How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Paper Review
목록 보기
2/2
How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
Andreas Steiner∗, Alexander Kolesnikov∗, Xiaohua Zhai∗ Ross Wightman†, Jakob Uszkoreit, Lucas Beyer∗
Google Research, Brain Team; †independent researcher
- Paper보다는 Technical Report 느낌이지만, ViT 사용에 도움이 될까 싶어 읽어봄
- 어찌보면 당연한 이야기들을 일일이 실험해보고 기록한 정도라 자세히 언급하진 않고 적당히 요약함
Contents
- Computer Vision 영역에서 최근 떠오르는 ViT의 경우 이전에 널리 사용되던 CNN의 translational equivariance 특성이 없기 때문에 large amounts of training data 혹은 strong AugReg scheme이 필요함
- 하지만 이런 computational cost와 model performance 사이의 tradeoff에 대한 연구는 아직까지 명확하게 이루어진 부분이 없어 이 논문에서 그 연구를 하려함
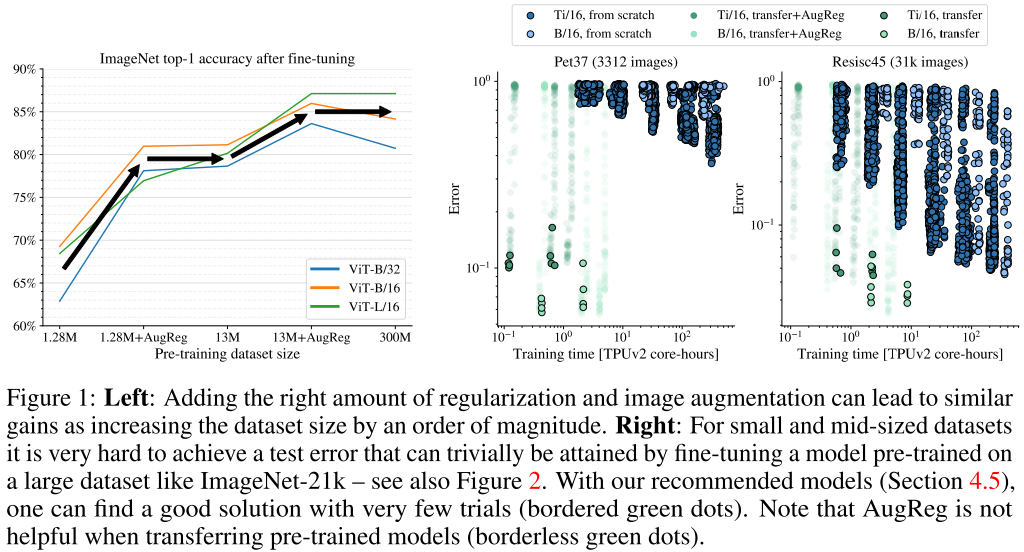
- 위 그림(left)을 보면 small dataset에 적절한 AugReg 기법을 적용해 모델을 학습시키면 더 larger dataset으로 학습시킨 것과 유사한 성능을 얻을 수 있다는 것을 알 수 있음
- 위 그림(right)을 보면 ImageNet-1k보다도 작은 dataset의 경우 AugReg 기법을 적용해도 pre-trained 모델을 사용하는 것에 비해 성능/효율 모두 좋지 않다는 것을 알 수 있음
- 여기서 recommended model이란 pre-training 단계에서 validation accuracy가 높은 모델을 뜻함
- Pre-training 단계에서 성능이 좋은 경우 fine-tuning때도 성능이 좋았다고 함
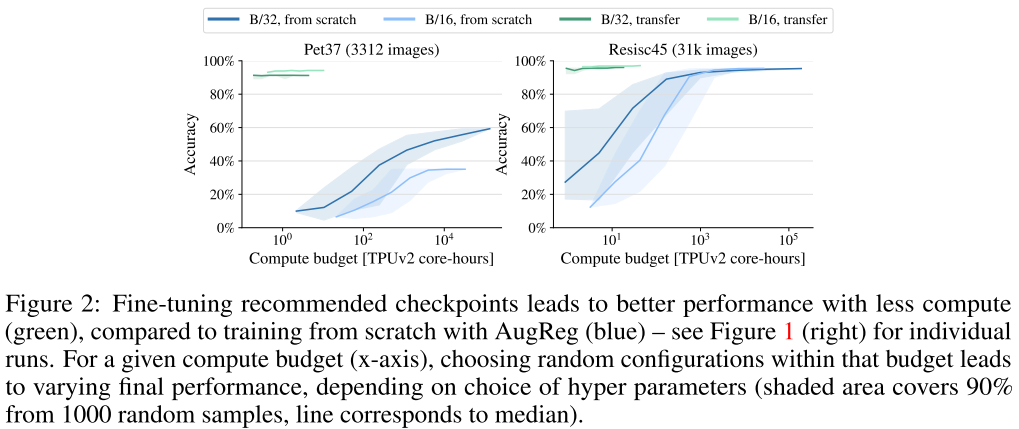
- 위 그림의 결과도 Figure 1 right와 같은 맥락으로 볼 수 있는데, dataset이 작을 경우 당연하게도 성능이 나오기 어렵고, pre-trained model을 이용해 fine-tuning하는 편이 좋음
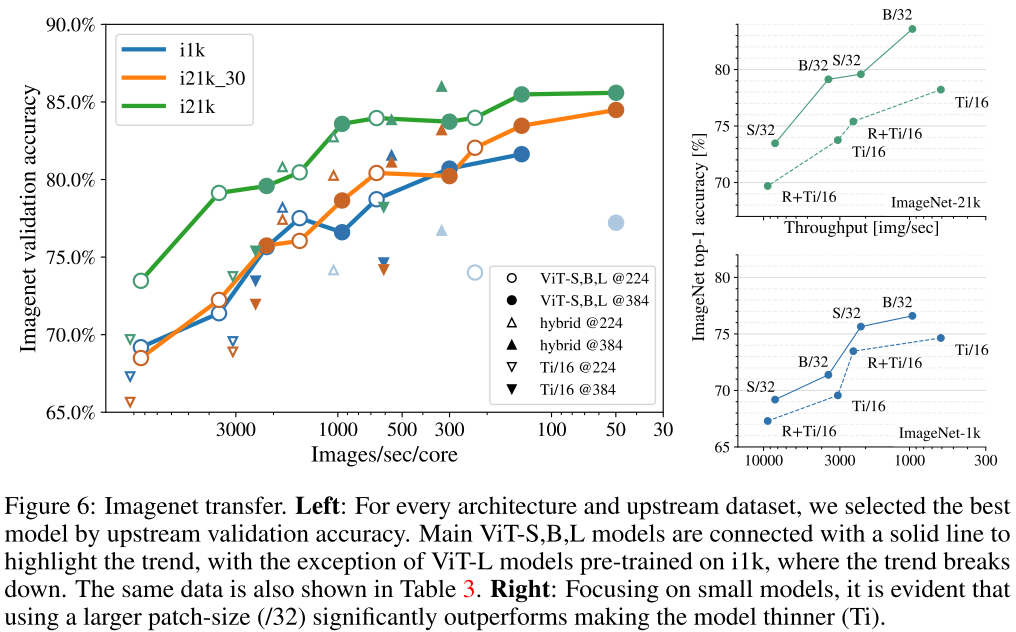
- 위 Figure 6 right를 보면, 같은 inference throughput(img/sec)을 가정할 때 모델 사이즈가 작은 것보다 패치 사이즈를 크게 잡아 token의 수를 줄이는 편이 성능이 나은 편인 것을 알 수 있음
Conclusion
- Novelty를 바라고 읽은건 아니지만 크게 흥미로운 내용은 아님
- ViT를 사용함에 있어 필요한 일반적인 배경지식을 정리한 정도의 느낌

AI공부중..