Daily plan
🌞오전
- 데일리 스크럼
- 코드카타 SQL 3문제
- 코드카타 Python 5문제
- 아티클 스터디🔥 오후
- 빅분기 3과목 강의
- 데이터 리터러시 강의
- 파이썬 개인 과제 🌝 저녁
- 강의 못들은 거 다 듣기
- 데일리 스크럼 + TIL 제출SQL 코드카타
Q64 - 헤비 유저가 소유한 장소
SELECT *
FROM PLACES
WHERE HOST_ID IN (
SELECT HOST_ID
FROM PLACES
GROUP BY HOST_ID
HAVING COUNT(ID)>1
)
ORDER BY ID나는 WHERE절에 서브쿼리를 작성하는 방식을 선택 했지만, 다음과 같이 JOIN을 활용해서 풀이할 수도 있다.
SELECT P1.*
FROM PLACES P1
INNER JOIN (SELECT HOST_ID, COUNT(ID) CNT_ID
FROM PLACES
GROUP BY HOST_ID) P2
ON P1.HOST_ID=P2.HOST_ID
WHERE P2.CNT_ID>1
ORDER BY P1.IDQ65 - 우유와 요거트가 담긴 장바구니
SELECT CART_ID
FROM CART_PRODUCTS
WHERE NAME='Yogurt' OR NAME='Milk'
GROUP BY CART_ID
HAVING COUNT(DISTINCT NAME) = 2
ORDER BY CART_ID언제쯤 DISTINCT랑 친해질 수 있을까? 요거트나 우유를 구매한 정보만 추출해서 CART_ID로 묶어주고, 각 CART_ID마다 중복 제거해서 개수를 세었을 때 2개가 되는 것들을 골라내면 되는 문제였는데 DISTINCT를 생각해내지 못해서 오래 걸렸다!!

결국 챗지피티한테 힌트 구걸함..ㅋㅋ
(챗지피티한테 힌트 물어보는 거 생각도 못했는데, 오전에 튜터님께서 파이썬 공부 팁과 함께 이런 방법도 있다는 것을 알려주셨다.. 감사합니다ㅜ.ㅜ)
Q66 - 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기
SELECT CONCAT('/home/grep/src/',F.BOARD_ID,'/',F.FILE_ID,F.FILE_NAME,F.FILE_EXT) FILE_PATH
FROM (SELECT BOARD_ID
FROM USED_GOODS_BOARD
ORDER BY VIEWS DESC
LIMIT 1) B
JOIN USED_GOODS_FILE F
ON B.BOARD_ID=F.BOARD_ID
ORDER BY F.FILE_ID DESC분명 맞게 작성한 것 같은데 자꾸 틀렸다고 해서 당황했다. 한참을 째려보다가 CONCAT에서 FILE_NAME을 빼먹었다는 걸 아주 뒤늦게 발견...ㅎㅎ;
Python 코드카타
Q13 - 자릿수 더하기
def solution(n):
x=0
while(n>0):
x += n%10
n = n//10
return x난 이걸 그냥 while문을 사용해서 단순하게 계산했는데
def sum_digit(number):
if number < 10:
return number
return number%10 + sum_digit(number//10)이렇게 재귀함수를 이용해서 풀 수도 있는 거였다니...!!! 한 수 배우고 갑니다,,
def sum_digit(number):
return sum([int(i) for i in str(number)])이것도 나보다 훨씬 깔끔하다. 나도 이런 방법을 바로바로 떠올리고 싶다ㅜ.ㅜ
Q14 - 약수의 합
def solution(n):
sum = 0
for i in range(1,n//2+1):
if n%i==0:
sum+=i
return sum+n이걸 최대한 간략하게 줄이면 다음과 같다.
def solution(n):
return num + sum([i for i in range(1, (num // 2) + 1) if num % i == 0])어차피 내용은 똑같은데 무조건 줄여쓰는 게 더 좋은 건 아닐 것 같다.
Q16 - x만큼 간격이 있는 n개의 숫자
def solution(x, n):
answer = []
while len(answer)!=n:
answer.append(x)
x+=answer[0]
return answerdef number_generator(x, n):
return [i * x + x for i in range(n)]answer이라는 리스트를 만들고 while문으로 하나씩 append하는 것보다,
걍 범위를 n으로 정하고 for문을 사용해서 바로 리스트로 만들어 리턴하면 훨씬 간단한 코드가 되는구나..
아티클 스터디
- 요약 :
- A/B 테스트의 표면적인 목적은 ‘목표 달성을 휘한 방안으로 A안과 B안 중 무엇이 더 효과가 좋은지 파악하는 것’
- 하지만 실제로 우리는
- 두 실험 결과가 상당히 크거나 확실하길 바라고
- 실험이 공정하게 진행되길 바라고
- 실험 결과가 이례적이거나 우연이 아니길 바람
- 이와 같은 심층적인 목적 달성을 위해서는 A/B 테스트의 설계 및 결과 해석 과정이 더욱 구체적이고 세밀하게 이루어져야 함
- 주요 포인트 :
A/B테스트를 단순히 트래픽을 절반으로 나누거나 변수를 하나만 설정하거나, 더 나은 결과를 보여주는 방안을 선택한 수 배포하는 것이라고 정의할 수 없다. 우리는 A/B테스트를 통해 표면적인 결과보다 더욱 구체적인 결과를 얻길 원한다. - 인사이트 :
A/B 테스트를 채용공고에서만 가끔씩 봤을 뿐, 정확히 어떤 방식으로 수행되는지 공부해본 적은 없었다. 이 글을 읽기 전에는 A/B 테스트를 단지 ‘기계적인 시뮬레이션을 통해 수치적으로 더 나은 결과를 선택하는 것’ 정도로만 생각했다. 이번 아티클을 읽으면서 A/B테스트가 단순 비교에 그치면 안된다는 것을 깨달았다. 또한, 비단 A/B 테스트 뿐만 아니라 데이터 분석을 배우면서 매번 느끼는 것은 ‘누가 분석을 하느냐’가 정말 중요하다는 것이다. 정해진 답이 있는 게 아니라 ‘예측’을 하는 과정이기 때문에 더 그런 것 같다. SQL이나 파이썬, 시각화 등의 스킬을 공부하는 것도 중요하지만, 주어진 과제에 대하여 다각도로 고민하고 넓은 시야로 문제를 바라보는 등의 태도를 갖추는 것도 매우 중요하다는 걸 잊지 않아야겠다.
데이터 리터러시
데이터 리터러시란?
- 데이터를 읽고, 이해하고, 비판적으로 분석하여 결과를 의사소통에 활용할 수 있는 능력
- 데이터 수집과 데이터 원천, 데이터 활용법 및 데이터를 통한 핵심지표를 이해하는 것
- 올바른 질문을 던질 수 있게 함
데이터 분석 접근법
- 문제 및 가설 정의
- 데이터 분석
- 결과 해석 및 액션 도출
데이터 분석이 목적이 되지 않도록 항상 '왜?'를 생각해야 함
1. 문제 정의
- 분석하려는 특정 상황, 현상에 대한 명확하고 구체적인 진술을 의미하며, 프로젝트의 목표를 설정하고 분석 방향을 결정하는 단계
문제 정의 예제
- 상황
: 3개월 전부터 자사 제품 사용자 수 감소, 포인트 이벤트의 효과도 없어 보임, 자사 제품 내 서비스 중 A보다 B가 더 안 좋은 상황, 사용자가 줄어 수입도 감소함
- 문제 정의
사용자 수가 감소하고 있음 -> 원인 (근본적인 문제가 아님)
포인트 이벤트의 효과가 없음 -> 근본적 문제가 아님
서비스 B의 상황이 좋지 않음 -> 근본적 문제가 아님
수입이 감소함 -> 가장 중요한 문제라고 판단 가능 (더 명확한 정의가 필요) - 문제 정의는 복잡하고 시간이 소요되는 과정이며, 항상 문제를 올바르게 정의 하였는지에 대한 물음을 가지고 임해야 함
문제 정의 방법론
- MECE (Mutually Exclusive, Collectively Exhaustive)
- 문제 해결 및 분석에 널리 사용되는 접근 방식
- 문제를 상호 배타적이면서, 전체적으로 포괄적인 구성요소로 나누는 것
- MECE를 통해 복잡한 문제를 체계적으로 분해하고, 구조화된 방식으로 분석 가능
- 분류 기준이 명확한지, 서로 중복되고 누락된 정보가 존재하는 지 잘 확인해야 함
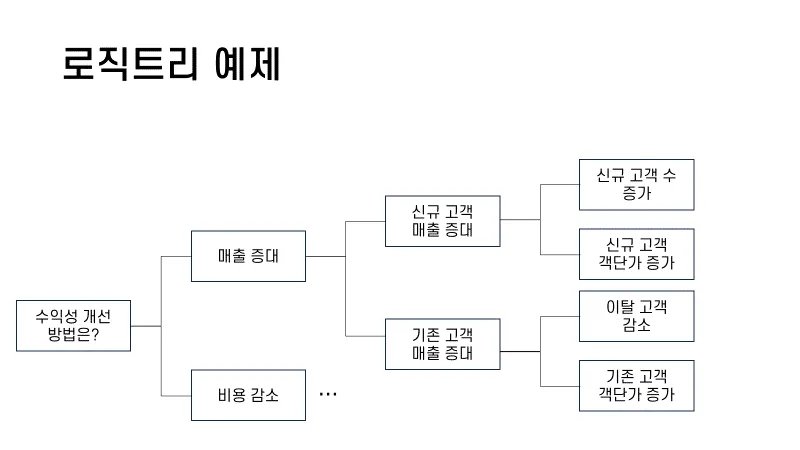
- Logic Tree
- MECE 원칙을 기반으로, 복잡한 문제를 더 작고 관리하기 쉬운 하위 문제로 분해하는 데 사용
- 상위 문제에서 시작해 하위 문제로 계층적 접근
- 일반적으로 도표 형식으로 표현 -> 쉽게 파악 가능
2. 데이터의 유형
정성적 데이터 (Qualitative Data)
- 사람의 경험, 관점, 태도 등 주관적인 요소를 포함하는 비수치적 정보
- 대부분 텍스트, 비디오, 오디오 형태로 존대
- 정형화, 구조화 되어있지 않음 (데이터를 구조화하기 어려움)
- 새로운 현상이나 개념에 대한 이해를 심화하기 위해 사용
정량적 데이터 (Quantitative Data)
- 양적 측정과 분석을 통해 얻을 수 있는 수치적으로 표현된 정보
- 숫자 형태이므로 통계적 분석에 유리함
- 객관성을 가지며 지표로 만들기에 용이
- 설문조사, 실험, 인구 통계, 지표 분석 등에 활용
정량적 데이터 vs 정성적 데이터
| 정량적 데이터 | 정성적 데이터 | |
|---|---|---|
| 유형 | 정형 데이터 / 반정형 데이터 | 비정형 데이터 |
| 특징 및 관점 | 여러 요소의 결합으로 의미 부여 | 객체 하나가 함축된 의미 내포 |
| 주로 객관적 내용 | 주로 주관적 내용 | |
| 구성 및 형태 | 수치나 기호, 데이터베이스, 스프레드 시트 | 문자나 언어, 웹 로그, 텍스트 파일 |
| 위치 | DBMS, 로컬 시스템 등 내부 | 웹사이트, 모바일 플랫폼 등 외부 |
| 분석 | 통계 분석 시 용이 | 통계 분석 시 어려움 |
일기
확실히 인터넷강의 듣는 거 너무 안 맞는다... 늘 생각하는 거지만 정말 안맞아...
문제 풀면서 공부하는 건 재밌는데 강의만 들으려고 하면 집중력이 나가리된다.ㅜㅜ
그래도 들어야지...
내일은 차라리 강의 듣는 걸 오전에 해치워버리고 집중력 떨어질 때 문제 풀이를 해봐야겠다!
