JPA를 이용한 게시판 개발 중 사용하게 된 FetchType 관련 내용입니다.
여기서 Eager는 즉시 로딩 을 의미하고, Lazy는 지연 로딩을 의미합니다. 간단하게 설명하자면 말 그대로 즉시 로딩은 데이터 조회시 연관된 데이터까지 한 번에 불러오는 것이고, 지연 로딩은 필요한 시점에 연관된 데이터를 불러오는 것이라고 할 수 있습니다.
즉시 로딩
참조 블로그의 예시를 가져왔습니다.
@Entity
public class Member{
...
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name="team_id")
Team team;}
@Entity
public class Team{
@Id @GeneratedValue
private Long id;
private String teamname;
}이렇게 즉시 로딩을 사용하면 Member를 조회하는 시점에 바로 Team까지 불러오는 쿼리가 날아가고 이로 인해 한꺼번에 데이터를 불러오게 됩니다. 코드를 통해 확인을 해보자면
JPQL로 Member를 조회를 해보면
Member findMember = em.createQuery("select m from Member m", Member.class).getSingleResult();실제로 날아가는 SQL 코드는 다음과 같아집니다.
select
member0_.id as id1
member0_.team_id as team_id3_0_,
member0_.username as username2_0_
from
Member member0_
// 팀을 조회하는 쿼리
select
team0_.id as id1_3_0_,
team0_.name as name2_3_0
from
Team team0_
where
team0_id=?지연로딩
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name="team_id")
Team team;지연 로딩을 설정하고 멤버를 조회해보면 team을 조회하는 쿼리가 생성되지 않고 멤버를 조회하는 쿼리만 나갑니다. 참조 객체들의 데이터들은 무시하고 해당 엔티티의 데이터만을 가져오는 방식입니다.
Member findMember = em.createQuery("select m from Member m", Member.class).getSingleResult();실제 SQL은 다음과 같습니.
select
member0_.id as id1_0_,
member0_.team_id as team_id3_0_,
member0_.username as username2_0_
from
Member mbmer0_이렇게 되면 실세 Team을 사용하는 시점에 쿼리가 나가도록 할 수 있습니다. 그러니까 엔티티 조회시점이 아닌 엔티티 내의 연관관계를 참조할 때 해당 연관관계에 대한 SQL이 질의되는 기능이라는 뜻입니다. 엔티티 조회시엔 연관관계 필드는 프록시 객체로 제공됩니다.
Member findMember = EntityManager.find(Member.calss, 1L);
member.getTeam().getClass(); // 프록시 객체
member.getTeam().getName(); // 프록시객체 초기화 및 SQL 질의이것이 왜 장점이 되냐면 Member와 연관된 Team이 만약에 1,000개 이상이 된다면 엄청난 양의 SQL 쿼리가 나가게 됩니다.따라서 기본적으로 지연 로딩을 사용하는 것이 가장 좋습니다.
@_ToOne에서는 EAGER이 기본값, @_ToMany에서는 LAZY가 기본값입니다.
Fetch Join에 대해 알아보겠습니다.
일반 Join과 Fetch Join에 대한 차이를 짚어보면서 얘기해보려고 합니다.
일반 Join
= 연관 엔티티에 join을 걸어도 실제 쿼리에서 SELECT하는 엔티티는 오직 JPQL에서 조회하는 주체가 되는 Entity만 조회하여 영속화합니다.
= 조회의 주체가 되는 엔티티만 SELECT 해서 영속화하기 때문에, 데이터는 필요하지 않지만 연관 엔티티가 검색 조건에는 필요한 경우에 주로 사용됩니다.
JPQL
: Java Persistence Query Language로서 테이블이 아닌 엔티티 객체를 대상으로 검색하는 객체지향 쿼리입니다. SQL을 추상화해서 특정 DB SQL에 의존하지 않습니다. JPA는 이러한 JPQL을 분석한 후 적절하게 SQL을 만들어서 DB를 조회합니다.
영속성 컨텍스트
: 영속성 컨텍스트란 인스턴스로 존재하는 엔티티를 관리하고 영속화시키는 논리적 영역을 말합니다. 이때 영속화란 '사라지지 않고 지속되게 한다'는 것입니다. 쉬이 말하면 DB에 저장이 된다는 것입니다. 영속성 컨텍스트에서 관리하는 엔티티는 영속화 될 수 있는 가능성을 가진다고 인식하면 됩니다.
: 영속성 컨텍스트에서 엔티티를 관리하고 저장,조회, 수정, 삭제할 수 있는데 이러한 작업을 담당하는 객체가 바로 '엔티티 매니저'입니다.
Fetch Join
ex)
public intance MemberRepository extends JpaRepository<Member, Long>{
@Query("select m from Member m left join fetch m.team")
List<Member> findMemberFetchJoin()
}= 이렇게되면 회원 엔티티를 조회하면서 연관된 팀 엔티티도 함꼐 조회하게 됩니다. 프록시 객체로 가져오지 않고 Team 엔티티를 정확히 가져옵니다.
= 조회의 주체가 되는 Entity 이외에 Fetch Join이 걸린 연관 Entity도 함께 SELECT하여 모두 영속화 시킵니다.
= Fetch Join이 걸린 엔티티 모두 영속화 하기 때문에 , Lazy인 Entity를 참조하더라도 이미 영속성 컨텍스트에 들어있기 때문에 따로 쿼리가 실행되지 않은 채로 N+1 문제가 해결됩니다.
= 즉, 기존 SQL의 조인이 아니라 JPQL의 성능 튜닝을 위해 제공되는 Join입니다.
(fetch=FetchType.LAZY보다 우선시 됩니다.)
위에서 언급한 내용을 보다 더 잘 이해해보고자 영속화와 N+1 문제에 관해서도 언급을 해보고자합니다.
영속화
참조블로그의 예제를 살펴보겠습니다.
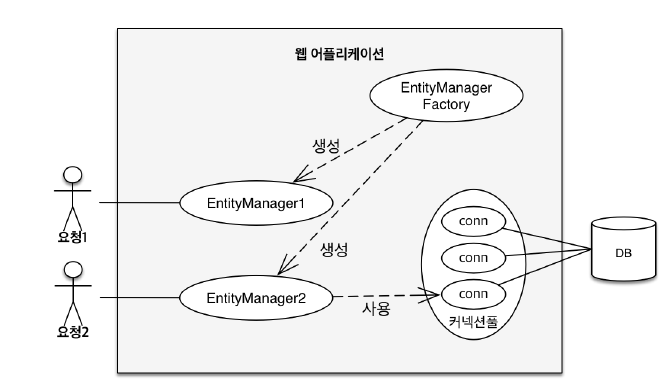
클라이언트의 요청이 올 때마다 엔티티 매니저 팩토리를 통해서 엔티티 매니저를 생성합니다. 생성된 엔티티 매니저는 내부적으로 DB 커넥션을 사용하여 DB에 접근합니다.
이때 영속성 컨텍스트란 위에서 언급했듯 '엔티티를 영구 저장하는 환경'을 의미하는 것입니다. 논리적인 개념으로서, 엔티티 매니저를 통해서 논리적인 공간인 영속성 컨텍스트에 접근 가능합니다. 스프링 프레임워크와 같은 컨테이너 환경에선 '엔티티 매니저'와 '영속성 컨텍스트'가 N:1의 관계를 갖습니다. 동일한 @Transactional이면 같은 영속성 컨텍스트에 접근합니다.
영속화라는 개념을 이해하기 위해서는 엔티티의 4가지 생명주기를 살펴 보아야 합니다.
- 비영속 상태
= 엔티티를 생성하고 영속성 컨텍스트에 아직 집어넣지 않은 상태입니다. 비영속 상태의 엔티티는 영속성 컨텍스트로부터 어떠한 관리도 받지 못합니다. - 영속 상태
= 엔티티를 persist 메서드를 통해서 영속성 컨텍스트 안에 집어넣었다면, 엔티티는 영속 상태가 되고, 영속성 컨텍스트로부터 지속적인 관리를 받습니다. - 준영속 상태
= 엔티티가 영속성 컨텍스트에 저장되었다가 분리된 상태를 의미합니다. - 삭제
= 엔티티가 삭제된 상태를 의미합니다.
영속성 컨텍스트의 내부는 다음과 같습니다.
- 1차 캐시
엔티티가 영속화 되면! 엔티티는 '영속성 컨텍스트' 내부의 1차 캐시라는 공간에 저장됩니다. 여기는 key와 value로 이루어진 저장소로서 key값으로는 엔티티의 id값이 들어가고, value로는 엔티티가 들어갑니다.
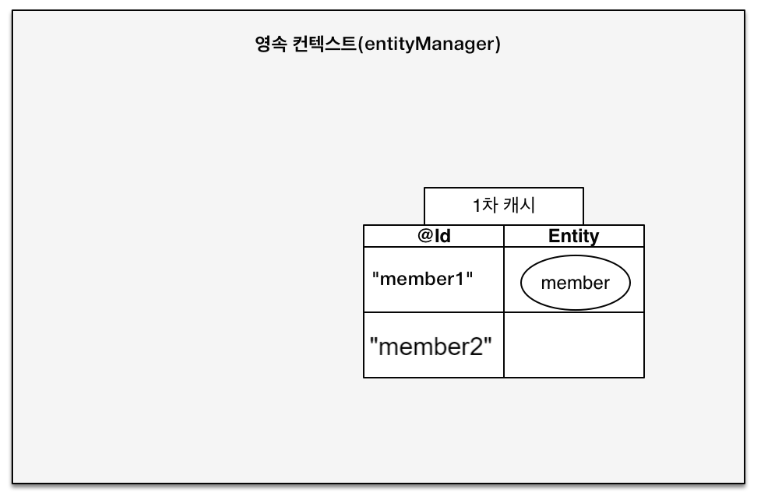
: 이러한 구조에서 우리가 member1이란 ID를 가지는 엔티티를 '저장' 한 뒤 같은 엔티티를 조회한다면 DB로는 아무 쿼리도 날라가지 않게 됩니다. 왜냐면 DB에 접근할 필요없이 1차 캐시의 ID값을 참조해서 엔티티를 조회해오면 되기 때문입니다.
: 1차 캐시에 조회하려는 엔티티가 존재하지 않는다면
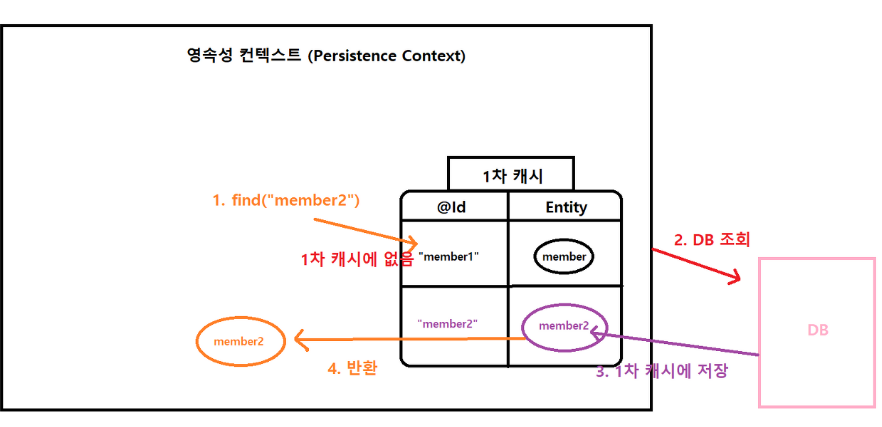
- 쓰기 지연 SQL 저장소
: persiste로 엔티티를 영속성 컨텍스트에 등록하면, SQL 쿼리로는 INSERT 쿼리가 동작합니다. 하지만 이 쿼리는 "쓰기 지연 SQL 저장소"라는 가상 공간에 저장되므로, 트랜젝션을 커밋하기 전까지는 DB로 INSERT 쿼리가 보내지지 않습니다.
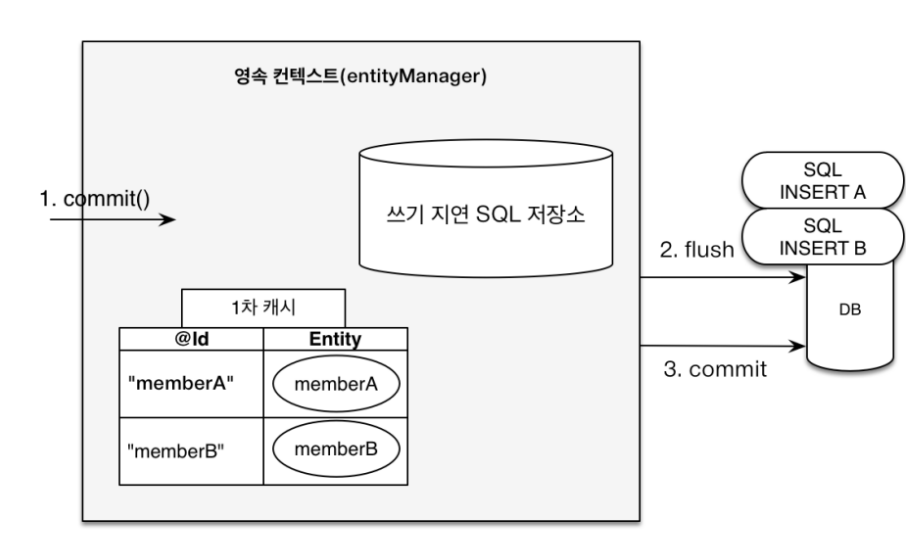
여기에 보관된 쿼리들은 트랜젝션 커밋이 일어나면 일관적으로 DB에 적용이 되는 것인데, 더 세분화 시켜보면 트랜젝션이 커밋되기 전에 flush라는 코드가 동작합니다. flush는 "쓰기 지연 저장소" 내부에 있는 SQL 쿼리들을 모두 DB로 반영시켜버립니다. 중요한 것은 1차 캐시에 있는 데이터는 건드리지 않으므로! flush이후에도 정상 유지된다는 것입니다.
그러니까 영속성 컨텍스트란 간단히 말해서 엔티티를 저장하고 관리하는 저장소의 개념입니다.
영속성 컨텍스트 는
- 엔티티를 식별자 값으로 구분하고
- 여기에 저장된 엔티티는 transaction을 커밋하는 순간 DB에 반영됩니다. (=flush)
flush란 영속성 컨텍스트의 변경 내용을 DB에 동기화하는 작업을 의미합니다.
- 장점으로는
- 차 캐시 : 효율성 증가
- 동일성 보장 : 같은 엔티티 조회시 컨텍스트에 존재하는 엔티티를 바로 반환.
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
이 있습니다.
(+)변경감지
JPA에서 엔티티를 수정할 때에는 엔티티를 조회하고 데이터를 변경해주기만 하면 됩니다.
Member findMember = entityManager.find(Member.class, "id001");
// 영속 엔티티 데이터 수정
findMember.setUsername("더블에스");
// entityManager.update(findMember);를 안해줘도 된다.이렇게 엔티티 변경 사항을 DB에 자동으로 반영하는 것을 변경감지라고 합니다. 이것이 어떻게 동작하냐면 JPA는 영속성 컨텍스트에 보관할 때 최초 상태를 복사해서 저장해두는데 이것을 '스냅샷'이라고합니다. 그리고 플러시 시점에서 스냅샷과 엔티티를 비교해서 변경된 엔티티를 찾게 됩니다.

앞서 간단히 언급한 N+1 문제란 다음과 같습니다.
N+1 문제
: 실무에서 즉시로딩을 주로 사용하지 않는 이유가, 즉시로딩을 사용하면 예상하지 못한 SQL이 발생하고 N+1 문제를 발생시키기 때문입니다.
: 여기서 N+1문제는 한 번 쿼리를 날렸는데, 추가로 N번 더 쿼리문을 날려야하는 상황을 말합니다.
: Post:comment = 1:N 관계를 예시로 설명드리겠습니다.
-
@OneToMany 애노테이션 fetch를 즉시로딩으로 변경한 상태에서 4개의 post와 각 post에 2개의 comment를 생성하고 나서 findAll() 메서드로 조회를 하게된다고 생각해봅시다.
= 이렇게 된다면 post select 쿼리를 실행하게 되는데, 이 과정에서 해당 post에 대해서 comment를 조회하기 위해서 post의 수 만큼 4번의 쿼리가 추가로 발생하게 됩니다.
-> 이것을 가장 빠르게 해결하는 방법은 '지연 로딩'으로 변경하는 것입니다. 이렇게 변경한다면 findAll() 메서드로 호출하면 지연 로딩이므로 post SELECT 쿼리만 실행되게 됩니다.
-> 이 경우에는 실제 Comment의 값을 조회하는 경우에만 해당 select 쿼리가 발생하게 됩니다. -
@OneToMany에서 지연 로딩으로 변경하고 loop로 조회해도 N+1 문제가 발생합니다.
@Transactional
@Test
public void test_N1_문제_발생_지연로딩설정_loop으로_조회하는_경우() throws JsonProcessingException {
savePostWithComments(4, 2);
List<Post> posts = postRepository.findAll(); //N+1 발생하지 않는다
List<Comment> commentList;
for (Post post : posts) {
commentList = post.getCommentList();
log.info("post author: {}", commentList.size()); //N+1 발생한다
}
}-> 지연 로딩으로 findAll()을 실행하면 Post 객체 관련된 정보를 조회합니다.
-> 여기서Comment 정보를 조회하면, Post에 대한 조회는 이미 끝난 상태여서 JOIN으로 쿼리가 생성이 안됩니다. 단지 POST에 대한 정보ID로 조회할 수 밖에 없어서 where comment.postId=? 형식으로 JPQL 쿼리를 생성한다. 이로 인해 매번 조회 쿼리가 생성이 되어 N번 실행되는 이슈가 바생됩니다.
이를 해결하기 위해서
- JPQL에 fetch join 키워드를 사용해서 join 대상을 함께 조회할 수 있습니다. Post 조회시 p.commentList도 같이 조인에서 조회해옵니다.
@Repository
public interface PostRepository extends JpaRepository<Post, Long> {
@Query("select p from Post p left join fetch p.commentList")
List<Post> findAllWithFetchJoin();
}지연 로딩 설정 이후에 Loop를 사용하면 그 전 예제에서는 N+1이 발생하는데 findAllWithFetchJoin() 메서드 실행할 때에는 관련 대상을 한 번에 조회하여 N+1 이슈가 발생하지 않습니다.
@Transactional
@Test
public void test_N1_문제_해결방법_fetch_join_사용() {
savePostWithComments(4, 2);
List<Post> posts = postRepository.findAllWithFetchJoin(); //한번에 조회해온다.
List<Comment> commentList;
for (Post post : posts) {
commentList = post.getCommentList();
log.info("post author: {}", commentList.size()); //N+1 발생하지 않는다
}
}2. Batch size 지정 + 즉시 로딩
: JPQL 패치 조인 대신 배치 크기를 지정하는 방법도 있습니다. @BatchSize 어노테이션에 사이즈를 지정하고 fetch 타입은 '즉시'로 설정합니다.
@Table(name = "post")
public class Post extends DateAudit {
...(생략)...
@JsonIgnore //JSON 변환시 무한 루프 방지용
@BatchSize(size = 2) //batch size를 지정한다
@OneToMany(mappedBy = "post", fetch = FetchType.EAGER) //즉시로딩으로 변경한다
private List<Comment> commentList = Lists.newArrayList();
}@Transactional
@Test
public void test_N1_문제_해결방법_증시로딩설정_loop으로_조회하는_경우() throws JsonProcessingException {
savePostWithComments(4, 2);
List<Post> posts = postRepository.findAll(); //배치 사이즈만큼 조회해온다
}findAll로 호출할 떄마다 where in 쿼리를 사용하여 배치 사이즈만큼 조회해오고, 배치 사이즈를 넘는 경우에는 추가로 조회해오는 쿼리가 생성됩니다. 배치 사이즈 지정으로 해결하는 방법은 '즉시 로딩'으로 변경해야하고 또한 배치 사이즈 만큼만 조회할 수 있으므로 N+1 방법을 완벽히 해결하는 것은 아니므로... 권장하는 해결법은 아닙니다.
