RNN
- 기존에 쓰인 standard network으로는 word간의 전, 후 영향을 서로 못 주기에 word와 관련된 prediction 성능이 굉장히 낮았습니다.
초기의 network는 아래와 같은 구조를 사용했습니다.
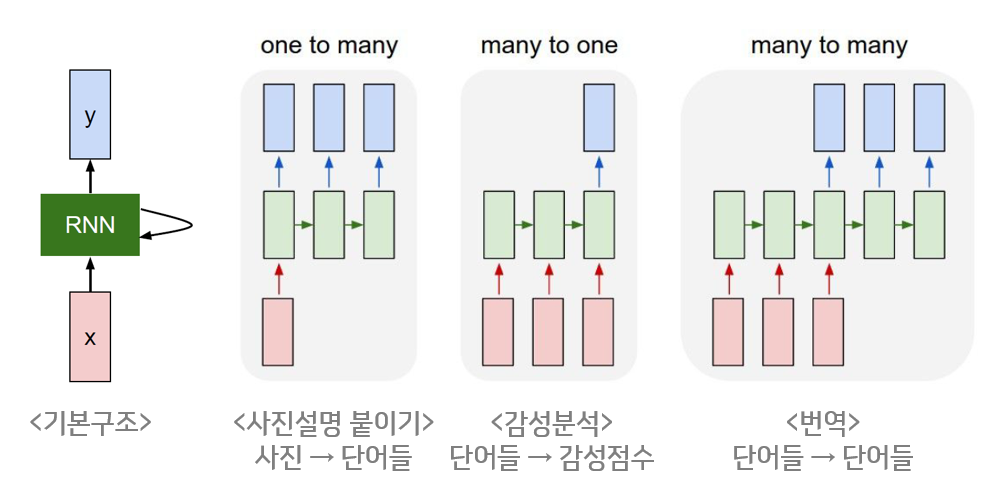
한 단어씩 input으로 들어오면, 이에 대한 공유된 를 곱해주고, 이전 단어의 값을 같이 사용해서 현재 단어를 예측합니다.
이때 를 통해 현재 word에서의 activation 값을 구할 수 있습니다. 이때 는 와 를 stack한 구조입니다. 는 이전 에 적용하는 가중치입니다.
이 방식에는 현재 단어 이전의 정보만 사용한다는 것이 단점으로 소개됩니다.
unidirectional한 train은 teddy bear와 teddy roosevelt이 teddy 이후에 각각 예측될 단어가 달라야하는데 이를 구분하지 못하는 상황이 일어날 수 있습니다.
이 기본 RNN은 backward 과정도 이전에 배운 다른 backward과정과 유사한 방식으로 진행되니 이는 생략하겠습니다.
Language Model
1. speech recognition
The apple and pair salad.
The apple and pear salad.
Q. Which one is the right input?
A. 이 둘 증 p(sentence1) 과 p(sentence2)의 확률을 구해서 더 높은 확률의 문장을 정답으로 고릅니다.
이 과정을 진행할 수 있으려면, 많은 양의 english text data를 구해야합니다. 데이터셋에 없는 단어는 로 표현하고, 이전 예측값을 현재 input값으로 넣어줘서 다음 예측값을 찾아야합니다. 이렇게 가 나올때까지 진행해서 문장을 예측합니다.
현 RNN 방식의 단점 : long term에 거쳐서 연관성이 필요한 단어들끼리의 학습이 잘 진행되지 않습니다. vanishing gradient가 발생합니다.
이를 해결하고자 GRU와 LSTM을 사용합니다.
2. LSTM
1. update gate (이전 정보를 얼마나 통과시킬지 정하는 gate)
해당 gate는 forget gate와 input state 를 합쳐서 사용합니다. 입력값과 hidden state값을 각각 가중치에 곱하고 simoid를 통과시켜 forget gate를 씁니다. 여기서 -1을 빼서 input gate로 씁니다.
2. Reset gate (이전 hidden state 얼마만큼 잊을지 결정하는 gate)
sigmoid를 거쳐 0~1의 값을 결정하는 gate
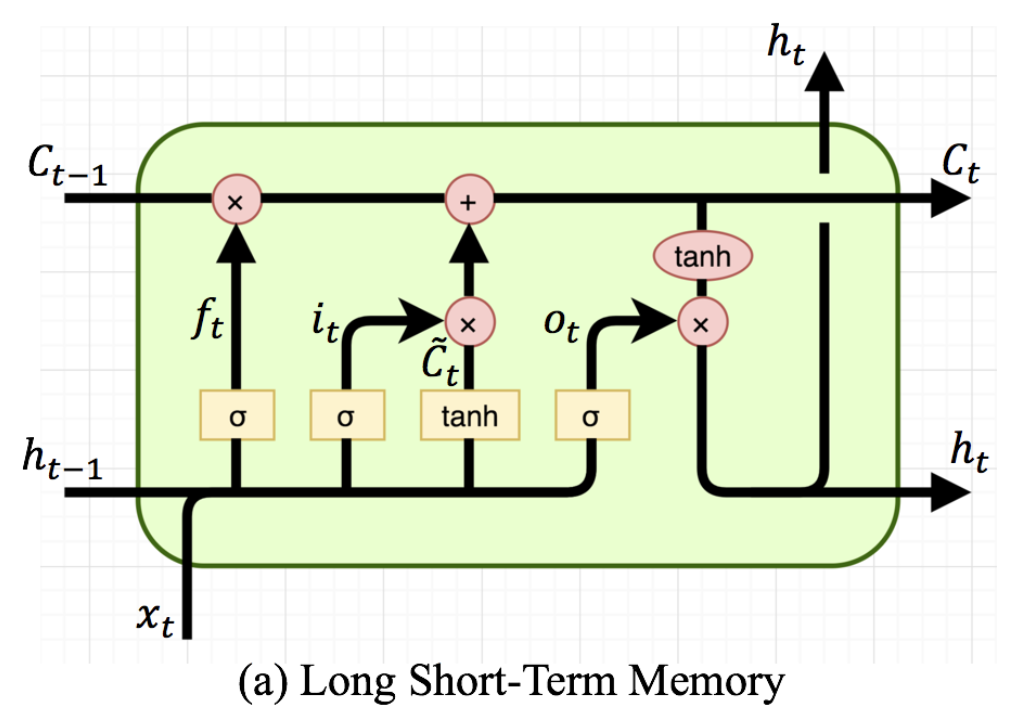
3. input state (현재 정보를 얼마나 기억할 것인지 결정합니다)
와 ~을 합쳐 cell state에 저장할 정보를 정합니다.
4. forget gate (과거 정보를 얼마나 잊을지 결정합니다.)
이렇게 값을 업데이트할 때 사용됩니다.
5. cell state : 제일 상단에 있는 state로 정보를 저장하고 있는 메모리와 같은 역할
gate들은 cell state에 보유할 정보를 제어하는데 쓰입니다.
3. GRU
- LSTM보다 효율적인 구조 : gradient vanishing 문제를 해결
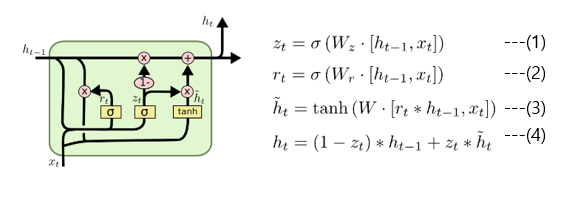
기존 LSTM 구조와 다르게 2개의 gate를 사용합니다.
GRU는 lstm 이후에 나온 구조이며, 학습 parameter 개수가 더 적다는 것이 특징입니다.1. reset gate : previous hidden state와 current x를 sigmoid함수를 적용하여 구하는 방식
이 gate는 이전 hidden state를 얼마나 활용할지 정하는 gate입니다.2. Update gate: 과거와 현재의 정보를 얼마나 반영할지 비율을 구하는 gate
이 gate는 현 시점의 hidden state를 얼만큼의 현재 정보와 얼만큼의 과거 정보를 사용하여 반영할지 정하는데 쓰입니다.
관련 이미지 자료들은 아래의 블로그에서 가져왔습니다. https://ratsgo.github.io/natural%20language%20processing/2017/03/09/rnnlstm/
