
호기롭게 시작한 두 번째 리팩토링 주제이다. (아직도 리팩토링 할 건 차고 넘친다)
그리고 역시나.. 삽질과정답게 결과물은 아무것도 없다(?)
그래도 고민의 과정이 의미있다고 생각하기 때문에 일단 시작 ~ ~ ~
1. 개요
우리 프로젝트에는 모든 감정 게시물을 긁어와서 화면을 보고 있는 사용자가 좋아요 한 글이면 like=True를 세팅해주는 로직이 존재한다.
public BasicResponseDto<List<EmotionDto>> getAllEmotionDtos(EmotionSearchDto emotionSearchDto, Principal principal) {
String type = emotionSearchDto.getType();
Account account = get_account(principal);
List<Emotion> result;
List<EmotionLike> liked = emotionLikeRepository.findByAccount(account);
if (type.equals("private")) {
result = emotionRepository.findAllByAccount(account);
} else if (type.equals("public")) {
// public 한 애들 -> 시간 순
result = emotionRepository.findAllPublicStatus(Sort.by("createdDateTime").descending());
} else {
throw new InvalidInput(EMOTION,EMOTION_TYPES_EXCEPTION);
}
List<EmotionDto> emotionDtos = result.stream().map(emotion -> entityToDto(emotion))
.collect(Collectors.toList());
for (EmotionDto emotionDto : emotionDtos) {
for (EmotionLike emotionLike : liked) {
if (emotionLike.getEmotion().getId() == emotionDto.getId()) {
emotionDto.setLike(true);
}
}
}
return new BasicResponseDto<>(HttpStatus.OK.value(), "emotion", emotionDtos);
}이와 같은 로직인데,
코테 준비 등 모종의 이유로 이중 for문을 거의 금기시하다보니 해당 코드를 보고 뭔가 죄를 짓는 듯한(?) 기분이 들었다.
전체 Emotion(게시글)을 다 ~ 읽어오고 해당 사용자가 좋아하는 Emotion을 다 읽어 온 다음 그걸 이중 for문으로 비교해서 DTO에 like 값을 세팅해주는 코드가 과연 최선인가..?
개선할 방법이 분명 존재할 것 같아 이와 관련한 내용을 github에 이슈로 등록하고!
리팩토링을 시작했다.
2. 해결 방법에 대한 고민
해당 로직을 수정하는게 단순한 문제라고 생각했는데, 고민을 하다보니 전혀 아님을 알게 됐다. 생각보다 이중 for문을 제거하고 내가 원하는 로직을 구현하는게 쉽지 않았던 것이다.
한 Account(사용자)는 여러 Emotion에 좋아요를 만들 수 있고, 한 Emotion(게시글)은 여러 Account에게 좋아요를 당할 수 있다.
이러한 관계로 인해, "좋아요 한 게시글"과 "좋아요하지 않은 게시글"을 모두 조회하는 로직은 필연적으로 최악의 경우 O(N^2)의 복잡도를 띄게 되는 것이다. (더 나은 방법이 있다면 알려주세요💧)
여기서 아직도 의문인점은 사람이 겁~나 많고 좋아요도 정~말 많은 인스타그램 같은 곳에서는 어떻게 효과적으로 "좋아요 한 게시글" 정보를 가져오는걸까?? 영어로도 한국어로도 하루죙일 서치해봤는데 전혀 모르겠다😂😂😂😂 좀 더 찾아봐야겠다
(1) JOIN으로 해결해볼까?
그렇다면 애초에 DB에서 값을 가져올 때 JOIN 해서 가져오면 비용을 줄일 수 있지 않을까?
(2) 과연 JOIN은 성능에 긍정적인 영향을 미치는가?
JOIN을 하기 전, 알아야하는 것이 바로 과연 JOIN이 성능에 도움이 되는가?이다.
생각해보니 JOIN이 어떻게 동작하는지 구체적인 방식을 모르기 때문에, 이것이 비즈니스 코드에서의 이중 FOR문보다 더 나은 방식일 것이라고 확신할 수가 없었다.
그래서 관련 자료를 찾아보니 역시나! 기본적으로 선택하는 Nested Loops Join 방식이 이중 for문과 별반 차이 없이 동작하고 있었다😂
그래서 선택한 JOIN 방식이 바로 subquery를 활용하여 최대한 탐색의 범위를 좁히고, 우리가 필요한 것이 바로 Emotion 전체 row이므로 LEFT JOIN을 활용하는 것이다.
그래서 탄생한 쿼리가 바로
SELECT * FROM emotion AS a LEFT JOIN (SELECT emotion_id FROM emotion_like WHERE account_id = 10) AS b ON a.id = b.emotion_id;이다.
(3) 실행 계획 분석해보기
해당 쿼리의 실행 계획은 아래와 같다.

두 번째의 type이 ref임이 확인된다.
왜냐하면 JOIN의 조건이 되는 컬럼 account_id가 기본키도 아니고, 인덱스도 걸려있지 않기 때문이다.
그렇다면 여기서 고민이 든다
account_id 컬럼에 인덱스를 걸면 조회 성능이 더 빨라지지 않을까?
고민을 해봤지만, 결론적으로는 해당 컬럼에 인덱스를 설정하지 않기로 결정했다.
왜냐하면
-
account_id 컬럼은 중복성이 높아서 인덱스의 효과가 떨어질 것이다..
한 사용자가 여러 Emotion을 like할 수 있기 때문이다. -
EmotionLike에는 수정이 많이 발생한다.
좋아요는 쉽게 변경될 수 있는 내용이기 때문에 해당 테이블에 변경이 가해질 일이 많을 것이고, 이렇게 된다면 인덱스가 성능저하의 원인이 될 수도 있다.
이러한 원인으로 인해 EmotionLike 테이블에 인덱스 설정을 하지 않게 된 것이다.
그리고 애초에 EmotionLike의 emotion_id와 함게 비교되는 Emotion의 id 컬럼이 PK로서 자동적으로 인덱스가 설정되어있기 때문에, 위의 부담을 지고서라도 EmotionLike에 추가적으로 인덱스를 설정할 이유가 없었다.
맨날 이론으로만 보던 지식을 복합적으로 적용해 결정한 내용이었어서 나름 의미 있었다. 결국 변한건 크게 없지만 😂
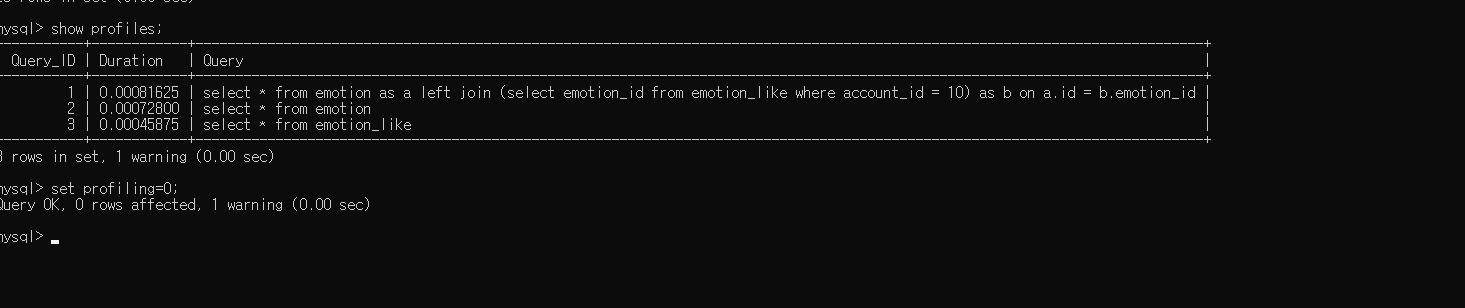
(4) profiling을 활용한 성능 조회
mysql의 profiling을 활용하여 쿼리 실행 시간을 측정해본 결과는 다음과 같다.
(5) JPA의 FROM 절에 subquery?
과연 API적으로도 유의미한 결과물이 나올까 확인하고 싶어 직접 EmotionRepository의 코드를 수정했다.
하지만 @Query 어노테이션 파라미터로 넣어준 SQL 구문에서 자꾸 예외가 발생했다.
대체 무엇이 문제인고..싶어서 찾아보니
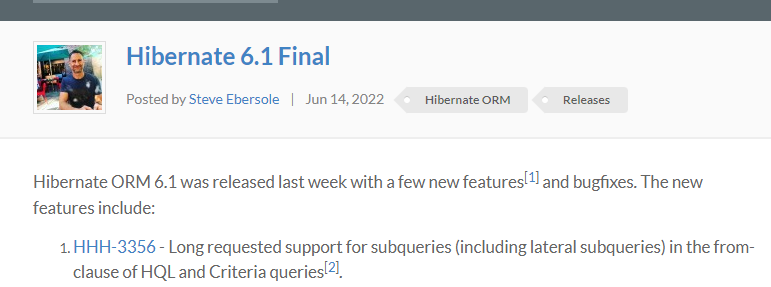
JPA의 FROM 절에서는 Subquery가 지원되지 않는다는 이슈가 있었던 것이다. .!
찾아 본 결과 hibernate 6.1에서는 지원이 되는 것 같긴 하다(?)
https://in.relation.to/2022/06/14/orm-61-final/
subquery가 지원되지 않는다면 기존 로직을 수정할 이유가 전혀 없다.
애초에 해당 쿼리의 최대 개선 점이 서브 쿼리를 활용하여 비교 대상 테이블의 row 개수를 줄이는 것이었기 때문이다 ㅠㅠ
정말.. 삽질 그 자체이다 🤢
3. 결론
하지만 이대로 끝날 순 없다! 싶어서 기존 코드를 조금이나마 개선하고자 시도했다.
(1) sort 로직 수정
Emotion row들을 다 받아와서 createdtime에 따라 내림차순 정렬하는 기존 코드는 아래와 같았다.
// EmotionRepository
@Query("SELECT e FROM Emotion e WHERE e.status = 'PUBLIC'")
List<Emotion> findAllPublicStatus(Sort sort);// EmotionService
...
emotionRepository.findAllPublicStatus(Sort.by("createdDateTime").descending());Repository에서 DB에 접근해서 받아 온 결과물을 파라미터로 넘어온 Sort를 활용해 정렬해주는 코드였다.
그런데 이미 Repository 내 코드가 @Query를 활용하고 있는데 Sort 객체를 추가로 생성해 줄 필요가 있을까?
큰 의미가 없을 것 같아서 아래와 같이 코드를 변경하였다.
//EmotionRepository
@Query("SELECT e FROM Emotion e WHERE e.status = 'PUBLIC' order by e.createdDateTime desc")
List<Emotion> findAllPublicStatus();// EmotionService
...
result = emotionRepository.findAllPublicStatus();
...(2) 잘못된 로직 해결
public BasicResponseDto<List<EmotionDto>> getAllEmotionDtos(EmotionSearchDto emotionSearchDto, Principal principal) {
String type = emotionSearchDto.getType();
Account account = get_account(principal);
List<Emotion> result;
List<EmotionLike> liked = emotionLikeRepository.findByAccount(account);
if (type.equals("private")) {
result = emotionRepository.findAllByAccount(account);
} else if (type.equals("public")) {
// public 한 애들 -> 시간 순
result = emotionRepository.findAllPublicStatus(Sort.by("createdDateTime").descending());
} else {
throw new InvalidInput(EMOTION,EMOTION_TYPES_EXCEPTION);
}
List<EmotionDto> emotionDtos = result.stream().map(emotion -> entityToDto(emotion))
.collect(Collectors.toList());
for (EmotionDto emotionDto : emotionDtos) {
for (EmotionLike emotionLike : liked) {
if (emotionLike.getEmotion().getId() == emotionDto.getId()) {
emotionDto.setLike(true);
}
}
}
return new BasicResponseDto<>(HttpStatus.OK.value(), "emotion", emotionDtos);
}기존 코드를 다시 보면 로직적으로 무언가 문제가 있음을 알 수 있다.
-
private한 Emotion은 좋아요를 설정해 줄 필요가 없음에도 불구하고 해당 이중 for문을 거치도록 설계되었다.
-
좋아요 한 게시글을 발견했으면 나가면 되는데 내부 for문이 무조건 끝까지 다 돌게 설계되어있다.
그래서 아래와 같이 수정하였다.
if (type.equals("public")) {
for (EmotionDto emotionDto : emotionDtos) {
for (EmotionLike emotionLike : liked) {
if (emotionLike.getEmotion().getId() == emotionDto.getId()) {
emotionDto.setLike(true);
break;
}
}
}
4. 추후 과제
전반적으로 고민은 많았지만 수정된건 하나도 없는(?) 리팩토링이었다.
그래도 인덱스, JOIN 등 본질적인 부분에 대해 새롭게 고민할 수 있었어서 나름 의미는 있었다
하지만 그렇다고 해당 코드가 최선의 코드가 된 것은 아니다.
내 이후 과제는 아래와 같다 :) 얼른 해내야징
(1) 캐싱
보통의 좋아요 최적화는 캐싱을 활용한다고 한다.
따라서 다양한 레퍼런스를 참조하여 최적의 캐싱을 구현하여 Emotion을 불러오는 순간순간마다 이중 for문을 도는 코드를 개선해보고자!!!! 노력할 것이다.
개인적으로 캐싱 서버는 처음 도입해보는거라 걱정도 되고 설레기도 한다.
짬짬히 계속 시도해야징
(2) N:M 관계 매핑
코드를 보면서 생각한 부분인데, Account:Emotion 의 N:M관계를 풀어주기 위해 도입한 EmotionLike 객체엔 필드값으로 Emotion과 Account가 존재한다.
그런데, 단순히 관계를 풀어주는 것만이 목적이라면 객체를 필드로 갖고 있는 것이 아니라 id만을 필드로 갖고 있으면 더 수월하게 관리가 되지 않을까?? 라는 생각이 들었다.
당시에 내가 어떤 레퍼런스를 참조하면서 해당 기능을 구현했는지 기억이 잘 나지 않아 함부로 고치지 못했다.
N:M 관계 관련해서 더 찾아보고! 내 생각이 합당한 것 같으면 수정해야겠다 :):)
(3) 이중 for문 로직 알고리즘 적으로 해결할 수 있을까?
이중 for문 조회를 알고리즘적으로 해결할 수도 있지 않을까??
시도를 해봐야겄다
삽질의 과정은 정말 힘들지만 이만큼 빨리 성장할 수도 없는 것 같다.
아직 한참~~~ 남은 리팩토링이니까 화이팅해봐야지!
느리지만 꾸준히 해내는게 내 최종 목표이다
으하하하
