
이 글은 teddy note님의 패스트캠퍼스 RAG 강의를 듣고 작성된 포스트 입니다
✨ Ollama란?

Ollama는 LLM을 쉽고 효율적으로 실행하고 관리할 수 있게 도와주는 툴이다. 주로 로컬 환경에서 AI 모델을 구동하고자 할 때 많이 사용되며, 복잡한 설정 없이 다양한 LLM을 다운로드하고 실행할 수 있도록 지원하는 아주 편리한 서비스다.
원래라면 오픈소스 모델을 다운로드하고, 해당 모델이 추론을 할 때 많은 GPU 자원이 필요하다. 하지만 이 ollama를 사용하게 되면 GPU 자원이 모자라도, 빠르게 추론할 수 있다.
✨ Ollama 설치
위 사이트에 들어가면 바로 download 버튼이 보이는데, 내 운영체제에 맞는 ollama를 설치해주면 된다. 설치가 성공적으로 되었다면 작업표시줄에 귀여운 라마가 한마리 보인다.
✨ LLM 다운로드
이제 Ollama에서 구동될 LLM을 다운로드 받아보자.
Ollama에서 지원하는 모델이 있는데, Ollama를 설치했던 사이트로 돌아가 우측 상단 메뉴의 Models를 클릭하면된다.
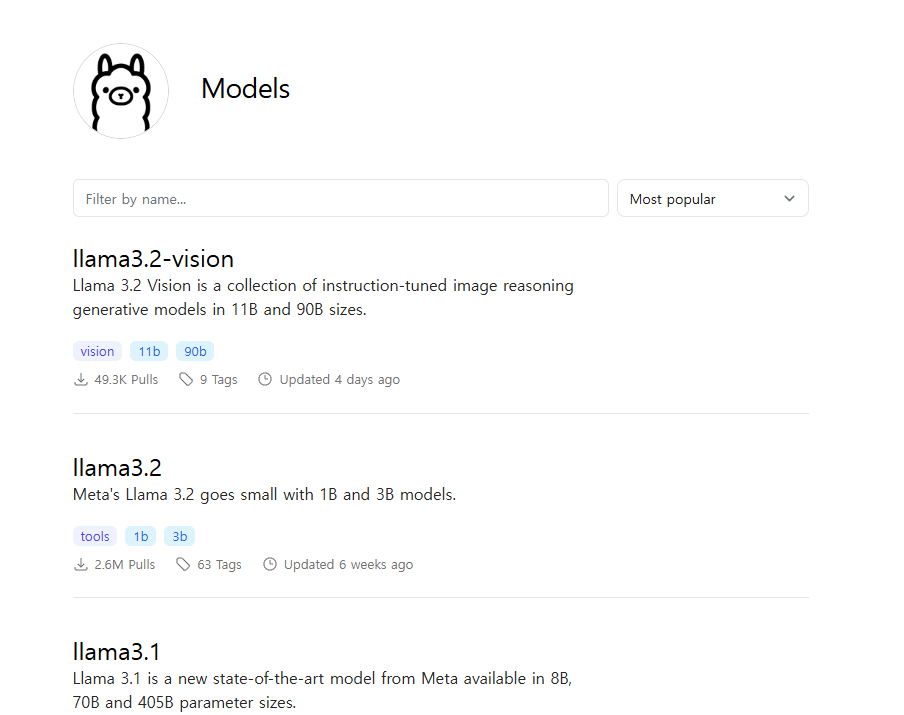
여기서 내가 원하는 모델을 검색해서 선택한 후 ollama run '모델이름'을 터미널에서 실행해주면 설치 후 해당 모델이 실행된다.
(모델을 선택하면 명령어를 복사할 수 있는 버튼이 있다)
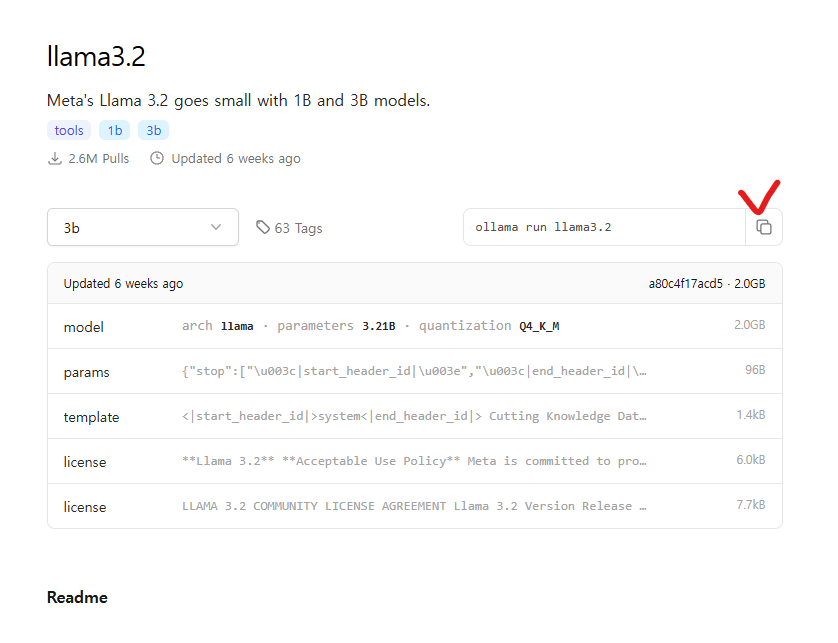
참고로 ollama run ~ 명령어는 해당 모델을 실행하는데, 만약 해당 모델이 설치되지 않았다면 설치 후 실행을 진행한다.
ollama pull ~ 명령어는 해당 모델을 설치만 하고 모델을 실행하지는 않는다.
따라서 그냥 설치만 되기를 원한다면 run이 아닌 pull 명령어로 바꿔서 실행한다.
✨ GGUF 파일 형식의 모델을 Ollama에서 실행해보기
만약에 Ollama에서 지원하지 않는 로컬 모델을 Ollama에서 이용하고 싶다면, gguf파일 형식으로 모델을 다운로드 받아오면 된다.
(HuggingFace 사이트에서 검색해보자!)
내가 원하는 모델의 gguf 파일을 내가 작업하는 프로젝트에 폴더를 하나 만들어 넣어주고, 같은 경로에 Modelfile(확장자X) 파일을 만들어준다.
FROM (내가 실행할 gguf파일 이름(확장자 포함))
TEMPLATE """
템플릿 정의
(사용자 입력과 모델 출력 형식 정의)
"""
SYSTEM """
시스템 정의
(모델이 대화 맥락을 이해하도록 기본 배경 설명 제공)
"""
PARAMETER stop <s>
PARAMETER stop </s> 위 파일을 모두 작성했다면 터미널에 해당 gguf파일과 Modelfile이 있는 폴더까지 이동하여 다음 명령어를 쳐준다.
ollama create (모델이름) -f Modelfile
성공적으로 create 되었다면 ollama list 명령어를 쳤을 떄 해당 모델이 목록에 나타날 것이다.
실행은 위에서 언급한것과 똑같이 ollama run ~ 명령어로 실행시킬 수 있다.
