
- 컴퓨터에서 알파벳이나 한글 등의 문자는 어떻게 나타낼까요?
- 지난 포스팅에서 알아본 것처럼 컴퓨터는 이진법을 통한 숫자밖에 사용할 수 없기 때문에 저희는 컴퓨터에 나타나는 문자, 이미지, 이모티콘 등을 이진수에 대응하여 변환해야합니다.그래서 이를 변환하기 위한 약속(표준)을 정해놓았습니다.
- 이 약속 중 유명한 것 하나는 설명미국정보교환표준부호 ASCII(아스키코드/American Standard Code for Information Interchange)입니다.
ASCII(American Standard Code for Information Interchange)
- 아스키 코드(ASCII)는 미국 ANSI(미국 국가표준 협회)에서 표준화한 정보 교환용 7비트 부호체계입니다.
- 대부분의 문자 인코딩이 아스키 코드에 기초를 두며 컴퓨터와 통신 장치 등 문자를 많이 사용하는 장치에 사용합니다.
- 아스키 코드는 8비트가 아닌 7비트만 사용되는데 나머지 1비트는 통신 에러 검출을 위해 사용됩니다.
- 1비트는 패리티 비트(parity bit)라고 하여 7개의 비트 중 1의 갯수가 홀수면 1, 짝수면 0으로 나타내어 통신 정보가 도중에 변질되었는지 수신할 때 한번 확인해주는 용도로 사용됩니다.
- 아스키 코드는 7비트이므로 0~127까지 128개의 문자로 이루어져있습니다. 이는 출력 불가능한 제어 문자 33개, 출력 가능한 문자 95개로 이루어집니다.
- 이는 또한 영어 대소문자 52개 + 숫자 10개 + 특수문자 33개 + 제어문자 33개 = 128개으로 구분할 수도 있습니다.
아스키 코드 표
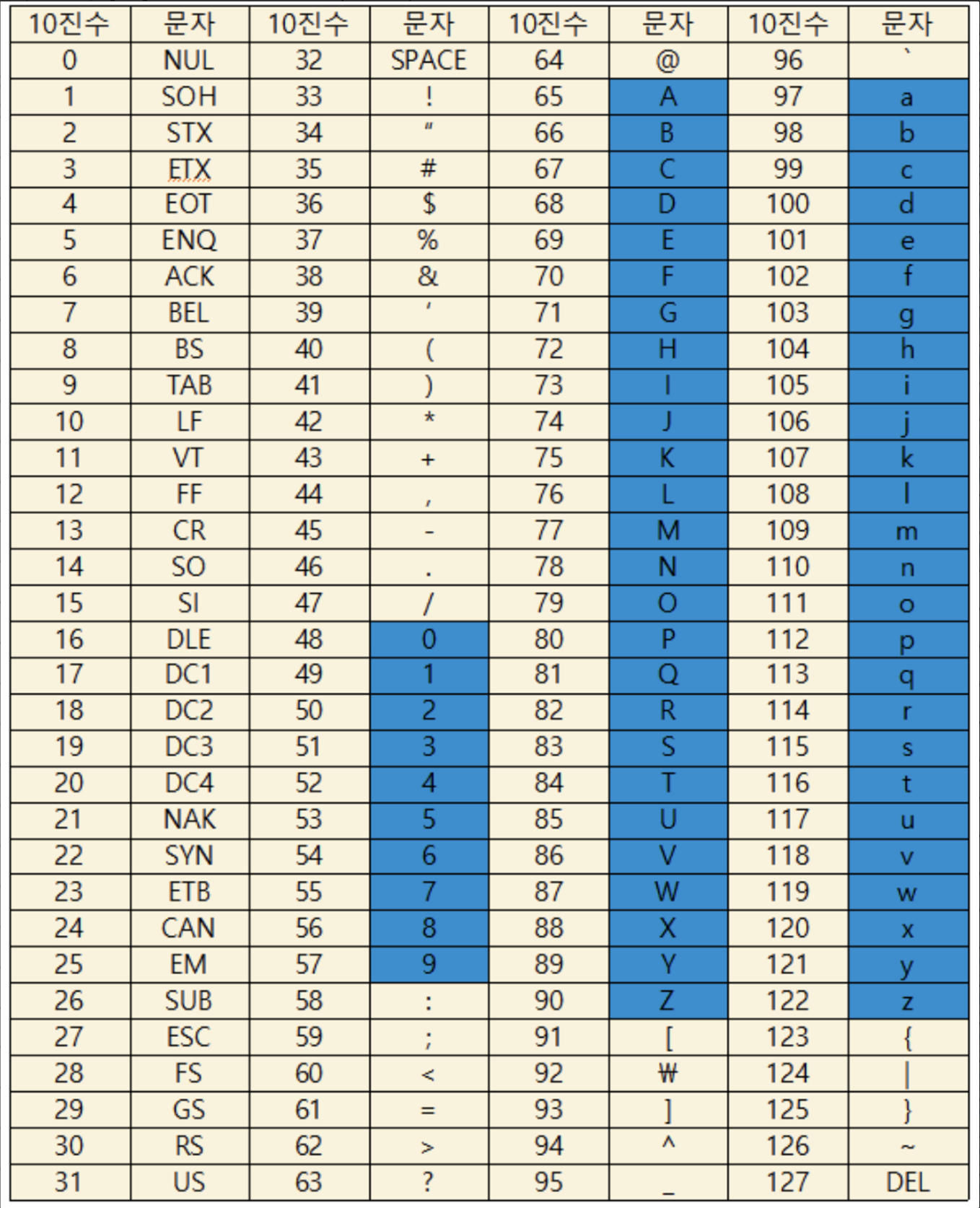
- 여기서 0~31과 127은 위에서 말했던 출력이 불가능하고 정보 표현보다는 화면 제어나 장치 제어를 위한 제어 문자입니다.
- 제어 문자는 전송 제어, 서식 제어, 특수 제어, 정보 분리 제어으로 구성되며 자세히 알고 싶으신 분들은 정보통신기술용어해설을 보시는 것을 추천드립니다!
- 위 아스키 코드에서 A는 10진수로 65입니다. 이를 컴퓨터에서 표현하기 위해 이진수로 나타낸다면 다음과 같습니다.
65 = (2^6) * 1 +... (2^3) * 0 ...+(2^0) * 1 = 1000001- 하지만 이러한 128개의 아스키 코드로는 한글, 이모티콘 등을 모두 표현할 수 없습니다.
- 그래서 이들을 나타내기 위해 나온 것이 유니코드입니다.
유니코드
- 유니코드는 아스키 코드로는 담을 수 없는 세상의 모든 문자를 담기 위해 2byte(65536개)로 문자를 숫자로 변환하기 위한 약속이었습니다.
- 유니코드 공식 홈페이지의 소개를 보면 유니코드를 다음과 같이 설명하고 있습니다.
The design of Unicode is based on the simplicity and consistency of ASCII, but goes far beyond ASCII's limited ability to encode only the Latin alphabet. The Unicode Standard provides the capacity to encode all of the characters used for the written languages of the world. To keep character coding simple and efficient, the Unicode Standard assigns each character a unique numeric value and name.
유니코드의 디자인은 ASCII의 단순성과 일관성을 기반으로 하지만 라틴 알파벳만 인코딩하는 ASCII의 제한된 기능을 훨씬 뛰어넘습니다. 유니코드 표준은 전 세계의 문자 언어에 사용되는 모든 문자를 인코딩하는 기능을 제공합니다. 문자 코딩을 간단하고 효율적으로 유지하기 위해 유니코드 표준은 각 문자에 고유한 숫자 값과 이름을 할당합니다.
- [The Unicode® Standard: A Technical Introduction](https://www.unicode.org/standard/principles.html)
- 하지만 처음에 65536개로 모든 문자를 담을 수 있을 것이라는 생각과는 달리 쓰지 않는 고어나 토속어, 악보 기호, 이모지, 태그, 마작이나 도미노 기호 등의 문자를 담기 위해서는 2byte로 부족했기 때문에 이를 해결하기 위해 유니코드 3.0부터 보충 언어판을 정의하였습니다.
- 위에서 언급한 기존의 2바이트에서 2바이트를 추가하여를 상위대행 1byte(high surrogates, 1024자), 하위대행 1byte(low surrogates, 1024자)로 할당한 뒤 이 둘의 조합으로 1024 x 1024 = 1,048,576 약 백만자가 넘는 문자를 추가로 정의했습니다.
- 유니코드 최신 기술 발표에 의하면 이 글을 작성하는 시점 중 가장 최신(2023.09.12)의 버전인 유니코드 15.1에는 이전 버전보다 627자가 추가되어 총 149,813자가 되었다고 합니다!
- 이렇게 하여 총 110만개가 넘는 문자를 지정할 수 있게된 유니코드는 이를 2byte에 해당하는 65536개로 나누어 17개의 구역으로 나누었습니다. 이 구역을 평면이라하며 총 0~16까지의 평면이 생겼고 이 평면은 1개의 기본언어판(Basic Multilingual Plane, BMP)와 16개의 보충언어판(SMP)으로 구성됩니다.
- 17개의 평면 중 현재는 7개만 사용되고 10개는 아직 사용되지 않고 있습니다. 반 이상이 현재 미할당 상태이며 앞으로 어떤 문자를 추가할지 나타내는 로드맵이 따로 있습니다.
UTF
- 컴퓨터에서 이러한 유니코드를 통해 문자를 2진수로 저장하는 것을 인코딩이라고 합니다.
- 이러한 유니코드 문자를 컴퓨터에서 인코딩하는 방식을 정의하였는데 이를 UTF(Universal Coded Character Set Transformation Format)라고 합니다.
- UTF는 유니코드 문자 집합을 실제로 컴퓨터 시스템에서 사용할 수 있도록 변환하는 방식을 제공하며 대표적인 UTF 인코딩 방식으로는 UTF-8, UTF-16, UTF-32가 있습니다.
UTF-8
- UTF-8은 가변 길이 문자 인코딩 방식으로, 각 문자를 1바이트 ~ 4바이트로 사용하여 표현합니다. ASCII 코드와의 호환성을 가지며,ASCII 문자는 1바이트로 표현되고, 그 외의 유니코드 문자는 2바이트 이상을 사용합니다. 웹에서 가장 널리 사용되는 인코딩 방식 중 하나입니다.
- UTF-8은 영문 중심의 텍스트에 효율적이며, 웹 개발에 널리 사용됩니다. 저장 공간과 호환성을 중시할 경우 유리합니다.
UTF-16
- UTF-16 또한 가변 길이 문자 인코딩 방식으로, 각 문자를 2바이트 ~ 4바이트를 사용하여 표현합니다. 위에서 얘기했듯이 기본 다국어 평면(Basic Multilingual Plane, BMP)에 속한 문자는 2바이트로 표현되며, BMP를 벗어난 추가 문자는 SMP에서 상위 대행(surrogates)과 하위 대행(surrogates)의 조합을 통해 4바이트로 표현됩니다.
- UTF-16은 아시아 언어 등 BMP를 벗어난 문자가 자주 사용되는 경우 효율적일 수 있으나, 문자에 따라 가변 길이를 사용하기 때문에 처리 복잡성이 증가할 수 있습니다.
UTF-32
- UTF-32는 모든 유니코드 문자를 4바이트로 표현하는 고정 길이 인코딩 방식입니다.
- UTF-32는 모든 문자를 동일한 길이로 처리할 수 있어 프로그래밍 측면에서 간단하지만, 1바이트로 처리가능한 문자도 4바이트로 처리하기 때문에 저장 공간 측면에서 비효율적일 수 있습니다.
UTF-8과 UTF-16
- 이렇게 알아봤으면 “UTF-8과 UTF-16는 같은 가변 길이 문자 인코딩 방식이고 문자 표현의 최소 범위만 다른데 어떤 차이가 있지?”라는 생각이 들 수도 있습니다.
- UTF-8과 UTF-16는 인코딩 방식이 다릅니다. UTF-16은 영어나 숫자를 표현하는데도 16bit를 사용하기 때문에 만약 “A”를 표현한다면 0000 0000 0100 0001로 표현하여 앞의 8bit는 아무 의미없이 사용됩니다. 하지만 UTF-8은 최소 표현 단위가 1byte이기 때문에 7bit로 표현 가능한 문자는 7bit 그대로 표현이 가능합니다.
- 그렇다면 무조건 UTF-8이 좋은가? 그것도 아닙니다. UTF-8에서는 8bit가 넘어가는 문자에 대해서는 8bit씩 끊어서 문자를 해석하기 때문에 8bit가 넘어가는 문자를 구분하기 위해 구분자가 사용됩니다. 그래서 한글을 UTF-16에서 표현한다면 2byte를 사용하면 되지만 UTF-8에서 인코딩한다면 3byte가 필요합니다.
- 따라서 인코딩 방식은 상황에 따라 잘 사용하는 것이 좋습니다. 아스키 코드 안의 문자가 주로 사용된다면 UTF-8이 유용하겠지만 그 외의 문자를 사용한다면 UTF-16이 유용할 수 있습니다.
- 제가 주로 사용하는 JAVA의 JVM(Java Virtual Machine)은 문자열을 메모리에 저장할 때 UTF-16 방식을 기본으로 사용합니다.
- 그렇다면 JAVA는 왜 UTF-16을 기본으로 사용하는지 알아보겠습니다.
JVM은 왜 UTF-16을 기본으로 사용할까?
- JAVA는 2004/2005년에 UTF-16으로 전환하기 전 UCS-2를 사용하였다고 합니다. 하지만 UCS-2는 고정적으로 2바이트를 사용하기 때문에 표현할 수 있는 글자 수가 65536개 밖에 되지 않았고 시스템 간 문자열을 주고받을 때의 문제점이 있었기 때문에 UTF-16으로 전환하였습니다.
- 위에서 설명했듯이 UTF-16은 surrogate의 사용으로 문자를 저장할 수 있는 공간이 엄청나게 커졌기 때문에 이는 효율적인 선택이었다고 볼 수 있을 것 같습니다.
- 하지만 UTF-8을 선택하지 않고 UTF-16을 선택한 이유는 무엇일까요?
- UTF-8은 메모리효율에 비효율적이고 다국어 지원에 문제가 있기 때문입니다.
- 우선 위 UTF-8과 UTF-16의 차이점에서 말했듯 UTF-8은 영어 이외의 문자에 더 많은 바이트를 사용하여야 했고 이는 메모리 효율성에서 문제를 가집니다.
- 또한 자바가 영어권에서만 사용될 것이 아니라면 영어 이외의 문자를 인코딩할 때도 효과적인 방법을 제공해야하기 때문에 여러 언어에 효율적인 UTF-16을 기본으로 사용하였습니다.
결론
- 유니코드는 전 세계의 모든 글자를 이진수로 표현하여 컴퓨터에서 사용하기 위한 체계입니다.
- 유니코드의 각 글자는 코드 포인트라는 숫자에 대응되고 코드 포인트는 추상적인 개념으로 코드 포인트를 실제 바이트 형태로 표현하기 위해서는 인코딩이 필요합니다.
- 오늘은 인코딩을 하는 대표적인 방식들에 대해서 알아보았습니다.

블로그 이전했습니다!! 👉 https://alswp006.github.io/