수많은 featrue를 가진 데이터셋은 최고의 성능을 보장할까요? 정답은 '절대 아님'입니다. [차원의 저주]가 무엇인지 확인하고, 데이터셋의 차원을 축소하는 주요 목적이 무엇인지 서술하세요.
supervised learning(지도 학습)을 예로 들어 학습에 사용되는 data set에서 예측하고자 하는 y(종속 변수)를 구하기 위해 X1, X2, ..., Xn(독립 변수)를 feature라 하고 독립 변수의 갯수를 차원이라 합니다.
y와 관련된 X의 갯수가 많을수록 데이터를 설명하기 좋지만, train data set의 갯수보다 feature의 갯수인 차원이 많을 경우(높을 경우) 성능이 현저히 저하됩니다.
[아래의 이미지의 경우 train data set이 10개 이며, dimension(차원)이 train data set과 동일할 경우에 예측이 떨어지고, 초과될 경우 새로운 데이터를 설명하지 못하고 있습니다.]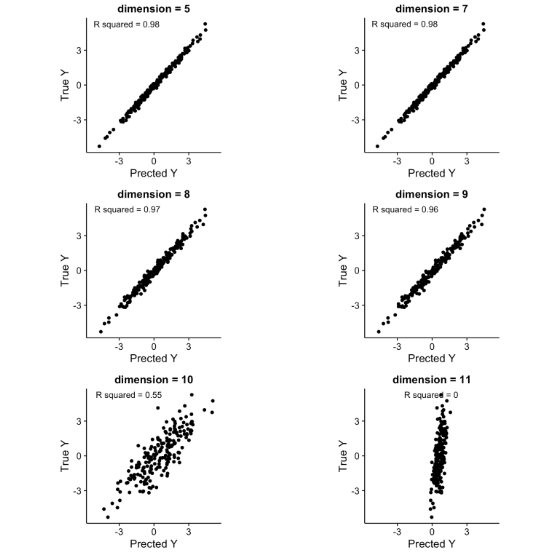
일반적으로 종속 변수보다 학습 데이터가 적은 경우를 underdetermined(과소 결정)된 문제라고 볼 수 있습니다.
성능이 떨어지는 이유중 하나는 차원이 높을수록 빈공간이 생기며, 이는 데이터의 정보(설명)가 떨어진다고 볼 수 있기 때문입니다.
따라서 차원이 커질수록 훨씬 더 많은 데이터를 가지고도 높은 성능에 이르지 못할 수 있으며, 한 샘플을 특정짓기 위해서 많은 양의 정보를 준비할수록 (즉, 고차원 데이터일수록) 그 데이터로부터 모델을 학습하기가 훨씬 더 어려워지고 훨씬 더 많은 데이터 양이 필요하게 됩니다. 이것이 바로 차원의 저주 (Curse of dimensionality) 입니다.
(출처 : https://thesciencelife.com/archives/1001)
