2주차 정리 Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and optimization
ML_Basic
본 작성 글은 coursera 강의를 수강하고 난 후 정리용으로 작성했습니다.
이번 글은 학습 시의 optimization methods들을 정리하고 있습니다.
실제 강의에서 작성된 수식을 참고해서 정리했습니다.
1. Mini-batch gradient descent
(기존 gradient descent는 batch gradient descent으로도 불립니다.)
gradient descent는 training dataset 전체를 다 돌고 나서 parameter update를 진행합니다. 그렇기에 빠르게 학습하려면 mini-batch를 쓴다고 합니다.
notation recap
(i) - i번재 data
[l] - layer l
{t} - mini-batch
mini batch를 적용하면 cost function에 noise가 발생하는 것을 볼 수 있습니다.
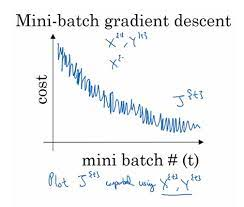
🖐 mini batch의 크기를 정하는 방법
1과 dataset 크기 사이 중 cpu와 gpu의 computational limit을 기반으로 결정합니다.
보통 64, 256, 512 와 같은 수를 결정합니다.
2. Exponentially weighted average
데이터의 이동 평균을 구할 때, 오래된 데이터가 미치는 영향을
지수적으로 감쇠(exponential decay) 하도록 만들어 주는 방법으로 최적화 알고리즘에 필요한 지식
Vt = β×Vt−1 + (1−β) ×Θt
Vt−1 = β×Vt−2 + (1−β) ×Θt−1
여기서 는 hyperparameter이며, 는 해석하자면 의 개수의 영향을 받은 값이라고 할 수 있습니다.
여기서 만약 베타가 0.99라면 100개의 영향을 받는 값이라고 할 수 있고, 0.995라고 하면 200개의 영향을 받는 값이 되기에 베타라는 hyperparameter는 조정 시 조심해야하는 값이라는 것을 알 수 있습니다.
3. Bias correction
Expontentially weighted average 쓸때, 초기에 예상보다 낮은 값이 측정되어 이를 해결하고자 쓰입니다.
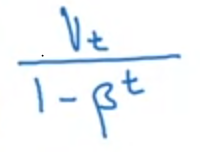
따라서 는 위와 같은 과정을 거칩니다. 여기서 t는 mini-batch를 뜻합니다.
4. momentum with gradient descent
momentum을 이용하면 global optima에 더 빠르게 학습하여 도달할 수 있습니다.

이와 같이 momentum을 적용한 값을 으로 만들어줍니다. 이때 가 가속도, 가 속도로 비유되어 를 갱신해줍니다. (도 마찬가지로 갱신해줍니다.)
여기서 베타가 더 클수록 exponentially weighted average의 영향으로 noise가 덜 하고 오른쪽으로 이동된 결과가 나옵니다. (average를 도출할때 쓰이는 값의 개수가 점점 더 커지기 때문입니다.)
5. RMSProp
momentum과 마찬가지로 더 빠르게 학습할 수 있게 합니다.
momentum과 다른 점은 을 사용했다는 점입니다. (이유는 이후 포스팅에서 공부후 올릴 예정입니다.)
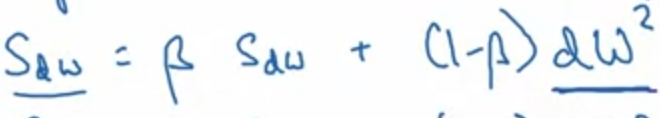
그리고 epsilon을 분모(denominator)에 더해줍니다. (분모 0이 되는 것을 막기 위해서입니다.)
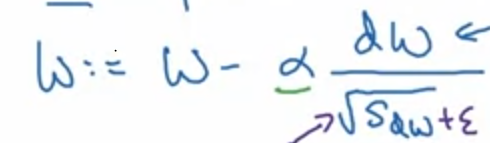
6. Adam
Adam은 RMSProp과 Momentum 방식을 모두 적용한 방식입니다.
위 2가지 과정을 거치는 것이 Adam
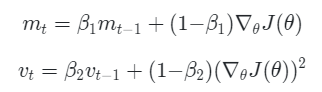
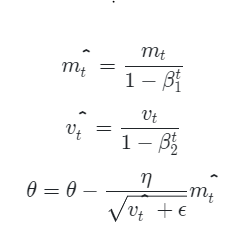
7. learning rate decay
alphainitail은 learning rate 초기값
추가
In Limited computational environment, hyperparameter for Adam ( has default 0.9 and 0.999 which is recommended to use since performance are good).
Else learning rate, exponetially weighted average (β) and mini batch ..etc.. needs to be tested
