Internal Covariate Shift
1. Internal Covariate Shift란?
Covariate shift (공변량 변화)
: 입력 데이터의 분포가 학습할 때와 테스트 할 때 다르게 나타나는 현상
- 학습 데이터를 이용해 만든 모델이 테스트 데이터셋을 가지고 추론할 때 성능에 영향을 미칠 수 있음
Internal Covariate Shift
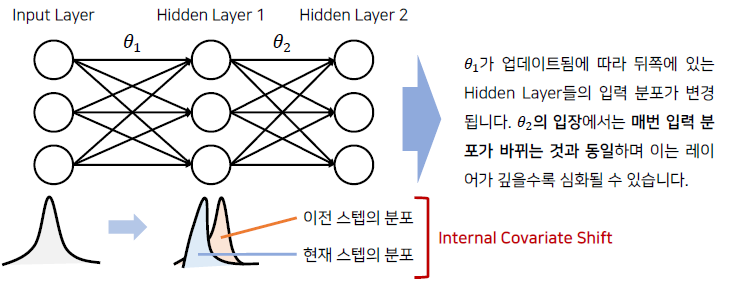
: Covariate Shift가 Neural Network 내부에서 일어나는 현상 → 매 스텝마다 hidden layer에 들어오는 데이터 분포가 달라짐
- layer의 수가 많아질수록 학습이 잘 되지 않음 (학습 성능이 떨어짐)
-
특히, mini-batch 사용하여 학습시 batch 마다 출력 데이터 분포가 달라짐 → 전혀 예측 불가한 gradient 학습
→ 이것의 원인이 Internal Covariate Shift
-
- Batch Normalization이 이 문제를 해결해 준다고 함
Batch Normalization
1. Batch Normalization이란?
: 일정한 크기의 미니배치에 걸쳐 네트워크의 활성화를 정규화
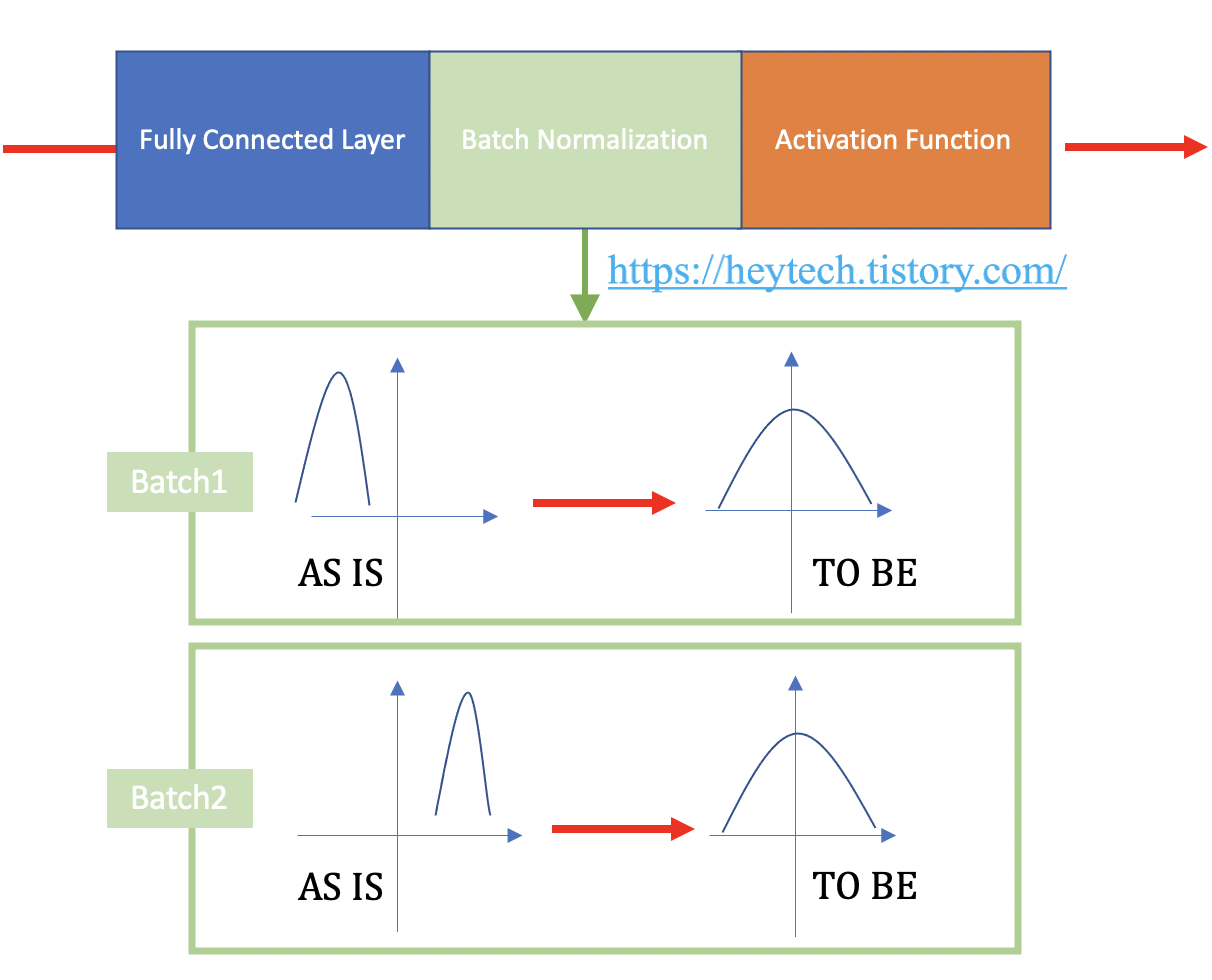
- 단순히 평균 0, 표준편차 1이 되도록 정규화하는 것 x → 아래의 규칙들을 따름
-
각 feature에 대해서 mini batch에서 평균과 표준편차를 구한후, 평균을 빼고 mini batch의 표준편차로 나눠줌
→ 가중치의 크기를 증가하면 성능이 더 좋아지는가? → γ와 β scale, shift 학습 가능한 parameter로 추가

-
2. Batch Normalization 장점
-
데이터 scale 통일
어떤 데이터 분포가 입력으로 들어와도 모두 정규화 → layer의 feature가 동일한 scale을 가짐
-
활성화 함수 맞춤형 분포 변화
추가적인 scaling과 bias를 학습함으로써 활성함수의 종류에 맞게 적합한 분포로 변환 가능
3. Batch Normalization의 문제
-
mini batch 크기에 의존적
batch size가 1일 때, variance=0 → batch norm이 작동하지 않음 (너무 작은 배치 크기에서 잘 동작하지 않음)
mini batch 너무 작으면 noise가 크고 훈련에 영향을 줄 수 있음 → 동일한 배치 크기를 가져와야함
-
Recurrent Neural Network에 적용하기 어려움
RNN에서 각각의 time-step에 따라 batch norm layer를 분리해야함 (각각의 time-step마다 다른 분포를 갖고 있기 때문)
but 이렇게 하면 각 time step마다 통계를 저장해야 하기 때문에 모델이 더 복잡해지고 공간 소모가 많음
4. Batch Normalizaton의 대안들
- weight normalization → weight(convolution filter) 대상으로 normalization
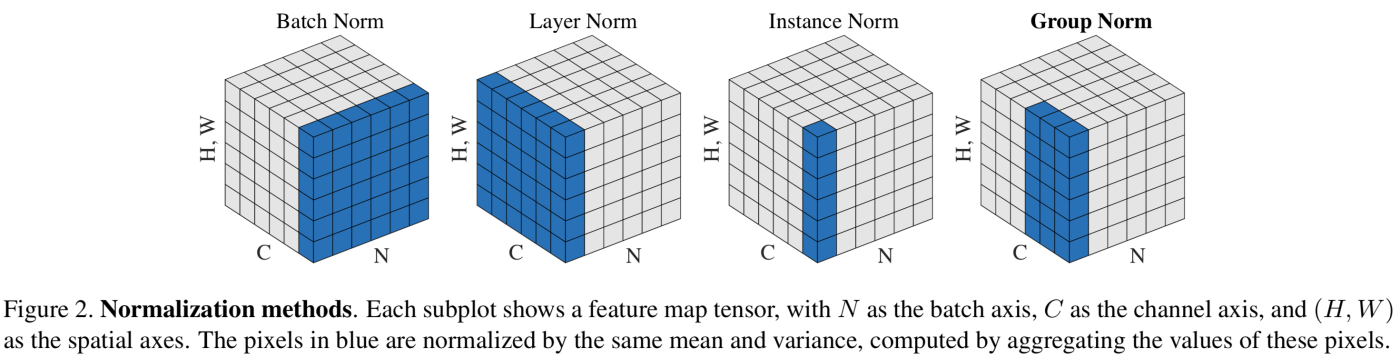
- batch / layer / instance / group normalization → feature activation 대상으로 normalization
4-1. Weight Normalization
: activation을 직접 정규화하는 대신 layer의 가중치(convolution filter)를 직접 정규화
- mean-only batch normalization과 weight normalization이 결합된 것이 CIFAR-19에서 최상의 결과를 달성함
4-2. Layer Normalization
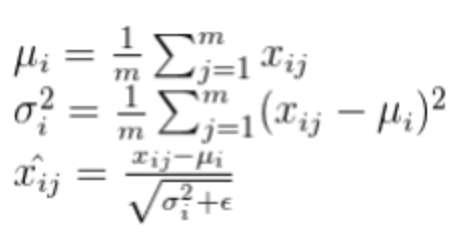
: batch normalization에서 batch 차원의 input feature를 정규화하는 대신 기능 전반에 걸쳐 입력을 정규화
- RNN에서 batch norm보다 더 잘 작동함
4-3. Instance Normalization
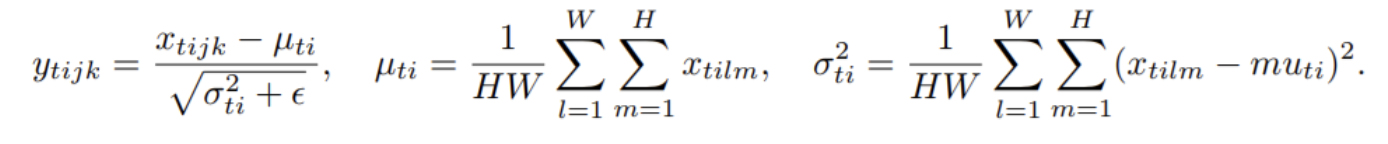
: layer normalization과 매우 비슷
- instance normalization은 train instance의 입력 기능에 걸쳐 정규화하는 대신 각 train 예제의 각channel에 걸쳐서 정규화된다는 점이 layer normalization과의 차이점
4-4. Group Normalization
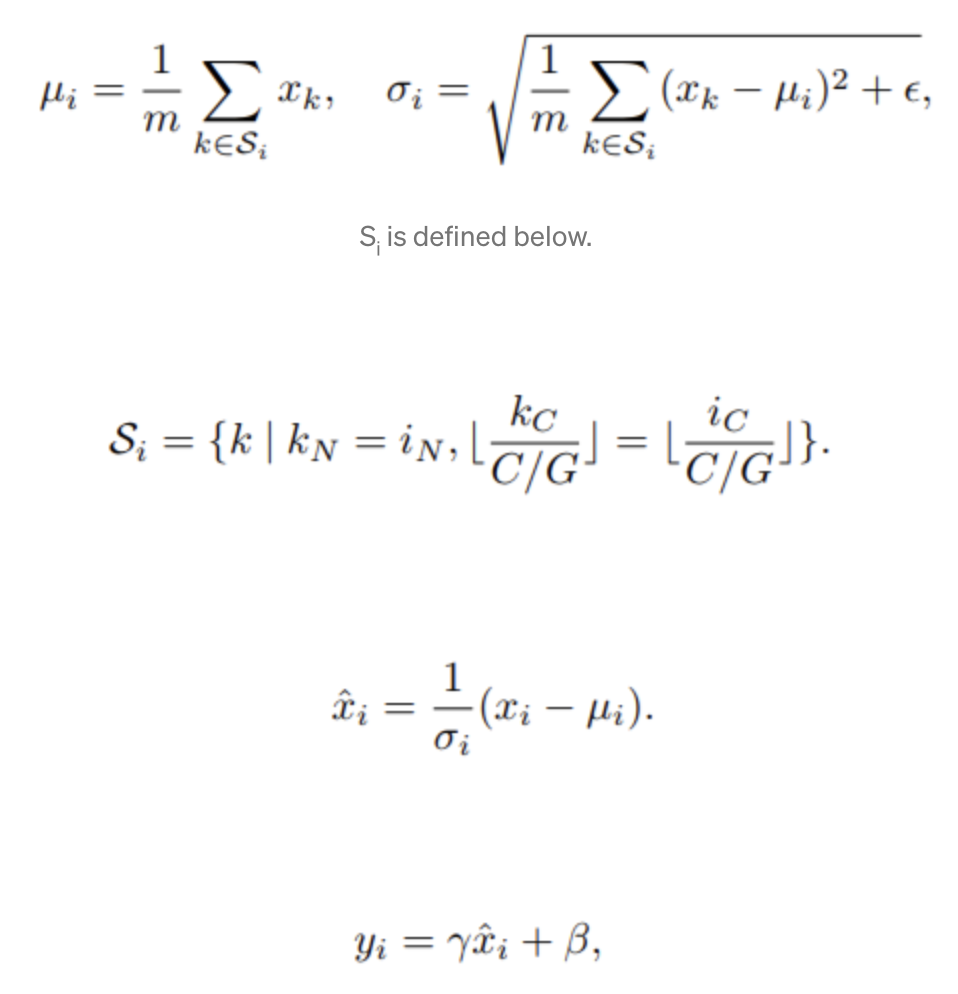
: 각 training 예를 위한 채널들의 그룹을 너머 정규화
- single group으로 채널을 넣으면 layer normalization
- 각각 다 다른 그룹으로 채널을 넣으면 instance normalization
4-5. Batch-Instance Normalization
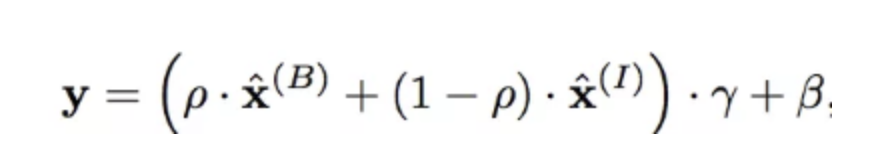
- instance normalization은 style information을 없앤다는 문제점 존재
-
그렇지만 contrast 문제가 있을 때 문제가 될 수 있음
→ batch-instance normalization이 이것을 다루기 위해서 얼마나 많은 스타일 정보가 각각의 채널에 사용되었는지를 시도
-
5. Batch Normalization에 대한 다른 주장
https://arxiv.org/pdf/1805.11604.pdf 논문에 따르면,
-
Batch Normalization은 Internal Covariate Shift를 해결하지 못함
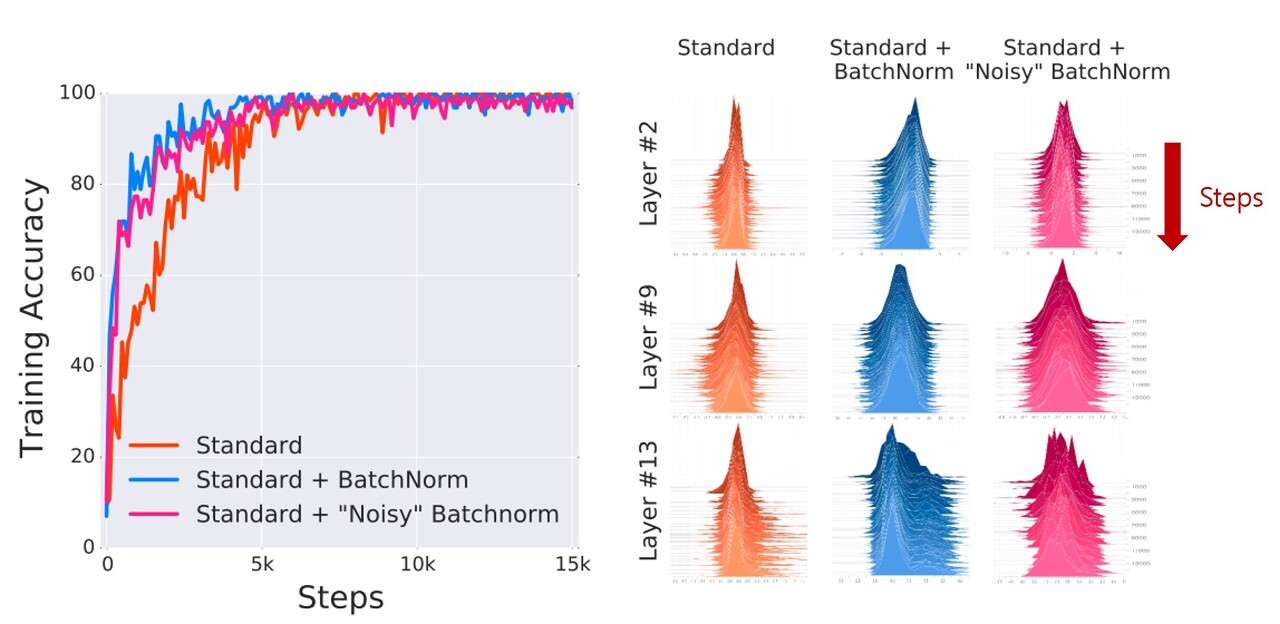
- 왼쪽 그래프 → Batch Normalization을 사용하면 학습 속도가 빨라져 빠르게 수렴
- 오른쪽 그래프 → layer가 많아질수록 Internal Covariate Shift가 심해짐, Batch Normalization이 추가되어도 이 현상이 없어지지 않음
-
Internal Covariate Shift가 있더라도 학습에 나쁜 영향을 주지는 않음
-
Batch Normalization이 학습 성능을 높이는 이유는 optimization landscape를 smooth하게 만들어주기 때문 → 정규화 방법 (L1 Normalization, L2 Normalization)도 같은 효과

Reference
[1] https://medium.com/techspace-usict/normalization-techniques-in-deep-neural-networks-9121bf100d8
[2] https://heytech.tistory.com/438
[3] https://cvml.tistory.com/5
