
이번 포스트에서는 RFM 분석을 SQL 쿼리로 어떻게 구현할 수 있는지 알아보겠습니다.
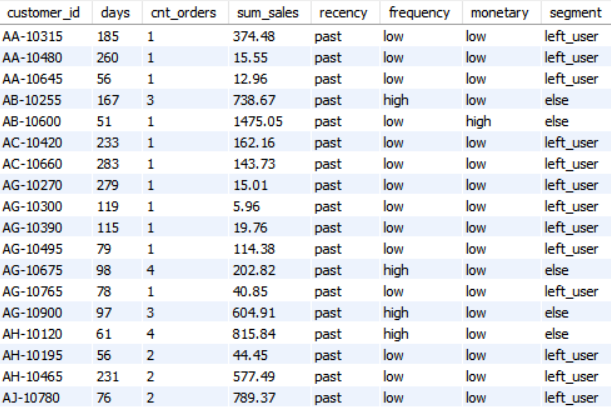
최종적으로 구현한 쿼리를 실행하면 위와 같은 결과를 얻을 수 있습니다. 우선, RFM 분석에 대해서 가볍게 알아보겠습니다.
RFM 분석이란?
Recency: 얼마나 최근에 구매했는가?
Frequency: 얼마나 자주 구매했는가?
Monetary: 얼마나 많은 금액을 지출했는가?
RFM 분석은 Recency, Frequency, Monetary에 따라 사용자 그룹을 분류하거나 분포를 확인하기 위해 쓰는 분석 기법입니다. 각각의 지표가 높을수록 고객의 충성도가 높다고 볼 수 있습니다.
개념은 정말 간단하지만 실제로 적용하려면 아주 복잡해지는데요. 저는 이 사실을 모르고 온라인 마켓 판매 데이터 분석 프로젝트를 수행했을 때, 단순히 구간을 4등분해서 각 요소별로 점수를 매긴 뒤 점수의 합을 기준으로 High, Medium, Low의 세 그룹으로 분류한 적이 있답니다.
프로젝트를 마치고 나서야 RFM 분석 사례들을 알아보다가 각 요소에 대한 기준을 분석 목적과 서비스의 특성에 맞게 설정해야 함을 배울 수 있었습니다. 각 요소의 기준을 설정하기 위해 생각해야 할 부분이 정말 많더라고요.
RFM 분석을 위한 시나리오
데이터
미국 이커머스 데이터인 US E-Commerce 2020 data를 활용하여 SQL 쿼리를 통해 사용자의 구매 행동을 분석해보겠습니다. 분석 기준은 서비스 특성과 분석 목적에 따라 다양하지만 이번 포스트에서는 다음과 같은 기준을 적용하겠습니다.
Recency: 2020년 12월 31일 기준으로 50일 이내에 결제되었는가?
Frequency: 3회 이상 주문하였는가?
Monetary: 1395달러 이상 주문하였는가?
위와 같은 기준을 세우고 나면 각 컬럼은 아래와 같이 분류할 수 있습니다.
Recency: 2020년 12월 31일 기준으로 50일 이내에 주문했으면 'recent', 그렇지 않으면 'past'
Frequency: 주문 횟수가 3회 이상이면 'high', 미만이면 'low'
Monetary: 구매 금액이 1395달러 이상이면 'high', 미만이면 'low'
위 내용을 사용자 세그먼트와 함께 표로 나타내면 아래와 같은 형태가 됩니다. 세그먼트의 경우, 정말 다양한 기준에 따라 그 수가 늘어날 수도 줄어들 수도 있겠죠?
| 사용자 | Recency | Frequency | Monetary | Segment |
|---|---|---|---|---|
| 1 | recent | high | high | vip |
| 2 | recent | high | low | poten_vip1 |
| 3 | recent | low | high | poten_vip2 |
| 4 | recent | low | low | new_user |
| 5 | past | high | high | left_vip |
| 6 | past | high | low | else |
| 7 | past | low | high | else |
| 8 | past | low | low | left_user |
시나리오
서비스에서 최근에 구매를 하지 않은 사용자들을 다시 불러오기 위한 마케팅 캠페인을 기획하고 싶다면 어떻게 할 수 있을까요? 한 가지 예시로 이전 구매 횟수가 높았거나 구매 금액이 높았던 사용자들에게 할인 쿠폰을 제공하는 방법을 제안할 수 있습니다. 위 표를 기준으로 5, 6, 7번 그룹의 사용자를 조회해서 마케팅 캠페인의 타겟으로 선정해 보겠습니다.
🎯 기획 의도
최근 상품을 구매하지 않은 사용자들 중에서도 과거에 높은 구매력을 보였던 고객이 존재합니다. 이들을 다시 유입시킬 수 있다면 비교적 적은 비용으로 높은 효과를 기대할 수 있습니다.
💡 실행 방안
RFM 분석을 통해 최근에는 구매하지 않았지만 이전 구매 횟수가 높았거나 구매 금액이 높았던 사용자군을 선별합니다. 특히, R 점수가 낮고 F 또는 M 점수가 높은 그룹(5, 6, 7)을 타겟팅하여 할인 쿠폰을 제공하는 마케팅 캠페인을 설계해보겠습니다.
쿼리
그럼 이제 5, 6, 7번 사용자 그룹을 조회할 쿼리를 작성할 차례입니다. WITH를 사용해서 테이블 3개를 만들면 위에서 만든 표를 구현할 수 있습니다. 생각보다 어렵지 않으니 한 단계씩 차근차근 작성해 보겠습니다.
Step 1
WITH customer_stats AS (
SELECT customer_id
, DATEDIFF('2020-12-31', MAX(order_date)) AS days -- 최근 주문일과 기준 날짜의 차이 (Recency)
, COUNT(DISTINCT order_id) AS cnt_orders -- 주문 횟수 (Frequency)
, ROUND(SUM(sales), 2) AS sum_sales -- 구매 금액 (Monetary)
FROM ecommerce.records
GROUP BY customer_id
ORDER BY customer_id
)먼저, customer_stats라는 테이블을 만듭니다. 해당 테이블은 고객별로 Recency, Frequency, Monetary의 기준이 되는 값을 계산하여 정리해두는 테이블입니다.
Recency의 기준 값은 고객별 기준 날짜와 최근 주문일의 차이입니다. 기준 날짜는 2020년 12월 31일로 가정하고 최근 주문일은 order_date의 가장 큰 값인 MAX(order_date)입니다. 그리고 두 날짜의 차이를 구하기 위해 DATEDIFF 함수를 사용합니다. 해당 값을 양수로 얻기 위해서는 DATEDIFF(기준 날짜, 최근 주문일)의 형태로 작성해야 합니다. 이를 종합하면 아래와 같이 작성할 수 있습니다.
DATEDIFF('2020-12-31', MAX(order_date)) AS daysFrequency의 기준 값은 고객별 주문 횟수입니다. 중복되지 않는 order_id를 세어야 하므로 아래와 같이 작성합니다.
COUNT(DISTINCT order_id) AS cnt_ordersMonetary의 기준 값은 고객별 구매 금액입니다. 편의상 sales의 합을 ROUND 함수로 소수 둘째 자리까지 반올림한 값을 사용하기 위해 아래와 같이 작성합니다.
ROUND(SUM(sales), 2) AS sum_salesStep 2
WITH customer_stats AS (
SELECT customer_id
, DATEDIFF('2020-12-31', MAX(order_date)) AS days -- 최근 주문일과 기준 날짜의 차이 (Recency)
, COUNT(DISTINCT order_id) AS cnt_orders -- 주문 횟수 (Frequency)
, ROUND(SUM(sales), 2) AS sum_sales -- 구매 금액 (Monetary)
FROM ecommerce.records
GROUP BY customer_id
ORDER BY customer_id
), rfm AS (
SELECT *
, CASE -- 50일 이내에 주문했으면 'recent', 그렇지 않으면 'past'
WHEN days <= 50 THEN 'recent'
ELSE 'past'
END AS recency
, CASE -- 주문 횟수가 3회 이상이면 'high', 미만이면 'low'
WHEN cnt_orders >= 3 THEN 'high'
ELSE 'low'
END AS frequency
, CASE -- 구매 금액이 1395달러 이상이면 'high', 미만이면 'low'
WHEN sum_sales >= 1395 THEN 'high'
ELSE 'low'
END AS monetary
FROM customer_stats
)다음으로, rfm 테이블을 만들고 customer_stats에서 생성한 컬럼들을 RFM 기준에 맞게 CASE 문을 활용하여 구분해줍니다.
Step 3
WITH customer_stats AS (
SELECT customer_id
, DATEDIFF('2020-12-31', MAX(order_date)) AS days -- 최근 주문일과 기준 날짜의 차이 (Recency)
, COUNT(DISTINCT order_id) AS cnt_orders -- 주문 횟수 (Frequency)
, ROUND(SUM(sales), 2) AS sum_sales -- 구매 금액 (Monetary)
FROM ecommerce.records
GROUP BY customer_id
ORDER BY customer_id
), rfm AS (
SELECT *
, CASE -- 50일 이내에 주문했으면 'recent', 그렇지 않으면 'past'
WHEN days <= 50 THEN 'recent'
ELSE 'past'
END AS recency
, CASE -- 주문 횟수가 3회 이상이면 'high', 미만이면 'low'
WHEN cnt_orders >= 3 THEN 'high'
ELSE 'low'
END AS frequency
, CASE -- 구매 금액이 1395달러 이상이면 'high', 미만이면 'low'
WHEN sum_sales >= 1395 THEN 'high'
ELSE 'low'
END AS monetary
FROM customer_stats
), rfm_segment AS (
SELECT *
FROM (SELECT *
, CASE
WHEN recency = 'recent' AND frequency = 'high' AND monetary = 'high' THEN 'vip'
WHEN recency = 'recent' AND frequency = 'high' AND monetary = 'low' THEN 'poten_vip1'
WHEN recency = 'recent' AND frequency = 'low' AND monetary = 'high' THEN 'poten_vip2'
WHEN recency = 'past' AND frequency = 'high' AND monetary = 'high' THEN 'left_vip'
WHEN recency = 'recent' AND frequency = 'low' AND monetary = 'low' THEN 'new_user'
WHEN recency = 'past' AND frequency = 'low' AND monetary = 'low' THEN 'left_user'
ELSE 'else'
END AS segment
FROM rfm) tmp
)마지막으로, 각각의 기준을 적용한 고객 세그먼트를 CASE 문을 이용해서 구분한 테이블을 만들어줍니다. 이 과정까지 마치면 원하는 사용자 세그먼트를 마음껏 조회할 수 있습니다.
Step 4
WITH customer_stats AS (
SELECT customer_id
, DATEDIFF('2020-12-31', MAX(order_date)) AS days -- 최근 주문일과 기준 날짜의 차이 (Recency)
, COUNT(DISTINCT order_id) AS cnt_orders -- 주문 횟수 (Frequency)
, ROUND(SUM(sales), 2) AS sum_sales -- 구매 금액 (Monetary)
FROM ecommerce.records
GROUP BY customer_id
ORDER BY customer_id
), rfm AS (
SELECT *
, CASE -- 50일 이내에 주문했으면 'recent', 그렇지 않으면 'past'
WHEN days <= 50 THEN 'recent'
ELSE 'past'
END AS recency
, CASE -- 주문 횟수가 3회 이상이면 'high', 미만이면 'low'
WHEN cnt_orders >= 3 THEN 'high'
ELSE 'low'
END AS frequency
, CASE -- 구매 금액이 1395달러 이상이면 'high', 미만이면 'low'
WHEN sum_sales >= 1395 THEN 'high'
ELSE 'low'
END AS monetary
FROM customer_stats
), rfm_segment AS (
SELECT *
FROM (SELECT *
, CASE
WHEN recency = 'recent' AND frequency = 'high' AND monetary = 'high' THEN 'vip'
WHEN recency = 'recent' AND frequency = 'high' AND monetary = 'low' THEN 'poten_vip1'
WHEN recency = 'recent' AND frequency = 'low' AND monetary = 'high' THEN 'poten_vip2'
WHEN recency = 'past' AND frequency = 'high' AND monetary = 'high' THEN 'left_vip'
WHEN recency = 'recent' AND frequency = 'low' AND monetary = 'low' THEN 'new_user'
WHEN recency = 'past' AND frequency = 'low' AND monetary = 'low' THEN 'left_user'
ELSE 'else'
END AS segment
FROM rfm) tmp
)
SELECT *
FROM rfm_segment
WHERE segment IN ('left_vip', 'else');위 시나리오에 따르면 5, 6, 7번 그룹 사용자를 조회해야 하니 5번 그룹에 해당하는 left_vip와 6, 7번 그룹에 해당하는 else를 WHERE절을 사용하여 필터링해줍니다. 그러면 해당 사용자 그룹을 타겟팅하여 마케팅 캠페인을 수행할 수 있게 됩니다.
참고
