RecSys'16 Deep Neural Networks for YouTube Recommendations 논문 리뷰입니다.
0. Abstract
- 대규모인 유튜브 환경에서 추천을 진행하기 위해 two stage information retrieval을 이용해 추천시스템을 구성하였다.
- 이 과정에서 딥러닝을 적용하였고 성능이 dramatic하게 향상됐다.
- Two-stage information retrieval dichotomy
- 후보군 생성 (Deep candidate generation model)
- 랭킹 (Deep ranking model)
- 거대한 추천시스템을 구축할 때 인사이트도 함께 제안한다.
1. Introduction
- YouTube는 사용자 개개인들이 원하는 개인화된 컨텐츠 추천을 해야할 책임이 있다.
- 추천시스템을 구현할 때 다음과 같은 3가지의 문제를 갖고 있다.
1. Scale
- YouTube의 수많은 사용자와 코퍼스를 다루기 위해서 효율적인 서빙과 특화된 추천 알고리즘이 필요하다.
2. Freshness
- YouTube에는 매분매초 수많은 영상이 업로드 되고, 추천시스템은 새롭게 올라오는 컨텐츠와 사용자의 행동에 적절하게 대응해야 한다.
- 잘 만들어진 영상과 새로운 컨텐츠 사이에서 적절하게 적용 및 반영할 수 있어야 한다.
3. Noise
- Sparsity와 수많은 외부요인으로 사용자 행동을 예측하기 어렵다.
- Implicit feedback을 적절히 사용하고, poorly structured metadata도 활용할 수 있어야 한다.
2. System Overview
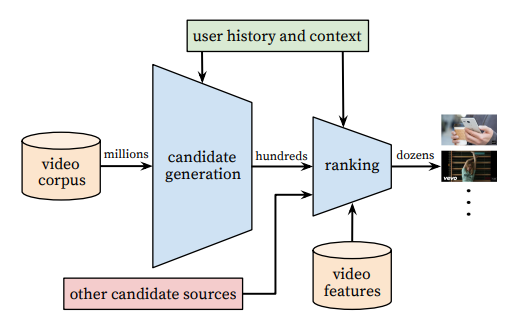
- 2010년도 유튜브 논문과 같이 Candidate Generation과 Ranking 부분으로 나눌 수 있다.
- 두 layer를 모두 neural network로 구성한다는 점이 바뀐점
- Candidate Generation
- Input : 사용자의 YouTube 히스토리
- Output : 사용자와 관련있을만한 영상집합
- 협업필터링을 사용하고, 시청기록, 검색키워드, demographics 정보를 활용한다.
- 생성된 후보군은 high precision을 가지도록 추천하는 것이 목표이다.
- 유저는 자기가 좋아하는 video를 몇 개 빠뜨리는 것(FN)에는 관대하지만, 싫어하는 것을 추천하는 것(FP)에는 민감하게 반응하기 때문에
- Ranking Model
- 영상과 사용자 features로 각 영상에 대해 점수를 매긴다.
- 높은 recall을 가지도록 하는 것이 중요하다.
- 점수에 따라 순위가 매겨져 가장 높은 점수를 받는 비디오는 사용자에게 표시된다.
- 반복적인 업데이트를 가이드하기 위해서 학습할 때, offline metric(precision, recall, ranking loss 등) 활용한다.
- (라이브) A/B 테스트를 통해 최종 알고리즘을 선택한다.
3. Candidate Generation
Non-linear generalization of factorization technique
3-1. Recommendation as Classification
-
: high-dimensional user-embedding
-
: 개별 video의 embedding
-
C : context
-
사용자와 context의 vector u를 학습하여 영상(i)을 시청 확률을 계산하는 Softmax Classifier
-
비디오를 끝까지 본 사용자를 positive로 간주하여 implicit feedback을 사용한다.
- explicit이 드문 영상, viral한 영향을 받는 영상에 대해 공평한 기준이 implicit feedback이기 때문에 이것으로 평가
-
Negative Sampling을 통해 효율적인 학습을 한다.
- 수백만개의 클래스를 갖는 softmax classification 문제에서 계산량이 기하급수적으로 늘어나기 때문에 negative sampling을 적용한다.
- Negative sampling
- word2vec에서 나온 아이디어로 다중 분류 문제를 이진분류로 만드는 데 사용하는 방법
- 전체 단어 집합이 아닌 일부 단어 집합만 조정
- 이 단어 집합은 positive sample(기준 단어와 관련 있는 sample)과 negative sample(기준 단어와 관련 없는 sample)로 이루어져 있음 (기준 단어와 관련된 parameter들은 다 업데이트 해주는데, 관련되지 않은 parameter들은 몇 개 뽑아 업데이트)
- Negative sampling
- negative sampling 후 importance weighting으로 보정
- 전통적인 softmax classification보다 100배 이상의 속도 개선
- 연산이 너무 비대해지는 것을 막기 위한 비슷한 방법인 hierarchical softmax로 해결할 수도 있지만 이 경우에는 tree 구조로 변경하면서 관련 없는 클래스들이 묶이는 경우가 생겨 성능이 내려가 선택 x
- 수백만개의 클래스를 갖는 softmax classification 문제에서 계산량이 기하급수적으로 늘어나기 때문에 negative sampling을 적용한다.
-
Serving을 통해서 top N classes를 보여줘야 하는데 latency를 줄이기 위해서 dot product space에서 Nearest Neighbor Search를 찾는 방법을 활용
3-2. Model Architecture
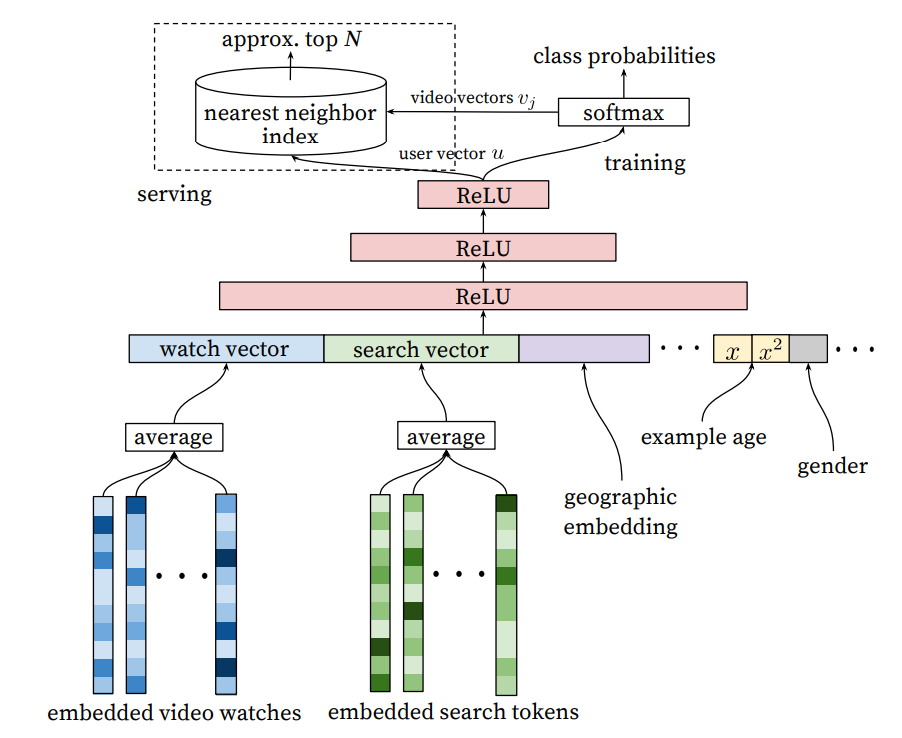
- 다음의 embedding을 모두 concat한다.
- 사용자의 시청 기록 (embedded video watches)
- 사용자의 검색 기록 (embedded search tokens)
- 시청 기록과 검색 기록의 임베딩을 평균내어 concat하는 이유
- 순서 정보를 뭉개버리기 위해서 (마지막 검색어의 importance를 의도적으로 낮춰주기 위해서)
- 임베딩 그대로 넣게 되면 모델이 가장 최근 검색어만 외우는 수준으로 학습하게 되는데, 유저는 이미 검색해서 본 영상 말고 새로운 영상을 추천 받기 원하기 때문에
- 시청 기록과 검색 기록의 임베딩을 평균내어 concat하는 이유
- geographic embedding
- 추가 meta 정보 (age, gender 등)
3-3. Heterogeneous Signals
- Continuous와 categorical features를 deep neural network에 사용할 수 있다.
- DNN을 사용하면 categorical한 feature를 깎아내릴 필요도 없고, continuous한 feature도 여러번 normalize할 필요가 없어 쉽게 feature를 추가 할 수 있다.
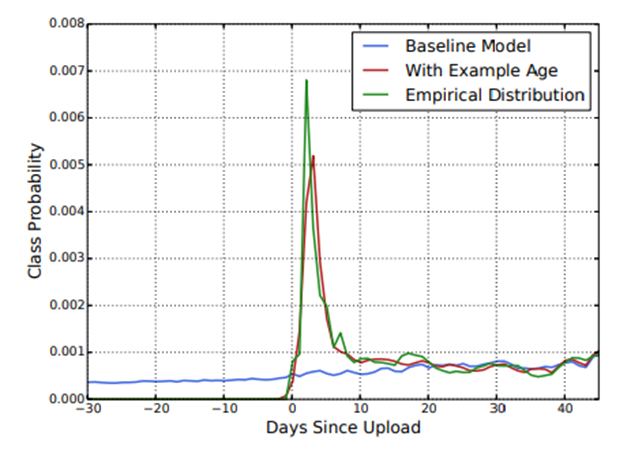
- 보통 새로운 영상은 사용자가 선호하는 경향을 보임
- 시청기록은 시간정보를 포함하고 있지 않다.
- Age feature는 영상 콘텐츠의 시간정보이다.
- 자신과 비슷한 취향의 영상일 경우 최신 영상을 선호하기 때문에 example age를 도입해 가중치 부여
3-4. Label and Context Selection
- 추천 시스템은 surrogate problem (실제 상황과 evaluation metric 차이)을 항상 고려해야한다.
- 유튜브 이외의 데이터도 학습데이터에 포함해야한다.
- 사용자의 가중치를 동일하게 하기 위해 사용자의 학습데이터 수를 고정한다.
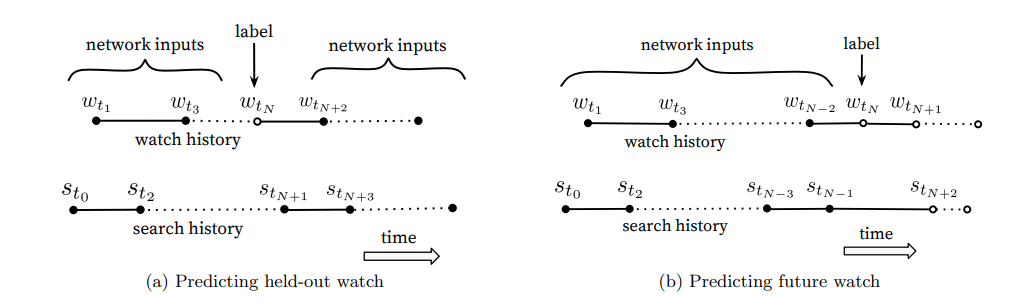
- 영상 시청 패턴은 비대칭적 → 무작위로 아이템을 선정하여 예측하는 것보다 특정 시점 기준으로 예측하는 것이 더 효과적
- 시리즈물은 순서대로, 음악은 유명한 노래에서 마이너한 노래 순으로 감상하는 것처럼 영상 시청 패턴은 랜덤하지 않음
- 그러므로 유저의 history를 rollback하여 watch label 시점보다 과거 사용자 로그에서만 샘플링하여서 input으로 넣음
3-5. Experiments with Features and Depth
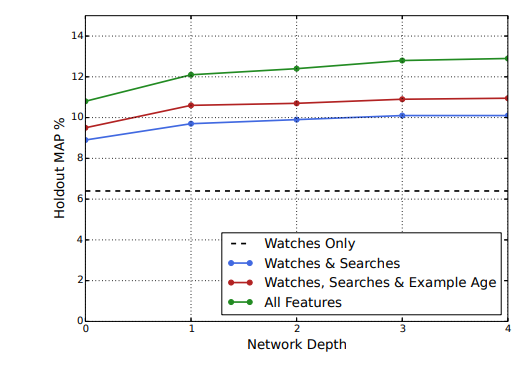

- Features 수와 depth에 따라 달라지는 성능을 비교한다.
- 시청 정보만 확인할 때보다 특성들을 추가할수록 성능이 증가했다.
4. Ranking
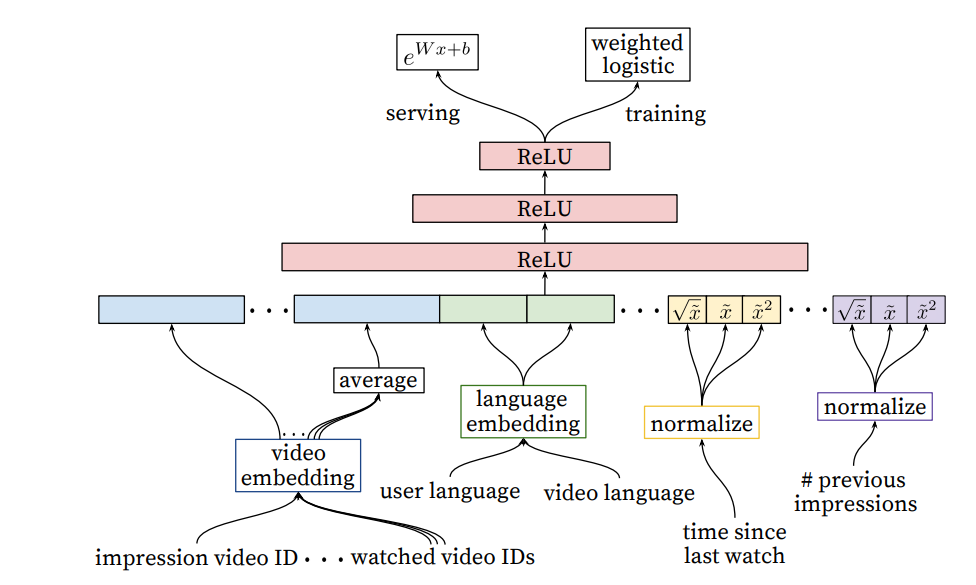
- impression data를 사용하여 특정 사용자 인터페이스에 대한 후보 예측을 한다.
- Ranking에서는 영상과 사용자 사이의 관계를 표현하는 features를 많이 사용해야 한다.
- 로지스틱 회귀를 사용하여 비디오 노출에 독립적인 점수를 할당하기 위한 Candidate generation과 유사한 구조를 가진 DNN을 사용 → 비디오 목록이 점수별로 정렬되어 사용자에게 반환
- categorical feature와 continuous features를 사용한다.
- 사용자의 이전 행동을 고려하여 아이템과의 interaction을 모델링 해야한다.
4-1. Feature Representation
- 랭킹 모델에서 수백개의 feature를 사용하면서 범주형과 연속형을 균등하게 분할한다.
- 각 features에 대한 feature engineering이 필요하다.
- Embedding Categorical features
- 조회수 순으로 높은 N%로 잘라내고 그 안에 속하지 않는 클래스들은 zero embedding 처리를 한다.
- 다중값을 가지는 경우는 candidate generation과 같이 average 값을 넣는다.
- 동일한 ID 공간의 feature는 embedding을 공유하여 속도 개선
- Normalizing Continuous features
- 분위수로 변환하여 0~1로 정규화
- 모두 feature로 넣어 추가적인 레이어를 거치지 않도록 보기를 많이 넣어준다.
- Embedding Categorical features
4-2. Modeling Expected Watch Time
- 사용자가 선택한 아이템과 그렇지 않은 아이템의 예상 시청 시간을 예측하는 것이 목표이다.
- 감상을 하지 않았으면 0. 감상을 했으면 감상한 시간을 값으로 넣는다.
- A/B test 결과 CTR Prediction보다 예상 시청 시간을 예측하는 것이 더 나은 추천 결과를 얻었다.
- 예상 시청 시간을 예측하기 위해서 weighted logistic regression을 사용했다.
- positive(clicked) 노출은 관찰된 시청 시간에 따라 가중치가 부여되고, negative(clicked) 노출은 모두 단위 가중치만 부여받는다.
4-3. Experiments with Hidden Layers
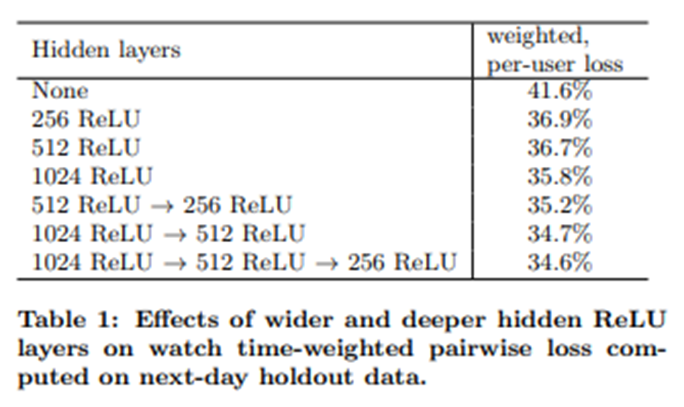
- weighted, per-user loss : (잘못 에측한 시청 시간) / (전체 시청 시간)
- FC의 차원을 늘릴수록 성능이 증가했다.
- FC를 쌓을수록 성능이 증가했다.
- 클릭된 경우/클릭되지 않은 경우에 따른 weight를 설정하지 않고 훈련했을 땐 loss가 4%나 증가했다.
5. Conclusions
- YouTube 영상 추천시스템은 candidate generation과 ranking 부분으로 나뉘어져 있다.
- Deep Collaborative filtering 모델은 더 많은 특징과 interaction을 반영할 수 있다.
- Age feature를 추가하여 time-dependent한 부분을 반영하고 watch time이 증가함을 확인했다.
- Embedding categorical features와 normalized continuous features를 활용한다.
- 여러 층의 신경망은 수많은 features 사이의 non-linear interactions를 효과적으로 모델링 할 수 있다.

we_need_to_talk_about_ds