CNN이란?
Image classification & Object detection 등의 Input data가 매우 큰 모델이라고 합니다.
이미지가 1000 * 1000인 경우 3000000 이기에 매우 큰 input
1. Edge Detection
cnn 방법 중 하나로, 이미지의 edge들을 추출하는 방식입니다. (vertical Edge, horizontal Edge로 나뉩니다.)
vertical Edge
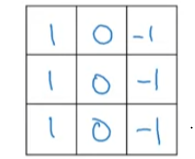
위 filter를 convolution layer에서 사용하면 수직선이 강하게 드러나서 밝은 경우와 어두운 경우의 픽셀로 나뉩니다.
horizontal Edge
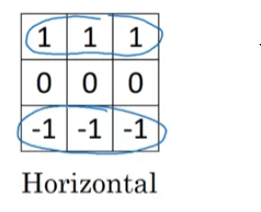
위 filter를 convolution layer에서 사용하면 수평선이 강하게 드러나서 밝은 경우와 어두운 경우의 픽셀로 나뉩니다.
위 2가지 방법을 통해 이미지 내에서의 edge이자 특징을 추출한다고 합니다.
2. padding
이미지 내의 데이터 손실을 방지하고자 사용합니다.
filter의 크기와 stride의 수치로 이미지의 크기는 작아지는 것은 자명해지지만, 작아지는 속도가 너무 빠르면 이미지 내의 필요한 수치를 뽑아내지 못할 수 있습니다. 그렇기에 이 방식을 사용한다고 합니다.
stride란 filter가 바로 옆 칸에서 다음 convolution 작업을 진행할지, 혹은 몇 칸 떨어진 곳에서 진행할지를 정하는 변수입니다. default는 1로 바로 옆칸에서 진행하는 것입니다.
convolution layer의 output h,w는 각각 (p=padding, f = filter size)
h_output =
w_output =
이렇게 표현할 수 있다.
same convolutions
input image 사이즈에 맞춰 padding을 진행해야하는 방식을 의미합니다.
을 맞춘다고 보면 됩니다.
valid convolutions
No padding 방식을 의미합니다.
RGB Image edge detection 방식
RGB 이미지를 R, G ,B의 분석으로 진행할 때, R filter에 대해서 vertical edge를 적용하고, 나머지 2 edge에 대해서는 filter를 모두 0으로 채우면 된다.
3. CNN 모델 구조
본 강의에서는 lenet-5 , alexnet을 시작으로 resnet과 inception을 소개했습니다. 정리용으로는 resnet과, inception module, 그리고 mobilenet의 내용 정리를 진행하려고 합니다.
Resnet
1. residual block
이 block은 skip connection이란 것을 구현한 block입니다. shortcut이라고 생각하시면 됩니다. model의 layer가 깊어질수록 overfitting이 되는 경우가 많아지지만, residual block을 사용함으로써 vanishing gradient, exploding gradient 문제를 해결하는데 쓰입니다.
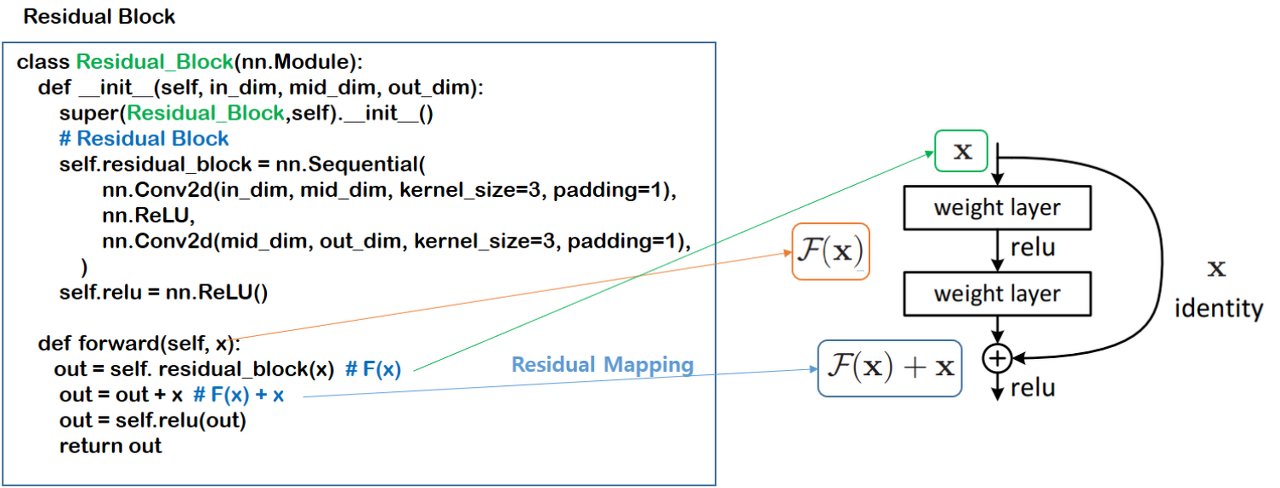
아래와 같이 기존의 cnn 방식에서 번째 값을 에 더하고 activation을 적용해줍니다.
residual network 성능이 좋은 이유
residual block은 형태입니다.
즉, 가 모두 0인 경우, 인 식이 성립됩니다.
이 수식을 통해, 가 없는 상황에서도 identity function의 값이 있기에 문제가 생길 확률은 적습니다. 즉, residual network를 통해 학습에 safety tool을 적용하였다고 생각할 수 있습니다.
1*1 convolution
한 1x1 차원만큼을 fully connected layer로 진행하는 방식입니다.
filter개수이자, channels의 차원을 줄이고 싶을 때 사용합니다.
1x1 convolution을 이용한 비선형성을 강조할 수 있습니다. 연산량을 줄이고 기존 layer보다 높은 비선형성을 가질 수 있습니다.
Inception network
1x1, 3x3, ..pooling등의 layer들을 한번에 결과로 얻고 싶을때 사용합니다.
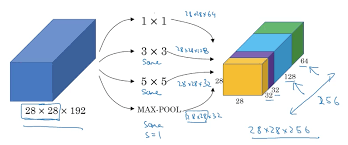
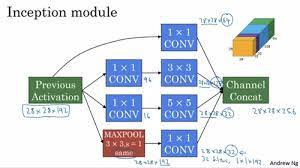
이렇게 channel의 concat 방식이 되려면 h,w의 크기가 같아야하기 때문에 'same' padding 방식을 씁니다.
1x1 convolution의 주요 역할은 parameter의 개수를 줄여주는 역할을 하는 것입니다. 이때 conv 1x1을 적용한 layer는 bottleneck layer라고 부릅니다. 제일 작은 layer라고 생각하시면 됩니다.
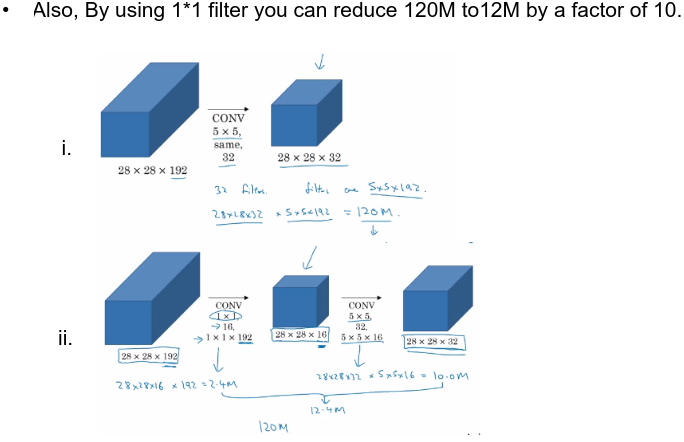
28x28x192의 convolution을 거친 28x28x32를 만들 경우, 28x28x32x(5x5x192)입니다.
반면 1x1 convolution을 거친다면, 28x28x16x(1x1x192) + 28x28x32x(5x5x16)입니다.
이 수치는 10배의 차이가 나기 때문에 1x1의 효과를 볼 수 있습니다.
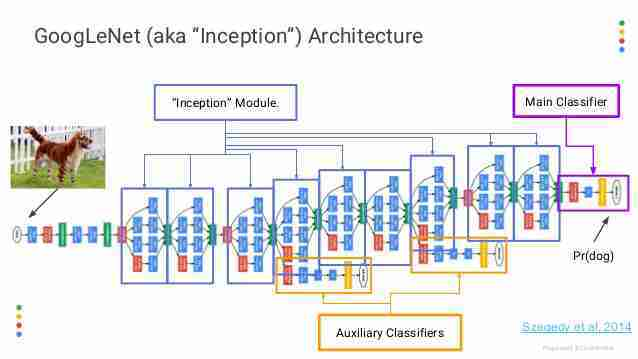
Auxiliary Classifier?
이 개념은 GoogleNet에서 사용된 side branch의 형태임을 확인할 수 있습니다. 짧게 설명하자면, overfitting을 방지하고자, regularization의 역할을 하기 위해 사용된다고 합니다.
- This classifier is used to solve gradient issue. This helps to send gradient value.
- NN이 깊어질수록, vanishing gradient 문제가 생기기 때문에 이 gradient가 잘 전달되기 위해서 쓰입니다.
Mobilenet
Depthwise separable convolution은 normal convolution의 cost가 필요합니다.
1. Depthwise separable convolution
Depthwise separable convolution은 크게 두 가지의 과정으로 진행됩니다.
1. Depthwise convolution
보통 filter의 size가 fxf 라고 하면, filter의 개수도 따로 주어지는데 이 convolution은 input의 dim=2의 크기만큼을 준비합니다. 그리고 element-wise와 유사한 규칙으로, 각 차원에 맞는 input layer와 filter를 곱한 값을 구합니다. 그렇게 되면 이 convolution의 output size는 h,w만 바뀌고 channel은 input과 똑같습니다.
2. Pointwise convolution
Depthwise convolution을 진행한 후, 1x1 convolution을 진행해서 (n개의 1x1 filter를 사용함으로써) 의 형태로 나오게 됩니다.
2. Expansion , skip connection
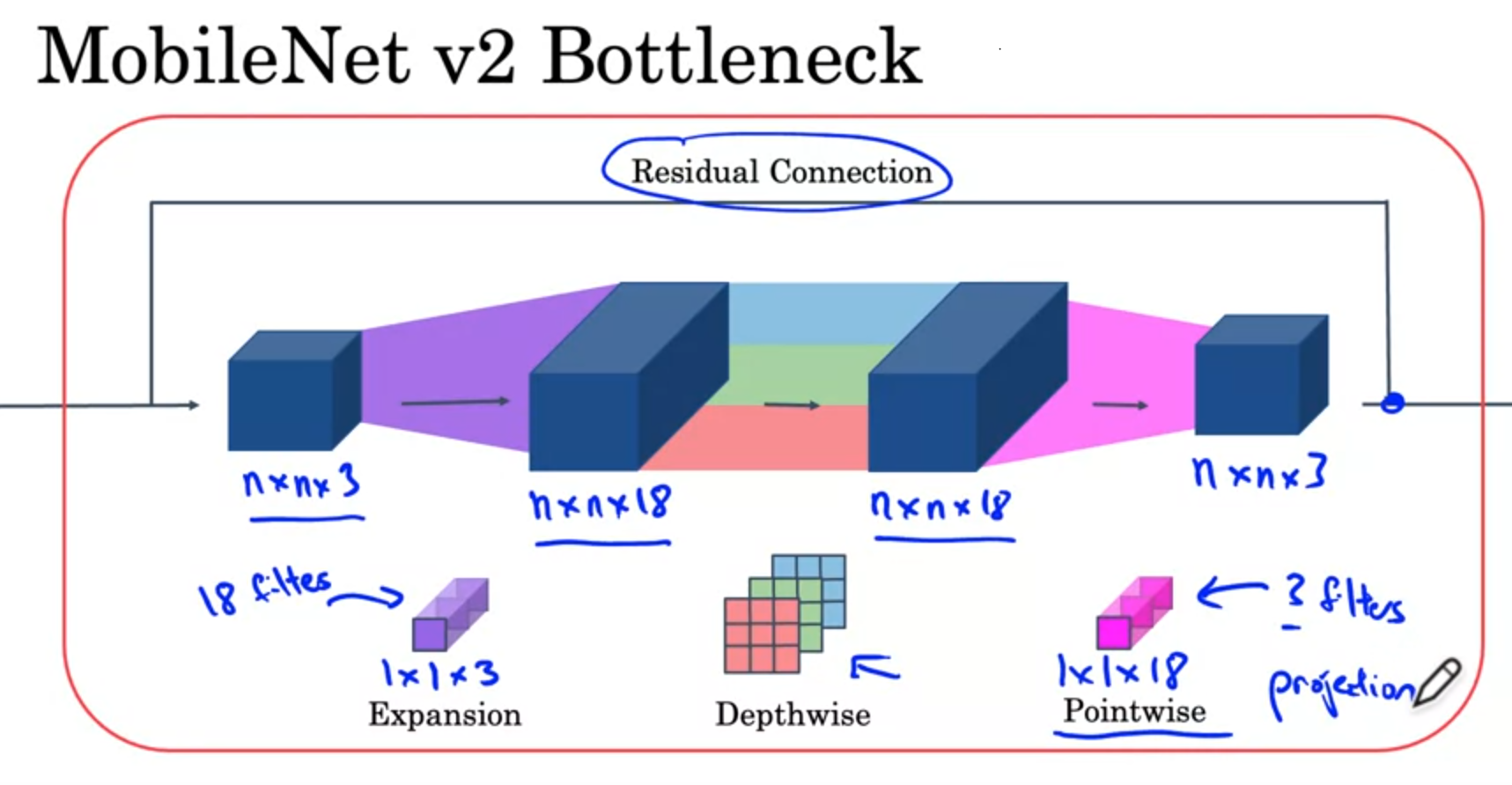
mobilenet의 bottleneck 과정에는 expansion과 skip connection이 사용되었습니다.
expansion은 1x1 convolution을 사용하여 channel의 수를 확장해줍니다. 이 과정을 통해 convolution 과정에서 사용할 수 있는 정보를 더 많이 얻을 수 있습니다.
이후, depthwise separable convolution을 거침으로써 computational cost를 줄입니다.
