🧐 Regularization이란?
- overfitting을 막기 위해 위해 사용하는 방법
1. Norm
: 벡터의 크기를 측정하는 방법 (두 벡터 사이의 거리를 측정하는 방법)
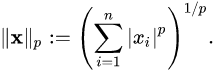
2. L1 Norm
: 벡터 p, q의 각 원소들의 차이의 절대값의 합
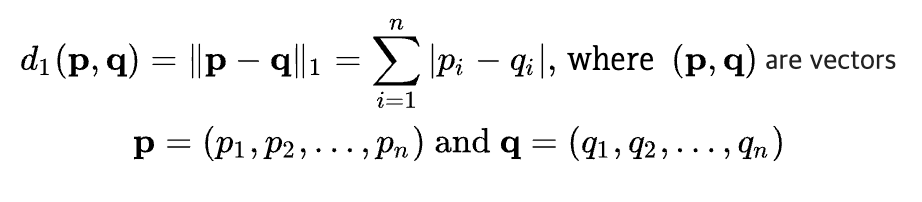
3. L2 Norm
: q가 원점이라고 했을 때, 벡터 p, q의 원소들의 원점으로부터의 직선거리
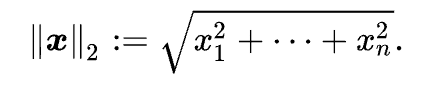
Regularization
: 모델 복잡도에 대한 패널티로 overfitting을 예방하고 generalization 성능을 높이는데 도움을 줌
- L1 Regularization, L2 Regularization, Dropout, Early stopping 등이 존재
- weight 중 일부가 학습과정 중 과도하게 커지면 몇몇 input에 과도하게 의존 → generalization 성능 감소 → 규제를 주어 w가 작아지도록 학습 → overfitting을 예방 (outlier의 영향을 덜 받도록 함)
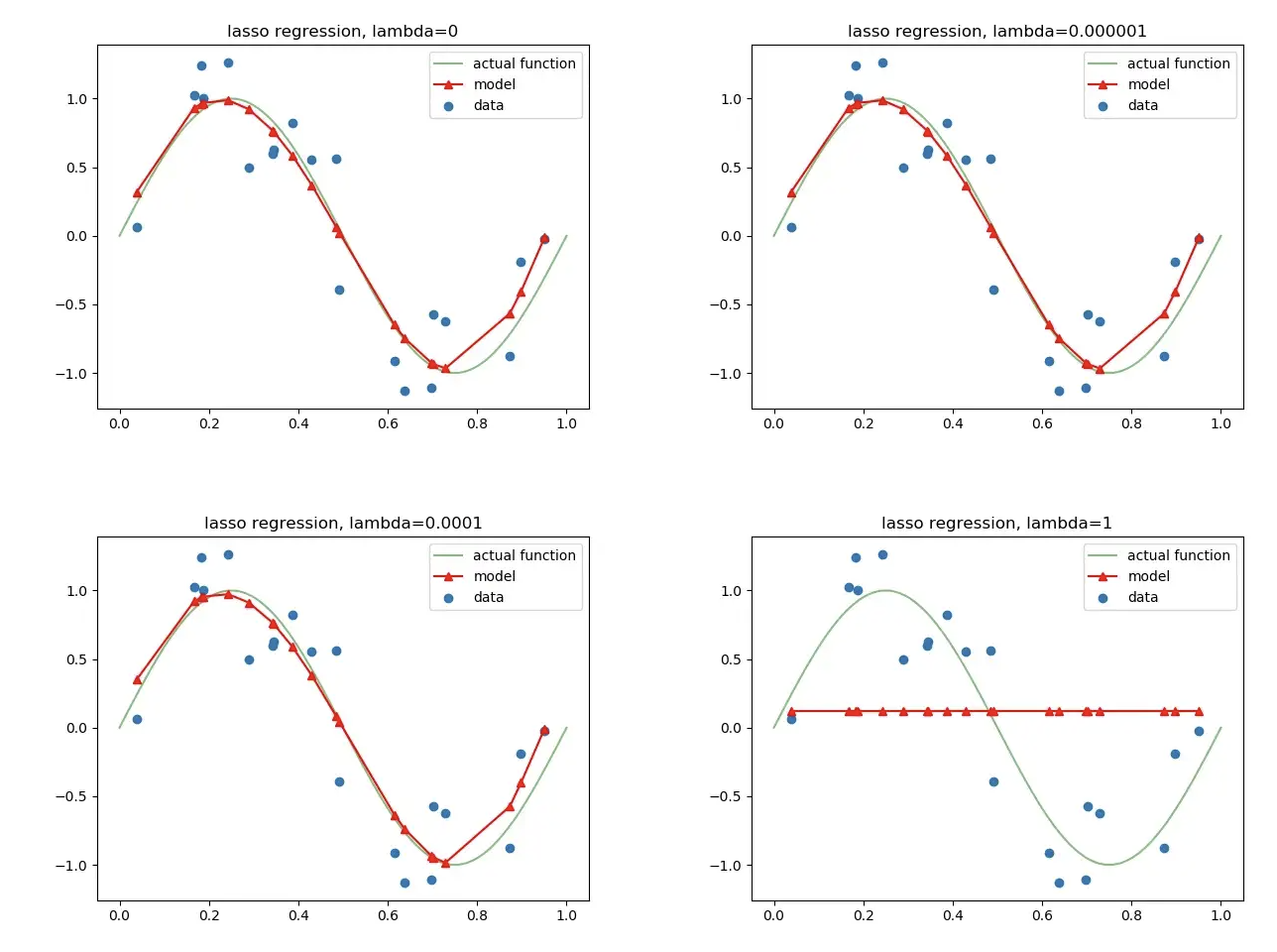
1. L1 Regularization
- L1 Regularization을 사용하는 Regression model을 Lasso(Least Absolute Shrinkage and Selection Operator) Regularization이라고 부름
- sparse model에 적합 convex optimization에 유용하게 사용됨
2. L2 Regularization
- L2 Regularization을 사용하는 Regression model을 Ridge Regression이라고 부름
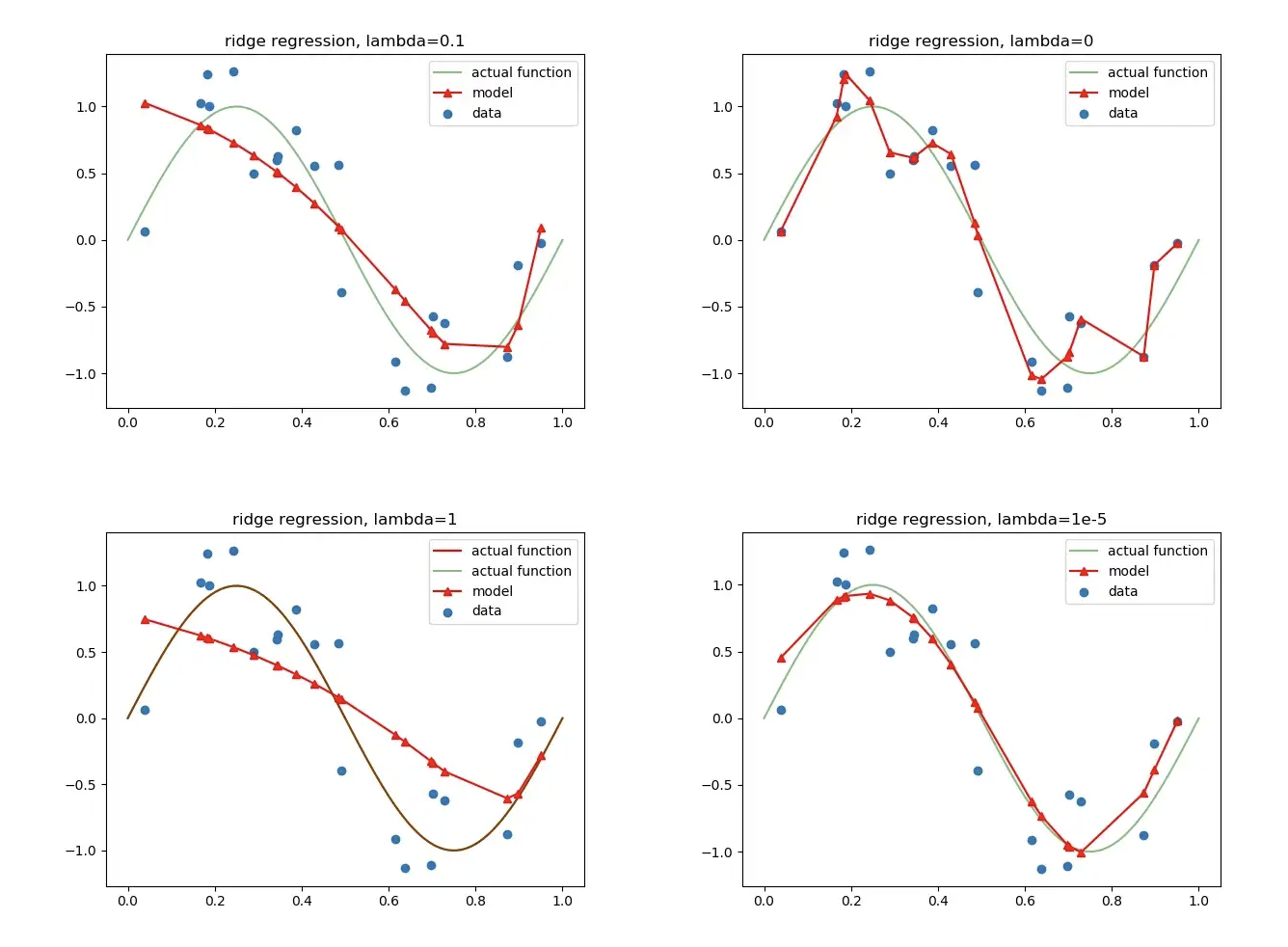
3. L1 Normalization, L2 Normalization의 비교
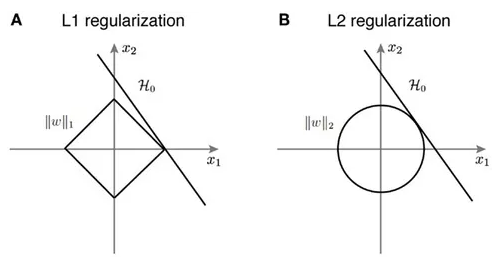
- computational difficulty : L2 > L1
- sparsity : L1 > L2
Reference
[1] https://light-tree.tistory.com/125
[2] https://towardsdatascience.com/regularization-the-path-to-bias-variance-trade-off-b7a7088b4577
[3] https://www.kaggle.com/code/residentmario/l1-norms-versus-l2-norms/notebook

we_need_to_talk_about_ds