데이터구조
1.자료구조
자료구조: 데이터(data)의 표현과 저장 방법알고리즘: 문제 해결 방법
2.스택, 큐
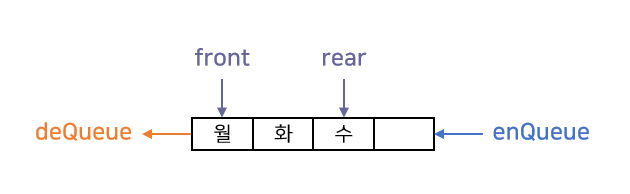
ex) 컴퓨터 되돌리기 기능: Ctrl + Z 기능마지막에 넣은 메모리가 처음으로 반환되도록 설계한 자료 구조 --> 밑이 막힌 상자 느낌LIFO(last in first out) - 후입선출입력: push() --> 파이썬 aappend()출력: pop()필요한 이유
3.linked list
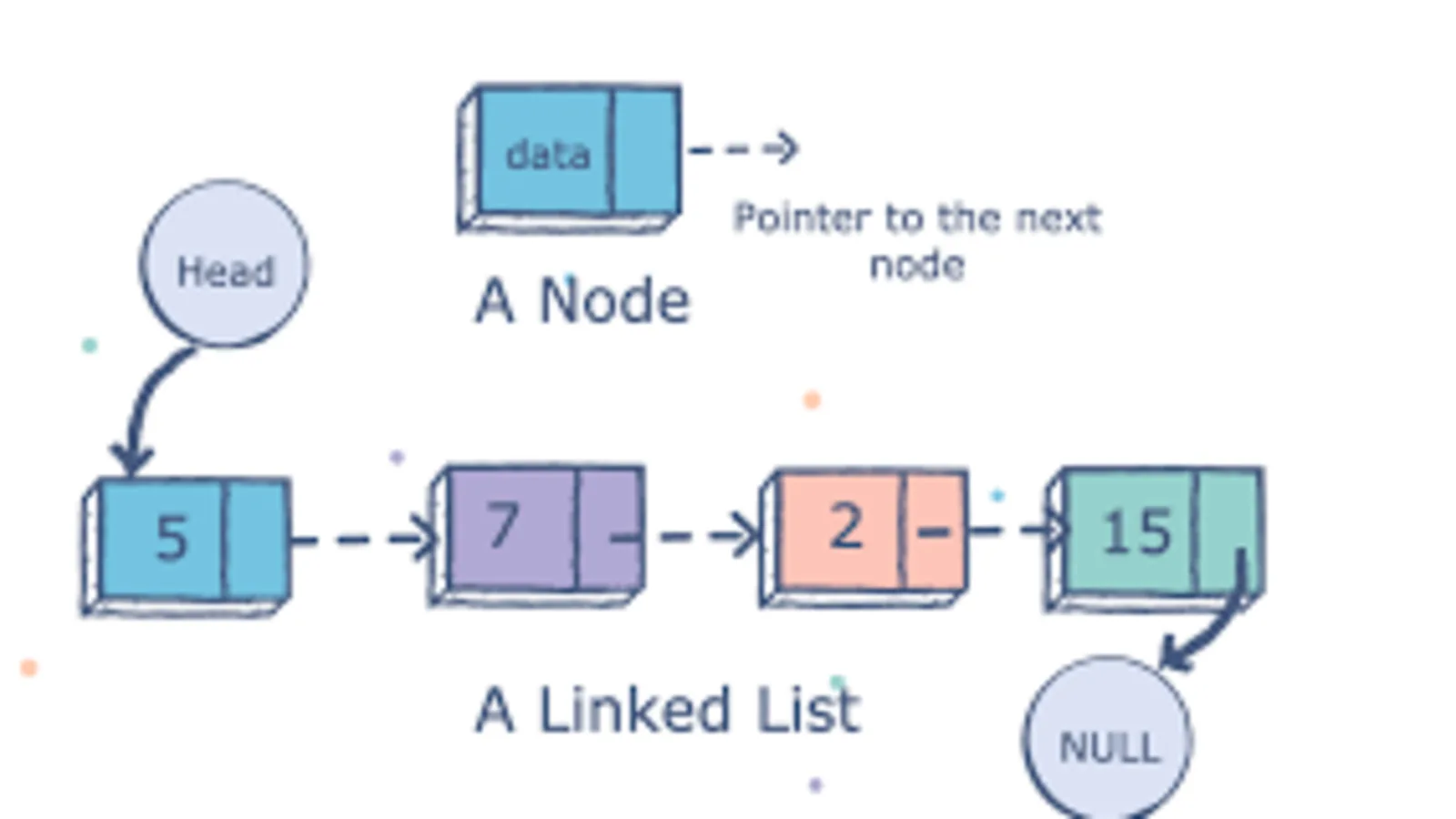
linked list 사용 이유: 배열에서 인덱스 추가, 삭제 불편 구성 node(원소): 본인의 클래스를 가리킬 수 있는 오브젝트 각 node는 link로 연결(link는 다음 node를 가리킴) 각 node는 필요한 시점에 dynamic하
4.binary tree
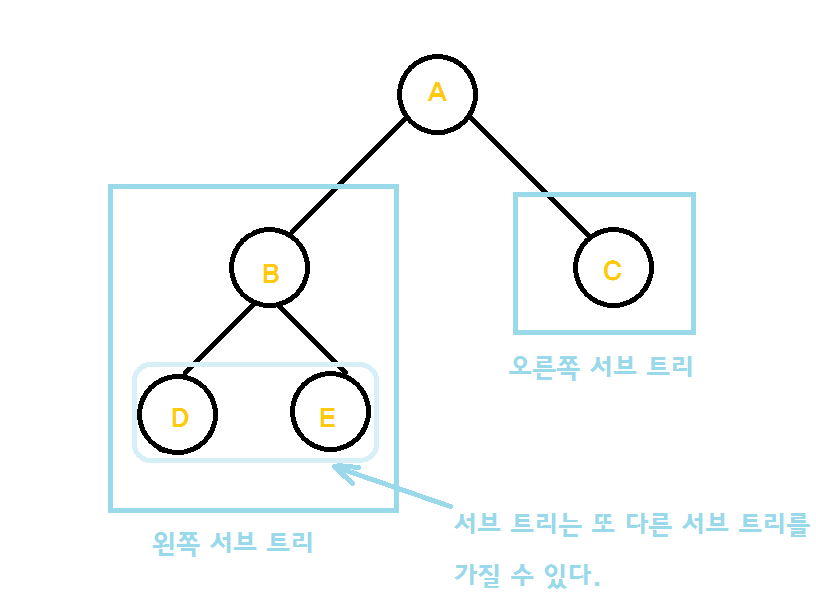
유한개(>=1)의 node로 이루어지며 root라는 특별한 node를 가지는 것용어node: tree에서 data 저장하는 기본 원소 단위root: 가장 상위의 한 개 nodesiblings: 동일한 parent를 갖는 node 들degreedegree of node:
5.heap

완전 이진트리를 기초로 함(complete binary tree)최대힙과 최소힙으로 나누어짐최대힙: 부모 노드의 값이 자식 노드들의 값보다 항상 큼최소힙: 부모 노드의 값이 자식 노드들의 값보다 항상 작음중복값 허용: 힙은 최댓값, 최솟값을 쉽게 뽑기 위한 자료구조 임
6.graph
vertex(node)와 edge(간선)으로 이루어진 것adjacent: 두 vertex간의 edge 존재path: 두 vertex간에 edge로 연결된 vertex의 sequencelength of a path: path를 구성하는 edge 개수connected: 두
7.huffman encoding
서로 다른 길이의 sorted list들을 two-way merge를 적용 --> sotred list 생성, 최적의 merge 순서는?방법: 현재 리스트 중 가장 작은 2개를 선택하여 결합(생성된 값 포함, 가장 작은 순서 확인 유의!)입력 파일의 문자 빈도수를 바탕
8.sort

데이터 처리를 용이하게 하기 위해 함번두번째 원소부터 끝 원소까지 해당 원소의 적절한 위치 찾은 후 삽입 --> 배열 앞에서 부터 해당 해당 원소까지 정렬 됨과정(반복)현 위치보다 앞쪽에서 자신보다 큰 값을 뒤로 이동, 더 이상 큰 값이 없거나 맨 앞 위치에 도달하면
9.Hashing
정의: key 연산 적용 --> Key값 위치 찾아내는 것용어hash table: 원소 저장되는 공간, 연속적인 공간(배열의 형태)버킷: 테이블 자체를 버킷이라고 하기도 함슬롯: 하나의 버킷에 여러개 슬롯 존재 가능해시: key 값 mapping 후 값을 hash라고
10.Stl
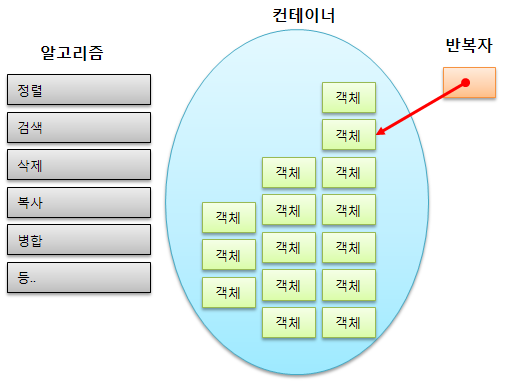
template: type의 종류에 관계없이 사용 가능한 data structure 또는 functionstl(standard template library)container: data 관리 --> 개념인듯ex) stack, queue, vector ...algorit
11.binary search tree
left --> root보다 작은 node들, right --> 큰 node들서로 다른 key값 가짐 --> 정의에 의해 존재 불가
12.avl tree
bst 이면서 height-balanced tree(좌우 subtree height 차이 1보다 작거나 같음)balance factorleft subtree height - right subtree heightavl tree --> 모든 balance factor -1