EDA
억사이트를 찾아서...
셀러별 취소율
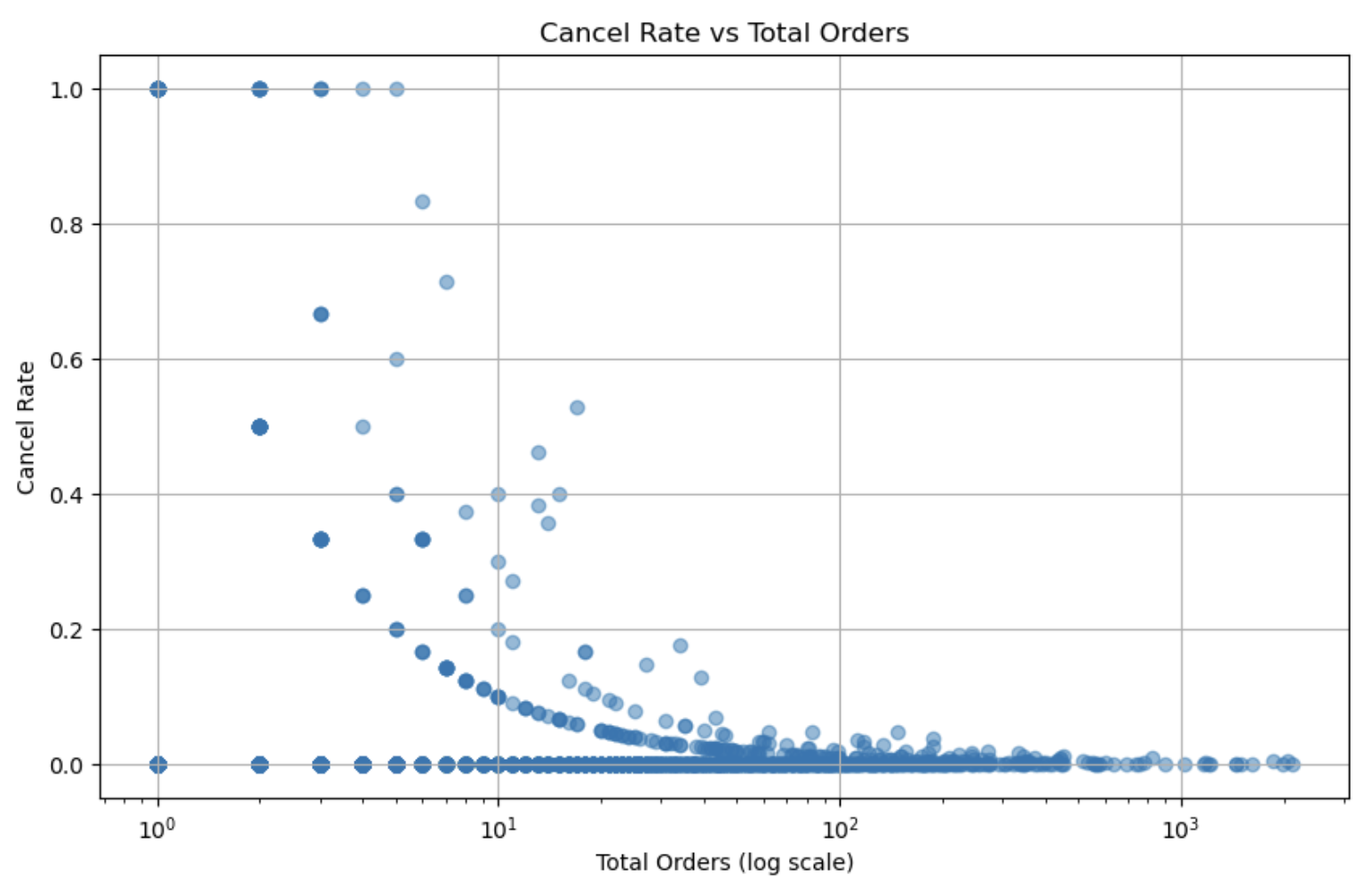
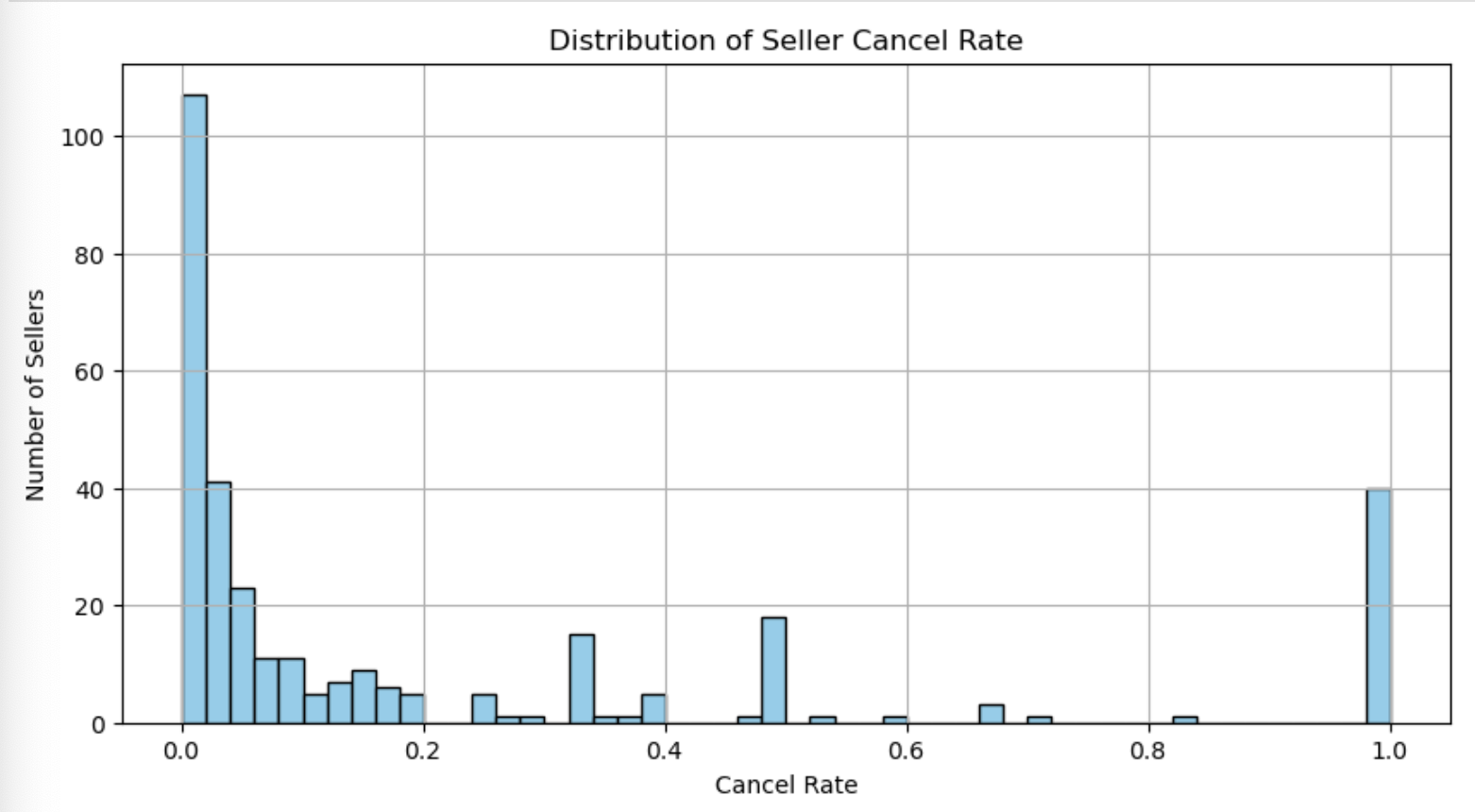
애초에 가장 취소가 많았던 경우가 고작 10회여서 취소율을 구하는 것 자체가 의미가 없다는 생각이 들었다.
만약에 굳이 구분을 지어서 분석해본다면 주문수가 많은지 적은지에 따라 나눠서 봐야할 것 같다.
셀러별 위치

가장 붉은 부분이 상파울로인데, 상파울로를 중심으로 그 주변부에 분포가 많다.
셀러를 분류하는 데 있어서 위치가 유의미할지는...모르겠다...
수익을 기준으로 셀러를 나눠보자
df.groupby('seller_id')['price'].sum().sort_values(ascending=False)단순히 셀러별로 그룹화를 해서 'price'의 합을 구했을 때
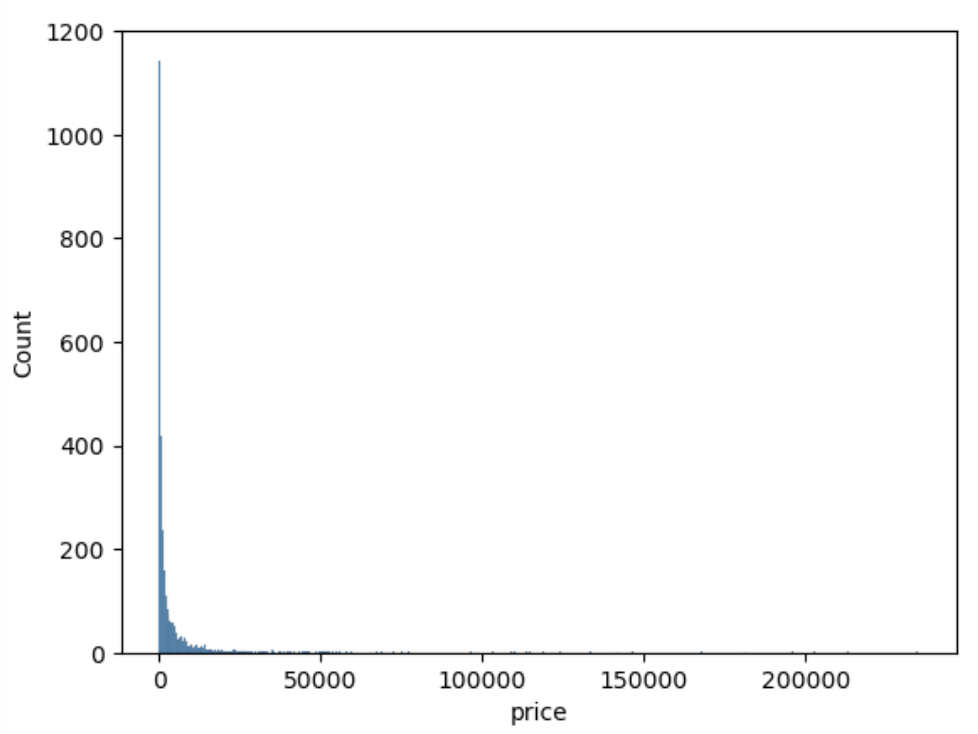
이런 분포가 나왔다.. 극단값이 엄청나다.
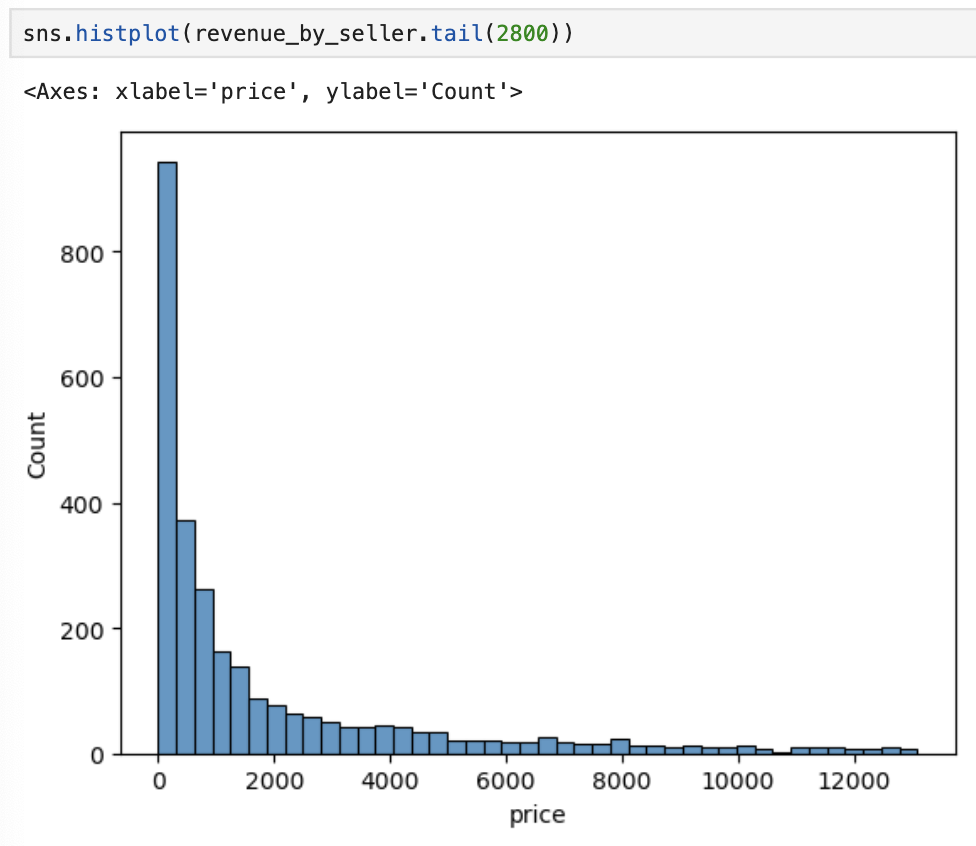

상위 10%만 떼어내도(사실상 상위 7% 정도,,) 분포가 이렇게 보인다.
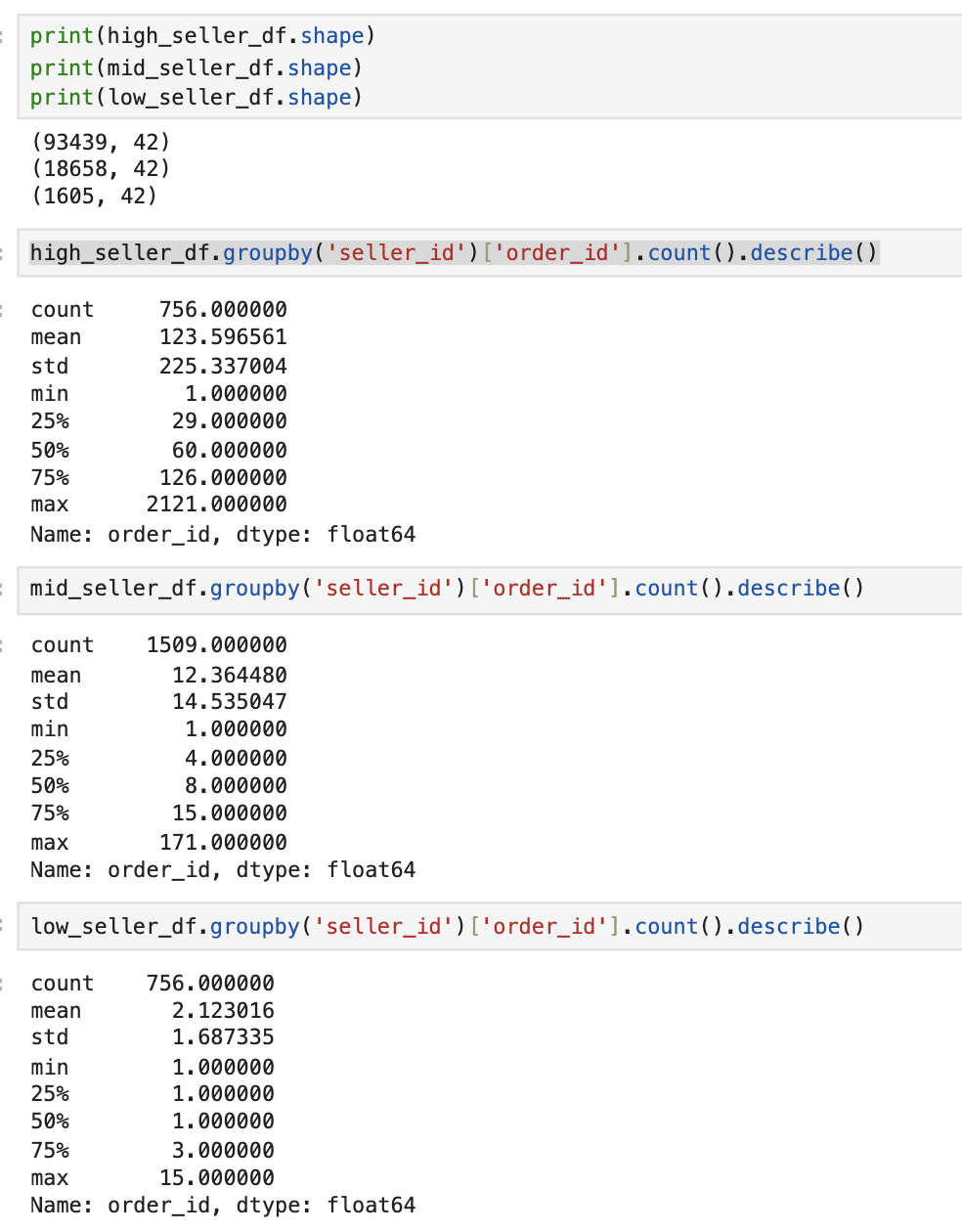
근데 수익이 높은 셀러들은 비싼 걸 팔아서라기 보다는 애초에 주문수 자체가 차이가 많이 나는 것 같다.
high_seller는 최대 주문건수가 2121건인데, low_seller는 최대가 고작 15건이다.
근데 high_seller에서 주문수가 1건인 경우는 뭐지???
- 하나는 art, 나머지 두개는 computer라고 한다.
- mid_seller에서 주문수가 1건인 경우도 보니까 payment_value순으로 봤을 때 상위권에는 역시나 computer가 꽤 있었음 (근데 같은 mid_seller로 분류지어놨다고 해도 가격 분포가 꽤 커서 유의미한 인사이트를 얻기는 어렵다고 판단했다..ㅜ)