1주차 정리(3) Improving Deep Neural Networks : Hyperparameter Tuning, Regularization and optimization
ML_Basic
2번째 강의의 3주차 강의에 대한 정리를 진행하겠습니다.
1. HyperParameter를 선택하는 방식
hyperparameter 대표적인 종류
- learning rate
- momentum
- Adam (beta1=0.9, beta2=0.999, epsilon=)
- number of layers
- learning rate decay
- hidden units
- mini-batch size
number of layers, hidden units 들을 잘 조정해본 적이 없어서 hyperparameter라는 느낌이 다소 생소했다.
computational limitation이 존재하는 경우, Adam에 있는 beta1, beta2는 default로 정해진 값을 써도 무방하다고 한다.
grid하게 찾는 방식보다는 random하게 추출하는 방식을 추천해주셨다. grid하게 추출한다는 것은 random하게 추출하는 것보다 global optima를 추출 못할 수 있다.
또한 특정 area의 hyperparameter들이 좋다는 판단되는 경우, 그 region을 random하게 탐색한다
2. Randomly sampling의 주의점
-> 앞서 1에서 언급한 randomly sampling 과정에서 추출하는 범위의 조심성을 인지하고 진행해야 한다.
exponentially weighted move average의 내용 (1주차 정리(2)에서 언급됨)에서 beta의 값이 1에 가까워질수록, 해당 값에 영향을 미치는 값이 기하급수적으로 늘어나기에 값을 추출하는데 log 형식으로 바꿔서 추출하는 경우가 존재한다.
ex) learning rate를 random하게 뽑을 수 있는 범위가 0.0001과 1 사이라면, 0.0001부터 0.1까지는 10%의 확률로 0.1부터 1까지 90%의 확률로 추출하기에 추출 불균형이 발생한다.
이 경우, log를 사용해서 0.0001, 0.001, 0.01, 0.1 ,1를 기준으로 추출한다고 생각하면 불균형이 발생하지 않는다.
3. hyperparameter search 방식
1. babysit one model
lack of gpu, cpu 인 경우, 모델 하나를 점차적으로 학습해나가며 수정하는 방식
2. parallel하게 진행
병렬적으로 진행해 제일 나을 학습 결과를 사용하는 방식
보통 백그라운드로 실행해서 로그를 찍어가며 학습의 loss와 총 학습 시간을 파악하게 naive하게 주어진 시간을 버리지 않는다고 한다.nohup python -u <파일명> > nameoflogfile.out &
4. Batch Normalization
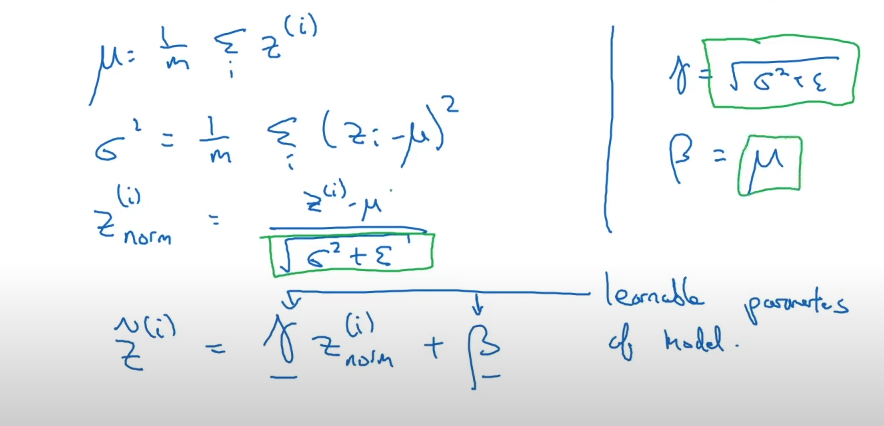
입력값의 경우 normalize하는 경우에 대해 앞서 알아보았다. 근데 hidden layer의 도 번째 layer의 입력층이기에 normalize를 하는 과정이 batch normalization이라고 한다.
이때 를 normalize하는 것이 아니라 인 activation 넣기 전에 진행한다.
-> 해당 layer에 대한 평균과 분산으로 정규화를 진행하고 gamma를 곱하고 beta를 더해준다.
이때 알게 된 점은 모델에서 쓰인 bias가 사실상 batch normalization을 거치고 사라지고 beta가 그 역할을 하게 된다고 한다.
- covariate shift는 train set과 test set의 분포가 다른 경우 발생하는 문제라고 한다. 이 문제를 해결하는데 Batch normalization을 사용하면 해결할 수 있다고 한다.