length,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# Hugging Face Dataset에 맞게 Python dict 형태로 저장
inputs.append({
"input_ids": encoding["input_ids"].squeeze(), # 차원을 맞추기 위해 squeeze() 사용
"labels": encoding["input_ids"].squeeze() # 동일한 input_ids를 labels로 사용
})
# 리스트 형식의 데이터를 Dataset으로 변환하여 반환
return Dataset.from_list(inputs)# 전처리 함수 실행
dataset = preprocess_data(data, tokenizer)📌 학습 설정 및 학습 시작
import os
os.environ["WANDB_MODE"] = "disabled"학습시키는 중간에 자꾸 추적 설정 관련 문구가 뜨는데 그걸 방지하고자 위 코드를 실행시킨다.
from transformers import Trainer, TrainingArguments
from transformers import DataCollatorForLanguageModeling
# 학습 파라미터 설정
training_args = TrainingArguments(
output_dir="./results", # 학습 결과가 저장될 폴더
per_device_train_batch_size=1, # 배치 크기
gradient_accumulation_steps=4, # 배치를 가상적으로 누적 (배치 크기 4와 유사)
num_train_epochs=3, # 학습 에폭 수
logging_dir="./logs", # 로그가 저장될 폴더
fp16=True # Mixed Precision 학습
)
# DataCollator 정의
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False, pad_to_multiple_of=8
)
# 모델의 일부 레이어 고정 (Layer Freezing)
for param in model.base_model.parameters():
param.requires_grad = False # 처음 몇 개의 레이어를 고정
# Trainer 설정
trainer = Trainer(
model=model, # 학습할 모델
args=training_args, # 학습 파라미터
train_dataset=dataset # 학습 데이터셋 (전처리된 데이터)
)
# GPU 메모리 캐시 비우기
import torch
torch.cuda.empty_cache()
# 학습 시작
trainer.train()코랩 유료 버전이 아니기 때문에 메모리부족 에러가 발생할 수 있다.
📌 학습된 모델 확인해보기
# 모델 저장
trainer.save_model("./trained_model")
# 저장된 모델과 토크나이저 불러오기
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("./trained_model")
tokenizer = AutoTokenizer.from_pretrained(model_name)위와 같이 다시 model 변수에 새롭게 훈련시킨 모델을 담는다.
# 모델을 GPU로 이동
model = model.to("cuda")
# 테스트 입력
input_text = "채식주의자 소설의 주인공 이름은 무엇인가요?\n답변:"
# 입력 텍스트를 토큰화하여 GPU로 이동
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# 모델 응답 생성
outputs = model.generate(**inputs, max_length=50) # 필요한 응답 길이만큼 max_length 조절
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("질문:", input_text)
print("모델 응답:", response)위 코드는 실제 학습된 모델에게 질문을 던지고, 답변을 받는 코드다.

....실패다.
💡 LangChain 설치 명령어
!pip install langchain이후에 혹시 몰라 미리 적어두는 LangChain 설치 명령어
