0. Abstract
- RNN(Recurrent Neural Network)는 NLP task에서 가장 많이 사용되는 구조
- 반복 구조가 가변 길이의 텍스트를 처리하는 데 매우 적합
- 각 텍스트를 구성하는 토큰을 벡터로 변환하여 행렬을 형성하여 단어의 분산 표현 활용 가능
- 기존 모델에서는 고정 길이의 벡터를 얻기 위해 시간 단계 차원에서만 1D pooling operation 또는 attention-based operation 사용
- 특징 벡터 차원의 특징들은 상호 독립적이지 않기 때문에 단순히 시간 단계 차원에 1D pooling operation을 독립적으로 적용하면 특징 표현 구조 파괴
- 2D pooling operation을 적용하면 sequence 모델링에서 더 의미있는 샘플링 가능
- 이 논문에서는
① 행렬의 두 차원에 있는 특징을 통합하기 위해 2D max pooling operation 적용하여 텍스트 고정 길이 표현 얻음
② 2D convolution을 활용하여 행렬의 보다 의미있는 정보 샘플링
1. Introduction
- 텍스트 분류는 NLP에서 필수적인 요소 ex) sentiment analysis, relation extraction, spam detection
- 텍스트 모델링의 과제는 구문, 문장, 문서 등 다양한 텍스트 단위의 특징을 포착하는 방법
- 순환 구조의 이점을 가진 RNN은 가변 길이 텍스트를 처리하는 데 매우 적합
- 각 텍스트를 구성하는 토큰을 벡터로 변환하여 행렬을 형성하여 단어의 분산된 표현 활용 가능
- RNN은 각 텍스트를 구성하는 토큰을 행렬에서 벡터로 변환하여 단어의 distributed representation 활용 가능
- 행렬은 time-step 차원과 feature vector 차원이라는 두가지 차원 포함, feature representation을 학습하는 과정에서 업데이트됨
- RNN은 최대값을 추출하거나 가중치 표현을 생성하는 1D max pooling operation 또는 attention-based operation 활용
- 두 연산자(1D max pooling operation, attention-based operation) 모두 feature vector의 특징을 무시하므로 sentence representation에 적합하지 않을 수 있음 → 심각한 한계 발생 가능
- CNN은 1D convolution 을 사용하여 특징 매핑 수행, time-step 차원에 걸쳐 1D max pooling operation을 적용하여 고정 길이 출력 얻음
- BLSTM-2DPooling (Bidirectional Long Short-Term Memory Networks with Two-Dimensional Max Pooling)
- 시간 단계 차원(time-step dimension)과 특징 벡터 차원(feature vector dimension) 모두에서 특징을 포착하기 위해 제안
- BLSTM을 사용하여 텍스트를 벡터로 변환 → 2D max pooling을 활용하여 고정 길이 벡터 얻음 → 의미 있는 특징을 포착하기 위해 2D convolution 적용
1-1. Contributions
- BLSTM을 활용하여 long-term sentence dependency 포착, sequence modeling을 위해 2D convolution, 2D max pooling operation을 통해 특징 추출하는 결합 프레임워크 제안
- BLSTM-2DPooling, BLSTM-2DCNN 소개, 감성분석, 6개의 텍스트 분류 작업에 대해 검증
- 6개 작업 중 4개 작업에서 우수한 성능 달성
- 2D convolution과 2D max pooling operation의 효과를 더 잘 이해하기 위해 문장의 길이, 2D의 민감도 분석 수행
2. Related Work
- Recursive Neural Networks(RecNN)
: 재귀적인 트리 구조 위에서 정의됨. 트리의 잎 노드와 내부 노드에서 정보가 하향식으로 결합 - Recurrent Neural Networks(RNN)
: 입력값을 순서대로 받아 하나씩 순차적으로 처리 - Convolution Neural Networks(CNN)
: 2D convolution layer와 2D pooling layer가 있는 신경망으로 이미지 처리를 위해 개발됨 - Other Neural Networks
텍스트 분류를 위해서 많은 모델들이 제안됨
- Iyyer et al. (2015) deep averaging network : 분류 전 여러 숨겨진 레이어를 통해 가중치가 없는 단어 임베딩 평균 제공
- Zhou et al. (2015) CNN 사용하여 높은 수준의 구문 표현 시퀀스 추출 → LSTM에 입력하여 문장 표현 얻음
- Wen et al. (2016) RCNN : LSTM, Bidirectional RNN사용하여 의존성 포착
3. Model
BLSTM Layer, 2D Convolution Layer, 2D max Pooling Layer, Output Layer 4 부분으로 구성
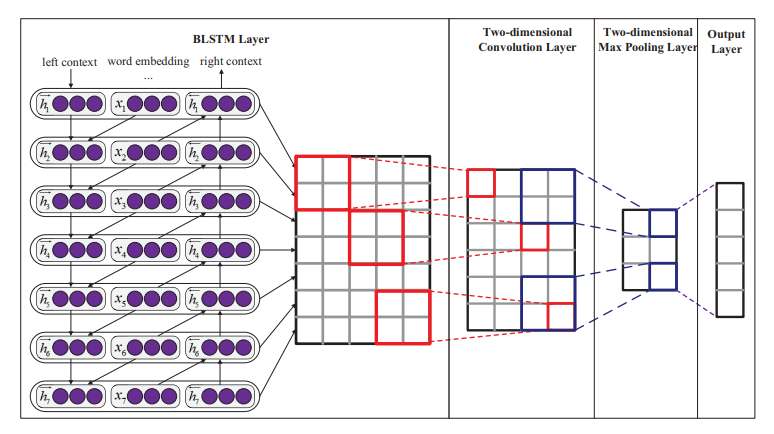
3-1. BLSTM Layer
- LSTM은 RNN의 gradient vanishing 문제를 극복하기 위해서 처음 제안됨
- adaptive gating mechanism : 현재 데이터 입력에 대해 이전 상태를 유지하고 현재 데이터 입력의 추출된 feature를 기억
- BLSTM (Bidirectional LSTM)
-
hidden to hidden 연결이 반대 시간 순서로 흐르는 두 번째 hidden layer를 도입하여 undirectional LSTM을 확장
-
과거와 미래의 정보 모두 활용 가능
-
forward와 backward pass의 결과가 결합될 때 element-wise sum이 사용됨
-
3-2. Convolutional Neural Networks
- BLSTM은 과거 문맥뿐만 아니라 미래 문맥에도 접근할 수 있기 때문에 텍스트의 다른 모든 단어와 관련이 있음
- 특징 벡터로 구성된 행렬을 효과적으로 이미지처럼 취급할 수 있으므로 2D convolution, 2D max pooling을 사용하여 의미있는 정보 캡처 가능
3-2-1. Two-dimensional Convolution Layer
- local feature를 추출하기 위함
- convolution layer에는 같은 크기의 필터를 여러 개 사용하여 상호 보완적인 특징을 살리거나 크기가 다른 여러 종류의 필터 사용 가능
- 2D filter , window of k words, d feature vectors일 때의 feature
3-2-2. Two-dimensional Max Pooling Layer
- 고정된 길이의 벡터를 얻기 위함
- 2D max pooling , window of matrix O일 때의 maximum value
3-3. Output Layer
- softmax classifier layer로 전달되어 이산적인 클래스 집합으로부터 의미 관계를 예측
- 분류기는 hidden state 을 입력값으로 받음
- 최소화해야 할 훈련 목표는 cross-entropy loss
- one-hot으로 표현된 ground truth , softmax에 의해 각 클래스에 대한 추정 확률 , 목표 클래스의 수 m, L2 regularization hyper-parameter
4. Experimental Setup
4-1. Datasets
- MR : 문장 극성(polarity) 데이터 세트. positive/negative 리뷰 탐지
- SST-1 : MR을 확장한 것. 리뷰를 세분화된 레이블 (very negative, negative, neutral, positive, very positive)로 분류
- SST-2 : SST-1과 동일하지만 neutral이 제거되고 positive, negative가 있음
- Subj : 주관성 데이터 세트. 문장이 subjective인지 objective인지 분류
- TREC : 질문 분류 데이터 세트. 문장 6가지 질문 유형 분류 (abbreviation, description, entity, human, location, numeric value)
- 20Newsgroups : 20개의 뉴스그룹의 메세지 포함. 네가지 카테고리로 분류 (comp, politics, rec, religion)
4-2. Word Embeddings
- 60억 개의 위키백과에 대해 훈련한 Glove embedding 사용
- [-0.1, 0.1] 범위에서 균등분포로 랜덤하게 샘플링하여 초기화
4-3. Hyper-parameter Settings
- 20Ng 데이터셋에는 Macro-F1 평가지표사용, 나머지 5개 데이터셋에는 accuracy 평가지표 사용
- SST-1 데이터셋에서 grid search를 통해 찾아진 값들
- word embeddiing 차원 : 300
- LSTM hidden units : 300
- window size : (3,3), 2D pooling size : (2,2) 각각 100개 convolution filter 사용
- mini-batch size : 10
- optimizer : AdaDelta
- word embedding dropout : 0.5, BLSTM dropout : 0.2, 끝에서 두번째 layer dropout : 0.4
- LSTM layer의 hidden layer 수를 다르게 하거나, 넓은 convolution을 사용하거나 fine tuning을 더 해서 성능을 더 개선할 수 있음
5. Results
5-1. Overall Performance
- 이 논문에서 파생된 모델 4가지 : BLSTM, BLSTM-Att, BLSTM-2DPooling, BLSTM-2DCNN
- 비교군으로 사용한 모델 유형 : ReNN, RNN, CNN, other neural networks
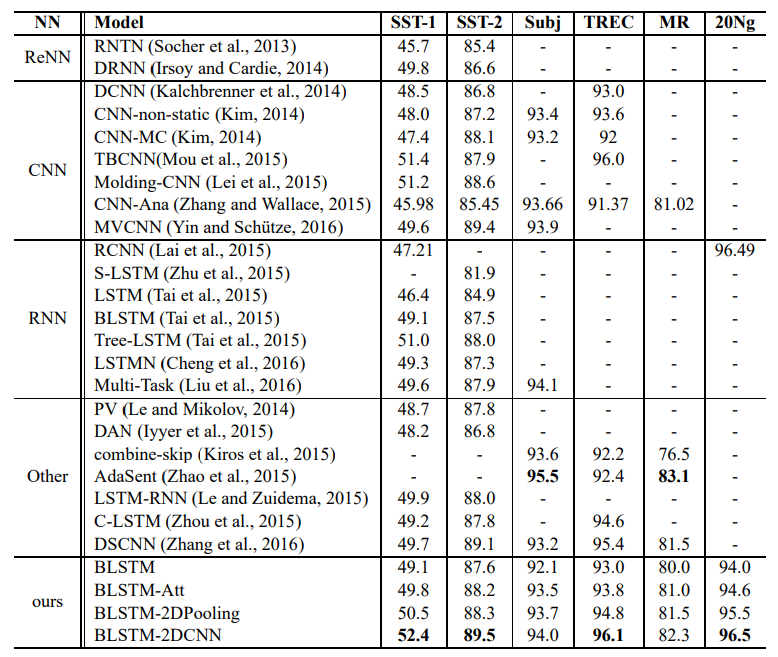
- BLSTM-2DCNN 모델은 6개 과제 중 4개 과제에서 가장 우수한 성능 달성
- 제안된 두 모델은 ReNN과 비교하여 종속성 구문 분석 트리와 같은 언어 고유의 기능에 의존하지 않음
- CNN은 입력 텍스트의 word embedding에서 특징을 추출하는 반면, BLSTM-2DPooling과 BLSTM-2DCNN은 원본 입력 텍스트에서 이미 특징을 추출한 BLSTM 레이어의 출력에서 특징 추출
- BLSTM-2DCNN은 BLSTM-2DPooling을 확장한 것 → 텍스트에서 더 많은 종속성 추출
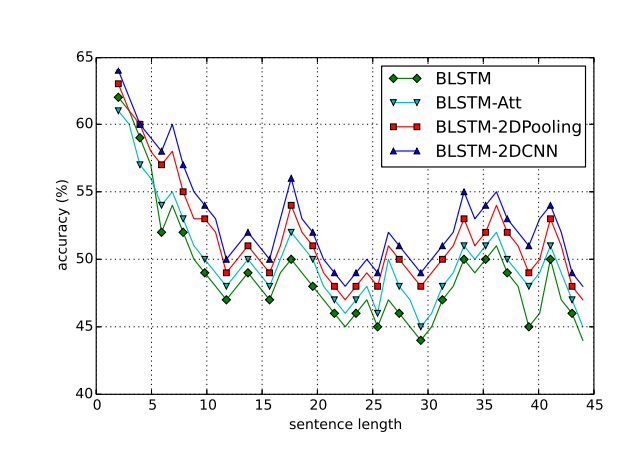
5-2. Effect of Sentence Length
- 다양한 길이의 문장에 대한 네 가지 모델의 성능
- [l-2, l+2]의 window 길이를 가진 문장의 평균값
- BLSTM-2DPooling, BLSTM-2DCNN이 모두 다른 두 모델보다 성능 뛰어남
- 문장의 길이가 증가함에 따라 정확도가 감소함을 보여줌
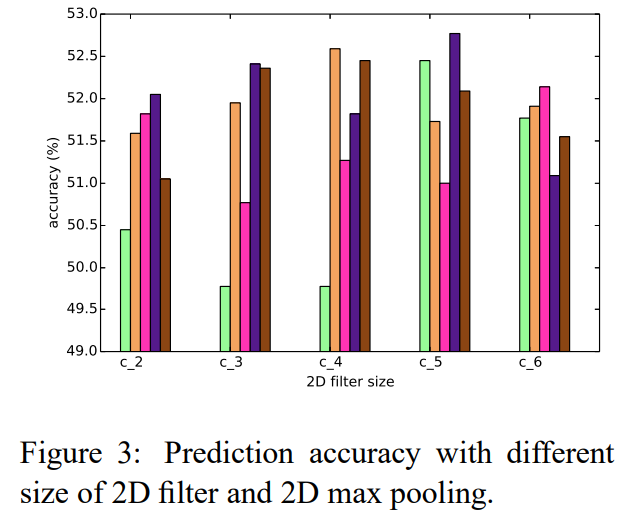
5-3. Effect of 2D Convolutional Filter and 2D Max Pooling Size
- BLSTM-2DCNN을 사용하여 SST-1 dataset을 사용하여 실험 수행
- feature map 수 : 100
- c는 2D convolution filter의 크기
- 2D filter size (5,5) 2D max pooling size(5,5)에서 accuracy 52.6%으로 최고
- 더 큰 filter를 사용하면 convolution이 더 많은 feature를 감지하여 accuracy 향상 가능
6. Conclusion
- BLSTM-2DPooling, BLSTM-2DPooling의 확장형인 BLSTM-2DCNN 모델 소개
- 두 모델 모두 time-series dimension 뿐만 아니라 feature vector dimension 정보도 가짐
- 실험은 6개의 텍스트 분류 작업에 대해 수행
- 실험 결과 BLSTM-2DCNN은 RecNN, RNN, CNN 모델보다 성능이 우수
- BLSTM-2DPooling 및 DSCNN보다 더 잘 작동
- 필터가 클수록 더 많은 특징을 검출할 수 있으며 이는 성능 향상으로 이어질 수 있음

we_need_to_talk_about_ds