Diffusion모델의 기본원리:
이미지에 노이즈를 더하면서 알아볼수 없는 가우시안 노이즈를 만들고,
그 역과정(노이즈를 예측)을 학습을 통해 재복원해내는 모델을 만들어보자!

위의 그림에서 및 가 있는데,
: 를 로 바꿔주는 가우시안 분포, Forward 과정이며
: 를 바꿔주는 가우시안 분포, Reverse 과정이다.
는 사실 어렵지 않다. 학습을 통해 얻는값도 아니고, 그냥 연산식을 통해 얻을 수 있는 일련의 과정속에 있다.
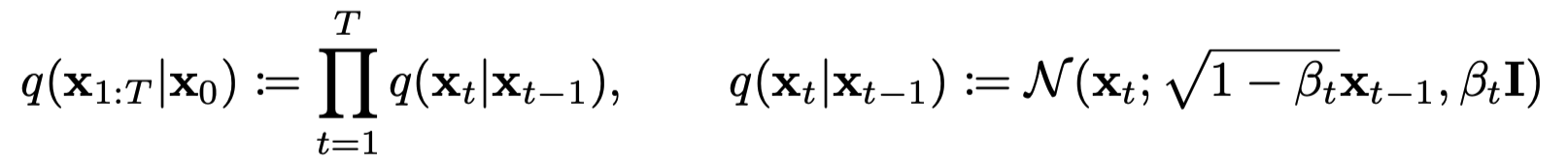
위 식을 보면, 오른쪽 식에서 볼 수 있듯이, 결국에 -> 로 가는 과정이,
이전 이미지를 얼만큼 반영할 것인가를 가 결정하고, 노이즈를 얼만큼 껴줄것인가를 가 결정한다.
보통 의 스케줄링 방식에따라 다르게 나타나겠지만, DDPM에서는

매우작은 값에서 시작해서 0.02로 마무리되도록 스케줄링한다. (linear하게 등분해서 증가한다)
다시 강조해보면,
의 정체는?
그런데 를 구하는 것이 단계적으로 이루어질때, 굉장히 귀찮고 연산이 복잡한 과정으로 정의될 수 있다. Marcov Chain으로 연결되어 있기 때문이다.
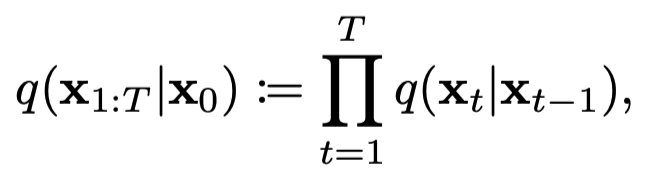
그래서 저자는, 한번에 forward process를 진행할 수 있는 key를 제공한다.
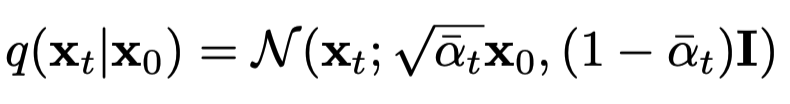
는 1 - 로 정의된다.
는 1부터 t까지의 누적곱으로 나타난다.
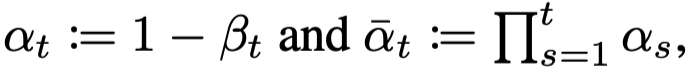
np.cumprod 를 사용하여, 누적곱을 np.array형식으로 보관할 수 있다.

alphas_cumprod에는 누적곱 array가 담겨져있으며,
alphas_cumprod_prev에는 누적곱을 오른쪽으로 한칸 시프팅하고, 맨 앞에 1을 추가한 array가 저장된다.
왜 이짓을 하느냐 하면,
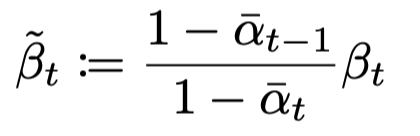
Posterior Variance인 를 구할때, 식이 위와 같기때문이다.
만약 t = 0이라면, 기존의 alphas_cumprod를 직접 사용할시, 오류가 생길 수 있다.
를 아래 코드로 구현하게된다.

원래 q는 forward process를 나타내는 가우시안 분포를 의미하지만, 여기서는
의 컨디션에서, 와 함께 를 추출하는 "이상적인" 분포를 말한다고 한다.
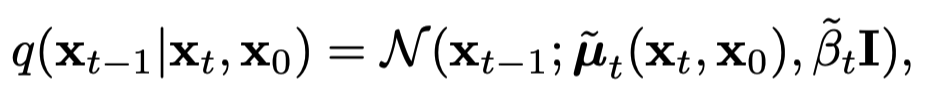
그래서 사실 diffusion 모델이 학습해야할 노이즈 분포의 이상적인 학습 목표를 여기서 이렇게 표현한 것 같다.
가 학습해야하는 것은 아래 가 된다. 그것은 아래와 같은 식으로 표현된다.
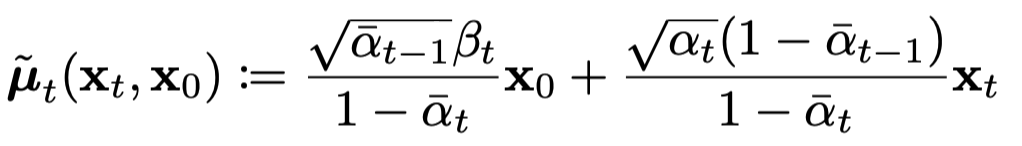
다음 코드를 통해 구현 할 수 있다. 에 곱해지는게 코드상에서 coef1이고, 그 다음 에 곱해지는게 coef2이다.

애초에 앞서서 , 이런 것들을 계산해두는 이유가, 를 계산하기 위함이라고 보면 될듯하다. 적어도 DDPM에서는 가 값이 정해져있는 (학습값이 아닌) value이기 때문에, 그냥 식은 저렇게 형성이 된다고 보면 된다.
sampling
와 을 가지고 를 추출하는 과정 이다.
q는 앞전과 같이 forward process라고 생각하면 된다.
다시 recap: 아래 식은 forward process를 여러 단계를 거치지 않고 를 미리 구하여 한번에 processing하는 식이다.
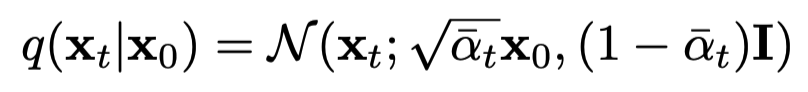
논문에 의하면, 위 식을 통해 를 추출할 수 있다고 하고, 아래와 같은 식으로 표현된다.
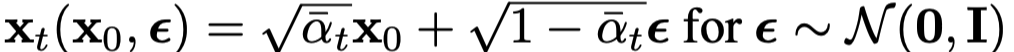
위 식을 아래 코드에서 구현하고 있다.
즉 x0(x_start) 와 노이즈를 입력으로 받아, xt를 만드는 함수이다.
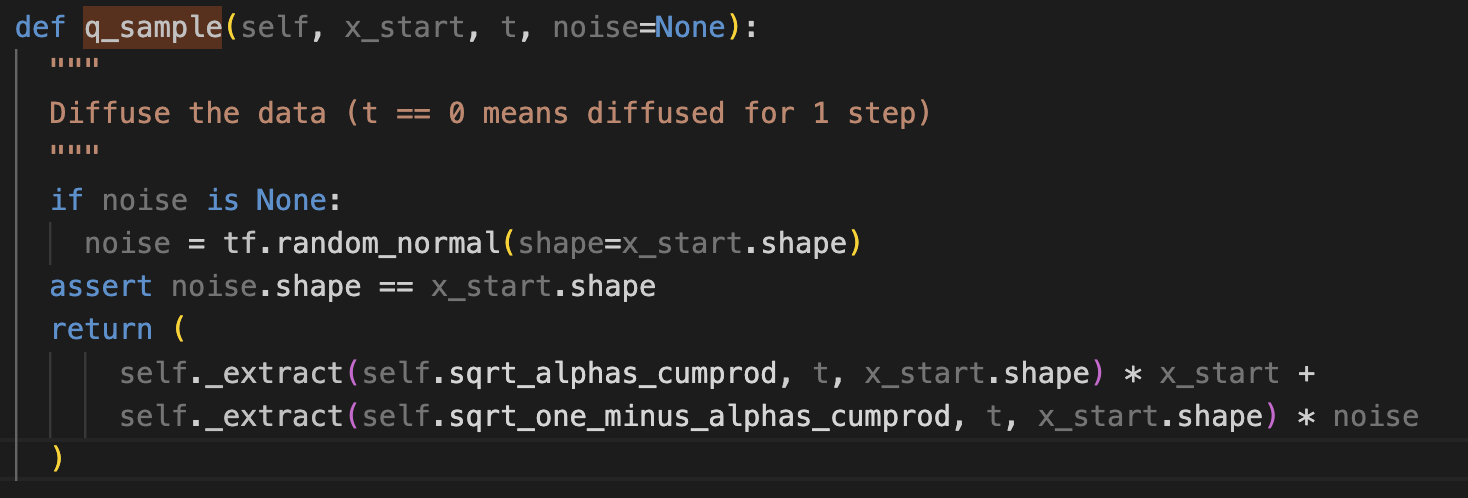
를 구하는 부분
앞서 클래스에 저장했던 coef들을 여기서 사용하여 posterior를 구한다.
variance는 클래스의 변수로 저장해놓고, mean은 그렇게 안했는지 의문을 가져본다.
mean을 미리 초기값으로 저장하여 쓰는것이 아니라, 초기에는 coef1,2만 저장후 mean을 새롭게 계산한다. 그렇다면, variance는 변하지 않고, mean은 계속 변할 수 있다는것일까?
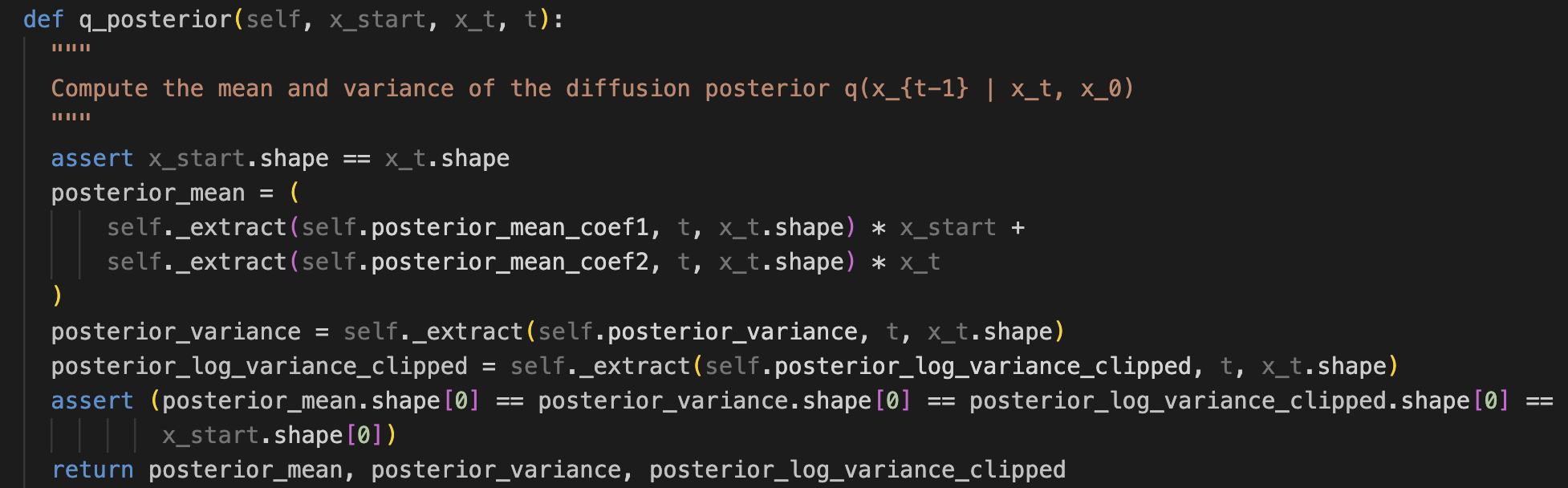
위에 코드에서 mean을 구할때는, x_t와 x_start를 입력받아 새롭게 계산해야돼서 매번 달라지는 값인 것으로 이해하면 될것 같다.
를 이해하기가 참 어려운 것 같다.
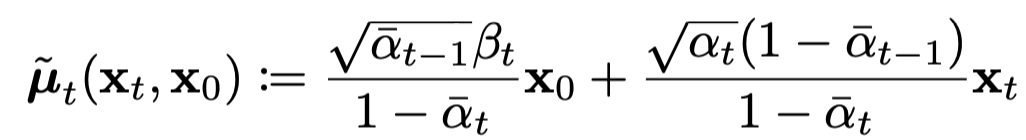
일단 식을 확인해보면, 다 그냥 구할 수 있는 값들이다. (just 연산으로)

결국에 우리가 denoising 과정을 학습을 통해 풀고자 하는 것인데, 위의 식은, 이상적인 분포가 된다. 즉, forward processing을 통해 얻은 noising 값들이 있을것인데, 그걸 바탕으로 denoising하는 역함수같은 과정을 얻어내는 것으로 이해했다.
loss Func
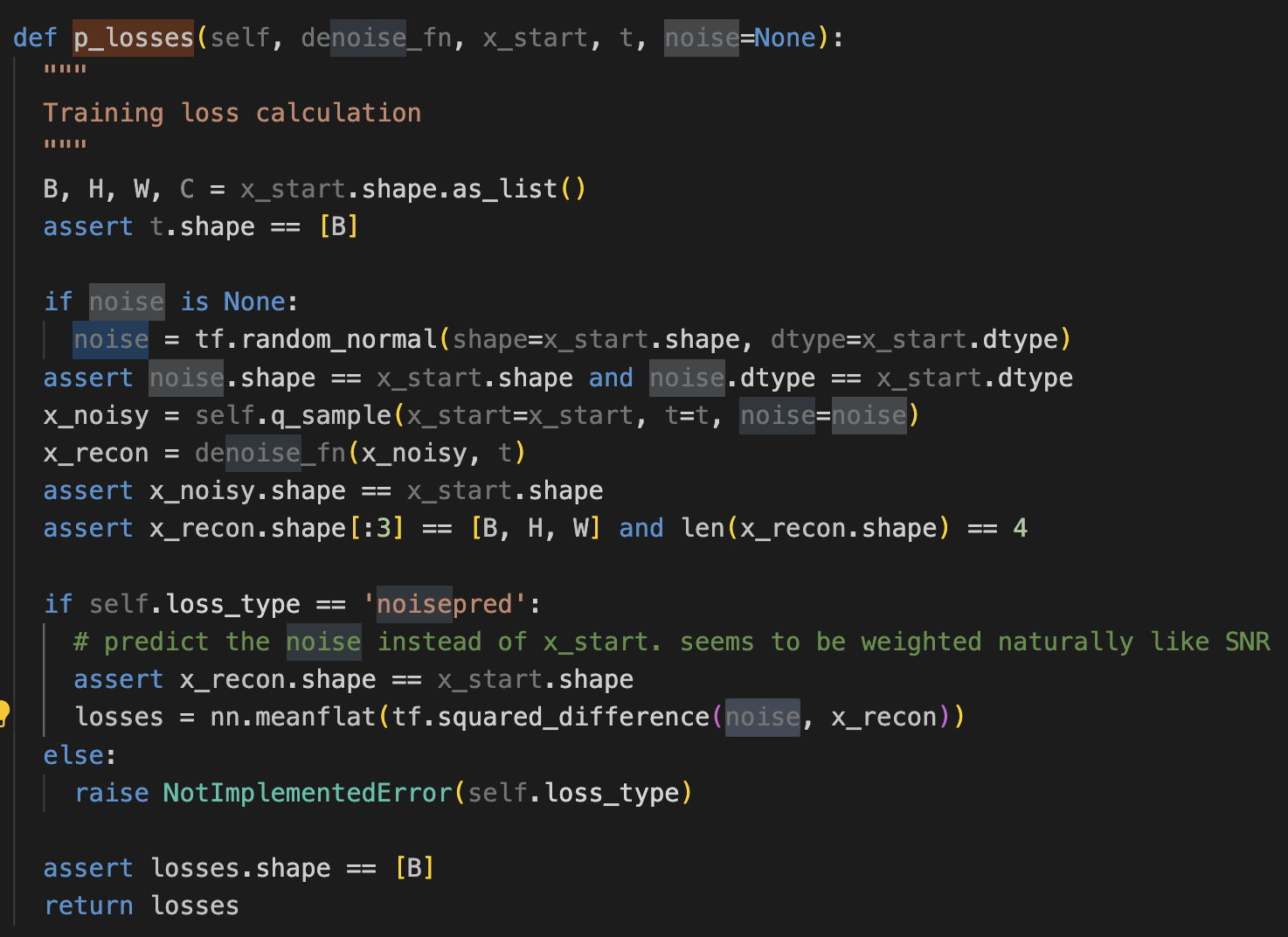
x_noisy에는 앞서 본 q_sample을 통해 얻은 노이지 이미지를 가져온다.
denoise_fn은 x_noisy와 t를 통해, x_start를 예측하려고 한다.
x_recon은 이름상 denoise_fn을 통해 denoising과정을 거친 이미지를 가져오는 것 같은 이름이지만, 아래 loss를 구하는것을 보면, 모델이 예측한 noise가 담긴다.
결국, 모델은 아래, training 알고리즘에서 보이는 것 처럼, 실제 노이즈와 예측 노이즈 loss를 기반하여 학습을 진행한다.

그 denoise_fn은 어떤식으로 구성되는가가 아마도 앞으로 볼 U-NET에서 하는 부분이지 않을까 싶다. 그부분이 바로 아래 코드에서 구현되고, unet모델이 쓰임을 볼 수 있다.
predict x0
이 부분은 논문에 식이 없는데, 코드에 있어서 출처가 의문스럽긴 하다.
하지만 함수 이름에서 하는 역할이 뚜렷히 예측이 가능해서 정리해보면,
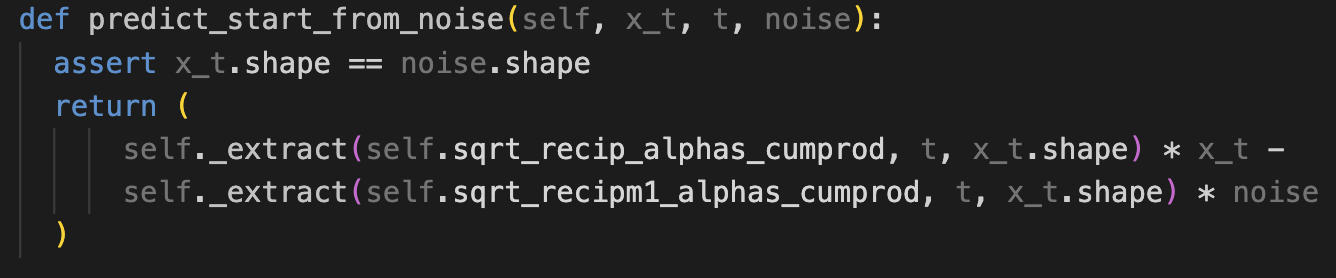
x_t와 t, 그리고 noise를 입력으로 받아, x0를 예측하는 함수이다.
이 함수가 p_mean_variance함수에서 쓰인다.
p_mean_variance 함수
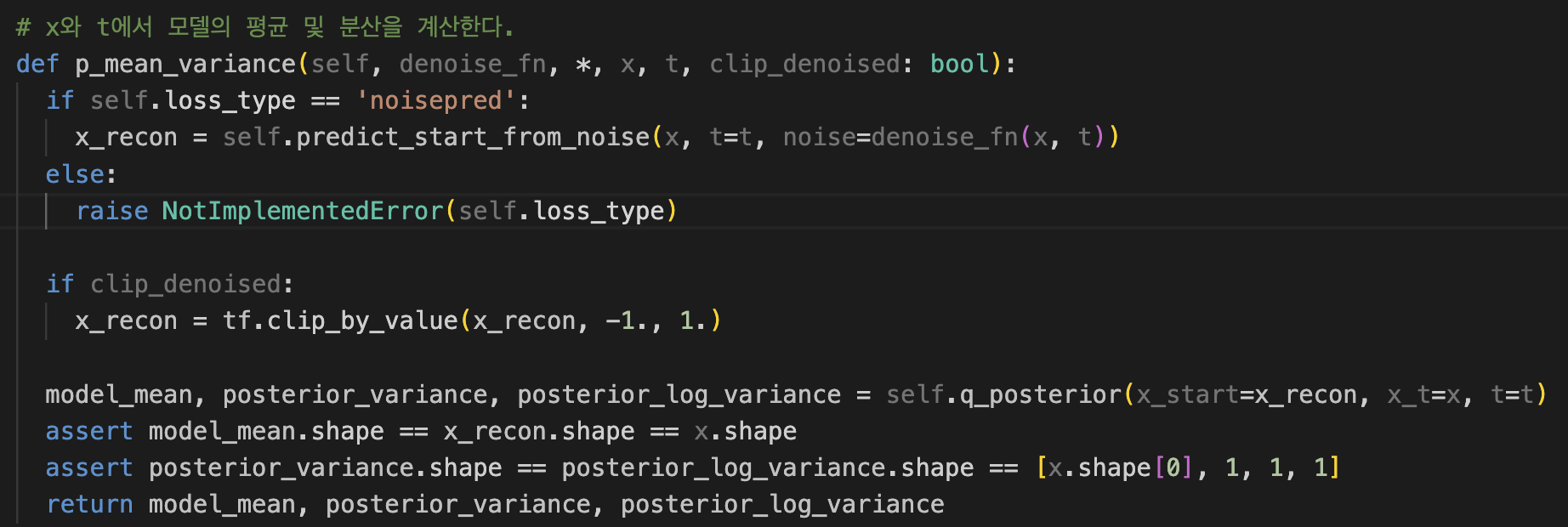
이 함수는 x와 t에서 모델의 평균 및 분산을 계산한다.
x_recon에 위에서 봤던 predict_start_from_noise 를 통해 x0를 담고,
아래 q_posterior함수에 넣어준다.
q_posterior 함수는 위에서 정리했는데, forward 프로세싱의 역과정을 표현하는 분포를 내뱉는다.
p sampling
위의 과정은 다 이것을 위한 빌드업이었다.
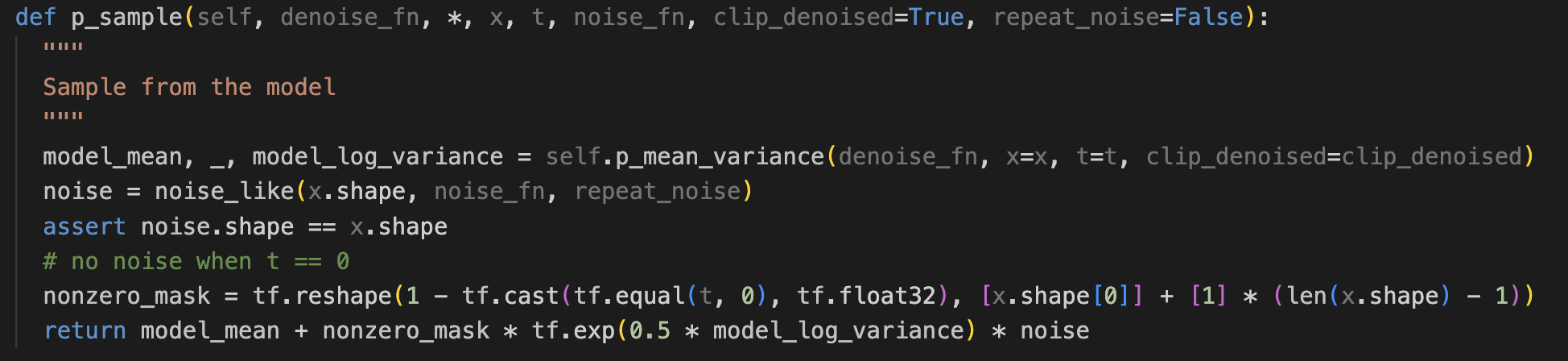
p mean variance함수를 가지고, 모델의 mean과 variance를 가져올 수 있다.
p sample에서 리턴하는 값이 아래 인데, 아래식을 관찰해보면
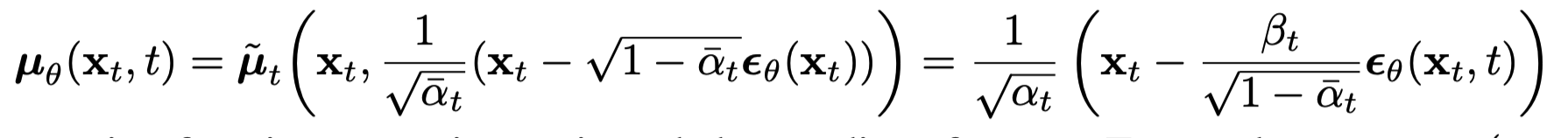
결국 샘플링하는 값과 똑같다. (즉 + 어쩌구가 = 인것....)
그래서 psample 함수에서 맨 아래 리턴부분이 model mean + (어쩌구) 가 있고,
그부분이 아래 sampling 에서 을 뽑는 과정이었던 것이다.

샘플링을 계속 해서 까지 가면 이미지를 복원하는 방향으로 갈 수 있다.
