ImageGenerator
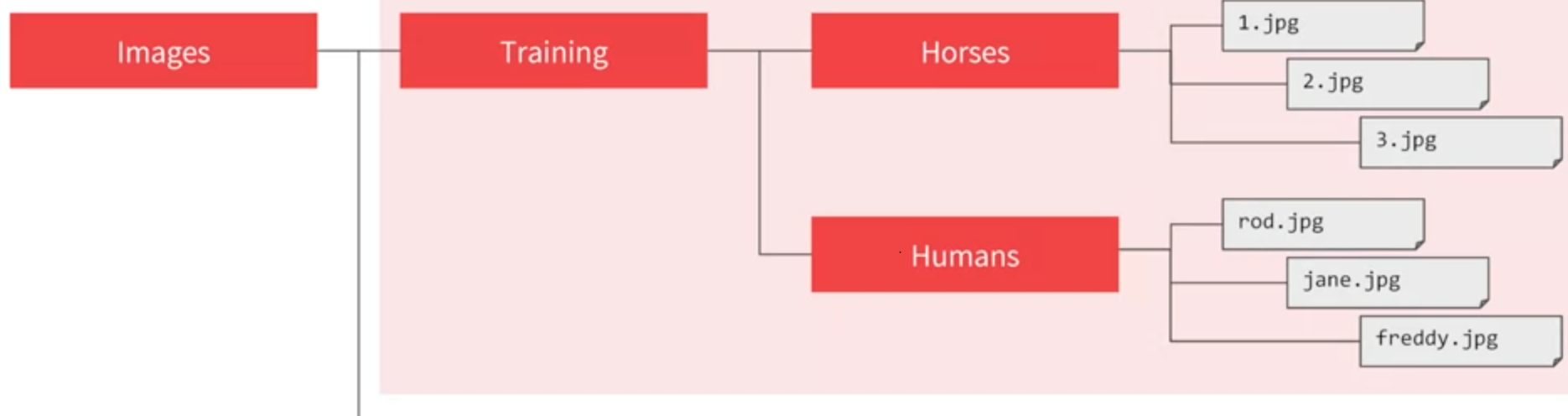
Imagegenerator를 사용하면 해당 폴더명은 label이 되어 dataset이 만들어진다.
python code이지만 model의 구조는 적지 않았다.from tensorflow.keras.preprocessing.image import ImageDataGenerator # rescale 거친다. train_datagen = ImageDataGenerator(rescale=1/255) validation_datagen = ImageDataGenerator(rescale=1/255) # 이후 generator 생성하면 label과 이미지가 자동으로 매핑된 generator가 나온다. train_generator = train_datagen.flow_from_directory( train_dir, # train 이미지 폴더 target_size=(300, 300), 300x300을 해줌으로써 데이터들 통째로 변경 가능 batch_size=128, class_mode='binary') # 말과 사람 분리니 binary validation_generator = validation_datagen.flow_from_directory( valid_dir, target_size=(300, 300), batch_size=32, class_mode='binary') history = model.fit( train_generator, steps_per_epoch=8, epochs=15, verbose=1, validation_data = validation_generator, validation_steps=8) # model.fit 때 validation data를 넣어주면 train epoch마다 validation set으로 평가하는데 8개씩 뽑아서 평가한다. ################## # 실제 predict 시 classes = model.predict(images, batch_size=10) if classes[0] > 0.5: then human else: then horse #로 구현할 수 있다.
이미지 데이터를 300300을 150150으로 변경해서 시간 소요를 측정해보면 더 빠르고, accuracy 도 나쁘지 않다. 데이터 입력 크기 자체도 고려해서 모델을 짜는것이 좋다.

우당탕탕 개발 지망생