Daily plan
🌞오전
- 코드카타 SQL 4문제
- 데일리 스크럼
- 파이썬 라이브 세션 10:00~12:00🔥 오후
- 빅분기 2과목 강의
- 데이터분석 파이썬 종합반 5회차 강의🌝 저녁
- 코드카타 파이썬 3문제
- 데일리 스크럼 + TIL 제출SQL 코드카타
Q59 - 자동차 대여 기록에서 대여중 / 대여 가능 여부 구분하기
SELECT CAR_ID,
CASE WHEN CAR_ID IN (SELECT CAR_ID
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE START_DATE<="2022-10-16" AND END_DATE>="2022-10-16")
THEN "대여중"
ELSE "대여 가능" END AS AVAILAVITY
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY CAR_ID
ORDER BY CAR_ID DESC지난주에 미뤄뒀던 문제를 드디어 해결했다. (사실 다른 사람 답변에서 접근법 훔쳐봄)
서브쿼리를 작성하지 않을 수 없는 문제인건가...
내가 쓴 답안이 최선의 방법인지는 잘 모르겠다.
Q61 - 서울에 위치한 식당 목록 출력하기
SELECT I.REST_ID,
I.REST_NAME,
I.FOOD_TYPE,
I.FAVORITES,
I.ADDRESS,
ROUND(AVG(R.REVIEW_SCORE),2) SCORE
FROM REST_INFO I JOIN REST_REVIEW R ON I.REST_ID=R.REST_ID
WHERE ADDRESS LIKE "서울%"
GROUP BY REST_ID
ORDER BY SCORE DESC, FAVORITES DESC처음엔 위와 같은 코드로 작성했다가 아래 코드로 바꾸어 봤다.
SELECT I.REST_ID,
I.REST_NAME,
I.FOOD_TYPE,
I.FAVORITES,
I.ADDRESS,
R.SCORE
FROM REST_INFO I
JOIN (SELECT REST_ID, ROUND(AVG(REVIEW_SCORE),2) SCORE
FROM REST_REVIEW
GROUP BY REST_ID
) R
ON I.REST_ID=R.REST_ID
WHERE ADDRESS LIKE "서울%"
ORDER BY SCORE DESC, FAVORITES DESC이 문제에서는 join 후에 group by로 묶고 계산하는 것보다, group by로 묶어서 계산한 후 join으로 묶는 게 더 낫다고 생각했기 때문이다.
REST_INFO 테이블은 각 식당에 대한 정보를 담고 있다. 즉, 하나의 식당에 대한 하나의 행이 존재한다.
REST_REVIEW는 각 식당들에 대한 리뷰 정보이기 때문에 하나의 식당에 대해서 여러 개의 리뷰가 존재한다.
따라서 join을 먼저 하면 REST_REVIEW 테이블에 포함된 행의 수만큼 각 식당에 대한 여러 개의 행이 생기게 된다.
반면에 REST_REVIEW를 먼저 REST_ID에 따라 group by로 묶고 각 식당에 대한 리뷰 평균 점수를 계산한 뒤 join으로 두 테이블을 묶는다면, 각 REST_ID에 대해 하나의 행이 유지되기 때문에 더 효율적이라고 생각했다.
(GPT한테도 물어봤더니 join하기 전에 데이터 크기를 줄이는 것이 더 효과적이라고 답해주었다.)
Q62 - 자동차 대여 기록에서 장기/단기 대여 구분하기
SELECT HISTORY_ID,
CAR_ID,
DATE_FORMAT(START_DATE, "%Y-%m-%d") START_DATE,
DATE_FORMAT(END_DATE, "%Y-%m-%d") END_DATE,
CASE WHEN DATEDIFF(END_DATE, START_DATE)+1>=30 THEN "장기 대여"
ELSE "단기 대여" END AS RENT_TYPE
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
WHERE START_DATE LIKE "2022-09%"
ORDER BY HISTORY_ID DESC아무리 봐도 맞게 썼는데 자꾸 틀렸다고 해서 한참을 째려봤다.
datediff함수를 이용해서 start_date와 end_date의 차이, 즉 대여 기간을 계산했는데 여기에 +1을 해주어야 한다. 같은 날 대여하고 바로 반납해도 대여기간이 1일이 되야한다는 걸 생각하면 바로 이해 가능하다.
Q63 - 자동차 평균 대여 기간 구하기
SELECT CAR_ID,
ROUND(AVG(DATEDIFF(END_DATE,START_DATE)+1),1) AVERAGE_DURATION
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY CAR_ID
HAVING ROUND(AVG(DATEDIFF(END_DATE,START_DATE)+1),1) >=7
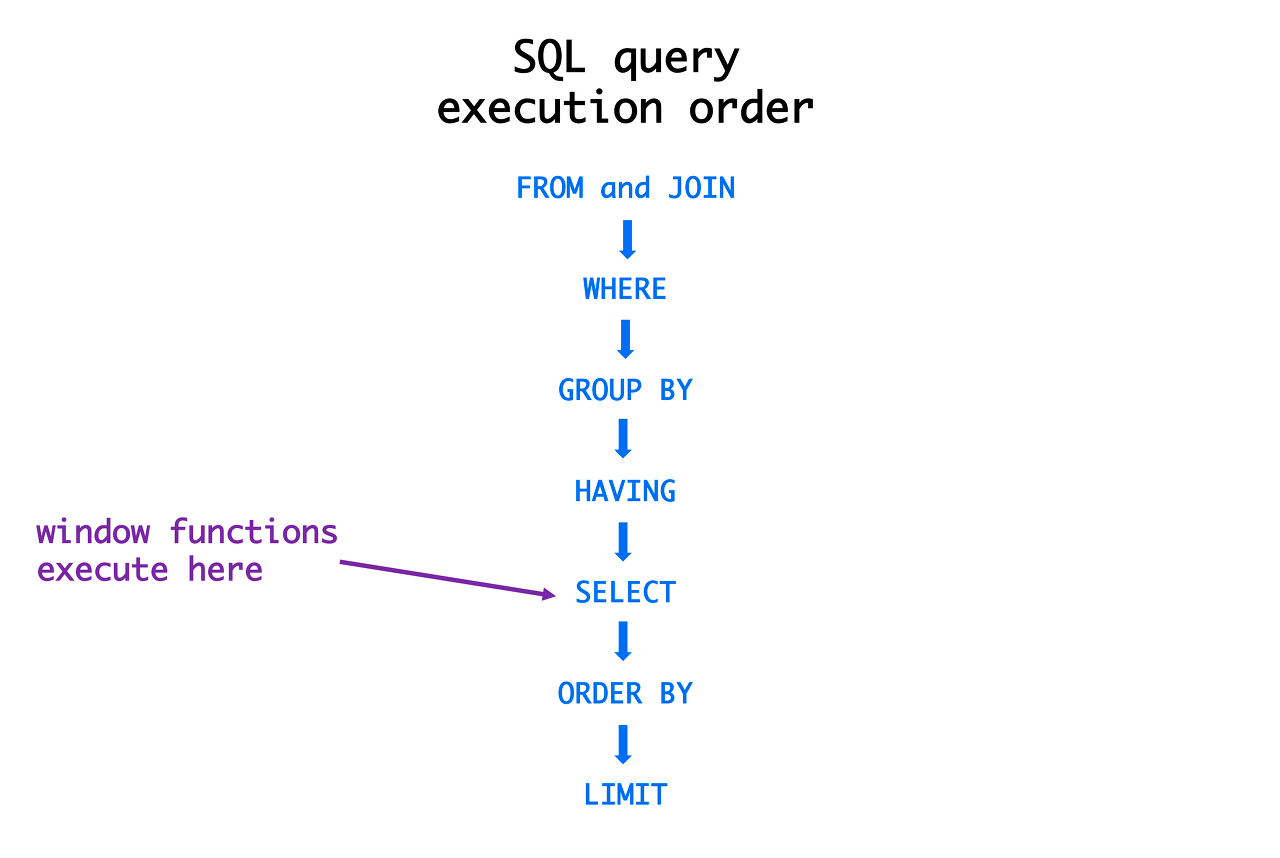
ORDER BY AVERAGE_DURATION DESC, CAR_ID DESCSELECT절에서 작성한 alias를 HAVING절에서 사용해도 똑같은 결과가 나오긴 했다.
HAVING AVERAGE_DURATION >=7하지만 이전 SQL 라이브 세션에서는 HAVING절이 SELECT절보다 먼저 실행되기 때문에 일반적으로는 HAVING절에서 alias를 사용하지 못한다고 말씀하셨다. 찾아보니 DBMS 종류에 따라 허용되는 경우도 있다고 한다. 앞으로는 실행 순서에 맞게 정석적으로 쿼리를 작성하는 습관을 들이는 게 좋을 것 같다.
SQL 실행 순서
파이썬 코드카타
lv1 앞 문제들은 굳이 TIL 안쓰고 빠르게 풀어 넘기려고 했는데 다른 사람들 코드를 보니까 배울 점들이 많은 것 같다.
Q8 - 각도기
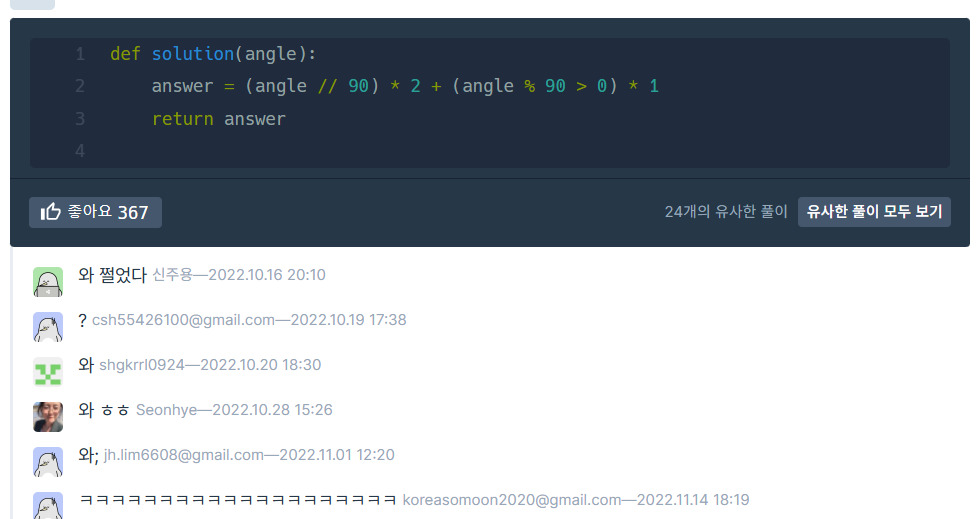
이걸 이렇게 푸는 사람이 있다니
천재 같기도 하고 약간 변태 같기도 함..ㅋㅋㅋ
def solution(angle):
if angle<90:
return 1
elif angle==90:
return 2
elif angle<180:
return 3
return 4난 이렇게 풀었는데 형편없는 내 코드에 초라해지는 기분이다.ㅋㅋ
def solution(angle):
if angle<=90:
return 1 if angle<90 else 2
else:
return 3 if angle<180 else 4이 코드가 더 맘에 듦!
Q9 - 짝수의 합
나의 풀이
def solution(n):
sum=0
for i in range(0,n+1,2):
sum+=i
return sum다른 사람 풀이
def solution(n):
return sum([i for i in range(2, n + 1, 2)])내용만 보면 같은데, 나는 4줄을 작성한 걸 누군가는 한 줄로 끝내버렸다.
for 구문을 통으로 sum 함수 안에 넣을 생각을 못했다.
(파이썬 코드카타 10번까지 완료!)
파이썬 라이브세션 1회차+2회차
라이브러리 개념 학습 & 실습 환경 준비
1. Library
- 라이브러리는 '자주 사용하는 함수들을 모아놓은 묶음'
- 라이브러리 호출
import pandas as pd
import numpy as np
import time
from matplotlib.pyplot as plt- import로 라이브러리(모듈)를 호출하고 as 뒤의 간단한 별칭으로 명명
- 라이브러리에서 특정 함수만 사용하고 싶을 때는 from을 이용2. Pandas
- Pandas는 다양한 유형의 데이터를 시리즈와 데이터프레임이라는 공통의 포맷으로 정리하여, 쉽고 빠른 연산 및 분석을 위한 함수를 제공하려는 목적으로 사용됨 (json, html, csv 등 모두 데이터프레임으로 통일해서 표현 가능)
- DataFrame은 통계와 머신러닝 모델에서 가장 기본이 되는 테이블 형태의 데이터 구조
- 기본적으로 행과 열로 구성된 이차원의 행렬
- 파이썬, R에서 사용하는 특정 데이터 포맷임
- Series는 데이터프레임의 하위 자료형으로, 모든 유형의 데이터를 보유하는 1차원 배열임
(테이블의 열을 의미한다고 볼 수 있음)
3. Data EDA
- Magic command를 활용한 셀 실행 시간 확인
- Magic command는 IPython kernel에서 제공되는 명령어로, '%', '%%' 키워드를 사용해 실행 가능
- 주피터 노트북 환경에서 지원하는 매직 커맨드로, 셀 가장 위쪽에 작성해야 함
- CPU time: CPU가 코드를 실행하는 데 걸린 시간
- Wall clock time: 실제 코드를 실행하는 데 걸린 시간
- 소요 시간 측정
- %time: 뒤에 나오는 한줄 커맨드 소요시간
- %%timeit: 뒤에 나오는 한줄 커맨드 반복 수행 후(iteration) 평균 소요시간
- %%time: 뒤에 나오는 셀 전체 수행 후 소요시간
- %%timeit: 뒤에 나오는 셀 전체 수행 후 평균 소요시간
- %time: 뒤에 나오는 한줄 커맨드 소요시간
핵심 코드 요약
df = pd.read_csv("~~.csv") # csv 파일 읽기
display(df1, df2, ..) # 테이블 확인하기
df.head() # 첫 5줄만 출력
df.tail() # 마지막 5줄만 출력
len(df) # 테이블의 행 길이
df.shape # 테이블의 행과 열 개수 반환
df.dtypes # 테이블 내 컬럼타입 확인
df.columns # 테이블 내 컬럼 확인
df.values # 테이블 내 각 행들을 배열 형태로 확인
df.info() # 테이블 기본 구조 한눈에 확인
df.describe() # 전체 행 개수, 평균, 표준편차, 최솟값, 사분위수, 최댓값 확인
df.isnull().sum() # 컬럼별 결측치 확인
# 특정 컬럼 가져오기
df['Category']
df.Category
df.iloc[row idx,col idx]
# 특정 컬럼 버리기
df.drop('Interaction type', axis=1, inplace=True)
# axis=0은 인덱스 기준 삭제 / axis=1은 컬럼 기준 삭제
# inplace=True는 원본을 변경 / inplace=False는 원본을 변경하지 않음
# 데이터 grouping
df.groupby('category1')['category'].count()
df.groupby(['category1', 'category2')['category'].count()
# count vs unuique(distinct, 중복제거) 차이
# count는 데이터의 수 출력
# nunique는 데이터 고유값들의 수를 출력
# value_counts()는 값별로 데이터 수 출력 (내림차순이 기본, 오름차순은 ascending=True 옵션이 필요)
# unique()는 데이터에 어떤 종류의 고유값들이 있는지 알려주는 함수
빅분기 2과목
데이터 탐색과 통계기법에 대한 내용을 다룬다. 여기도 ADsP랑 내용 거의 겹치는 듯?
키워드 위주로 흐름만 정리해놔서 내용이 별로 없어 보이는데, 외워야 할 게 꽤나 많다ㅜ.ㅜ

일기
일단 하기로 한 건 다했는데,,, 하루가 알차지 못한 것 같은 찝찝한 이 기분은 뭘까..
파이썬 개인과제 자꾸 까먹게 된다ㅜ.ㅜ 내일 한번에 다 끝내버려야지!
